

サーバーワークスの村上です。
re:Invent 2023の2日目はAmazon Bedrock関連で複数のアップデートがありました。
このブログでは、注目のアップデートであるKnowledge base for Amazon Bedrockについて紹介します。
その他のre:Invent関連ブログはこちらにまとめています。
概要
- Amazon Bedrockのプレビュー機能だったKnowledge baseの一般提供が開始されました
- Knowledge base for Amazon Bedrockは検索拡張生成(RAG)が簡単にセットアップできる機能です
- 私の意見ですが、これまでユーザー側の作業範囲だった情報のベクトル化、ベクトルデータベースへの追加作業がオフロードされ、かなり楽になったと思います!
- RAGで会話履歴を踏まえた回答をさせたい場合、ユーザーの質問を要約するための実装が必要ですが、そこも裏側でしっかりやってくれています!
利用可能なリージョン
執筆現在でus-east-1とus-west-2で利用可能です。
まず全体像を理解しよう
検索拡張生成(RAG)とは
大規模言語モデル(LLM)には、最新の情報に基づく回答が生成されない、企業独自の情報に基づいた回答を生成しない、といった課題がありました。
これを解決するためのひとつの手段としてRAGがあります。
具体的には、LLMの外部に情報の保管場所を作っておき、ユーザーの質問に関連する情報を検索・取得したうえで、LLMに回答を求める手法です。
RAGはハルシネーションを軽減するための施策としても有用といわれています。宜しければ過去のブログもご参照ください。
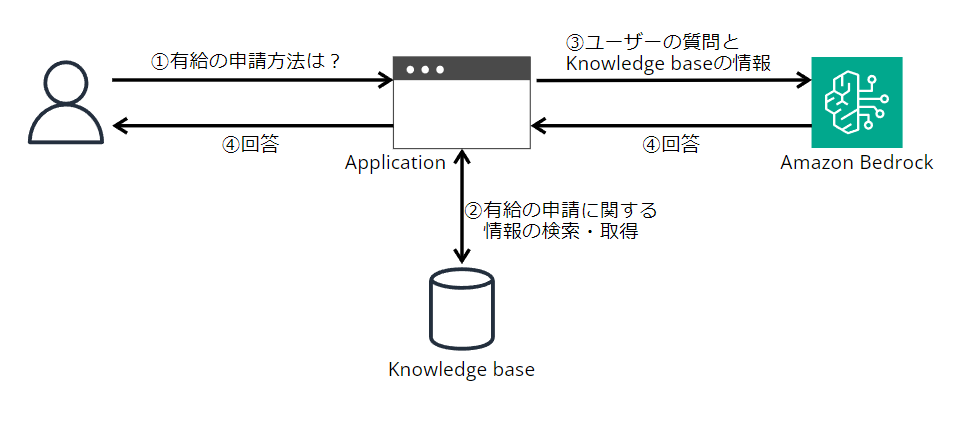
Knowledge base for Amazon Bedrockの全体像
