

サーバーワークスの村上です。
先日、「導入して終わり」にしない、 生成AI活用のファーストステップと運用のコツというタイトルでウェビナー登壇させていただきました。
ウェビナーではAmazon Bedrockの基本的な内容やRAG運用の弊社事例についてお話させていただきました。本ブログではRAG運用の弊社事例について簡単にまとめようと思います。
RAG運用のつらみ
いろいろあるとは思いますが、技術面では以下3点がぱっと思いつきました。
- 日々溜まっていく利用データのうち、どこで精度の低い回答が生成されているのか分かりづらい
- 精度の改善方法が分からない
- 新しいモデルや機能が頻繁に登場するので追従するのが大変
日々溜まっていく利用データのうち、どこで精度の低い回答が生成されているのか分かりづらい
RAGの使用履歴はDynamoDBなどを使ってテーブル形式として保存することが多いかと思います。
下図はイメージですが、テーブルにはユーザーの入力や検索してきたコンテキスト、生成AIが回答した内容、ユーザーからのフィードバック等々が保存されています。

このような履歴が日々溜まっていくわけですが、この中から精度の低い回答が生成されているケースを見つけるのは非常に骨が折れる作業です。
サーバーワークスの社内QAチャットボットでも、会話履歴の保存場所としてDynamoDBを採用していますが、とても目視で確認する気にはなれません。
サーバーワークスの社内QAチャットボットについては過去のブログもご参照ください。
精度の改善方法が分からない
データソースに情報はあるのにうまく検索されず、それ故に生成AIが正しく回答できないケースがあります。
改善のためにできる工夫はいくつかあります(例えばハイブリッド検索にしてみるなど)が、必ず改善するわけではないので難しいところです。
新しいモデルや機能が頻繁に登場するので追従するのが大変
日々発表されるアップデートの内容を理解し、検証・導入するのも一定の工数を要するため、辛いと感じられる方も多いかもしれません。
