

はじめに
アプリケーションサービス部の鎌田(義)です。
前回のエントリーに引き続き、AuroraからS3へのデータ移行について紹介します。
本エントリーでは、AuroraMySQLからDMSを利用してS3へ継続的にレプリケーションを行い、
GlueETLにてIcebergテーブルを作成/更新し、Athenaでデータを参照するまでの流れを検証したいと思います。
前提
以下の環境を使用、構築済の前提で進めます。
AuroraMySQL情報
- Engine: Aurora MySQL
- Version: 8.0.mysql_aurora.3.05.2
検証で使用するテーブル
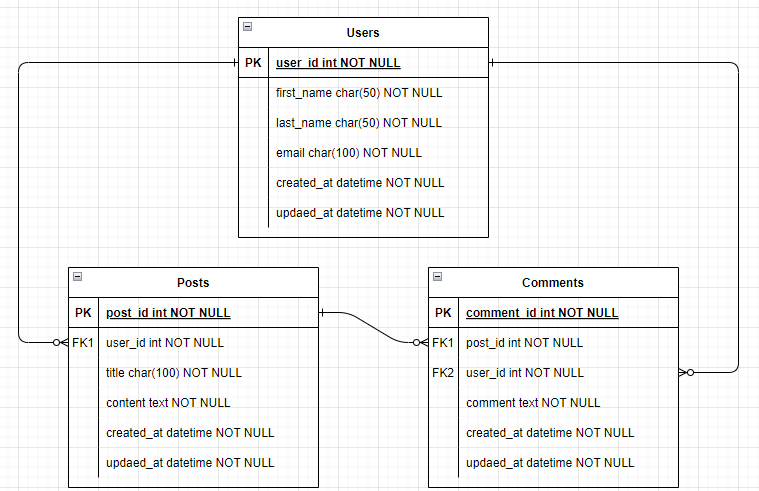
mysql> SELECT * FROM users; +---------+------------+-----------+-------------------+---------------------+---------------------+ | user_id | first_name | last_name | email | created_at | updated_at | +---------+------------+-----------+-------------------+---------------------+---------------------+ | 1 | user | 0 | user0@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | user | 1 | user1@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | user | 2 | user2@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | user | 3 | user3@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | user | 4 | user4@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +---------+------------+-----------+-------------------+---------------------+---------------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM posts; +---------+---------+--------+----------+---------------------+---------------------+ | post_id | user_id | title | content | created_at | updated_at | +---------+---------+--------+----------+---------------------+---------------------+ | 1 | 3 | title0 | content0 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | 1 | title1 | content1 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | 5 | title2 | content2 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | 1 | title3 | content3 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | 3 | title4 | content4 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +---------+---------+--------+----------+---------------------+---------------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM comments; +------------+---------+---------+----------+---------------------+---------------------+ | comment_id | post_id | user_id | comment | created_at | updated_at | +------------+---------+---------+----------+---------------------+---------------------+ | 1 | 2 | 2 | comment0 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | 2 | 3 | comment1 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | 3 | 1 | comment2 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | 3 | 4 | comment3 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | 5 | 3 | comment4 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +------------+---------+---------+----------+---------------------+---------------------+ 5 rows in set (0.01 sec)
DMSセットアップ手順
各リソースの構築については、基本的にはCLIを使用した手順を記載します。
後続で使用する為、AWSアカウントIDを変数にセットしておきます。
AWS_ACCOUNT_ID=`aws sts get-caller-identity \ --query Account \ --output text`
ソースエンドポイント作成
今回は、SecretsManagerに接続情報を保存していない為、手動で接続情報を渡すことにします。
SERVER_NAMEには、自身のAuroraインスタンスのエンドポイントを指定します。
ソースエンドポイント作成