公式ドキュメントに分かりやすい絵がありましたので引用させていただきます。
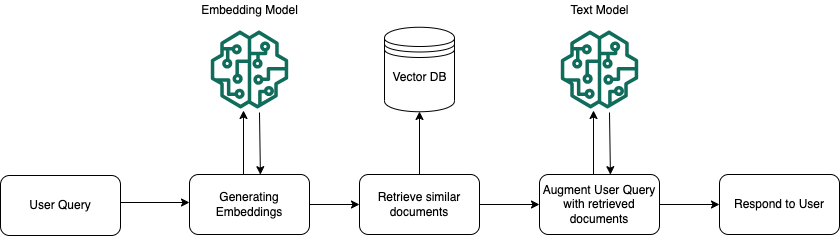
この絵に沿って説明します。
Vector DB(ベクトルデータベース)
絵の中央にあるVector DB(ベクトルデータベース)は、LLMに回答させたい情報を保存しておく場所です。
ベクトルデータベース=狭義のナレッジベースという理解で支障ないかと思います。
情報をテキストのまま扱うのではなく、ベクトルに変換することで、ユーザーの意図を汲みとった検索(セマンティック検索)が可能になります。
Embedding Model(埋め込みモデル)
情報をテキストからベクトルに変換するためのモデルです。
まずは企業独自の情報などLLMに回答させたい情報をベクトル化し、ベクトルデータベースに保存します。
次にユーザーからの質問もベクトル化し、先に保存した情報と意味的な類似度(関連度)を測る、という流れです。(類似度の計測はベクトルデータベースの役割です)
Text Model
Text ModelにはAmazon Bedrockの大規模言語モデル(Claude 2など)が該当します。
先述の流れで、ユーザーの質問に関連する情報を検索した後、これをユーザーの質問とともにText Modelにプロンプトとして入力します。
こうすることで、Knowledge baseの情報に基づいた回答の生成が可能になります。
なお、大規模言語モデルは膨大なコーパスで事前トレーニングされており、一般的な質問に回答することができますが、RAGではプロンプトで「Knowledge baseに情報がない場合は『分かりません』と回答を生成しなさい」と命令することが一般的です。
このようにして、ハルシネーションを軽減しているわけです。
Data source(データソース)
