

はじめに
こんにちは。高橋 (ポインコ兄) です。
さて、今回は「AWS の生成 AI を整理する」というテーマで、生成 AI とそれに関わる AWS サービスについて整理をしていきます。
※本ブログ記事は、2025/5/26 時点の情報です
- はじめに
- 生成 AI について整理する
- AWS における生成 AI サービス
- 各サービスの一覧・概要
- Amazon Bedrock
- Amazon SageMaker
- Amazon Q Business
- Amazon Q Developer (旧 Amazon CodeWhisperer)
- PartyRock
- AWS HealthScribe
- AWS Transform (旧 Amazon Q Developer transformation)
- Amazon Comprehend
- AWS Amplify Studio (旧 AWS App Studio)
- Amazon Kendra
- Amazon Transcribe
- Amazon Personalize - Content Generator
- Amazon Polly
- Amazon Textract
- Amazon Rekognition
- Amazon Lex
- 各サービスの一覧・概要
- あとがき
生成 AI について整理する
最近さかんに言われる「生成 AI」とは、そもそも何でしょうか? (gen AI とも呼ばれますね。)
生成 AI とは、学習済みデータから新しいコンテンツ (テキスト、画像、動画 etc...) を自律的に作り出す人工知能の一種です。厳密な定義は存在しませんが、既存の情報から新しいものを生み出す、というところが「生成」と言われる所以です。
では「AI (人工知能)」とは何でしょうか? AI とは人間の知的な振る舞いをコンピューター上で実現する技術の総称です。
AI を実現するための重要な技術要素の一つが機械学習 (ML / Machine Learning) です。 機械学習は、大量のデータからコンピューターが自動的にパターンやルールを学習し、予測や意思決定をおこない、自律的に性能を向上させることができます。
What is Machine Learning? - ML Technology Explained - AWS
そして、近年注目を集めているのが深層学習 (DL / Deep Learning) です。 深層学習は、人間の脳の働きを模した方法でデータを処理する手法 (ニューラルネットワーク) を用いることで、画像認識や自然言語処理といった複雑なタスクを自動化できます。 大量のデータから自動的に特徴量を抽出して学習できる点が大きな特徴です。
深層学習は以下のようなアプリケーション、サービスなどに利用されています。
- チャットボット
- 医療画像診断
- 自動翻訳
- 自動顔認識
- 生成 AI
これらから分かるように、AI は大きな概念であり、その実現のための中核的な技術が機械学習という位置付けです。 そして機械学習の中でも特に高度な手法が深層学習と捉えることができます。 生成 AI は、これらの技術を応用して新しいコンテンツを生成しています。

それでは、次に生成 AI についてもう少し詳しく整理してみます。
モデルとは
生成 AI には「モデル」という概念があります。
基盤モデル (FM / Foundation Model)
基盤モデルは、大量の多様なデータで事前にトレーニング (大量のデータからパターンを学習すること) され、 言語の理解、テキストや画像の生成、自然言語での会話など、さまざまなタスクに適応できるモデルです。 基盤モデルを利用しているサービスとしては ChatGPT、Gemini、Claude などがありますが、更に基盤モデルにもいくつか種類があります。
大規模言語モデル (LLM / Large Language Models)
従来の言語モデルを遥かに超える膨大なデータと巨大なパラメーター数で学習された AI です。 膨大なパラメーターにより文脈を深く理解し、人間のような自然で多様な文章生成や、質問応答、要約、翻訳、創作など、高度な言語タスクを実行できます。 その根幹にあるのは、入力されたテキストや、それまでに生成された単語 (トークン) の並びに基づき、次に続く単語として最も確率の高い候補を予測するという処理です。 この予測と生成を繰り返すことで、まとまった長い文章やコードなどを出力しています。
マルチモーダルモデル (MMM / Multimodal Model)
テキスト、画像、音声、動画など、複数の異なる種類のデータを同時に理解し、それらを連携させて処理できる AI モデルです。 テキストのみを扱う LLM など、単一のデータ種類に特化したモデルとは異なり、異なるモダリティ (情報の種類 (テキスト、画像、音声など) のこと) 間の関係性を捉えたり、 あるモダリティの入力 (例: 画像) から別のモダリティの出力 (例: 説明文テキスト) を生成したりできます。
