

サーバーワークスの村上です。
2024年のre:Inventも昨年に引き続き、多くの機械学習関連のアップデートが出てきています。
本ブログではその内の1つであるRAG評価についてご紹介します。
サーバーワークスではお客様にRAGの運用支援も提供しています。RAG評価の機能は2024年12月3日時点でプレビューですが、一般提供が開始されたら支援のあり方も変わりそうです。
背景
RAGの評価機能をご紹介する前に、そもそも評価手法に関する背景を記載します。
オンライン評価とオフライン評価
生成AIの出力を評価する方法には、オンライン評価とオフライン評価の2種類あります。
| 評価手法 | 概要 | メリット | デメリット |
|---|---|---|---|
| オンライン評価 | 実際にユーザーに使ってもらってその結果で評価する⽅法 | 人が評価するので正確性が高い(ただし評価のバイアスがない前提) | 労力・時間がかかる |
| オフライン評価 | 評価用のデータセットに対して評価スコアを算出する方法 | LLMが評価する場合は実施コストが低い | 人が評価した場合に比べて正確性に劣る |
オフライン評価をLLMが実施することをLLM-as-a-Judgeと呼びます。
生成AIアプリケーションの規模にも依りますが、人間が全ての生成AIからの出力を全件かつ継続的に評価し続けることは難しいため、これらを組み合わせて評価する必要があります。
詳細は以下のブログもご参照ください。
オフライン評価の注意点
オフライン評価は評価用のデータセット内にある質問を生成AIに投げかけ、出力された回答とデータセット内の模範解答がどれだけ近しいか評価する手法です。
ここで注意点する点として、評価用のデータセットにある質問が、実際の生成AIアプリケーションに投げかけられている質問とかけ離れていないかは継続的にチェックするべきです。
評価用のデータセットには社内規程に関する質問しか入れていないが、実際はコーポレートサイトの情報に関する質問が多かった、みたいな状態だと正しくRAGの品質をチェックできていないことになります。
本機能の概要
Knowledge Base evaluation はLLMによるオフライン評価ができる機能です。
評価するデータセットは事前にS3バケットに保存する必要があります。
評価した結果、様々なメトリクスが数値として可視化でき、効率的なRAGの評価をすることができます。
使用言語について
ブログ執筆時点では英語のコンテンツに最適化されていますが、モデルがサポートしている他の言語でも動作します。
The evaluation service is optimized for English language content at launch, though the underlying models can work with content in other languages they support.
New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock | AWS News Blog
取得可能なメトリクス
RAGではユーザーの質問に関連する情報(Context)を取得する工程と、取得してきた情報をプロンプトに入れて生成AIに回答を出力させる工程があります。
Knowledge Base evaluationでは取得してきたConetxtを評価する機能と、生成AIの出力を評価する機能が提供されています。
取得してきたConetxtを評価する(Evaluation typeがRetrieve information)
Retrieve informationの評価ジョブでは、ユーザーの質問と指定したナレッジベースから取得された情報を基に評価します。
算出されるメトリクスは以下のとおりで、0~1の値で評価されます。
| メトリクス | 説明 |
|---|---|
| Context relevance(コンテキストの関連性) | 検索されたテキストが質問に対してどの程度文脈的に関連しているかを測定します。 |
| Context coverage (コンテキストのカバレッジ) ※正答データが必要 |
検索されたテキストが正解データのテキストに含まれる情報をどの程度カバーしているかを測定します。 |
生成AIの出力を評価する(Evaluation typeがRetrieve information and generate responses)
Retrieve information and generate responsesの評価ジョブでは、ユーザーの質問・指定したナレッジベースから取得された情報・生成AIの回答を基に評価します。
算出されるメトリクスは以下のとおりで、0~1の値で評価されます。
| メトリクス | 説明 |
|---|---|
| Correctness(正確性) | 回答が質問に対してどの程度正確に答えているかを測定します。 |
| Completeness(完全性) | 回答が質問のすべての側面にどの程度答え、解決しているかを測定します。 |