掲載した絵には登場していませんが、実際の設定ではデータソースも登場しますので説明します。
データソースはベクトルに変換する前の情報を置いておく場所です。
後述しますが、ユーザーはデータソースに企業独自の情報を保存し、コンソール画面でポチっとすると、裏側でベクトルに変換しベクトルデータベースに保管してくれます。
各種コンポーネントの詳細
ここから、実際の設定画面を交えつつ説明します。
①データソースの設定
データソースは同じリージョンのS3を指定
データソースは同じリージョンのS3 URIを指定します。
S3には企業独自の情報など、LLMに参考にしてほしい情報をあらかじめ保存しておきます。
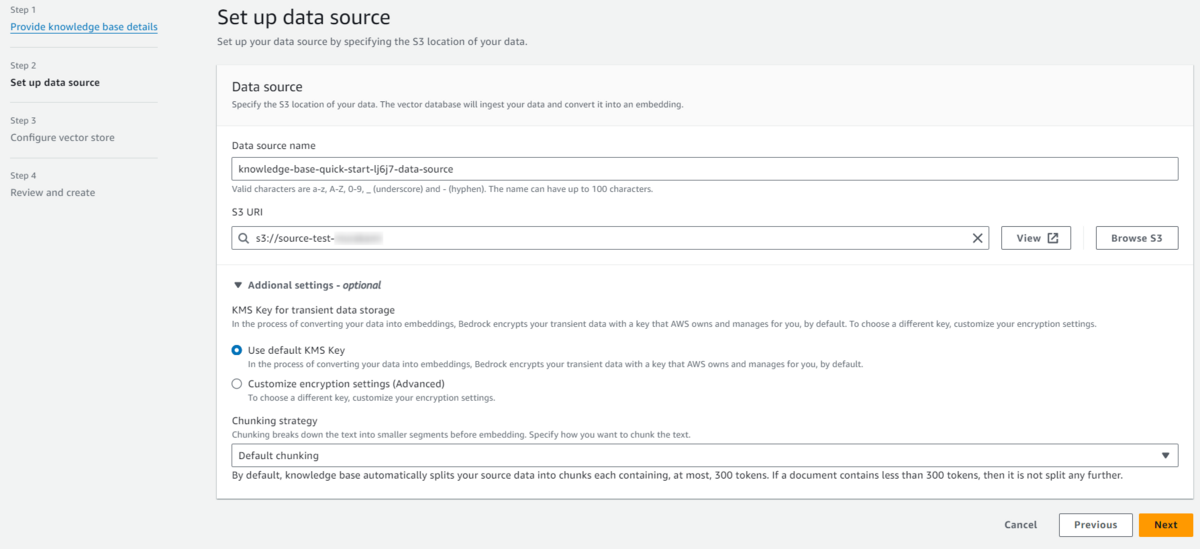
サポートしているファイル形式は以下のとおりで、ファイルあたり最大50MBまでです。
- Plain text (.txt)
- Markdown (.md)
- HyperText Markup Language (.html)
- Microsoft Word document (.doc/.docx)
- Comma-separated values (.csv)
- Microsoft Excel spreadsheet (.xls/.xlsx)
- Portable Document Format (.pdf)
私はサーバーワークスホームページの採用ページをいくつか保存しました。
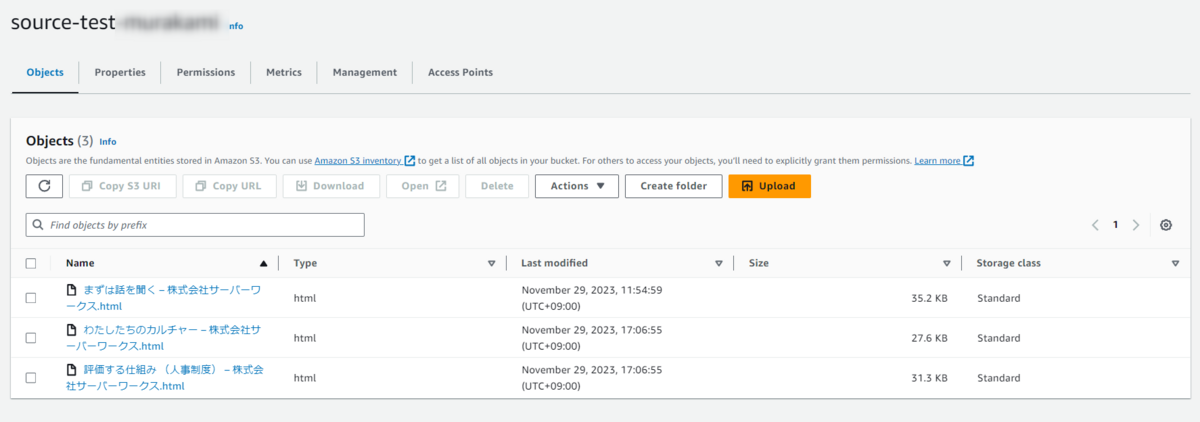
Chunking strategy(ドキュメントのチャンク化)
検索性能を向上させるために、ファイル内のテキストをいくつかに分割する(チャンクする)のが一般的です。
ここでは、どの長さでチャンクするか設定することができます。
- デフォルト