拡散モデル (DM / Diffusion Model)
主に写実的で高品質な画像や、音声を生成することができる AI モデルです。 このモデルは、データ (例えば画像) にノイズを少しずつ加えていく過程 (順拡散) と、その逆を学習し、 ランダムなノイズから段階的にノイズを取り除いて元のデータに似たクリアな新しいデータを生成する過程 (逆拡散) に基づいています。
※拡散モデルを使った画像生成 aws.amazon.com
敵対的生成ネットワーク (GAN / Generative Adversarial Network)
新しいデータを生成する AI モデルの一種です。「生成器 (Generator)」と「識別器 (Discriminator)」という、互いに競い合う 2つ のネットワークから成ります。 生成器は本物らしいデータを生成しようとし、識別器はそれが本物か偽物かを見分けようとします。 この敵対的な学習プロセスを通じて、生成器は識別器を騙せるほど高品質なデータを生成できるようになります。 特に、写実的な画像生成の分野で大きな成果を上げています。
モデルで使われる用語
モデルで使われる用語について簡単に説明します。モデルの特徴を把握するのに便利なので、概要を押さえておきましょう。
以下に各用語を使った「LLM におけるユーザー入力から回答を得るまでの流れ」を図にしました。あくまで用語をイメージしやすくするための概略図であることをご理解ください。
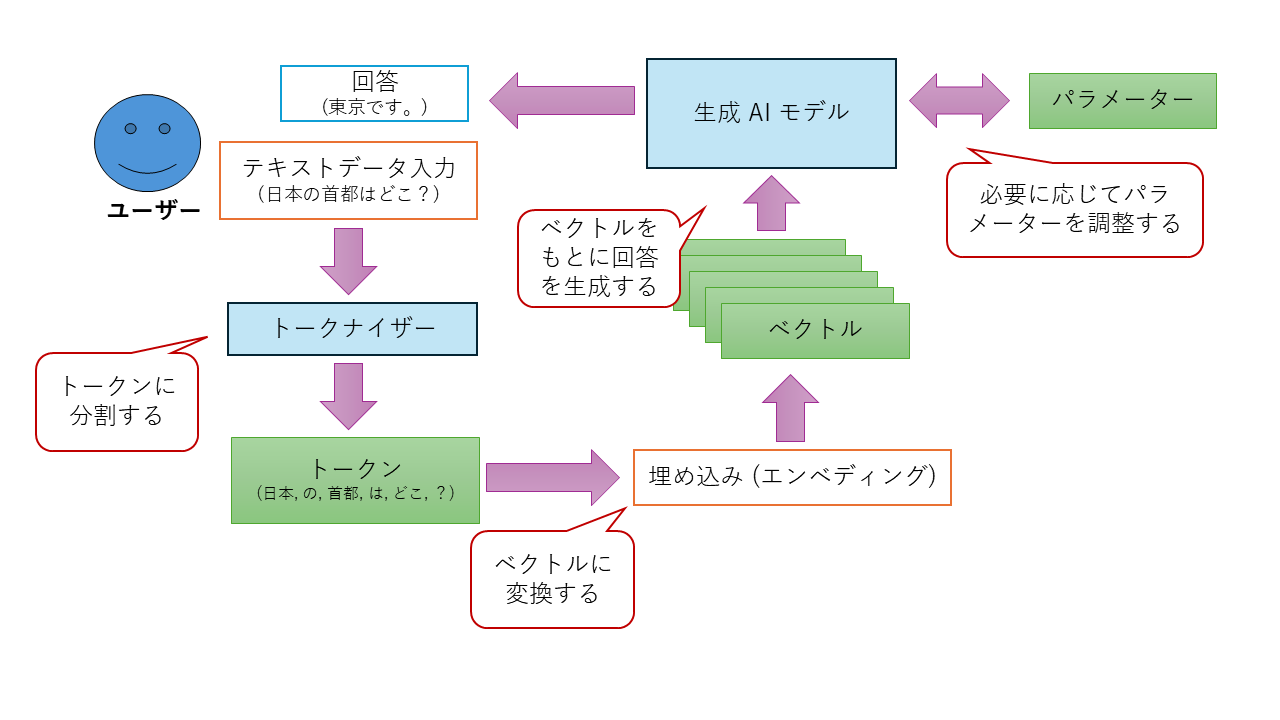
パラメーター
パラメーターとは、多くのモデルに存在する、学習可能な設定値 (変数) のことです。 モデルが訓練データから学習した知識やデータ内のパターンは、最終的にパラメーターの数値として蓄えられます。 モデルの学習とは、このパラメーターを最適な値に調整していくプロセスです。 モデルの規模を示す指標として「パラメーター数が多い=モデルが大きい」と表現されることが一般的で、大規模モデルほど多くのパラメータを持っています。
トークン
トークンとは、モデルがテキストデータを意味のある最小単位に分けたものです。 単語全体、単語の一部 (e.g.)「私」「は」「会社」「に」...) 、句読点、記号、あるいは特定の文字の並びなどがトークンとして定義されます。 元の文章は、モデルに入力される前に「トークナイザー」という専用の処理器によってこれらのトークンの列に分解されます。 モデルは、このトークン列を基にして言語の構造や文脈を理解し、次に続くトークンを予測したり、新しいトークン列 (文章) を生成したりします。 モデルが一度に処理できるテキストの長さ (コンテキストウィンドウのサイズ) は、しばしばトークン数で計測されます。
埋め込み (エンベディング)
埋め込み (エンベディング) とは、単語や画像などの情報を AI が理解しやすいように、ベクトル (意味的な関係性を保持した数値の集まり) に変換する技術です。 このベクトルの要素数を次元数と呼びます。次元数はモデルによって異なり、数百から数千にもなります。 高い次元数を持つことで、より複雑で微妙な意味の違いを表現できますが、その分計算コストも増加します。 AI は、この埋め込みによって得られたベクトルを使って情報の意味の近さを計算し、文章生成などのタスクをこなします。
生成 AI のモデル例
生成 AI のモデルは、今や正確な数を把握するのが困難なほど世に溢れています。 今回は生成 AI (Gemini) 自身に Amazon Bedrock で利用可能な生成 AI モデルについて「概要・特徴・主なメリット」を踏まえて一覧化して貰いました。
主要な生成AIモデル 詳細一覧
Amazon Bedrock で利用可能な主な生成AIモデルについて、モデル名 (バージョン含む) と、その概要・特徴・主なメリットを以下の表にまとめました。
| モデル名 (バージョン含む) | 概要・特徴・主なメリット |
|---|---|
| AI21 Labs | |
| Jamba 1.5 Large (ai21.jamba-1-5-large-v1:0) | テキスト生成、チャット。自然な対話や多様なテキストコンテンツ作成に適しています。ストリーミング対応。 |
| Jamba 1.5 Mini (ai21.jamba-1-5-mini-v1:0) | テキスト生成、チャット。Jamba Largeより小型で、効率的ながら高品質なテキスト処理を必要とするタスク向け。ストリーミング対応。 |
| Jurassic-2 Mid | テキスト生成。バランスの取れた性能で、記事作成、要約、質疑応答など、幅広い用途に対応可能です。 |
