

はじめに
こんにちは、絶賛新卒 OJT 中の香取です。
先日人事部に OJT としてお邪魔していた際に、既にインタビューした音声をもとにブログ記事を作成するという作業を任していただくことがありました。
このインタビュー音声というのが 50 分近くあり、「これを全部聞いて文字に起こすのか~」と少し先が思いやられており、文字起こしツールを使ってみようかなと考えていました。
しかしなんと、 AWS には文字起こしのサービスがあるというではありませんか。
ということで、今回は技術検証もかねて Amazon Transcribe でこのインタビュー音声を文字起こしし、Amazon Transcribe の機能の一つである音声識別(誰が話しているかを区別してくれる機能)も使ってみました。
本記事でやること
- Amazon Transcribe を使用してインタビューの音声データを文字起こし
- 話者を識別した文字起こし
- Amazon Transcribe のアウトプットである JSON ファイルから必要な情報を抽出
- スクリプトを用いて体裁を整える(spk_0 を任意の文字列に変更したり)
本記事でやらないこと
- 文字起こしをした後のさらに細かい日本語の修正など
- 音声識別以外のオプションは使用しない
最終的にはこのような Amazon Transcribe のアウトプットである JSON ファイルから、
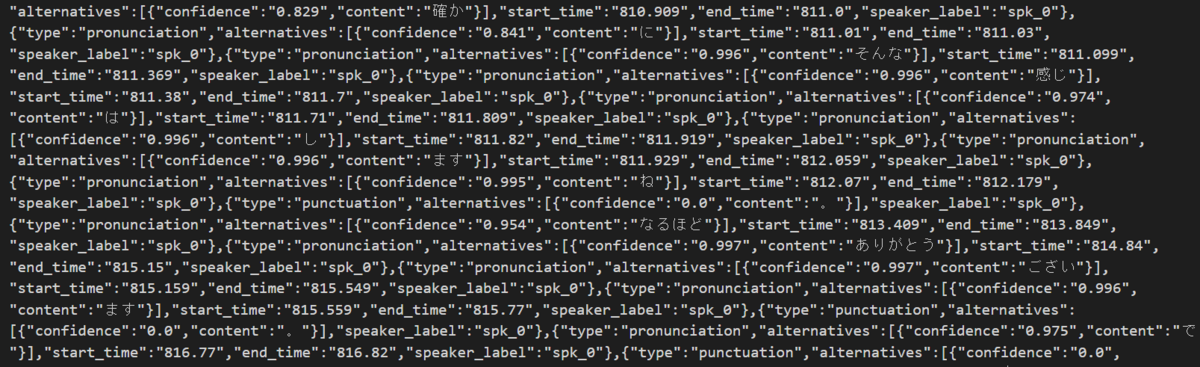