- 各チャンクに最大約 200 個のトークンが含まれる
- 固定サイズ
- チャンクを任意の長さに設定
- チャンクなし
- 各ファイルを 1 つのチャンクとして扱う
私はデフォルトを選択しました(コンソール画面では300トークンと表記されていますが、公式ドキュメントでは200トークンとあるのでこちらが正かと思います)。
②ベクトルデータベースの設定
Embedding Model(埋め込みモデル)の選択
データソースにあるテキスト情報をベクトルに変換するための埋め込みモデルを選択します。
現在のところ、Titan Embeddings G1 - Text v1.2のみ選択可能です。
ベクトルデータベースの選択
ベクトルデータベースは新規作成または既存のものを選択することが可能です。
新規作成する場合はAmazon OpenSearch Serverless、既存のものを選択する場合はAmazon OpenSearch Serverless、Pinecone、Redis Enterprise Cloudから選ぶことができます。
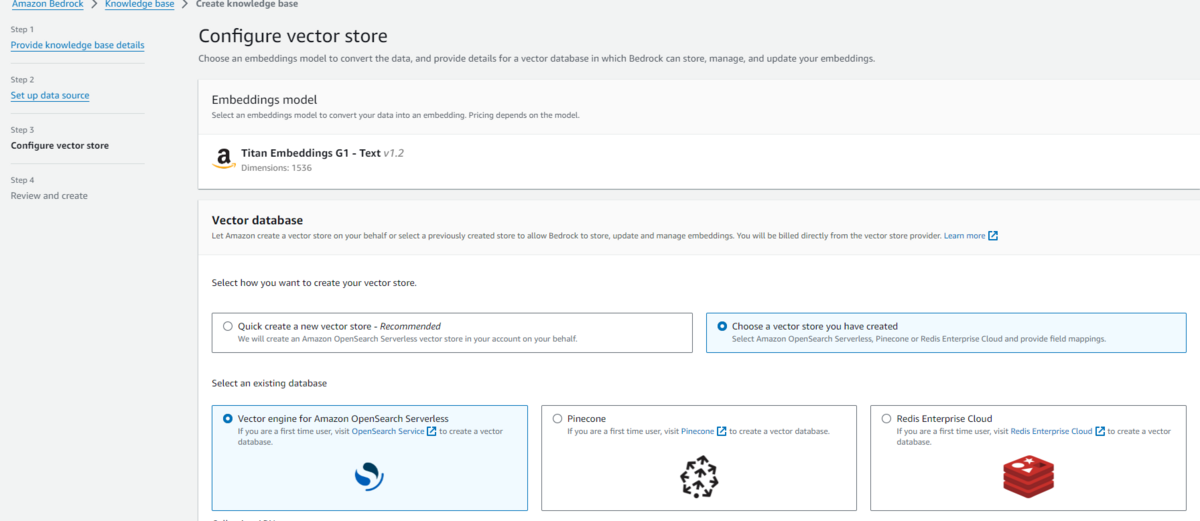
私はAmazon OpenSearch Serverlessを新規作成しました。
以上で初期設定は完了です。
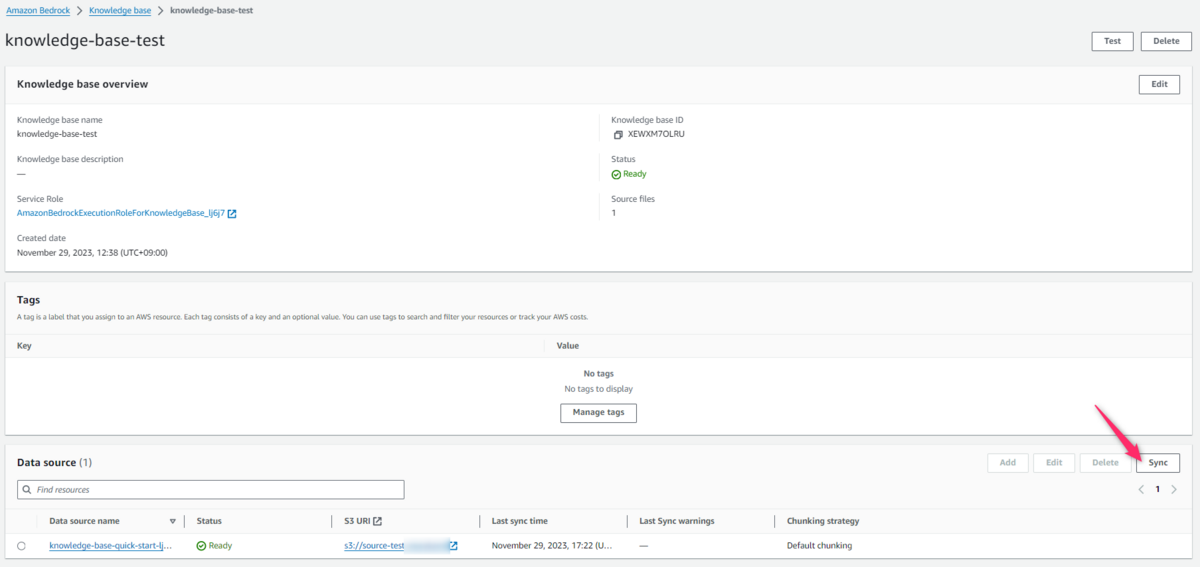
③Sync(同期)する
ステータスがReadyになったら、Syncすることでデータソースからベクトルデータベースへ情報が同期されます。
本来ならば情報をベクトル化し、OpenSearchにドキュメントを作成する操作をしなければいけないのですが、ここがオフロードされかなり楽になっています!
④テストする
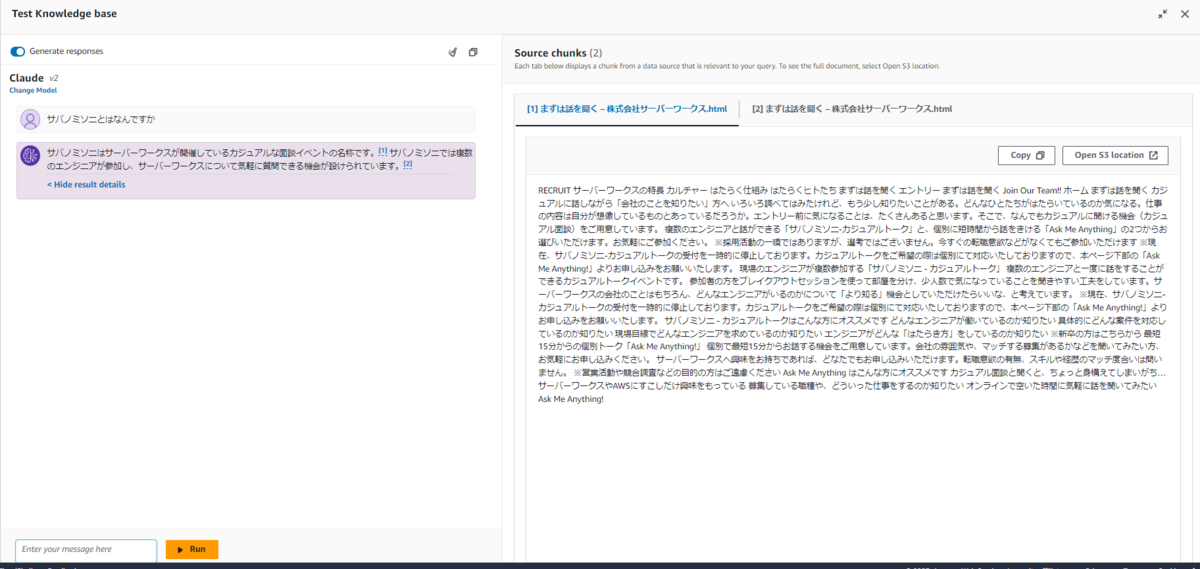
