

AWS re:Invent 2024から帰国した小菅です。
2024年12月02日~06日でラスベガスで開催されたAWS re:invent 2024に参加してまいりました。
Keynoteでのアップデート、数多くのブレイクアウトセッションがある中で
今回は、Keynoteで紹介がありましたAmazon S3 Tablesを実際にクエリを実行してみるところまで実施してみました。
Amazon S3 Tablesとは
Amazon S3 Tablesは、Apache Icebergをサポートする初のクラウドオブジェクトストアであり、大規模な表形式データの保存を効率化します。 S3 Tablesは、汎用のS3バケットに格納された自己管理Icebergテーブルと比較して、最大3倍のクエリパフォーマンスと最大10倍のトランザクション/秒を実現し、分析ワークロードに特に最適化されています。 Apache Iceberg標準のS3 Tablesサポートにより、表形式データはAmazon Athena、Redshift、EMR、Apache Sparkを含む一般的なAWSやサードパーティのクエリエンジンで簡単にクエリできます。 S3 Tablesを使用して、毎日の購買トランザクション、ストリーミングセンサーデータ、または広告インプレッションなどの表形式データをS3にIcebergテーブルとして保存し、自動テーブルメンテナンスを使用してデータの進化に合わせてパフォーマンスとコストを最適化します。
要するに、
- 新しいバケットタイプ
- Apache Icebergのテーブルを扱うのに最適
- テーブルメンテナンス、削除、継続的なコストとパフォーマンスを最適化する
と理解しました。
検証
公式ドキュメントにチュートリアルが用意されていたためそれをベースに実施。
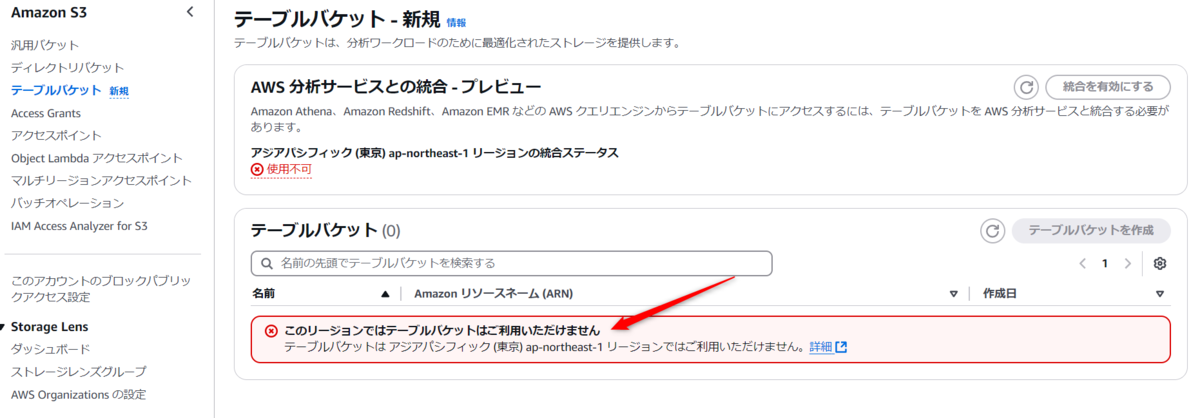
また、今回の検証では東京リージョン(ap-northeast-1)では利用できなかったので、