| Jurassic-2 Ultra | テキスト生成。シリーズ最高性能モデルの一つで、より複雑な指示理解や長文生成、創造的なライティングタスクで強みを発揮します。 |
| Amazon | |
| Nova Canvas (amazon.nova-canvas-v1:0) | テキストや画像からの画像生成。マーケティング素材、アート作品、製品デザインなどのビジュアルコンテンツ作成を支援します。 |
| Nova Lite (amazon.nova-lite-v1:0) | テキスト、画像、動画からのテキスト生成。マルチモーダルな入力から状況を理解し、説明文やレポートを生成できます。ストリーミング対応。 |
| Nova Micro (amazon.nova-micro-v1:0) | テキストからのテキスト生成。軽量で高速な応答が求められるシンプルなテキストタスクに適しています。 |
| Nova Pro (amazon.nova-pro-v1:0) | テキスト、画像、動画からのテキスト生成。Nova Liteより高度なマルチモーダル理解とテキスト生成能力を持ち、複雑な分析や詳細なレポート作成に対応。 |
| Nova Reel (amazon.nova-reel-v1:0, v1:1) | テキストや画像からの動画生成。プロモーションビデオ、教育コンテンツ、ストーリーテリングなど、動的なビジュアルコンテンツを容易に作成できます。 |
| Nova Sonic (amazon.nova-sonic-v1:0) | 音声からの音声変換およびテキスト生成。音声アシスタント、文字起こし、音声翻訳など、音声関連のアプリケーション開発に活用できます。 |
| Rerank 1.0 (amazon.rerank-v1:0) | テキストのリランキング。検索結果や推薦リストの関連性を向上させることに特化しており、ユーザー体験の最適化に貢献します。 |
| Titan Embeddings G1 - Text (amazon.titan-embed-text-v1) | テキスト埋め込み。セマンティック検索、クラスタリング、レコメンデーションなど、テキスト間の意味的な類似性に基づいた処理の基盤となります。 |
| Titan Image Generator G1 / G1 v2 (amazon.titan-image-generator-v1, v2:0) | テキストや画像からの画像生成。高品質な画像を生成でき、広告、デザイン、エンターテイメントなど多様な分野で活用可能です。 |
| Titan Multimodal Embeddings G1 (amazon.titan-embed-image-v1) | マルチモーダル埋め込み (テキスト、画像)。テキストと画像を共通のベクトル空間に表現し、画像検索、画像キャプション生成などの高度なタスクを実現します。 |
| Titan Text G1 - Express | テキスト生成。幅広いタスクに対応し、応答速度と品質のバランスが良いモデルです。 |
| Titan Text G1 - Lite | テキスト生成。Expressより軽量で、大量処理やコスト効率が重視されるシナリオに適しています。 |
| Anthropic | |
| Claude Opus 4 (NEW) | Anthropicの最新・最強モデル。市場最高レベルのコーディング能力を持ち、複雑なタスクの推論・計画・実行が可能なAIエージェント構築に最適。ソフトウェア開発、長期タスク、戦略分析、高度な研究で優れたパフォーマンスを発揮。 |
| Claude Sonnet 4 (NEW) | Claude Sonnet 3.7を上回る次世代モデル。 コーディングと推論能力が向上し、性能とコストのバランスが良い。リアルタイム応答と深い思考のハイブリッド。RAG、コードレビュー、サポートエージェントなど、本番環境での多くのユースケースに最適。 |
| Claude 3 Opus (Previous Gen) | (旧Opus 4) 高度なタスク、戦略分析、研究などで高いパフォーマンスを発揮した前世代モデル。 |
| Claude 3 Sonnet (Previous Gen) | (旧Sonnet 4) スキルとスピードのバランスが取れていた前世代モデル。 |
| Claude 3 Haiku | 高速・コンパクトで応答性に優れ、カスタマーサポートのチャットボット、コンテンツモデレーション、迅速な要約などに適しています。 |
| Cohere | |
| Command R / R+ | RAG(検索拡張生成) とツール連携に最適化。実用的で信頼性の高い大規模言語モデル。R+はエンタープライズ規模のワークロードに対応。 |
| Command / Command Light | テキスト生成、指示応答、要約。多言語対応。ビジネス文書作成、チャットボットなど幅広い用途。Lightはより高速・低コスト。 |
