

サーバーワークスの村上です。
2024年7月10日に行われたAWS New York Summitで生成AI関連のアップデートがいくつかありました。
ナレッジベース関連でも激アツなアップデートがあり、このブログではAdvanced RAG機能について紹介させていただきます。
- 追加のデータソースをサポート (プレビュー)
- S3以外にもウェブクローラなど追加のデータソースを選択可能に
- Advanced RAG機能をサポートするようになりました
- チャンク化のオプションがより充実し、精度向上に寄与
RAGとは
ユーザーの質問に関連する情報を検索し、検索してきた情報をプロンプトに含める手法です。
こうすることで大規模言語モデル(LLM)が知らない事項についても回答を生成させることが可能です。
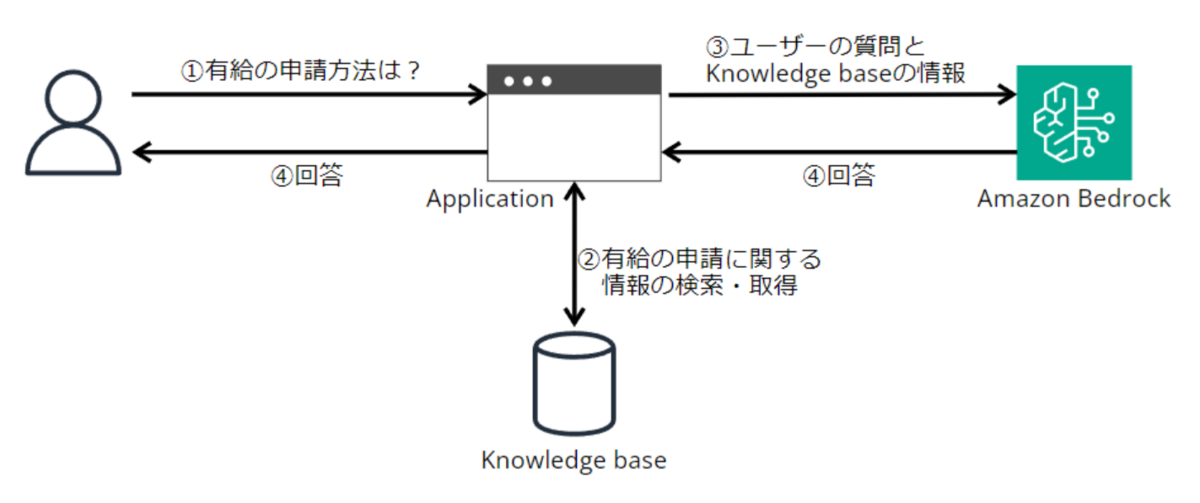
詳細は過去のブログでもご説明しています。
Advanced RAGとは
通常のRAG(Naive RAG)に対して、精度向上のために追加の工夫を加えたRAGをAdvanced RAGと表現します。
一般的にどのような工夫の手法があるかについては、AWSブログにて説明されています。
Advanced RAG の枠組みでは、 検索前処理 (pre-retrieval) と 検索後処理 (post-retrieval) としてさまざまな工夫が考案されています。検索前処理では、インデックス構造の最適化やクエリの改善を行います。検索後処理では、検索結果のランク付けや情報の圧縮を行い、大規模言語モデル (LLM) への入力を最適化します。