aws dms create-endpoint \ --endpoint-identifier dms-to-s3-aurora-endpoint \ --endpoint-type source \ --engine-name aurora \ --server-name <SERVER_NAME> \ --port 3306 \ --username admin \ --password <PASSWORD>
ターゲットエンドポイント作成
レプリケーションデータ保存先S3バケット作成
aws s3api create-bucket \ --bucket dms-to-s3-${AWS_ACCOUNT_ID} \ --region ap-northeast-1 \ --create-bucket-configuration LocationConstraint=ap-northeast-1
IAMロール作成
エンドポイント接続に使用するIAMロールを作成します。
後続で使用する為、作成したIAMロールのARNを変数にセットします。
IAM_ROLE_ARN=`aws iam create-role \ --role-name dms-to-s3-role \ --assume-role-policy-document \ '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }' \ --query Role.Arn \ --output text
IAMロールに権限をアタッチ
レプリケーションデータ保存先S3バケットへのアクセス権限を付与します。
aws iam put-role-policy \ --role-name dms-to-s3-role \ --policy-name dms-to-s3-policy \ --policy-document \ "{ \"Version\": \"2012-10-17\", \"Statement\": [ { \"Sid\": \"DmsToS3Policy\", \"Effect\": \"Allow\", \"Action\": [ \"s3:ListBucket\", \"s3:PutObject\", \"s3:DeleteObject\", \"s3:PutObjectTagging\" ], \"Resource\": [ \"arn:aws:s3:::dms-to-s3-${AWS_ACCOUNT_ID}\", \"arn:aws:s3:::dms-to-s3-${AWS_ACCOUNT_ID}/*\" ] } ] }"
ターゲットエンドポイント作成
DMSで出力されるファイルには、1列目にイベント種別を表す値(I, U, D)が入ります。
- I: Insert(挿入)
- U: Update(更新)
- D: Delete(削除)
デフォルトだと初回のフルロード時は上記イベント種別が出力されない為、
出力されるよう、IncludeOpForFullLoadをtrueに設定します。
aws dms create-endpoint \ --endpoint-identifier dms-to-s3-s3-endpoint \ --endpoint-type target \ --engine-name s3 \ --s3-settings \ "{ \"BucketName\":\"dms-to-s3-${AWS_ACCOUNT_ID}\", \"BucketFolder\": \"raw_input\", \"ServiceAccessRoleArn\":\"${IAM_ROLE_ARN}\", \"DataFormat\": \"parquet\", \"CompressionType\": \"GZIP\", \"IncludeOpForFullLoad\": true }"
レプリケーションインスタンス作成
レプリケーションサブネットグループ作成
今回はAuroraDBクラスターと同じVPC内のパブリックサブネットを指定しました。
後続で使用する為、作成したサブネットグループのIDを変数にセットします。
SUBNET-1/SUBNET-2には、自身のサブネットIDを指定します。
SUBNET_GROUP_ID=`aws dms create-replication-subnet-group \ --replication-subnet-group-identifier dms-to-s3-subnet-group \ --replication-subnet-group-description dms-to-s3-subnet-group \ --subnet-ids <SUBNET-1> <SUBNET-2> \ --query ReplicationSubnetGroup.ReplicationSubnetGroupIdentifier \ --output text`
レプリケーションインスタンス作成
AWS DMS バージョン 3.4.7 以降の場合、ターゲットエンドポイントであるS3へ接続するには
VPCエンドポイントかパブリックルートを利用してアクセスする必要がありますが、
簡単の為今回はパブリックIPアドレスを割り当てパブリックルートを使用します。
※ターゲットとしてAmazon S3を使用する為の前提条件
後続で使用する為、作成したレプリケーションインスタンスのARNを変数にセットします。
REPL_INSTANCE_ARN=`aws dms create-replication-instance \ --replication-instance-identifier dms-to-s3-replication-instance \ --replication-instance-class dms.t3.medium \ --replication-subnet-group-identifier ${SUBNET_GROUP_ID} \ --publicly-accessible \ --query ReplicationInstance.ReplicationInstanceArn \ --output text`
コンソールで確認すると、以下のようなインスタンス作成ステータスが確認できます。

CLIからも進捗状況を確認できます。
aws dms describe-replication-instances
セキュリティグループ更新
レプリケーションインスタンスからAuroraDBクラスターへ接続できるように
AuroraDBクラスターで使用中のセキュリティグループのインバウンドルールに
レプリケーションインスタンスで使用するデフォルトのセキュリティグループからの3306ポートでの接続を許可します。
※今回はレプリケーションインスタンス作成時に未指定の為、デフォルトのセキュリティグループが適用されています。
※レプリケーションインスタンスのためのネットワークのセットアップ
エンドポイント接続テスト
レプリケーションインスタンスから各エンドポイントへ接続できるかテストを実行します。
以下画像のように、接続のテストを押下しテストを実行しsuccessfulとなることを確認します。