コンソール画面上でテストする機能もあります。
弊社のイベントである「サバノミソニ」について質問したら、ちゃんと回答してくれました。参照したドキュメントも表示されています。
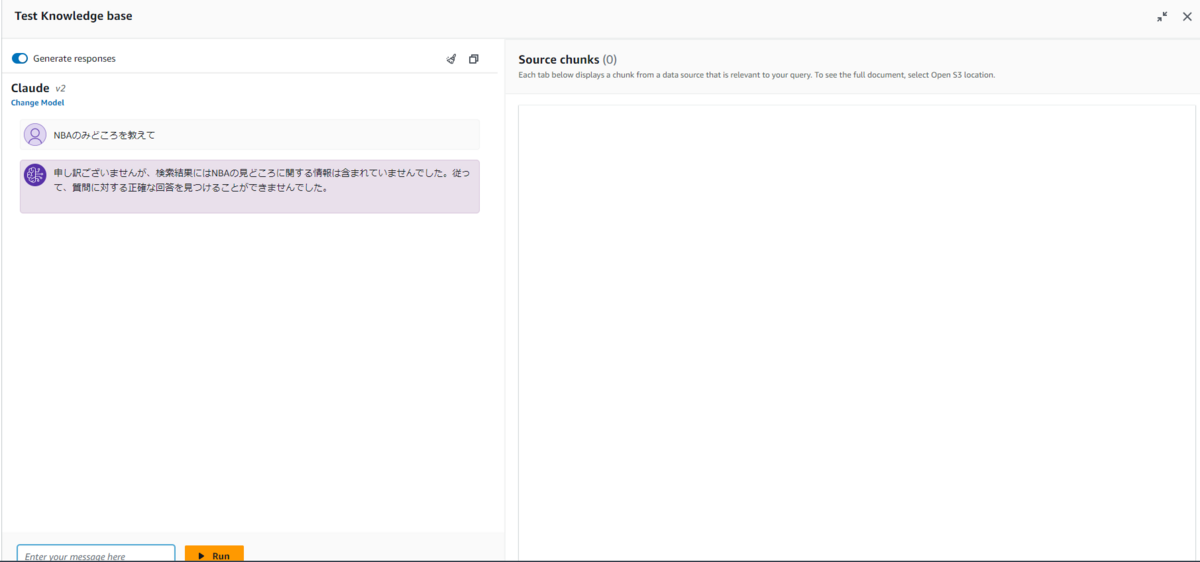
一般的な質問でもKnowledge baseに情報がなければ答えない
冒頭でRAGの場合、データベースに情報がなければハルシネーション防止のために回答を生成しないようにするのが一般的と説明しましたが、Knowledge base for Amazon Bedrockでもそのようになっているようです。
試しにNBAの見どころを質問すると、「Knowledge baseにないので回答しない」旨の回答がありました。 ちなみに、Claude 2にNBAの見どころを質問すると普通に答えてくれます。
⑤本番利用するためのAPIもあります
コンソール画面で本番利用することはほぼないと思いますが、他システム等から利用するためのAPIも用意されています。
- RetrieveAndGenerate
- Knowledge baseから情報を検索し、LLMに渡して回答を生成するAPI
- Retrieve
- Knowledge baseから情報を検索し、S3 URIや類似度スコアを返すAPI
実際に使ってみます。利用時は最新のboto3を使うようにしてください。
import boto3 my_session = boto3.Session(profile_name='xxxx') client = my_session.client('bedrock-agent-runtime', region_name='us-west-2')
RetrieveAndGenerate API
以下のようにして利用します。
response = client.retrieve_and_generate(