Amazon Kendra と Amazon Bedrock で構成した RAG システムに対する Advanced RAG 手法の精度寄与検証 | Amazon Web Services ブログ
チャンクとは
チャンクは検索対象ドキュメントを小さな単位に分割したものです。
LLMが正しい回答を生成するために理想的なLLMへの入力は、ユーザーの質問と質問に答えられるために必要かつ適切な量の情報です。
ユーザーの質問に加え、膨大な量の検索対象ドキュメントすべてをLLMに入力すると、コストがかかるだけでなくハルシネーションの原因にもなり得ます。
そのため、検索対象ドキュメントをさらに分割する必要があるわけです。
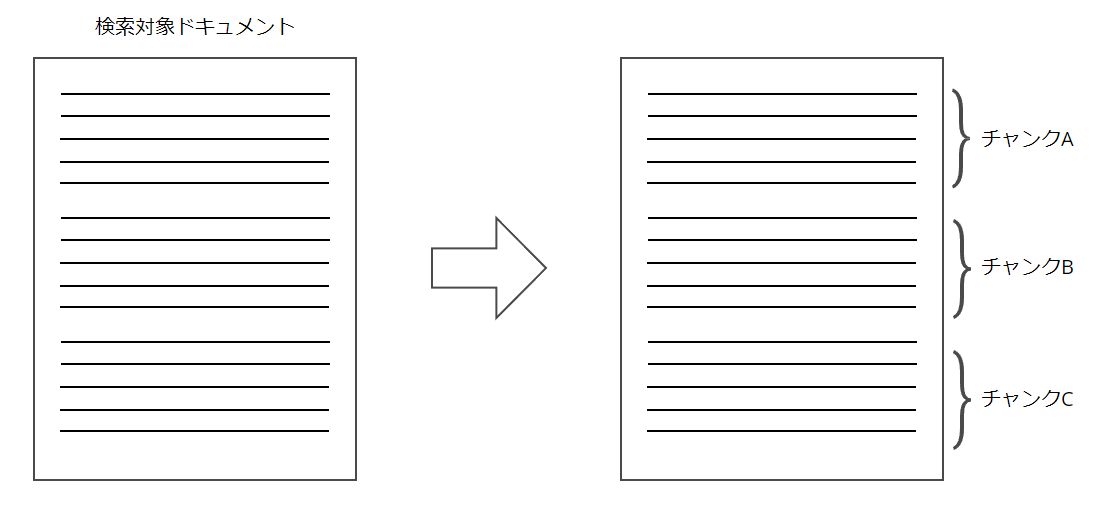
今回リリースされたチャンク戦略
下記3つのオプションが追加されました。
| チャンク戦略 | 説明 |
|---|---|
| セマンティック チャンク化(Semantic chunking) | 意味的に類似したチャンクを編成する |
| 階層的チャンク化(Hierarchical chunking) | ネストされた親子チャンクを編成する |
| カスタムチャンク化 | ユーザー独自のチャンク化コードを Lambda 関数として記述できる |
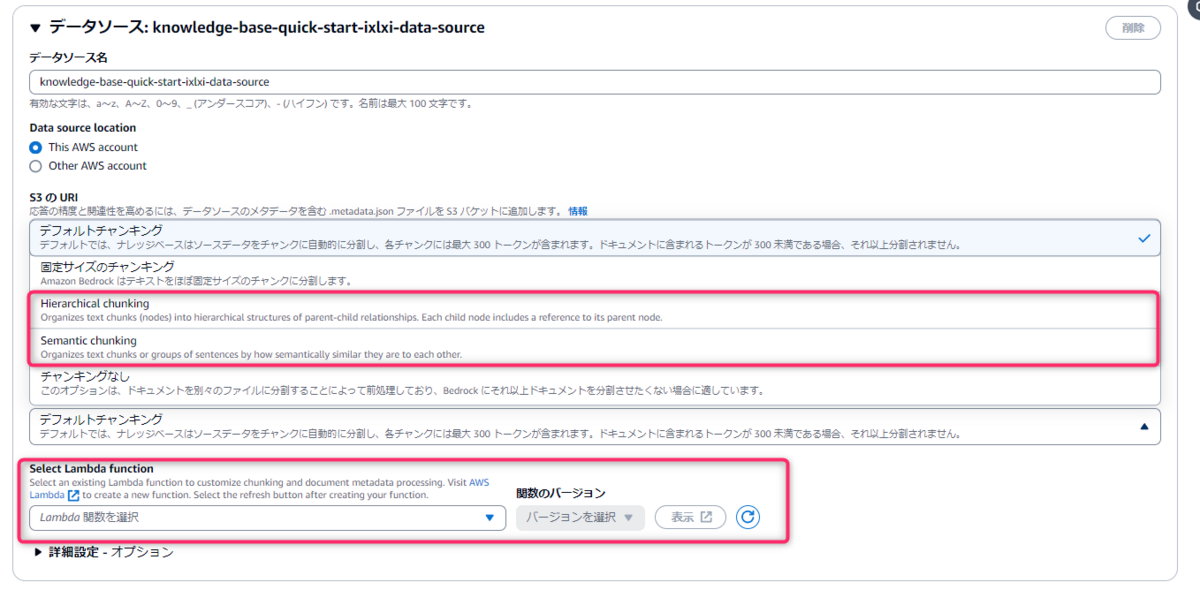
今回は上記のうち、階層的チャンク化(Hierarchical chunking)を試してみました。
Hierarchical chunking(階層的チャンク化)を試してみた
チャンクに関する検索精度と回答精度のトレードオフ