ソースエンドポイント、ターゲットエンドポイント両方とも確認します。

failedとなる場合は、セキュリティグループの設定の不足や
S3への接続に失敗する場合はレプリケーションインスタンスにパブリックIPが割当たっていない、
または、VPCエンドポイントへの接続経路がない、など考えられます。
AuroraDBクラスターパラメータグループ設定
ソースにMySQLを使用する場合、バイナリログを有効にする必要がありますが
デフォルトのパラメータグループでは無効になっている為、新たにパラメータグループを作成の上クラスターへアタッチします。
パラメータグループ作成
後続で使用する為、作成したパラメータグループの名前を変数にセットします。
PARAMETER_GROUP_NAME=`aws rds create-db-cluster-parameter-group \ --db-cluster-parameter-group-name dms-to-s3-cluster-parameter-group \ --db-parameter-group-family aurora-mysql8.0 \ --description dms-to-s3-cluster-parameter-group \ --query DBClusterParameterGroup.DBClusterParameterGroupName \ --output text`
パラメータ修正
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-name ${PARAMETER_GROUP_NAME} \ --parameters \ '[ { "ParameterName": "binlog_format", "ParameterValue": "ROW", "ApplyMethod": "pending-reboot" }, { "ParameterName": "binlog_row_image", "ParameterValue": "full", "ApplyMethod": "pending-reboot" }, { "ParameterName": "binlog_checksum", "ParameterValue": "NONE", "ApplyMethod": "pending-reboot" } ]'
AuroraDBクラスターへアタッチ
DB_CLUSTER_ARNには、自身のDBクラスターのARNを指定します。
aws rds modify-db-cluster \ --db-cluster-identifier <DB_CLUSTER_ARN> \ --db-cluster-parameter-group-name ${PARAMETER_GROUP_NAME}
AuroraDBクラスター再起動
筆者はライターインスタンス1台構成で検証を行っている為、ライターインスタンスを再起動します。
※読み取り可用性のないAuroraクラスターの再起動
aws rds reboot-db-instance \ --db-instance-identifier <DB_INSTANCE>
レプリケーションタスク実行
レプリケーションタスク作成
test_dbというスキーマのテーブルを全て移行します。
テーブル名を指定することで特定のテーブルのみを移行対象とすることも可能です。
既存のデータを移行し、継続的に変更をレプリケートしたい為、full-load-and-cdcを選択します。
aws dms create-replication-task \ --replication-task-identifier dms-to-s3-replication-task \ --source-endpoint-arn $SOURCE_ENDPOINT_ARN \ --target-endpoint-arn $TARGET_ENDPOINT_ARN \ --replication-instance-arn $REPL_INSTANCE_ARN \ --migration-type full-load-and-cdc \ --table-mappings \ '{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test_db", "table-name": "%" }, "rule-action": "include", "filters": [] } ] }'
コンソールでCreatedに変わることを確認します。

レプリケーションタスク実行
再起動/再開を押下し実行します。

検証では15件程度のレコード数の為、あまり参考にはなりませんが完了まで約3分程度かかっていました。
ターゲットエンドポイントにファイルが作成されていることを確認します。

実行結果確認
S3に格納されたイベントログファイルの中身を確認してみます。
1列目のOPにはイベント種別(I, U, D)が格納されます。
users
┌─────┬─────────┬────────────┬───────────┬───────────────────┬─────────────────────────┬─────────────────────────┐ │ Op ┆ user_id ┆ first_name ┆ last_name ┆ email ┆ created_at ┆ updated_at │ │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ │ str ┆ i32 ┆ str ┆ str ┆ str ┆ datetime[μs, UTC] ┆ datetime[μs, UTC] │ ╞═════╪═════════╪════════════╪═══════════╪═══════════════════╪═════════════════════════╪═════════════════════════╡ │ I ┆ 1 ┆ user ┆ 0 ┆ user0@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 2 ┆ user ┆ 1 ┆ user1@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 3 ┆ user ┆ 2 ┆ user2@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 4 ┆ user ┆ 3 ┆ user3@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 5 ┆ user ┆ 4 ┆ user4@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ └─────┴─────────┴────────────┴───────────┴───────────────────┴─────────────────────────┴─────────────────────────┘