| Embed English / Multilingual | テキストの埋め込み生成。セマンティック検索、クラスタリング、多言語間の意味理解向上。特にMultilingualは100以上の言語に対応。 |
| DeepSeek (NEW) | |
| (モデル名詳細不明) | オープンソースで強力なモデル (特にコーディングと数学) で知られる組織。Bedrock上の具体的なモデルと特徴はドキュメント参照。(一般的な知識に基づく) |
| AI21 Labs | |
| (Jambaモデル群) | (上記参照) |
| (Jurassic-2モデル群) | (上記参照) |
| Luma AI (NEW) | |
| (モデル名詳細不明) | 高品質な3Dコンテンツ生成や動画生成AIで知られる組織。Bedrock上では動画生成などの機能が期待されます。(一般的な知識に基づく) |
| Meta | |
| Llama 3.1 / 3.2 (NEW) | Llama 3の更新版。性能向上、新しい機能(例:ツール使用の改善など) が期待されます。(一般的な知識に基づく) |
| Llama 3 Chat (8B, 70B) | Llama 2の後継で、対話性能が向上。指示追従性や推論能力が強化され、より自然で有用なチャット体験を提供。オープンソース (条件あり) 。 |
| Llama 3 Text (8B, 70B) | Llama 2の後継で、テキスト生成能力が向上。一般的な知識、推論、コーディング能力などが強化。オープンソース (条件あり) 。 |
| Llama 2 Chat / Text (13B, 70B) | 高性能なテキスト生成・対話モデル。オープンソース (条件あり) 。研究開発、カスタムモデルの基盤として広く利用。 |
| Mistral AI | |
| Mistral AI 大規模 (24.07) (NEW) | Mistral Largeの可能性が高いですが、バージョン名が新しく、最新の性能向上が期待されます。(一般的な知識に基づく) |
| Pixtral Large (25.02) (NEW) | Mistral AIによる画像と言語のマルチモーダルモデルの可能性。テキストと画像を扱えるタスクが期待されます。(一般的な知識に基づく) |
| Mistral Large | Mistral AIのフラッグシップモデルの一つ。高度な推論能力、長文コンテキスト処理、多言語対応に優れています。 |
| Mixtral 8x7B Instruct | 高品質かつ高速なMoE (Mixture of Experts) アーキテクチャ採用。複雑な指示や長文の理解に優れています。 |
| Mistral 7B Instruct | 高効率な指示応答モデル。小型ながら高い性能を持ち、コストパフォーマンスに優れています。 |
| Stability AI | |
| Stable Diffusion 3 (NEW) | Stability AIの最新画像生成モデル。テキストプロンプトの理解度、画像品質、複数の被写体やテキストの描画能力が大幅に向上。(一般的な知識に基づく) |
| Stable Image Ultra | Stability AIの最先端画像生成モデル。最高の品質と忠実度を追求し、プロフェッショナルなクリエイティブ用途向け。 |
| Stable Image Core | 高速かつ高品質な画像生成・編集のためのコアモデル。多様なスタイルやコンセプトのビジュアルコンテンツを効率的に作成可能。 |
| Stable Diffusion XL1.0 | テキストからの高品質な画像生成、画像編集。リアルで詳細な画像生成が可能。 |
注:
- この表は、本日時点で確認できた情報およびご提供いただいたブログ記事の内容に基づいていますが、Amazon Bedrockのモデルラインナップは頻繁に更新されるため、これが常に最新かつ完全なリストであることを保証するものではありません。
- 特に (NEW) と記されたモデルや、概要が「一般的な知識に基づく」となっているモデルについては、今後詳細な情報が変更・追加される可能性があります。
- 「概要・特徴・主なメリット」は、AWSの公式ドキュメントの情報と、各モデルに関する一般的な公開情報に基づいており、特定のユースケースにおける最適性を保証するものではありません。
- モデルの選択は、具体的な要件(タスクの種類、必要な精度、応答速度、コストなど) に応じて行う必要があります。
- 最新かつ詳細な情報、各モデルの利用規約については、AWSの公式ドキュメントを直接ご参照ください。
AWS における生成 AI サービス
それでは、AWS において 生成 AI はどのように活用されているのでしょうか?