例えばKnowledge Bases for Amazon Bedrockで登場したAdvanced RAGなども新機能の1つと言えます。
弊社のようなクラウドインテグレーターがご支援する、という体制を組んでいただくのも手かと思います。
サーバーワークスがやっているRAG運用
ウェビナーではサーバーワークスのRAG運用事例をご説明しました。
LLM as a Judge(生成AIによる自動評価)
先述したようにRAGの履歴をマンパワーでチェックするは非現実的と考えています。
そこでRAGの評価にも生成AIを活用しました。
RAGの評価を支援するフレームワークであるRagasを使って、検索や回答の関連性を数値化・可視化しています。
以下3つのデータはRAGを使えば自然と蓄積されていきますので、これらを活用します。
①ユーザーの入力
②検索してきたコンテキスト
③生成AIの回答
具体的には、①と③の関連性(Answer Relevancy)を数値化します。

Answer Relevancyについて
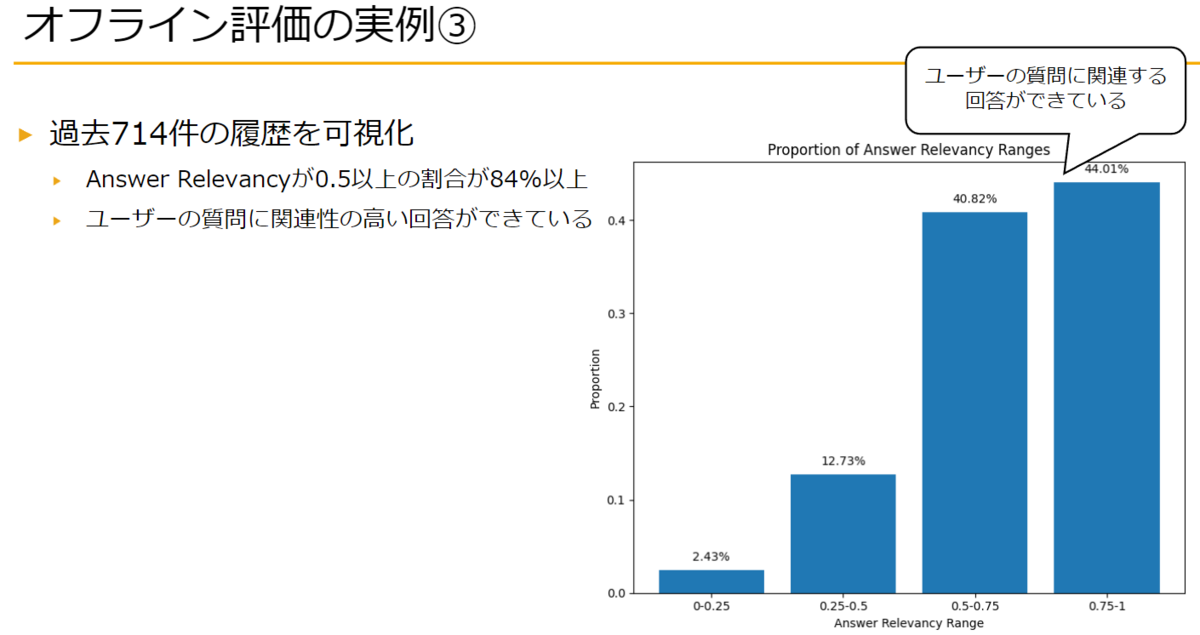
Answer Relevancyは質問と回答の関連性を測るための、0~1の範囲の値をとるメトリクスです(1に近いほど関連性が高い)。
下図は弊社の事例ですが、84%以上のケースでAnswer Relevancyが0.5以上を記録しています。つまり多くのケースでユーザーの質問に関連性の高い回答ができているということになります。
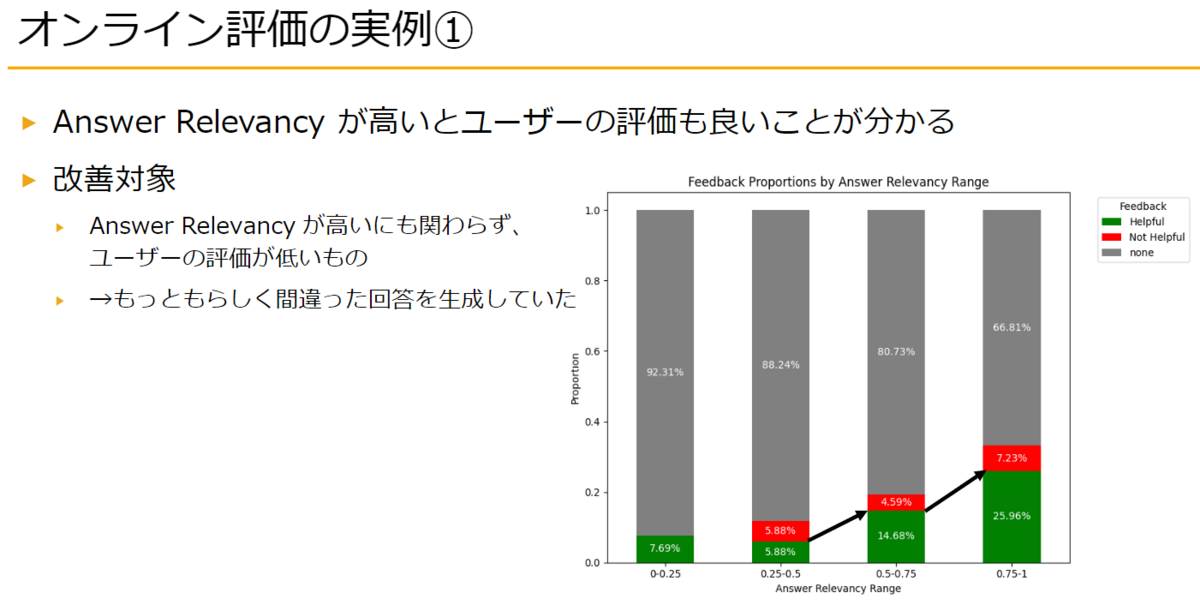
また、Answer Relevancyが高いほど、ユーザーからのフィードバックで「参考になった」というポジティブな評価(棒グラフの緑色の部分)を得られていることが分かります。
Answer Relevancyの算出方法
生成AIの回答からユーザーの質問を推測します。推測には生成AIを使っており、デフォルトでは3つの質問を生成します。
使う生成AIもカスタマイズ可能で、弊社ではAmazon BedrockのClaudeを使っています。