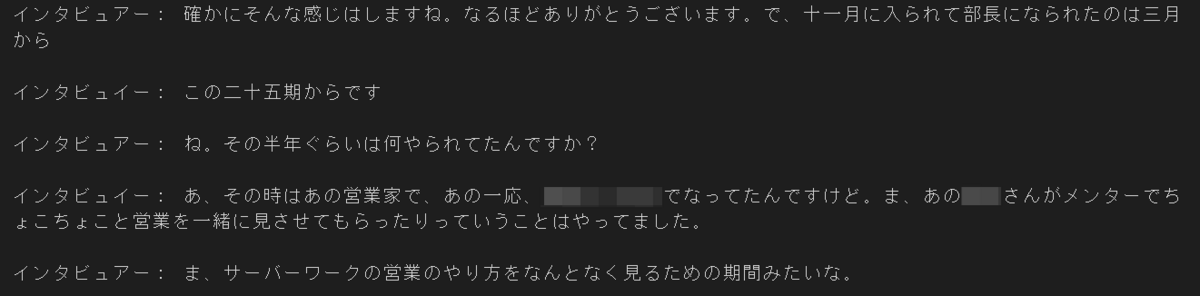
以下のように体裁を整えたアウトプットを目標として進めていきます(これ以降の修正は手作業となります)
文字起こしをやってみる
2-1. 今回使用した音声データ
今回使用した音声データは以下のようなものになります。
- 約 50 分、23 MB の M4A ファイル
- 登場人物はインタビュイーとインタビュアーの 2 人
- 対面で同じ場所で話をしている
ちなみに Amazon Transcribe は音声データの形式として、以下をサポートしているようです。
AMR、FLAC、M4A、MP3、MP4、Ogg、WebM、WAV
2-2. 音声データを S3 バケットにアップロード
まずは文字起こししたい音声データを S3 バケットにアップロードしましょう。
バケットが無い場合は先に作成しておきます。
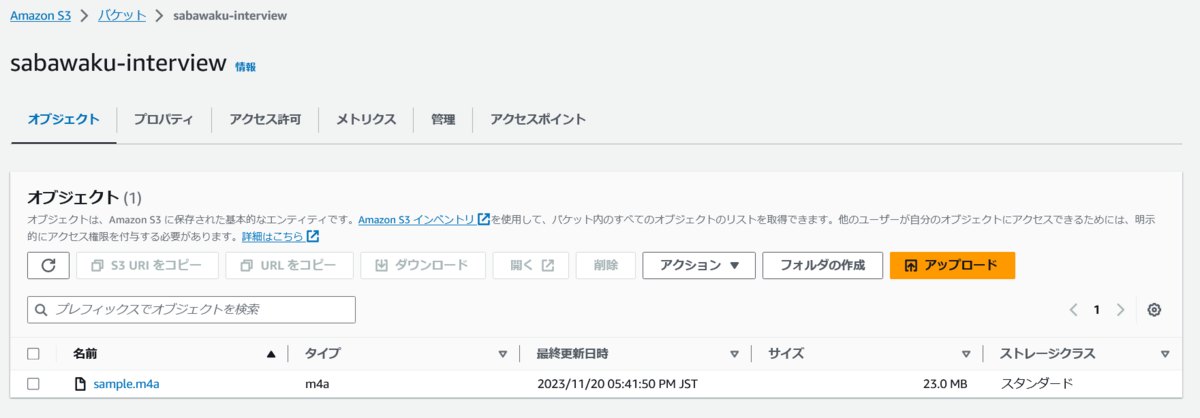
今回は「sabawaku-interview」というバケットを新たに作成し、その中に M4A ファイルをアップロードしました。
2-3. Amazon Transcribe でジョブを作成
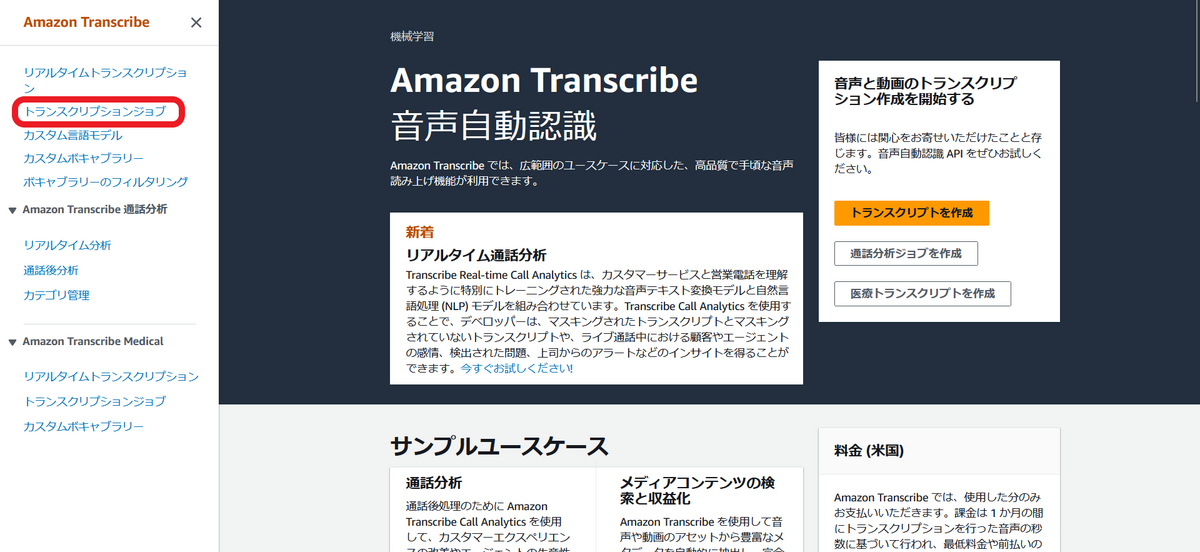
Amazon Transcribe では「トランスクリプションジョブ」というジョブを作成することで、S3 バケット内のオブジェクトに対して文字起こしを実行することができます。