冒頭に記載したとおり、RAGには検索・回答生成の2工程あります。
各工程に適したチャンクサイズを考えたとき、検索時は小さなチャンクの方が検索精度が上がりやすく、回答生成時は大きなチャンクの方が回答精度が上がりやすいという性質があります(もちろん小さすぎ・大きすぎはダメですが)。
冒頭の絵を再掲しますが、有給に関する情報を検索したいとき、有給申請に関する段落のみをチャンク化し検索対象とする場合と、すべての休暇制度に関するドキュメントを1つのチャンクとして検索する場合とでは、前者の方が検索精度が高いです。
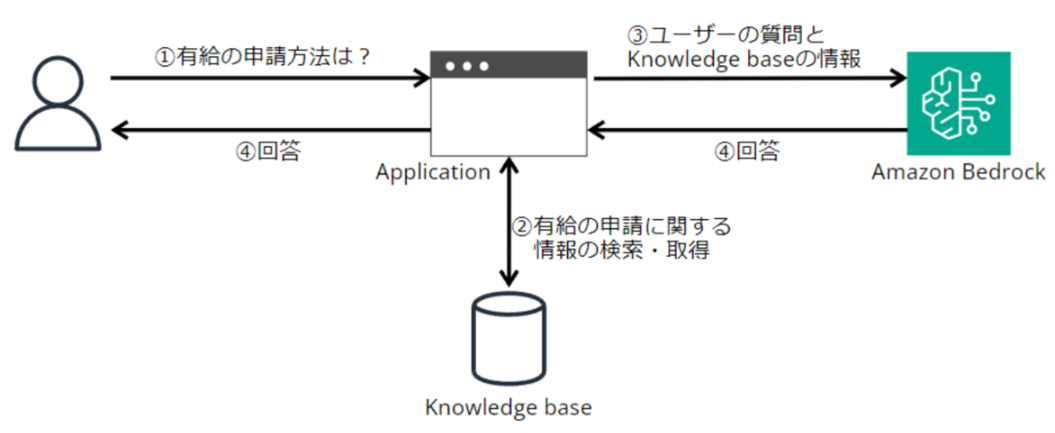
逆に回答生成の工程では、周辺知識も含めたそれなりに長い文章をLLMに入力した方が回答の質は高い傾向にあります。特に最近登場したようなLLMは膨大な量のコンテキストウィンドウをサポートしています。
つまり、チャンクサイズを小さくすると検索の精度は向上するが、質の高い回答生成に必要な情報が含まれなくなるリスクがある、というトレードオフがあります。
Hierarchical chunking(階層的チャンク化)とは
上記の問題を解決するためにあるのがHierarchical chunking(階層的チャンク化)です。
検索対象は子チャンク、LLMに渡すのは親チャンク、とするわけです。

設定方法
設定方法はとても簡単で、マネジメントコンソールからHierarchical chunking(階層的チャンク化)を選択するだけです。
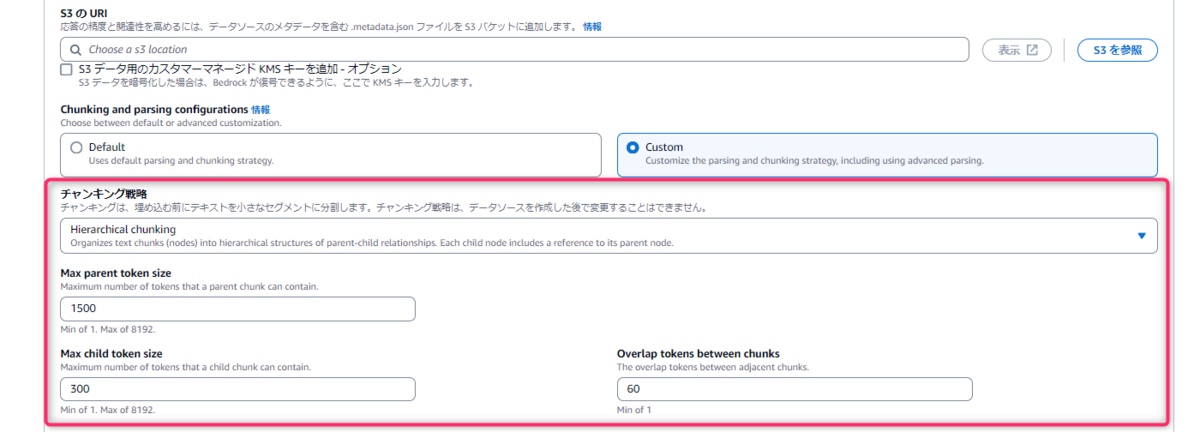
親チャンクの最大サイズなども設定することができます。
チャンクを確認してみる