posts
┌─────┬─────────┬─────────┬────────┬──────────┬─────────────────────────┬─────────────────────────┐ │ Op ┆ post_id ┆ user_id ┆ title ┆ content ┆ created_at ┆ updated_at │ │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ │ str ┆ i32 ┆ i32 ┆ str ┆ str ┆ datetime[μs, UTC] ┆ datetime[μs, UTC] │ ╞═════╪═════════╪═════════╪════════╪══════════╪═════════════════════════╪═════════════════════════╡ │ I ┆ 1 ┆ 1 ┆ title0 ┆ content0 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 2 ┆ 2 ┆ title1 ┆ content1 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 3 ┆ 2 ┆ title2 ┆ content2 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 4 ┆ 1 ┆ title3 ┆ content3 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 5 ┆ 5 ┆ title4 ┆ content4 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ └─────┴─────────┴─────────┴────────┴──────────┴─────────────────────────┴─────────────────────────┘
comments
┌─────┬────────────┬─────────┬─────────┬──────────┬─────────────────────────┬─────────────────────────┐ │ Op ┆ comment_id ┆ post_id ┆ user_id ┆ comment ┆ created_at ┆ updated_at │ │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ │ str ┆ i32 ┆ i32 ┆ i32 ┆ str ┆ datetime[μs, UTC] ┆ datetime[μs, UTC] │ ╞═════╪════════════╪═════════╪═════════╪══════════╪═════════════════════════╪═════════════════════════╡ │ I ┆ 1 ┆ 5 ┆ 4 ┆ comment0 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 2 ┆ 2 ┆ 3 ┆ comment1 ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ │ I ┆ 3 ┆ 5 ┆ 2 ┆ comment2 ┆ 2024-08-14 00:00:37 UTC ┆ 2024-08-14 00:00:37 UTC │ │ I ┆ 4 ┆ 3 ┆ 5 ┆ comment3 ┆ 2024-08-14 00:00:37 UTC ┆ 2024-08-14 00:00:37 UTC │ │ I ┆ 5 ┆ 3 ┆ 5 ┆ comment4 ┆ 2024-08-14 00:00:37 UTC ┆ 2024-08-14 00:00:37 UTC │ └─────┴────────────┴─────────┴─────────┴──────────┴─────────────────────────┴─────────────────────────┘
AuroraMySQL側にレコードが追加/更新/削除されると、以降は増分ファイルがS3に出力されますが
このままではテーブルとしては使用できないので、変更データを取り込むためIcebergを使用します。
Icebergテーブルへの反映
初回取り込み
Icebergテーブル作成
テーブルの作成方法はいくつかありますが、今回はAthenaクエリエディタからクエリ実行します。
以降の手順では、usersテーブルのみを対象に進めます。
CREATE DATABASE IF NOT EXISTS dms_test_db;
CREATE TABLE dms_test_db.iceberg_users ( user_id bigint, email string, first_name string, last_name string, created_at string, updated_at string) LOCATION 's3://<BUCKET_NAME>/iceberg_output/' TBLPROPERTIES ( 'table_type'='ICEBERG', 'format'='parquet' )
Glueジョブ実行
Glue ETLスクリプトエディタから以下のようなジョブを作成します。
EngineにはSparkを使用し、ジョブブックマークを有効化しています。
スクリプトの内容は参考1のブログを参考にしています。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from pyspark.conf import SparkConf from pyspark.sql.window import Window from pyspark.sql.functions import rank, max from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ['JOB_NAME']) AWS_ACCOUNT_ID = 123456789012 CATALOG_NAME = "glue_catalog" DB_NAME = "dms_test_db" TABLE_NAME = "iceberg_users" # Icebergフレームワークの有効化 conf = SparkConf() conf.set(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"s3://dms-to-s3-{AWS_ACCOUNT_ID}/iceberg_output/") conf.set(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") conf.set(f"spark.sql.catalog.