AWS マネジメントコンソールから Amazon Transcribe にアクセスし、画面左側の「トランスクリプションジョブ」を選択してください。
任意の名前を入力します。
今回のインタビューは全て日本語で行われていますので、「特定の言語」「日本語」を選択しました。
選択肢を見ると Amazon Transcribe は複数言語の自動識別にも対応しているようですね。すごいです。
入力データでは「Browse S3」から、先ほど格納した S3 バケット内のオブジェクトを指定します。
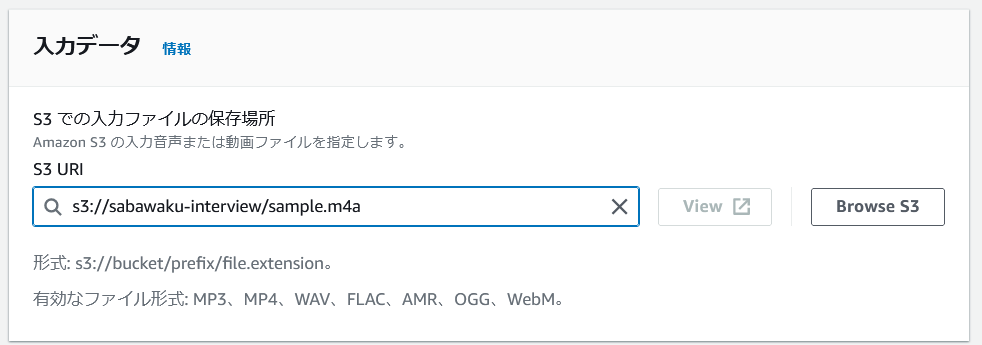
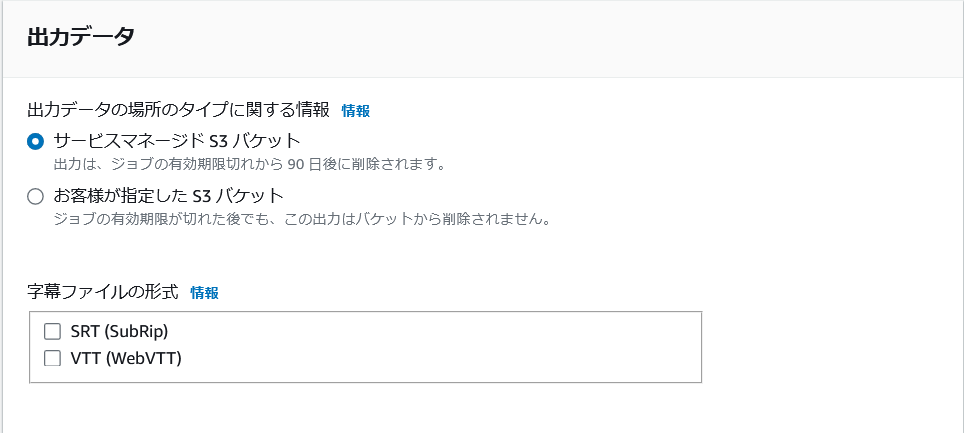
ジョブ実行結果の出力先として、今回はマネージドの S3 バケットを選択しています。
こちらはジョブの有効期限(90 日)から 90 日後、つまりジョブ作成から 180 日後には削除されてしまうのでご注意ください。
実行結果を S3 に長期間保持しておきたい場合は自前のバケットを指定しましょう。
最後に optional の設定です。ここでは「音声識別」を有効化しています。
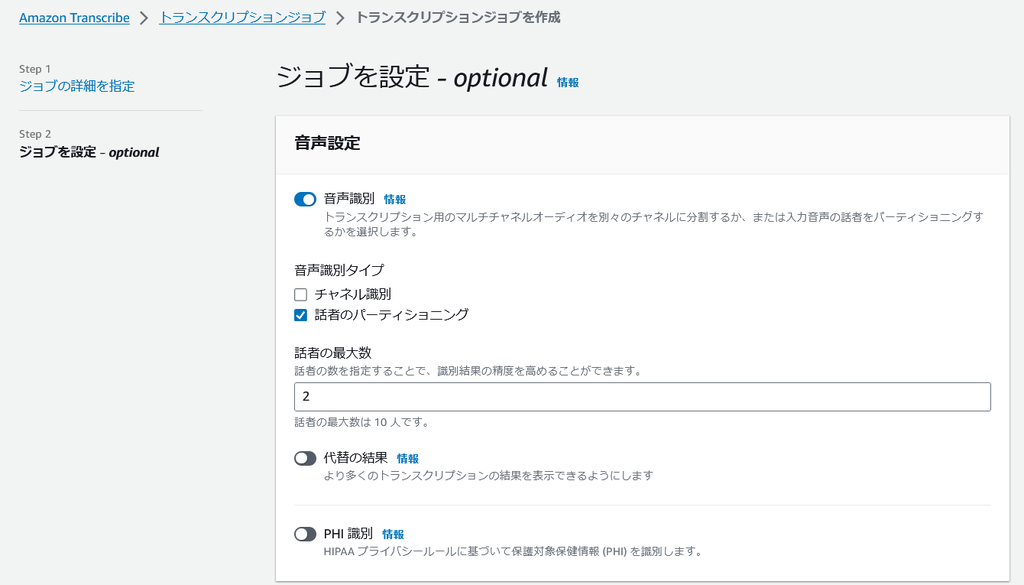
「音声識別」とは、データ中の ”声” を区別して、[spk_0] [spk_1] のような形で文字起こしに反映してくれる機能の事です。