input={
'text': 'サバノミソニとはなんですか'
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'XEWXM7OLRU',
'modelArn': 'arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-v2'
}
}
)
レスポンスにLLMが生成した回答やS3 URIが含まれていることが分かります。
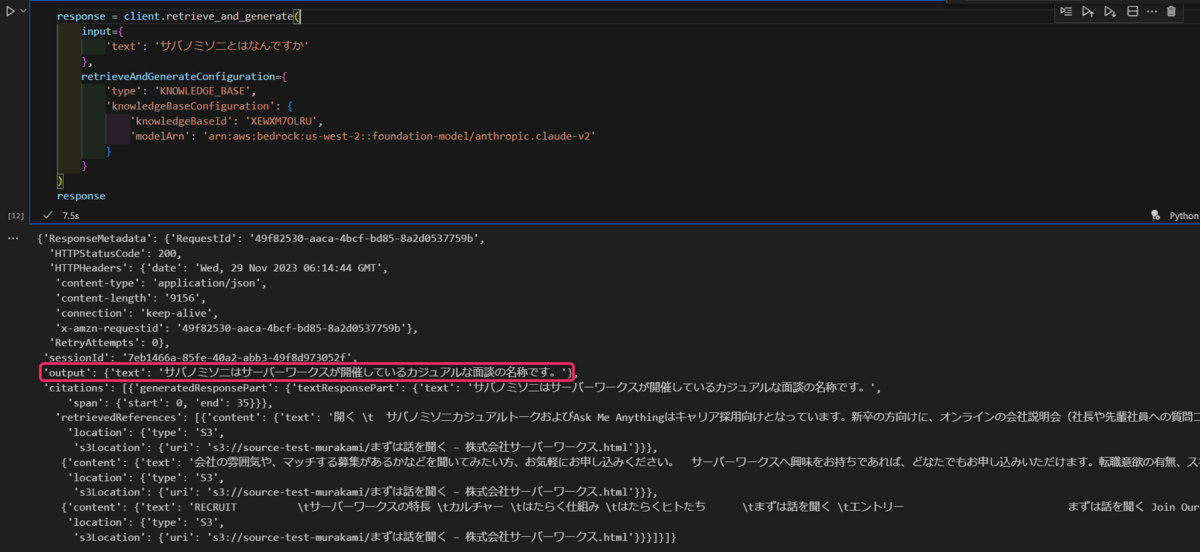
Retrieve API
以下のようにして利用します。
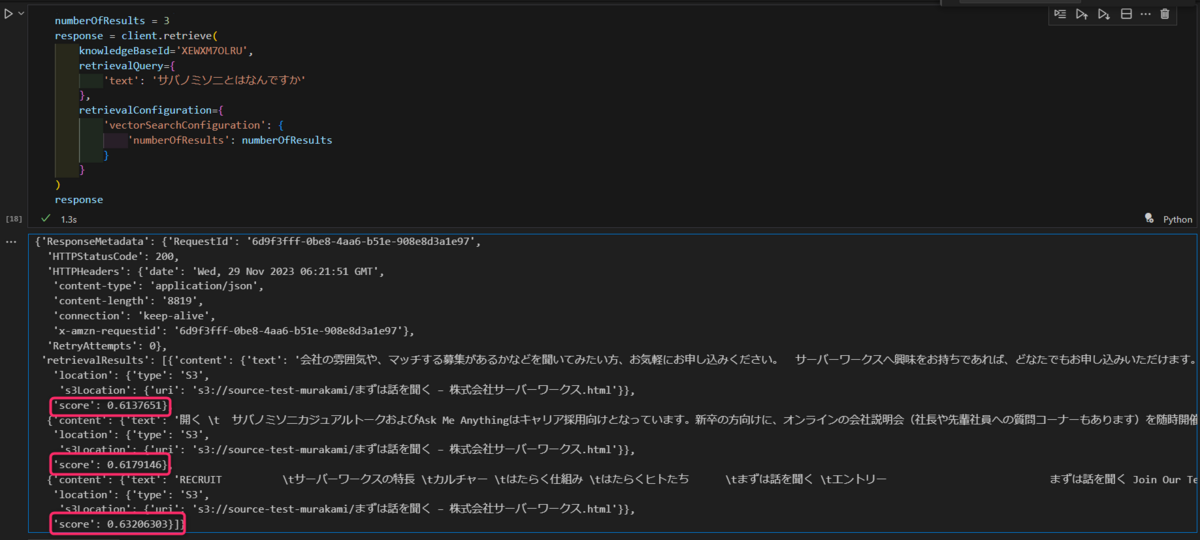
numberOfResults = 3 response = client.retrieve( knowledgeBaseId='XEWXM7OLRU', retrievalQuery={ 'text': 'サバノミソニとはなんですか' }, retrievalConfiguration={ 'vectorSearchConfiguration': { 'numberOfResults': numberOfResults } } )
レスポンスに類似度のスコアやS3 URIが含まれていることが分かります。
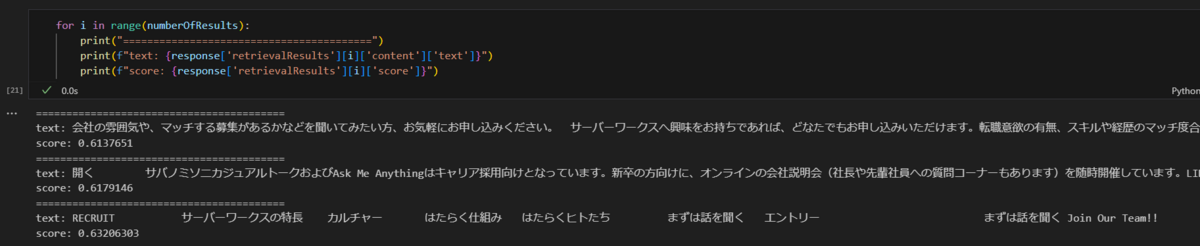
見やすいようにテキストとスコアのみ表示するとこんな感じです。
スコアとはなにか
Retrieve APIのレスポンスにあったスコアとは、ユーザーの質問とベクトルデータベースから検索してきた情報の類似度です。
類似度の計算にはコサイン類似度が使われており、1に近いほど関連性が高く、-1に近いほど関連性が低いです(cosθ懐かしいですね...)