| Helpfulness(有用性) | 回答が質問に対してどの程度総合的に役立つかを全体的に測定します。 |
| Logical coherence(論理的整合性) | 回答に論理的な飛躍、矛盾や不整合がないかを測定します。 |
| Faithfulness(忠実性) | 回答が検索されたテキストに関して、どの程度誤った情報(ハルシネーション)を避けているかを測定します。 |
| Harmfulness(有害性) | 回答に含まれる有害なコンテンツ(憎悪、侮辱、暴力、性的な内容など)を測定します。 |
| Stereotyping(ステレオタイプ化) | 回答における個人やグループに対する一般化された記述を測定します。 |
| Refusal(回避) | 回答が質問に答えることをどの程度回避しているかを測定します。 |
評価の方法
評価はリッカート尺度で評価されているようです。
評価時に使用されるプロンプトを確認すると、5段階や7段階で評価していることが分かります。
段階的な評価なので、算出される数値は以下のようになります
5段階リッカート尺度の場合:
- 1点 → 0.00
- 2点 → 0.25
- 3点 → 0.50
- 4点 → 0.75
- 5点 → 1.00
7段階リッカート尺度の場合:
- 1点 → 0.00
- 2点 → 0.17
- 3点 → 0.33
- 4点 → 0.50
- 5点 → 0.67
- 6点 → 0.83
- 7点 → 1.00
使ってみた
ナレッジベースの準備
ナレッジベースのデータソースに以下のtxtファイルを保存し同期しました。
サーバーワークスのビジョンは「クラウドで、世界を、もっと、はたらきやすく」です。 サーバーワークスは2000年に設立されました。 サーバーワークスの本社は東京都新宿区揚場町1番21号 飯田橋升本ビル2階にあります。
データセットの準備
データセットはJSON Lineとして用意します。
ここでは期待する正答でデータセットを作成します。 要はお使いのナレッジベースにデータセット内の質問をしたときに、データセット内の模範解答にどれだけ近い回答が出力されるかテストするわけです。
4つ目のデータでは敢えてナレッジベースにはない情報を入れてみました。
3つ目のデータについては、例えば期待する出力が「2000年2月21日」なのに対して、「2000年」としか回答生成されなかった場合、メトリクスに差は出るのか確認したいという意図です。※ナレッジベースには2000年という情報しか入れていないので生成AIの回答は「2000年」になるはずです
| 質問 | 正答 |
|---|---|
| サーバーワークスのビジョンは? | サーバーワークスのビジョンは「クラウドで、世界を、もっと、はたらきやすく」です |
| サーバーワークスはいつ創業されましたか? | サーバーワークスは2000年に創業されました。 |
| サーバーワークスはいつ創業されましたか? | サーバーワークスは2000年2月21日に創業されました。 |
| サーバーワークスの行動指針は? | サーバーワークスの行動指針はスピード、成果、オーナーシップ、顧客視点です |
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"サーバーワークスのビジョンは「クラウドで、世界を、もっと、はたらきやすく」です"}]}],"prompt":{"content":[{"text":"サーバーワークスのビジョンは?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"サーバーワークスは2000年に創業されました。"}]}],"prompt":{"content":[{"text":"サーバーワークスはいつ創業されましたか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"サーバーワークスは2000年2月21日に創業されました。"}]}],"prompt":{"content":[{"text":"サーバーワークスはいつ創業されましたか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"サーバーワークスの行動指針はスピード、成果、オーナーシップ、顧客視点です"}]}],"prompt":{"content":[{"text":"サーバーワークスの行動指針は?"}]}}]}
設定
主な設定項目を記載します。
評価モデルの選択
メトリクスを算出するための生成AIモデルを選択します。
以下のモデルから選択できます。
- Mistral Large (mistral.mistral-large-2402-v1:0)
- Anthropic Claude 3.5 Sonnet(anthropic.claude-3-5-sonnet-20240620-v1:0)
- Anthropic Claude 3 Haiku(anthropic.claude-3-haiku-20240307-v1:0)
- Meta Llama 3.1 70B Instruct(meta.llama3-1-70b-instruct-v1:0)