今回のようなインタビュー記事の場合、発言しているのが 「インタビュアー」 と 「インタビュイー」 のどちらなのかが分かっていると非常に作業がスムーズですので有効にしてみました。
その下の「音声識別タイプ」では「話者のパーティショニング」にチェックを入れ、最大数を 2 人にします。(この人数を正確に指定してあげることで、文字起こしの精度が上がるそうです。)
ちなみに、もう一つの項目「チャネル識別」とは “話者の空間” を識別するかという項目で、例えば電話音声のような、それぞれの音質や背後のノイズが異なる、つまり空間が異なる音声の場合には、チャネル識別にチェックを入れると精度が上がるようです。今回は同じ空間で対面でのインタビュー音声だったため、チェックは外しています。
その他はデフォルトのままジョブを作成したら、あとはジョブの完了を待つのみです。
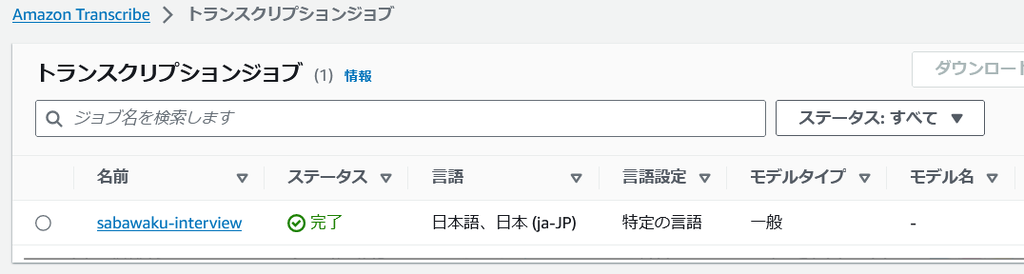
ご参考までに、今回の 23MB(50分)の音声データだと 5 分程度で完了しました。
2-4. ジョブ実行結果
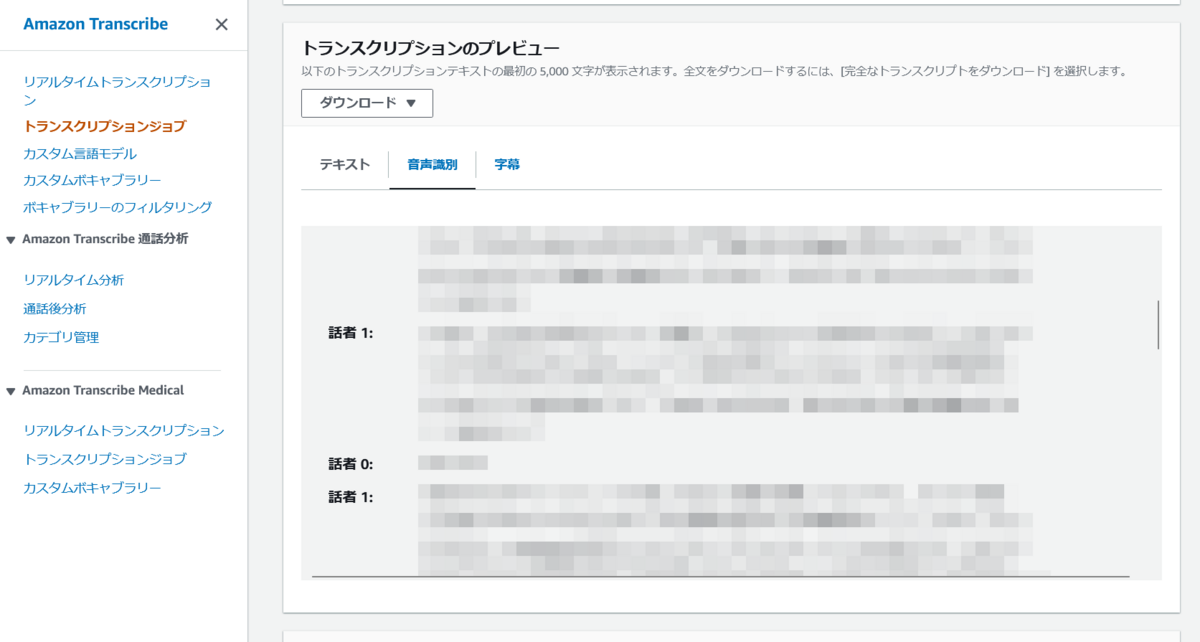
ジョブが完了したら、文字起こしのプレビューを確認することができます。
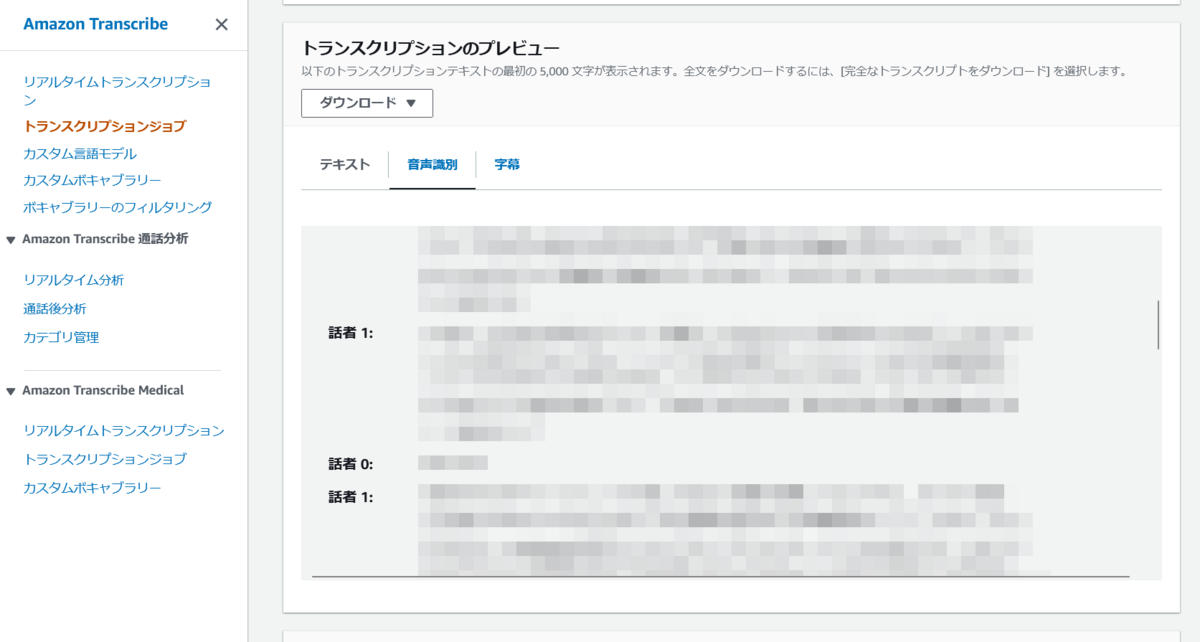
「話者 0」と「話者 1」を区別してくれていることが分かります。
ただ、このプレビュー画面では初めの 5000 文字しか確認できないので、実行結果のファイルをダウンロードする必要があります。