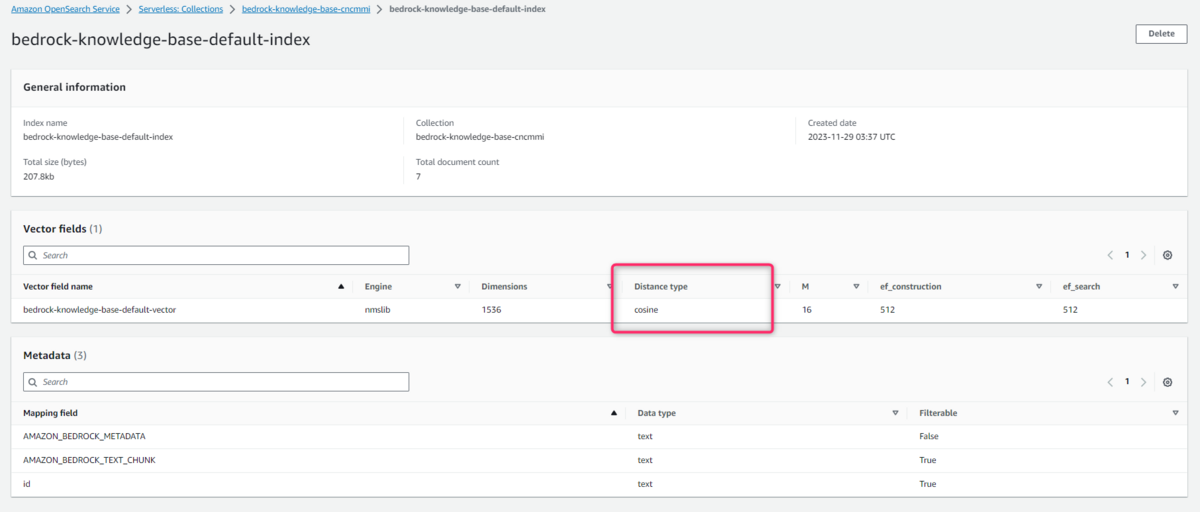
類似度計算はコサイン類似度を選ぶことになりそう
Amazon OpenSearch Serverlessでは類似度計算にコサイン類似度、ユークリッド距離、ドット積(内積)が選択可能です。
しかし、Knowledge base for Amazon Bedrockの公式ドキュメントにはTitan エンベディング モデルを使用する場合は、コサイン類似度を使用します。とあります。
If you use the Titan Embeddings Model, use cosine similarity.
Create a vector store in Amazon OpenSearch Serverless - Amazon Bedrock
そして現状利用可能な埋め込みモデルはTitanのみですので、実質コサイン類似度を選ぶことになりそうです。
Currently, only the Amazon Bedrock Titan G1 Embeddings - Text model is available.
Create a knowledge base - Amazon Bedrock
裏側の実装を垣間見る
会話履歴をふまえた応答も可能
試したところ会話履歴を踏まえた回答も可能です。
以下のキャプチャでは、まず最初に「サーバーワークスの行動指針はいくつありますか」と質問し、次にあえて行動指針とは書かずに「どのような内容ですか」とだけ質問しています。
会話履歴を覚えていない場合、「どのような内容ですか」とだけ質問されても答えられませんが、1回目のQAがプロンプトに含まれているので、きちんと回答できています。
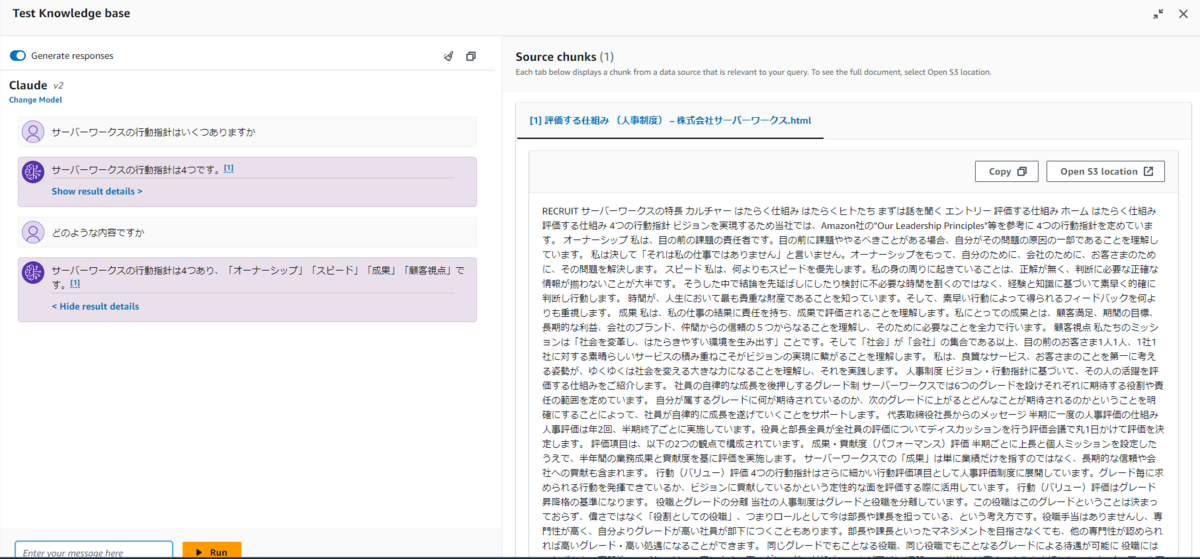
まずはユーザーの質問を要約するためにモデルが呼び出される
どんなプロンプトが使われているのか気になって調べたところ、まずはユーザーの質問をベクトル化する前に要約していることが分かりました。
以下、CloudWatchで確認したプロンプトですが、複数の例を含めたFew-Shotプロンプトを使いながら、会話履歴を踏まえてユーザーの質問を要約するよう指示しています。
具体的には、「どのような内容ですか」という質問をベクトル化して検索してもダメなので、会話履歴を踏まえて「サーバーワークスの行動指針の内容」という質問内容にまとめてくれています。
プロンプト
Human: You are a query creation agent. You will be provided with a function and a description of what it searches over. Your job is to determine the optimal query to use based on a <question> Here are a few examples of queries formed by other search function selection and query creation agents: <examples> <example> <question>What if my vehicle is totaled in an accident?</question> <generated_query>"what happens if my vehicle is totaled"</generated_query> </example> <example> <question>I am relocating within the same state. Can I keep my current agent?</question> <generated_query>"can I keep my current agent when moving in state"</generated_query> </example> </examples> You should also pay attention to the conversation history between the user and the search engine in order to gain the context necessary to create the query. Here’s another example that shows how you should reference the conversation history when generating a query: <example> <example_conversation_history> <example_conversation> <question>How many vehicles can I include in a quote in Kansas</question> <answer>You can include 5 vehicles in a quote if you live in Kansas</answer> </example_conversation> <example_conversation> <question>What about texas?