バージニア北部リージョン(us-east-1) を使って検証します。
1. テーブルバケット作成
Amazon S3のコンソール画面から「テーブルバケット」を選択します。
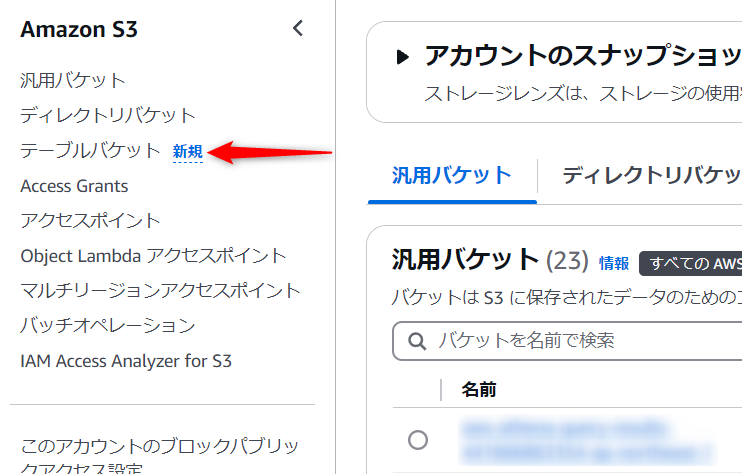
「テーブルバケット名」を入力し、AWS 分析サービスとの統合 - プレビューの「統合を有効にする」にチェックを入れて作成。
※AWS 分析サービスとの統合については、2024/12/09時点はプレビュー機能です。
2. Amazon EMR クラスターを作成し、Spark セッションを起動する
Sparkを実行する環境を用意する必要がありますが、今回は公式チュートリアルに記載の通り、EMRクラスターを用意してSparkを使える状態にします。
EMRクラスターの作成については、 Cloudshellを利用しました。
公式チュートリアルでは、早速EMRクラスターを構築しようとしてますが、事前にいくつかやることがあったため共有します。
①初めてEMRを利用される方でデフォルトのIAMロールやEMRサービスロールが用意されていない方は以下コマンドを実行して作成しましょう。
aws emr create-default-roles
②--log-uriに指定するEMRログ用のバケットをあらかじめ作成しておきましょう。
③キーペアを作成しておきましょう。
用意ができましたら、チュートリアル記載の通りconfigurations.jsonを用意したうえで少し改変したクラスター作成コマンドを実行していきます。
EMRからS3やAthenaなどの通信経路が必要になるため、PrivateLinkで通信可能なサブネットもしくはインターネット経由で通信可能なサブネットをご指定ください。