生成 AI アプリケーションを構築するため、基盤モデルを活用しています。
生成 AI を使用するアプリケーションにより、AWS を利用することで、データ、ユースケース、顧客にあわせて生成 AI を簡単に構築およびスケールすることができます。
aws.amazon.com
生成 AI が利用できるサービスにおいて、以下のように 3つ にカテゴリを分けて説明していきます。
- 開発者向けサービス
- 生成 AI アプリケーションを作成したい人向け
- 研究者向けサービス
- 生成 AI モデルを開発したり、機械学習する上で必要な環境を用意する
- アプリケーションとしてすぐに使えるサービス
- 生成 AI アプリケーションをとにかくすぐに使いたい人向けのサービス
| AWS サービス | 開発者向け | 研究者向け | アプリとして すぐに使える |
|---|---|---|---|
| Amazon Bedrock | ● | ||
| Amazon SageMaker | ● | ● | |
| Amazon Q Business | ● | ● | |
| Amazon Q Developer | ● | ||
| PartyRock | ● | ||
| AWS HealthScribe | ● | ||
| AWS Transform | ● | ||
| Amazon Comprehend | ● | ||
| AWS Amplify Studio | ● | ||
| Amazon Kendra | ● | ||
| Amazon Transcribe | ● | ||
| Amazon Personalize - Content Generator | ● | ||
| Amazon Polly | ● | ||
| Amazon Textract | ● | ||
| Amazon Rekognition | ● | ||
| Amazon Lex | ● |
各サービスの一覧・概要
Amazon Bedrock
- サービス概要: 大規模言語モデル (LLM) やその他の基盤モデル (FM) を単一のAPIで利用可能にするフルマネージド型サービスです。Amazonや主要なAIスタートアップの高性能なモデルを選択し、生成AIアプリケーションを構築・スケールできます。
- サービス名由来: 「Bedrock」は「基盤岩」や「基礎」を意味します。様々な基盤モデルを利用するための「基盤」となるサービス、という位置付けから名付けられたと考えられます。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: テキスト生成、チャットボット、検索、要約、画像生成など、多様な生成AIタスクを実行できる基盤モデルへのアクセスを提供します。ユーザーはこれらのモデルをカスタマイズし、自社のデータでファインチューニング (トレーニング済み AI を、特定のタスクに合わせて追加トレーニングで微調整すること) することも可能です。
- 参考ブログ:
Amazon SageMaker
- サービス概要: 機械学習モデルを大規模に構築、トレーニング、デプロイするための包括的なプラットフォームです。データの準備からモデルのデプロイ、モニタリングまで、機械学習ライフサイクル全体をサポートします。
- サービス名由来: 「Sage」は「賢人」「賢者」を意味します。「Maker」は「作り手」。合わせて「賢いもの (AI / MLモデル) を作るためのツール」や「賢人が使うツール」といった意味合いが込められていると推測されます。
- カテゴリ: 開発者向けサービス、研究者向けサービス
- 生成 AI をどのように利用しているのか: 基盤モデルを含むさまざまな機械学習アルゴリズムやフレームワークを利用して、カスタムモデルのトレーニングやファインチューニングが可能です。生成AIモデルの開発や実験、デプロイメントパイプラインの構築を支援します。
- 参考ブログ:
Amazon Q Business
- サービス概要: Amazon Q Business は、企業の従業員が社内情報やデータに簡単にアクセスし、質問への回答を得たり、コンテンツを要約したり、タスクを自動化したりすることを支援する、生成AIを活用した新しいタイプのアシスタントです。企業独自のデータソース (ドキュメントリポジトリ、CRM、イントラネットなど) に接続し、それらの情報を基にパーソナライズされた情報提供や業務支援を行います。
- サービス名由来: 「Q」は「Question (質問)」や「Query (問い合わせ)」の頭文字を連想させます。ビジネスに関する様々な質問に、AI が答えてくれるアシスタントであることを示しています。
- カテゴリ: アプリケーションとしてすぐに使えるサービス (従業員向け) 、開発者向けサービス (管理者や開発者がデータソース連携やカスタマイズを行うため)
- 生成 AI をどのように利用しているのか: Amazon Q Business は、中核機能として大規模言語モデル (LLM) などの生成AI技術を活用しています。主な利用方法は以下の通りです。
- 自然言語による質問応答: 従業員が自然言語で質問すると、社内の様々なデータソースから関連情報を検索・抽出し、要約された回答や必要な情報を生成します。
- コンテンツ作成支援: レポートの下書き、メールの作成、プレゼンテーションのアウトライン作成など、様々なビジネスコンテンツの生成を支援します。
- データ分析と洞察の抽出: 接続されたデータソースから傾向を分析したり、キーポイントを抽出したりして、ビジネス上の意思決定をサポートする情報を生成します。