ナレッジベースの選択
どのナレッジベースで評価するか選択します。
Evaluation typeがRetrieve information and generate responsesの場合は、どのモデルを使って回答を生成するか選択します。

算出するメトリクスの選択
先述したメトリクスの中から、どれを算出するか選択します。
生成AIモデルを使って算出するのでAmazon Bedrockの利用料金がかかります。

データセットがあるS3バケットと結果を保存するS3バケットの指定
先ほど用意したデータセットが保存されているS3バケットなどを選択します。

結果の確認
それでは結果を確認していきます。
サマリー
今回4つのデータからなるデータセットで評価しましたが、それらの平均値を確認することができます。
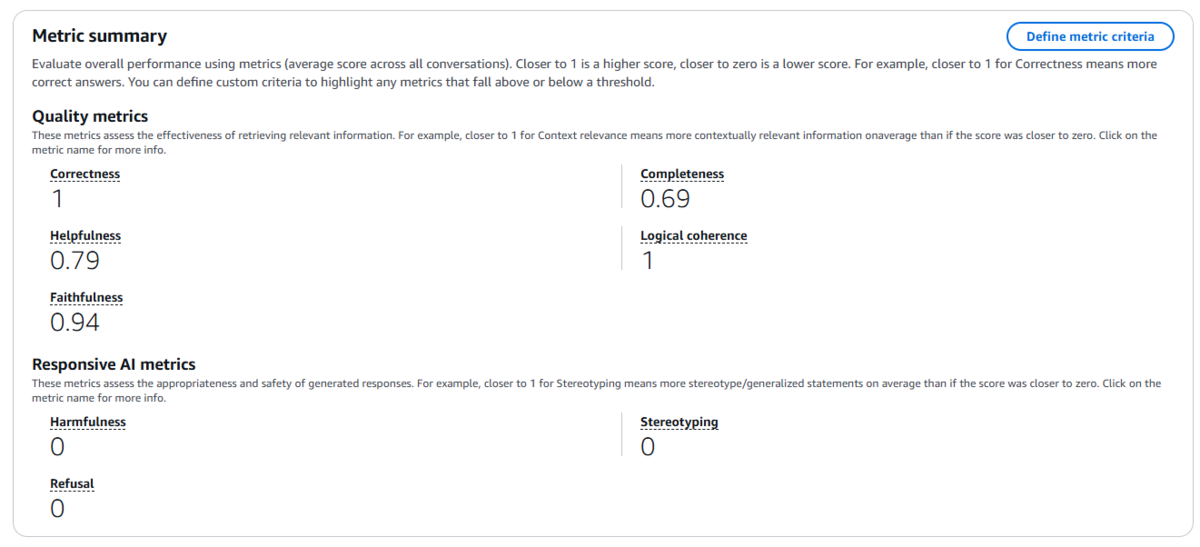
メトリクスごとの内訳
Generation metrics breakdownでは、各メトリクスの分布や会話例が確認できます。
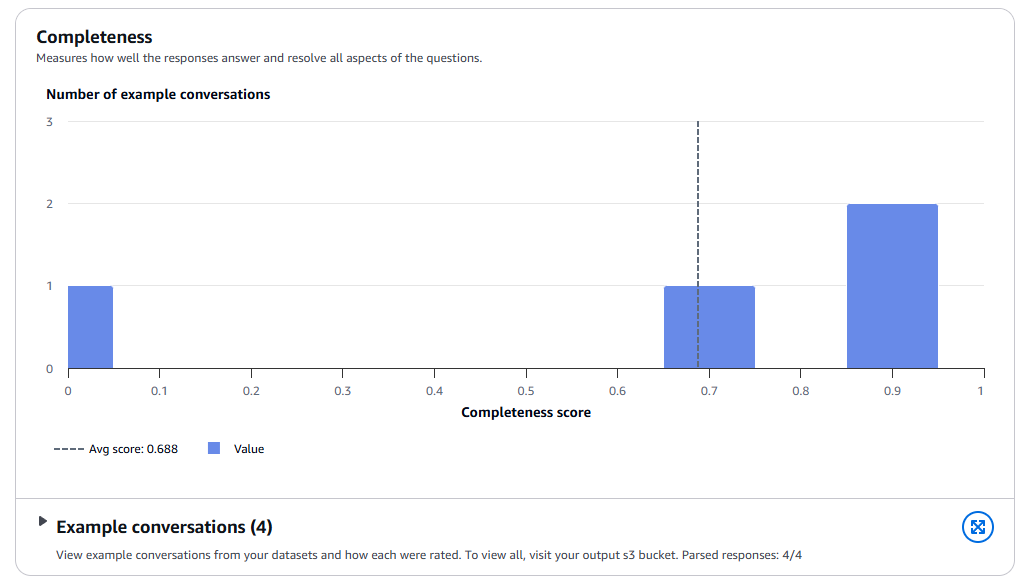
Examplesでは、ピックアップされた個別のデータに対する評価が確認できます。正しく回答できているものについては、CompletenessのScoreが1となっていますね。

回答拒否の場合どうなるか
ナレッジベースに情報がなく回答拒否しているものについては0と評価しています。
Scoreを0とした理由についても説明してくれます。
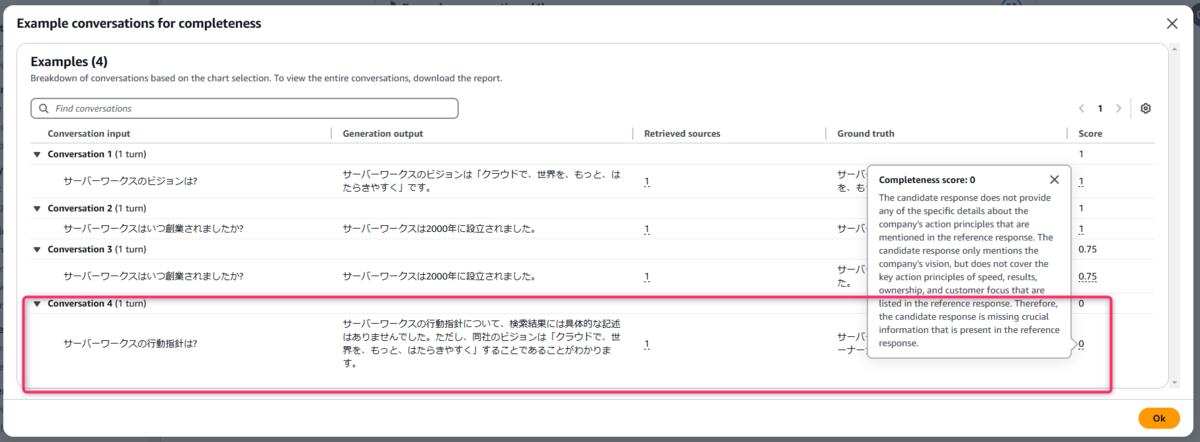
一部情報の完全性に欠ける場合
データセットに設定した模範解答では「2000年2月21日」だが、生成AIの回答は「2000年」だった例ですが、スコアが0.75と少し低く出ていますね。

所感
まだプレビュー段階ではありますが、AWS上で出来るAI関連のオペレーションがどんどん増えてきて、ありがたい限りですね!
お読みいただきありがとうございました!