Hierarchical chunking(階層的チャンク化)を設定し、どのようなチャンクがインデックス化され、最後にどのようなコンテキストがLLMに入力されるのか確認してみました。
データソースであるS3に徳川家康のWikipediaの記事をPDF化したものを保存し、ナレッジベースのRetrieve APIを使ってなにか質問してみます。
デフォルトのチャンク戦略の場合
デフォルトのチャンク戦略の場合、検索対象のチャンクとLLMに渡されるチャンクは同一です。
下図の左側がナレッジベースの画面(LLMに渡されるチャンク)で、右側がAuroraのクエリエディタの画面(検索対象のチャンク)です。
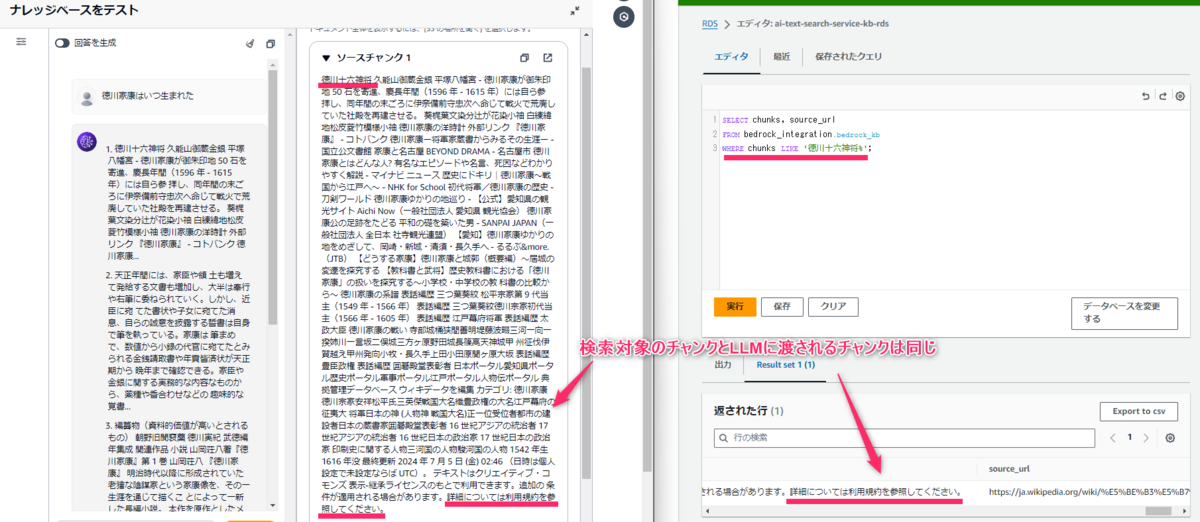
「徳川十六神将~(中略)~詳細については利用規約を参照してください 」までの同じチャンクであることが分かります。
Hierarchical chunking(階層的チャンク化)の場合
検索対象のチャンク(子チャンク)とLLMに渡されるチャンク(親チャンク)が異なります。
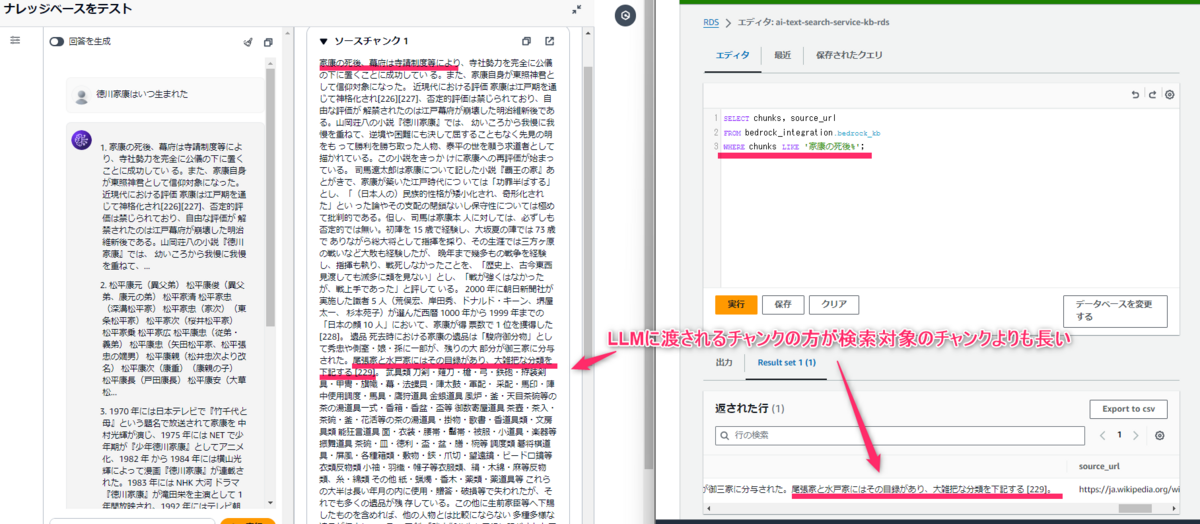
「家康の死後~」から始まるチャンクですが、LLMに渡されるチャンク(上記キャプチャ左側)の方が検索対象のチャンク(上記キャプチャ右側)よりも長いことが分かります。
所感
Amazon Bedrock のKnowledge Basesは簡単にRAGを実装できるメリットがあった反面、自由度に制限があった印象でしたが、検索アルゴリズムの選択や今回のチャンク戦略など、いろいろ自由度も増して使いやすくなってきています。