- タスク自動化: 定型的な業務プロセスに関する問い合わせ対応や情報提供などを自動化します。
- パーソナライズ: ユーザーの役割やアクセス権限に基づいて、関連性の高い情報を提供します。
- 参考ブログ:
Amazon Q Developer (旧 Amazon CodeWhisperer)
- サービス概要: Amazon Q Developer プログラムに統合された AI コーディングコンパニオンです。開発者がコードを生成、テスト、デバッグするのを支援し、開発の生産性を向上させます。旧 Amazon CodeWhisperer の機能を含みます。
- サービス名由来: 「Q」は「Question (質問)」や「Query (問い合わせ)」の頭文字を連想させます。「Developer」は開発者向けであることを示し、開発に関する質問への回答、コード生成、デバッグ支援などを行う AI アシスタントであることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: コード生成、コードの提案、デバッグ支援、脆弱性スキャン、Amazon Q を活用したチャット形式でのQ&Aや機能開発支援など、ソフトウェア開発ライフサイクル全体で生成AIを活用します。
- 参考ブログ:
PartyRock
- サービス概要: 生成系AIアプリケーションを楽しく、直感的に構築できる AWS のサービスです。コーディングの知識がなくても、テキストベースのインターフェースを通じて、様々な生成AIモデルを組み合わせてアプリケーションを作成・実験できます。
- サービス名由来: 「Party」(パーティー) と「Rock」(ロック、岩) を組み合わせた、遊び心のある名前です。「誰でも簡単に、楽しく生成 AI アプリを作って、パーティーのように盛り上がろう」といったコンセプトが込められていると考えられます。Bedrockの「Rock」とかけている可能性もあります。
- カテゴリ: アプリケーションとしてすぐに使えるサービス
- 生成 AI をどのように利用しているのか: テキスト生成、画像生成、質問応答など、様々な AI モデルを組み合わせて、ユーザーが独自のアプリケーションを構築できるようにします。ユーザーはプロンプトエンジニアリングを通じて、モデルの振る舞いを制御し、特定のタスクに特化したAIツールを作成可能です。
- 参考ブログ:
AWS HealthScribe
- サービス概要: 医療業界向けのサービスで、音声認識と自然言語理解 (NLU) 技術を利用して、医師と患者の会話をリアルタイムで文字起こしし、構造化された臨床記録を生成します。
- サービス名由来: 「Health」は「健康・医療」を、「Scribe」は「書記官」「筆記者」を意味します。医療現場での会話 (Health) を AI が聞いて書き起こし (Scribe)、記録を作成するサービスであることを直接的に表しています。
- カテゴリ: アプリケーションとしてすぐに使えるサービス
- 生成 AI をどのように利用しているのか: 音声認識と自然言語理解を活用し、医療専門用語を理解して会話を分析。要約された臨床ノートや構造化されたデータを生成し、電子カルテ (EHR) システムへの入力を効率化します。
- 参考ブログ:
AWS Transform (旧 Amazon Q Developer transformation)
- サービス概要: AWS Transform は、企業が持つさまざまなレガシーシステムやアプリケーションを AWS クラウドへ効率的にモダナイズ (近代化) することを支援するために設計された、生成AIを活用した新しいサービス群です。このサービスは、特定の技術スタックやプラットフォームに特化した複数のコンポーネントで構成されており、現状では「AWS Transform for .NET」、「AWS Transform for mainframe」、「AWS Transform for VMware」などが提供されています。開発者やITプロフェッショナルが、複雑で時間のかかるモダナイゼーションプロジェクトを、AIによる分析、コード変換の提案、自動化されたプロセスを通じて加速させることを目的としています。
- サービス名由来: 「Transform」は「変革する」「変換する」という意味です。レガシーなアプリケーションやシステムを、AWS 上のモダンな環境へ「変換・変革」するのを支援するサービスであることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: AWS Transform は、その各コンポーネントにおいて、生成AI (特に大規模言語モデル) を中核的な技術として活用し、モダナイゼーションの各ステップを支援します。
- AWS Transform for .NET:
- コード分析と変換: 古い .NET Framework で書かれたアプリケーションを分析し、最新のクロスプラットフォーム .NET (例: .NET 8) への変換を支援します。AIがコードの依存関係を理解し、APIの互換性問題の特定、推奨されるコード変更の提案、さらにはコードの一部自動生成やリファクタリングを行います。
- 対話型アシスタンス: 開発者はAIエージェントと対話しながら、変換オプションの選択やカスタマイズを行うことができます。
- AWS Transform for mainframe:
- レガシーコードの理解と変換: COBOLなどのメインフレーム言語で書かれたアプリケーションを分析し、Javaなどのモダンな言語やアーキテクチャへの変換を支援することが期待されます。生成AIは、複雑なビジネスロジックの解読、データ構造の移行計画、新しい言語でのコード生成などに利用される可能性があります。
- 移行戦略の策定支援: アプリケーションの特性や依存関係を評価し、最適な移行パスやリファクタリング戦略の策定を支援する可能性があります。
- AWS Transform for VMware:
- 移行評価と計画: オンプレミスのVMware環境で稼働しているワークロードをAWSへ移行する際の評価を自動化し、最適な移行戦略 (リホスト、リプラットフォーム、リファクタリングなど) の策定を支援することが考えられます。
- 設定変換やスクリプト生成: 移行に必要な設定ファイルの変換や、自動化スクリプトの生成などに生成AIが活用される可能性があります。共通して、AWS Transform は生成AIを用いて、手作業によるエラーを削減し、モダナイゼーションのプロジェクト期間を短縮し、より迅速なクラウドネイティブ化を実現することを目指しています。ユーザーはAIとの対話やガイダンスを通じて、複雑な意思決定をサポートされながら、移行プロセスを進めることができます。
- AWS Transform for .NET:
Amazon Comprehend
- サービス概要: 自然言語処理 (NLP) サービスです。テキストデータから洞察を抽出します。エンティティ認識、キーフレーズ抽出、感情分析、言語検出、トピックモデリングなどの機能を提供。
- サービス名由来: 「Comprehend」は「理解する」という意味の英単語です。テキスト (自然言語) の内容を深く「理解」し、そこから意味や洞察を引き出すサービスであることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: テキスト分析に機械学習モデルを活用。カスタムエンティティ認識やカスタム分類モデルをトレーニングすることで、特定のニーズに合わせたテキスト分析が可能。顧客からのフィードバック分析、コンテンツの分類、情報検索の強化などに利用されます。
- 参考ブログ:
AWS Amplify Studio (旧 AWS App Studio)
- サービス概要: ローコードでフルスタックのウェブおよびモバイルアプリケーションを構築できるビジュアル開発環境です。Figma デザインからコードを生成したり、バックエンド機能を簡単に設定したりできます。
- サービス名由来: 「Amplify」は「増幅する」「拡大する」という意味です。開発プロセスを「増幅」し、加速させることを目指すツールであることを示唆しています。「Studio」は、開発のための統合環境やツールセットであることを意味します。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: バックエンドのデータモデリングやAPI作成、認証機能などを自動生成する機能において、生成AIが活用されている可能性があります。また、UIコンポーネントの生成や、自然言語による指示からのコード生成など、開発プロセスを効率化する目的で生成AIが組み込まれていると考えられます。
- 参考ブログ:
Amazon Kendra
- サービス概要: インテリジェントなエンタープライズ検索サービスです。自然言語処理 (NLP) と機械学習アルゴリズムを使用して、構造化および非構造化データソースから情報を検索し、より関連性の高い検索結果を提供します。
- サービス名由来: 「Kendra」は、特定の技術用語ではなく、人名のような響きを持っています。これは、ユーザーが自然言語で質問すると、必要な情報を「見つけ出してくれる」賢いアシスタントのような存在を目指していることを示唆している可能性があります。覚えやすく、親しみやすい名前として選ばれたと考えられます。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: 自然言語による質問に対して、関連性の高いドキュメントや情報を抽出・提示します。FAQの自動応答、ドキュメント検索、ナレッジマネジメントシステムの構築などに活用されます。セマンティック検索やランキング機能により、従来のキーワード検索よりも高度な情報検索を実現します。
- 参考ブログ:
Amazon Transcribe
- サービス概要: 自動音声認識 (ASR) サービスです。音声ファイルをテキストに変換します。リアルタイムおよびバッチ処理に対応し、様々な言語の音声認識が可能です。医療、コールセンター、メディアなど、様々な分野で活用されます。
- サービス名由来: 「Transcribe」は「書き起こす」「文字に起こす」という意味です。音声データをテキストに「書き起こす」サービスであることを非常に分かりやすく示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: 音声データから高精度なテキストを生成します。話者ダイアライゼーション (誰が話しているか識別) 、カスタム語彙、句読点付加などの機能を提供。生成AIを活用して、文字起こしの精度向上や、特定の業界・分野に特化した音声認識モデルの構築を支援していると考えられます。
- 参考ブログ:
Amazon Personalize - Content Generator
- サービス概要: パーソナライゼーションサービスである Amazon Personalize の機能拡張です。顧客の行動データやコンテキスト情報を活用して、パーソナライズされたコンテンツ (例:製品推奨、マーケティングメッセージ、検索結果など) を大規模に生成します。