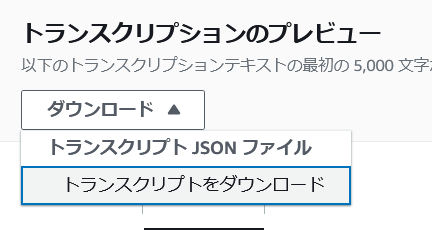
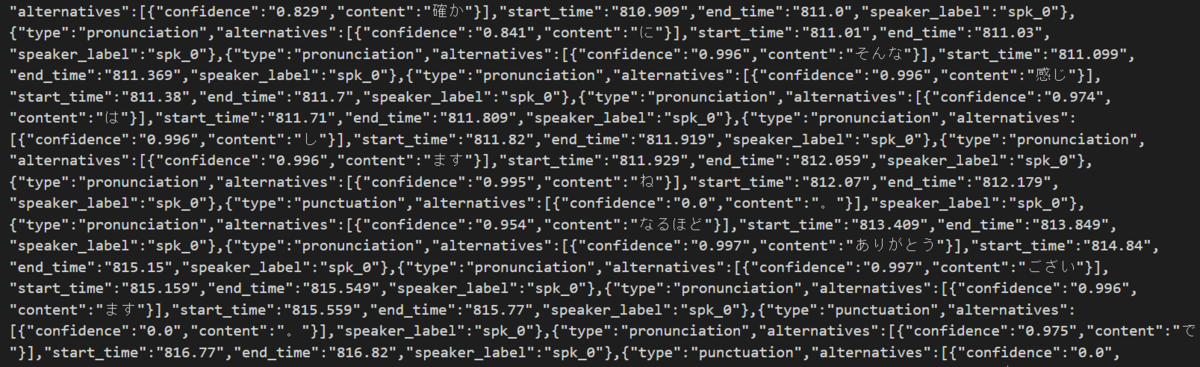
ダウンロードした「asrOutput.json」というファイルを確認してみると、プレビューのような見やすい形式ではなくなってしまいました。
なので、この JSON ファイルから必要な情報だけを取り出して、プレビューと同じように変換することにします。
2-5. JSON → テキストファイル への変換
話者識別を保ったまま、 JSON からテキストを取り出す公式のスクリプトなどが見当たらなかったため、以下のスクリプトをローカル環境に落として実行しました。
「asrOutput.json」があるディレクトリ内で以下のコマンドを実行します。
git clone https://github.com/trhr/aws-transcribe-transcript python3 ./aws-transcribe-transcript/transcript.py asrOutput.json
スクリプトを実行すると「asrOutput.json.txt」がディレクトリ内に出力されました。

中身を確認してみると、どうやら単語間にスペースが入ってしまっていますね。
また、行頭が [0:00:00] spk_0: のようになっているのでこれも整えたいです。