推測した質問と、実際のユーザーからの質問のコサイン類似度を計算し、Answer Relevancyを算出します。
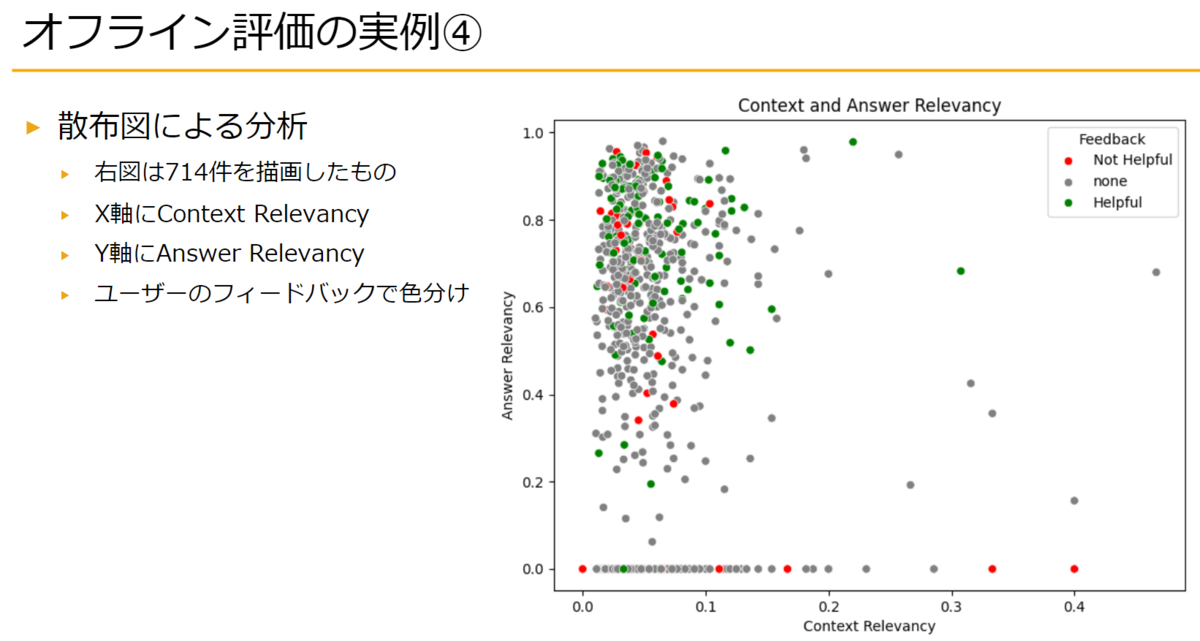
Context Relevancyについて
Context Relevancyは質問とコンテキスト(検索してきた情報)の関連性を測るための、0~1の範囲の値をとるメトリクスです(1に近いほど関連性が高い)。
Answer Relevancyと組み合わせて散布図を作成し、プロットが左下にあるケース(Answer Relevancy、Context Relevancyともに低い)から分析していくなどが考えられます。
もしFAQデータを持っていたら更にできること
弊社では下記3つのデータを使っていると説明しました。
①ユーザーの入力
②検索してきたコンテキスト
③生成AIの回答
もし、①に対する模範解答を持っている場合、RagasのAnswer semantic similarity(回答の意味的類似性)などのメトリクスも活用できます。
Answer Relevancyはあくまで質問と回答の関連性を測る指標であり、精度は測れません。例えば「日本の首都は?」という質問に対し、「日本の首都は大阪です」と回答していた場合でもAnswer Relevancyは高い数値になることが予想されます。
Answer RelevancyはRAGでよくある回答拒否(コンテキストに情報がないため回答を生成できないケース)を見つける手段としては有用ですが、上記のようなハルシネーションを見つける手段には向いていません。弊社でもハルシネーションはユーザーからのフィードバックで見つけることが多いです。
そのためFAQのような模範解答を含むデータセットを持っている場合は、Answer semantic similarity(回答の意味的類似性)などのメトリクスを活用すべきと考えます。
まとめ
生成AIを導入して終わりにしないためには、技術面以外の要素も重要ですが、とりわけ技術面に関しては「使うメリットがあること」を示し続けることが大事かと思います。
そのためにも日々の評価・改善が重要と考えます。