- サービス名由来: これは機能名をそのままサービス名にした形です。「Personalize」(個別化) された「Content」(コンテンツ) を「Generator」 (生成するもの) という意味で、個々のユーザーに合わせたコンテンツを生成する機能であることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: 機械学習モデルを使用して、ユーザーの過去の行動、コンテキスト、アイテム間の類似性に基づいて、個々のユーザーに最適化されたコンテンツを生成します。これにより、エンゲージメント向上やコンバージョン率改善を目指すことができます。具体的には、ユーザーの興味関心に合わせた製品説明文の生成、パーソナライズされたマーケティングコピーの作成などに利用されると考えられます。また、基盤モデル (LLM) と連携し、ユーザーとドキュメント間のインタラクションを分析して、よりパーソナライズされたコンテンツ生成を可能にします。
- 参考ブログ:
Amazon Polly
- サービス概要: テキストをリアルで自然な音声に変換するテキスト読み上げ (TTS) サービスです。多様な言語と音声に対応し、アプリケーションに音声機能を簡単に追加できます。
- サービス名由来: 「Polly」は、英語圏でオウムによく付けられる名前です。「Polly wants a cracker. (ポリーはクラッカーが欲しい)」という慣用句が有名で、オウムが人の言葉を真似て「話す」ことから、テキストを音声として「話す」サービスにこの名前が付けられたと考えられます。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: ニューラルネットワークベースの音声合成技術 (NTTS) を利用しており、これは広義の生成AIの一種と捉えられます。従来の機械的な音声ではなく、人間のような自然で表現力豊かな音声を生成します。イントネーションや感情表現の調整も可能です。
- 参考ブログ:
Amazon Textract
- サービス概要: スキャンされたドキュメントや画像からテキスト、手書き文字、フォームデータ、テーブルなどを自動的に抽出するサービスです。OCR (光学文字認識) 技術をベースに、より高度なドキュメント分析機能を提供します。
- サービス名由来: 「Text」(テキスト) と「Extract」(抽出する) を組み合わせた造語です。ドキュメントからテキストデータを「抽出」するサービスであることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: 主な機能は抽出と分析ですが、抽出された情報を基に構造化されたデータ (例: JSON形式のフォームデータ) を「生成」するという側面があります。また、Amazon Bedrock のような生成 AI サービスと連携して、抽出された情報から要約を作成したり、質問応答システムを構築したりすることが可能です。Textract 自体がコンテンツをゼロから創造するわけではありませんが、データ変換の過程で新しい形式の情報を生成します。
Amazon Rekognition
- サービス概要: 画像および動画分析サービスです。物体、人物、テキスト、シーン、アクティビティの検出、顔認識、不適切コンテンツの検出などが可能です。
- サービス名由来: 「Recognition」(認識) という単語を少しもじった名前です ("Recognition" -> "Rekognition")。画像や動画から物体、顔、シーンなどを「認識」するサービスであることを示しています。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: Rekognition のコア機能は分析と認識ですが、特定の機能 (例: 有名人の認識、カスタムラベルによる物体検出モデルのトレーニング) では高度な機械学習モデルが利用されています。直接的な「コンテンツ生成」とは異なりますが、分析結果を基にメタデータやタグを生成します。近年では、顔の比較や検索の精度向上などに深層学習モデルが活用されており、これは生成AIの基盤技術とも関連が深いです。
Amazon Lex
- サービス概要: 音声やテキストを使用して、アプリケーションに対話型インターフェースを構築するためのサービスです。チャットボットや音声アシスタントの作成に使用されます。
- サービス名由来: 「Lex」は「Lexicon」(語彙集) や「Lexis」(言語、語彙) を連想させます。会話型AIの基盤となる「言葉」や「対話のルール」を扱うサービスであることを示唆しています。また、Amazonの音声アシスタント「Alexa」との関連性も感じさせる名前です。
- カテゴリ: 開発者向けサービス
- 生成 AI をどのように利用しているのか: 自然言語理解 (NLU) と自動音声認識 (ASR) を活用してユーザーの意図を理解し、適切な応答を生成します。応答生成の部分では、定義済みの応答フローだけでなく、Amazon Bedrock のような生成AIモデルと連携して、より自然で文脈に応じた動的な対話を生成する能力が強化されています。これにより、より人間らしい会話体験を提供できます。
あとがき
AWS の生成 AI について (半分くらいは生成 AI を使って) 整理してみました。
今回は時間がなく図は自分で作りましたが、次回は生成 AI に作って貰いたいと思った兄でした。
それではまた、ごきげんよう。
高橋 悠佑 (ポインコ兄) (執筆記事一覧)
健康志向です