ということで、先ほどと同じディレクトリ内で以下の linux コマンドを実行します。
sed -e 's/ //g' -e 's/\[\([0-9]\+:[0-9]\+:[0-9]\+\)\]//g' asrOutput.json.txt | \ sed -e 's/spk_0:/インタビュアー: /' -e 's/spk_1:/インタビュイー: /' > final_output.txt
1行目で [0:00:00] の部分を削除し、2行目で「spk_0: → インタビュアー: 」「spk_1: → インタビュイー: 」に変換、「final_output.txt」 として出力しています。
インタビュアーとインタビュイーの部分は、適宜好きな文字列に変更してください。
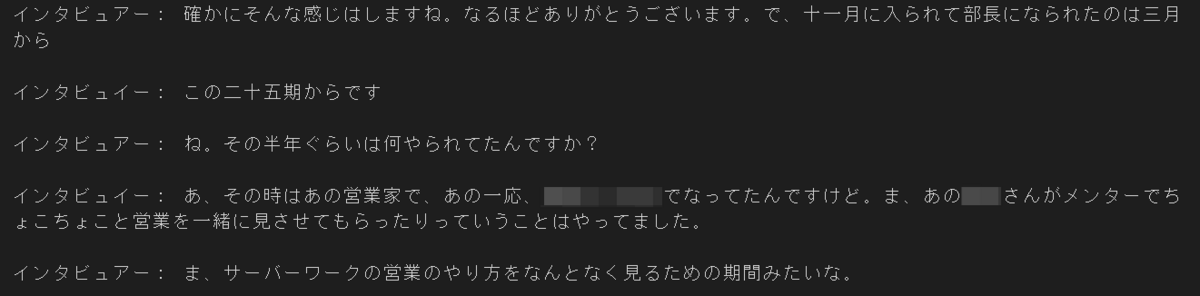
これでようやく、ある程度きれいな文字起こしが完成しました!
まとめ
この後は記事に不要な部分を削除したり、「あの」や「えー」などの余計な文字を削除して整える作業をすることになります。
そこに関しては手作業になるので、よりよい記事にできるようもう少しがんばる必要がありますね。
今回の内容よりもさらに楽をしたいという場合には、「Amazon Transcribeのジョブ完了をトリガーに自動で変換→体裁を整えてくれるように Lambda 関数を起動」というように、より自動化された文字起こしフローが作れそうな気がしますね。
ぜひ興味のある方は試してみてください。