{CATALOG_NAME}.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") conf.set(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") sc = SparkContext.getOrCreate(conf=conf) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) users_dyf = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={ "paths": [f"s3://dms-to-s3-{AWS_ACCOUNT_ID}/raw_input/test_db/users"], }, format="parquet", transformation_ctx="RawInputUsers" ) users_dyf.printSchema() users_df = users_dyf.toDF() users_df.show() if not users_df.rdd.isEmpty(): # user_id毎に更新日時(updated_at)順にソートする IDWindowDF = Window.partitionBy(users_df.user_id).orderBy(users_df.updated_at).rangeBetween(-sys.maxsize, sys.maxsize) # user_id毎の最新の更新日時(updated_at)をmax_op_date列に格納 inputDFWithTS= users_df.withColumn("max_op_date",max(users_df.updated_at).over(IDWindowDF)) # 更新日時(updated_at)がmax_op_dateと一致する、各OPのレコードを抽出する NewInsertsDF = inputDFWithTS.filter("updated_at=max_op_date").filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter("updated_at=max_op_date").filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) # 重複排除したデータを一時テーブルに書き込む finalInputDF.createOrReplaceTempView("incremental_input_data") finalInputDF.show() # イベント種別に応じたマージ処理を行う IcebergMergeOutputDF = spark.sql(f""" MERGE INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME} t USING (SELECT op, user_id, email, first_name, last_name, to_timestamp(created_at) as created_at, to_timestamp(updated_at) as updated_at FROM incremental_input_data) s ON t.user_id = s.user_id WHEN MATCHED AND s.op = 'D' THEN DELETE WHEN MATCHED THEN UPDATE SET t.email = s.email, t.first_name = s.first_name, t.last_name = s.last_name, t.created_at = s.created_at, t.updated_at = s.updated_at WHEN NOT MATCHED THEN INSERT (user_id, email, first_name, last_name, created_at, updated_at) VALUES (s.user_id, s.email, s.first_name, s.last_name, s.created_at, s.updated_at) """) job.commit()
作成したジョブを実行します。
Athenaで初回取り込みの結果を確認
SELECT * FROM dms_test_db.iceberg_users;

増分取り込み
ソースDBに対して、適当に挿入/更新/削除を行ってみます。
今回は、以下のようなクエリをソースDBで実行し増分ファイルがS3に作成されること、
Glueジョブ実行後にテーブルに反映されることを確認します。
mysql> select * from users; +---------+------------+-----------+-------------------+---------------------+---------------------+ | user_id | first_name | last_name | email | created_at | updated_at | +---------+------------+-----------+-------------------+---------------------+---------------------+ | 1 | user | 0 | user0@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 2 | user | 1 | user1@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 3 | user | 2 | user2@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 4 | user | 3 | user3@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 5 | user | 4 | user4@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | +---------+------------+-----------+-------------------+---------------------+---------------------+ 5 rows in set (0.00 sec) mysql> mysql> insert into users (first_name, last_name, email) VALUES ("user", 5, "user5@example.com"); Query OK, 1 row affected (0.01 sec) mysql> update users set email="update-user0@example.com" where user_id=1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> delete from users where user_id=4; Query OK, 1 row affected (0.01 sec)