aws emr create-cluster --release-label emr-7.5.0 \ --applications Name=Spark \ --configurations file://configurations.json \ --region us-east-1 \ --name My_Spark_Iceberg_Cluster \ --log-uri s3://<EMRログ用バケット名>/ \ --instance-type m5.xlarge \ --instance-count 2 \ --service-role EMR_DefaultRole \ --ec2-attributes \ InstanceProfile=EMR_EC2_DefaultRole,SubnetId=<※AWS各サービスと通信が可能なサブネットID>,KeyName=<キーペア名>
ステータスが開始中から待機中になるのを待ちます。
(検証中に何度も試行錯誤したEMRクラスターの残骸は見なかったことにしてください笑)
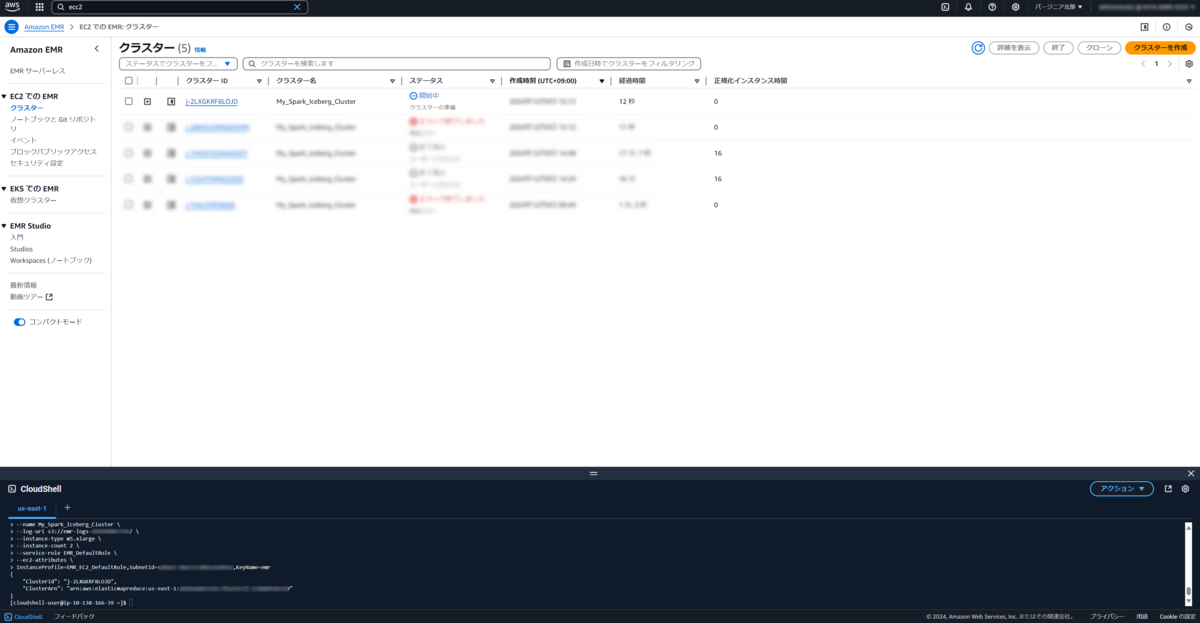
3. SSH接続
ステータスが待機中になったら、接続していきます。
以下コマンドで接続します。
aws emr ssh --cluster-id j-2LXGKRF8LOJD --key-pair-file <キーペア名>
クラスターIDは、GUIから確認いただけますが、以下コマンドでも確認可能です。
aws emr list-clusters
1点注意ですが、プライマリノードにSSH接続することになりますが、 セキュリティグループで接続元を許可することをお忘れなく。
私はローカルから接続することにしたため、疎通できるように設定変更しました。
接続ができるとこんな画面になります。
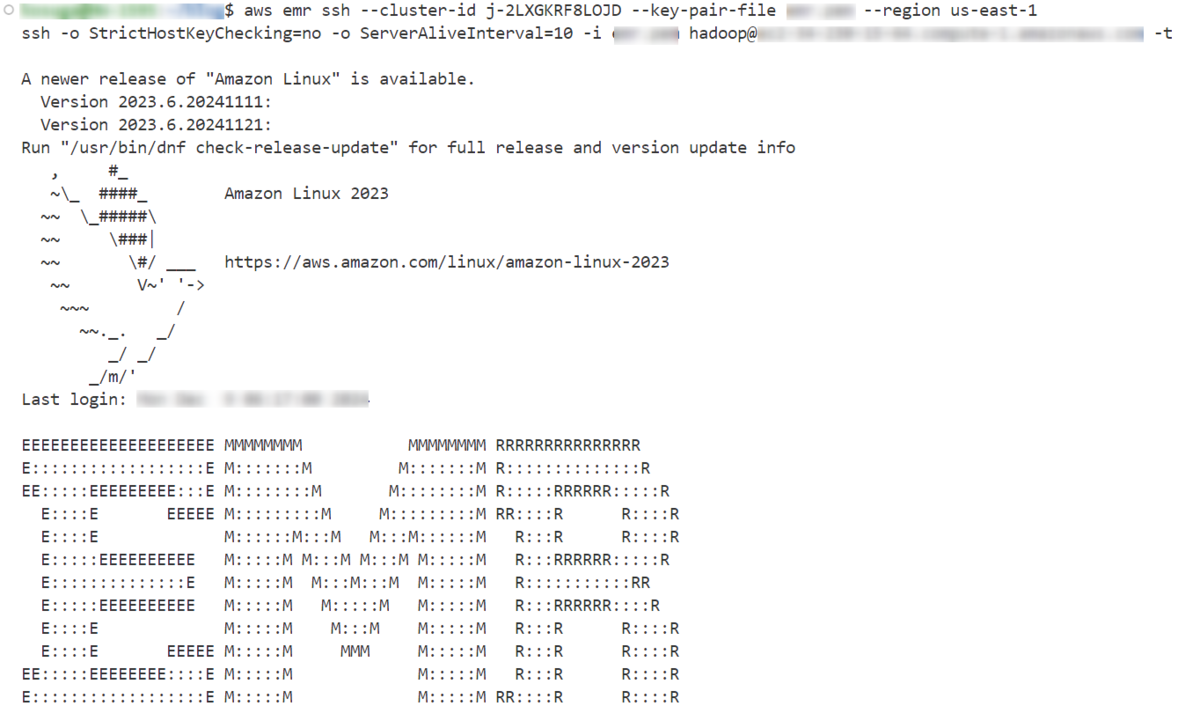
4. Sparkシェル起動
以下コマンドでSparkシェルを起動しSparkセッションを初期化します。