</question> <answer>You can include 3 vehicles in a quote if you live in Texas</answer> </example_conversation> </example_conversation_history> </example> IMPORTANT: the elements in the <example> tags should not be assumed to have been provided to you to use UNLESS they are also explicitly given to you below. All of the values and information within the examples (the questions, answers, and function calls) are strictly part of the examples and have not been provided to you. Here is the current conversation history: <conversation_history> <conversation> <question>サーバーワークスの行動指針の数</question> <answer>サーバーワークスの行動指針は4つです。</answer> </conversation> </conversation_history> Here is the user’s input: <question>どのような内容ですか</question> The format for the <generated_query> MUST be: <generated_query>$GENERATED_QUERY_VALUE</generated_query> If you are unable to determine which function to call or if you are unable to generate a query, respond with 'Sorry, I am unable to assist you with this request.' Assistant:
出力
<generated_query>"サーバーワークスの行動指針の内容"</generated_query>
次に埋め込みモデルでベクトル化される
次にTitanが呼ばれベクトルに変換していることが分かります。
CloudWatch Logsの抜粋
input.inputBodyJson.inputText サーバーワークスの行動指針の内容 output.outputBodyJson.embedding [1.4609375,0.28125,-0.15332031,-0.20117188, ...
最後に検索してきた情報をLLMに入力し質問に回答させる
最後に、以下のように検索してきた情報とユーザーの質問を入力し、簡潔に回答するよう指示しています。
プロンプト
Human: You are a question answering agent. I will provide you with a set of search results and a user's question, your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion. Here are the search results in numbered order: <search_results> <search_result> <content> チャンク化したナレッジベースの内容 </content> <source> 1 </source> </search_result> ...中略... Here is the user's question: <question> サーバーワークスの行動指針の内容 </question> If you reference information from a search result within your answer, you must include a citation to source where the information was found. Each result has a corresponding source ID that you should reference. Please output your answer in the following format: <answer> <answer_part> <text>first answer text</text> <sources> <source>source ID</source> </sources> </answer_part> <answer_part> <text>second answer text</text> <sources> <source>source ID</source> </sources> </answer_part> </answer> Note that <sources> may contain multiple <source> if you include information from multiple results in your answer. Do NOT directly quote the <search_results> in your answer. Your job is to answer the <question> as concisely as possible. Assistant:
料金
最後に料金ですが、Knowledge base for Amazon Bedrock特有の課金はなく、従来通りの入出力トークンに基づく課金となります。
なお、ベクトルデータベースの料金は別途かかります。
所感
冒頭にも書きましたがRAGをサクッと作れるのでとてもいいですね。
ユーザーはKnowledge baseに保存する情報の管理に集中できそうです。