しばらくすると、DMSのレプリケーションタスクにより以下のようにS3バケットに増分ファイルが取り込まれます。
日付入りのファイルが増分ファイル、LOAD00000**.parquetがフルロード時のファイルです。

以下はusersの増分ファイルの中身です。
┌─────┬─────────┬────────────┬───────────┬──────────────────────────┬─────────────────────────┬─────────────────────────┐ │ Op ┆ user_id ┆ first_name ┆ last_name ┆ email ┆ created_at ┆ updated_at │ │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ │ str ┆ i32 ┆ str ┆ str ┆ str ┆ datetime[μs, UTC] ┆ datetime[μs, UTC] │ ╞═════╪═════════╪════════════╪═══════════╪══════════════════════════╪═════════════════════════╪═════════════════════════╡ │ I ┆ 6 ┆ user ┆ 5 ┆ user5@example.com ┆ 2024-08-14 00:26:34 UTC ┆ 2024-08-14 00:26:34 UTC │ │ U ┆ 1 ┆ user ┆ 0 ┆ update-user0@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:26:42 UTC │ │ D ┆ 4 ┆ user ┆ 3 ┆ user3@example.com ┆ 2024-08-14 00:00:36 UTC ┆ 2024-08-14 00:00:36 UTC │ └─────┴─────────┴────────────┴───────────┴──────────────────────────┴─────────────────────────┴─────────────────────────┘
Glueジョブ実行
S3に増分ファイルが格納されたことを確認し、先ほど作成したGlueETLジョブを再度実行します。
Glueジョブ実行ログに出力したDataFrameの結果を確認すると
ジョブブックマークにより、増分ファイルのみが対象となっています。

Athenaで増分取り込みの結果を確認
SELECT * FROM dms_test_db.iceberg_users ORDER BY user_id;

ソースDBでの実行結果と一致しています。
mysql> select * from users; +---------+------------+-----------+--------------------------+---------------------+---------------------+ | user_id | first_name | last_name | email | created_at | updated_at | +---------+------------+-----------+--------------------------+---------------------+---------------------+ | 1 | user | 0 | update-user0@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:26:42 | | 2 | user | 1 | user1@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 3 | user | 2 | user2@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 5 | user | 4 | user4@example.com | 2024-08-14 00:00:36 | 2024-08-14 00:00:36 | | 6 | user | 5 | user5@example.com | 2024-08-14 00:26:34 | 2024-08-14 00:26:34 | +---------+------------+-----------+--------------------------+---------------------+---------------------+ 5 rows in set (0.00 sec)
課題
上記で、usersテーブルのレコードを1件削除しましたが、user_idを外部キーとして参照している子テーブルにて
ON DELETE CASCADEにより子テーブル側でレコードが削除された場合、MySQL側でbinlogイベントを生成しない為、変更をキャプチャできないようです。
回避方法の検証までは今回は行っておりません。
※MySQLをソースとして使用する場合の制限
※インデックス、外部キー、カスケード更新、または削除が移行されない
おわりに
かなり長くなってしまいましたが、
今回はDMSとIcebergを合わせて利用することでS3への継続的なレプリケーションを実現できました。
上記課題にも記載したような、利用にあたって事前に確認しておいた方がよい仕様もありますので
機会があれば改めて記事にしたいと思います。
最後までご覧いただきありがとうございました。
参考
- Implement a CDC-based UPSERT in a data lake using Apache Iceberg and AWS Glue | AWS Big Data Blog
- MySQL 互換データベースの AWS DMSのソースとしての使用 - AWS データベース移行サービス
- のターゲットとしての Amazon S3 の使用 AWS Database Migration Service - AWS データベース移行サービス
- Writes - Apache Iceberg™
鎌田 義章 (執筆記事一覧)
2023年4月入社 アプリケーションサービス本部ディベロップメントサービス3課