spark-shell \ --packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \ --conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \ --conf spark.sql.catalog.s3tablesbucket.warehouse=<ここにテーブルバケットのARNを入力します> \ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
5. テーブルを作成し、データ挿入
Spark セッションで SQL クエリを使用して名前空間とテーブルを作成する必要があります。
まずは、名前空間を作成します。
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.test_namespace")
次に、テーブルを作成します。
私は独自のデータを挿入してみたかったためテーブルの型はチュートリアルと異なります。
データを用意されていない方は、チュートリアルの通りのテーブル定義でよいかと思います。
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.test_namespace.`table_bucket` (
id INT,
name STRING,
age INT,
email STRING,
date DATE,
amount FLOAT
)
USING iceberg """
)
ここまでやると、GUIのテーブルバケットの画面では作成したテーブルが表示されます。
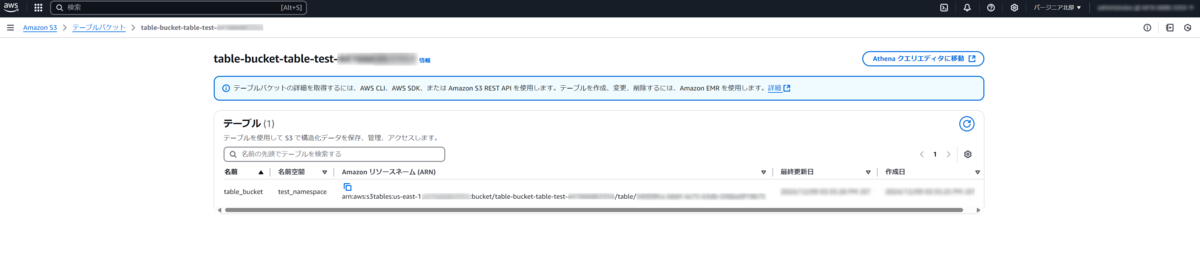
データ挿入については、データを用意されていない方は、チュートリアル通りのINSERT文でお試しください。
私は30000行のParquetファイルからデータを挿入してみたかったので、まずは ParquetファイルをS3に配置した後に データをSparkに読み込みます。
val data_file_location = "<ParquetファイルのS3 URI>" val data_file = spark.read.parquet(data_file_location)

読み込んだデータをもとにテーブルに書き込みます。
data_file.writeTo("s3tablesbucket.test_namespace.table_bucket").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
![]()
6. クエリ実行
チュートリアル通り、Sparkクエリを実行しました。
spark.sql(""" SELECT * FROM s3tablesbucket.test_namespace.`table_bucket` """).show()
結果は以下の通り無事結果が返ってきました。
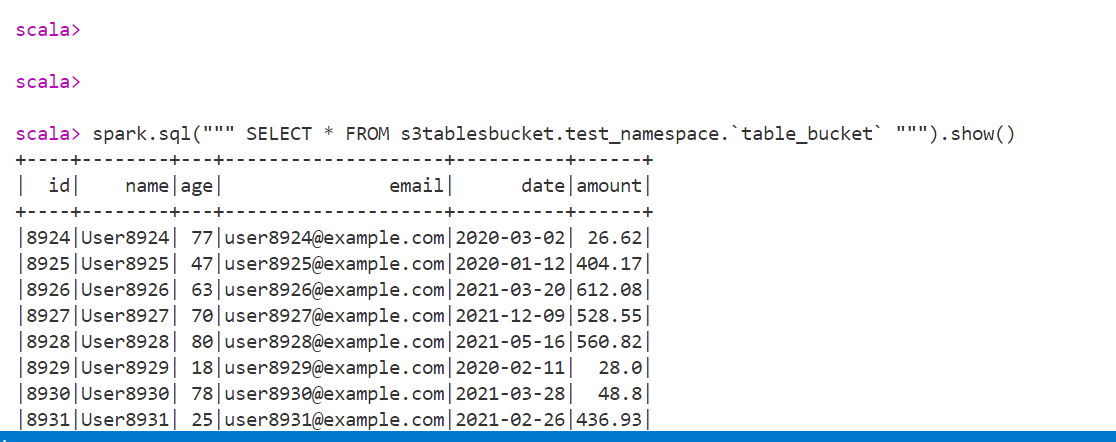
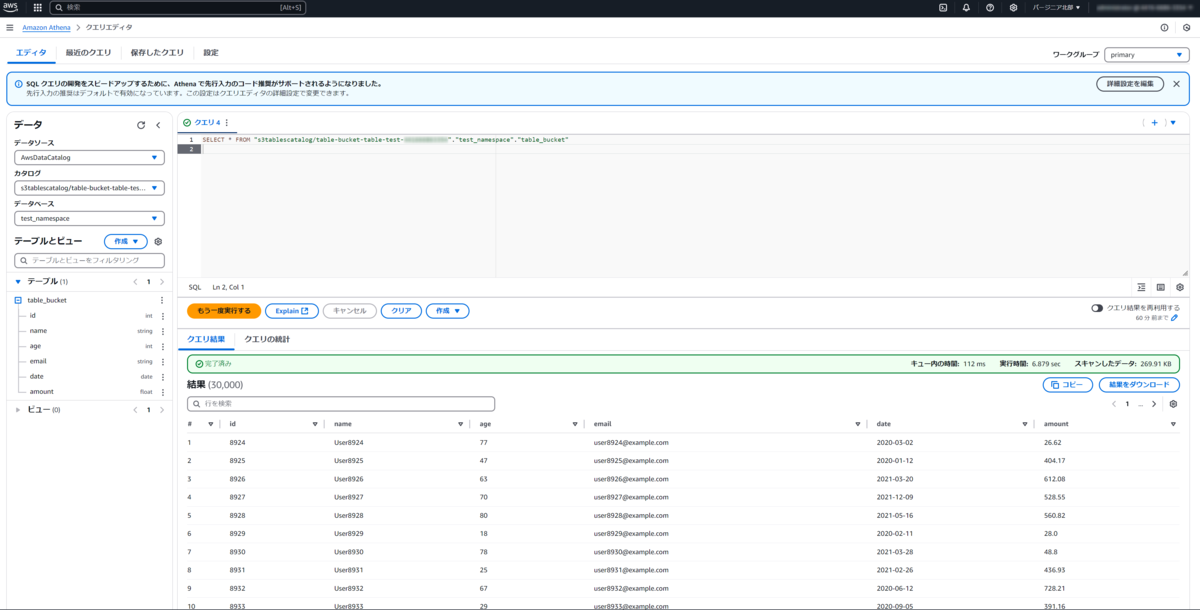
ちなみに、Athenaの画面からもクエリができました。
感想
新しいバケットタイプと言うからにはS3バケットのようにデータとなるオブジェクトがみえるかと思いましたが、ユーザーには見えないようでちょっと慣れるまでに時間がかかりそうです。
このアップデートの本筋とはズレますが、個人的にHive形式でデータ分析することが多かったんですが、このアップデートのみならずApache Icebergに絡んだAWSアップデートも増加しているため、Apache Iceberg形式をスタンダートとして利用することに慣れておかないといけないなと思いました。
とにもかくにも、データ分析に特化した形でS3に新機能が追加されたことは大変うれしく思ってますので今後もどのように変化していくのか楽しみです!
小菅 信幸(執筆記事の一覧)
仙台在住/サウナをこよなく愛するエンジニア
2024 Japan AWS All Certifications Engineers