


こんにちは、カスタマーサクセス部カスタマーサクセス2課の畑野です。 普段、システム運用に携わっている身の為、システム障害に敏感です。
そういった障害に備えた訓練方法の1つとして、カオスエンジニアリングがあり、 たまたま見つけたセッション名で「Chaos」の文字から不穏な雰囲気を察知し、興味本位で参加することにしました。
カオスエンジニアリングとは
「カオスエンジニアリングは、システムが本番環境における不安定な状態に耐える能力へ自信を持つためにシステム上で実験を行う訓練方法です。」
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
カオスエンジニアリングってなに? | CTC - 伊藤忠テクノソリューションズ ※引用元
本番環境で実際に障害を発生させ、その復旧を行うということで訓練とはいいつつも冷や汗を飛び越えて、心臓が飛び出しそうな試みです。 記事を書いていて気付いたのですが、なんとセッションスライド等の写真が1枚も残っていませんでした。カメラのデータを誤って削除してしまっていました。のっけからカオスの始まりです。
セッション概要
参加したセッションはこちらです。 ARC326: Chaos Engineering: A Proactive approach to system resilience
根本的な障害にさらされたときに、システムが意図したとおりに動作するかどうかを知っていますか?本セッションでは、カオスエンジニアリングがどのように組織のシステム回復力の弱点をプロアクティブに特定し、オペレーショナルエクセレンスを向上させ、インシデント対応能力を強化するかを探ります。このセッションでは、AWS Fault Injection Service (FIS)で実行される実際のシナリオを通して、カオスエンジニアリングの利点を実際に示します。BMWグループの変革の旅から洞察し、カオスエンジニアリングを組織全体に拡大するための重要な教訓を学びます。また、BMWグループがどのように大規模なカオス実験を本番環境で実施し、問題を発見し、より高い回復力と継続的な改善の文化を醸成しているかを紹介します。
Do you know if your system will behave as intended when exposed to underlying failures? In this session, explore how chaos engineering enables organizations to proactively identify system resilience weaknesses, improve operational excellence, and enhance incident response capabilities. Through real-world scenarios executed with the AWS Fault Injection Service (FIS), this session demonstrates the benefits of chaos engineering in action. Gain insights from BMW Group’s transformative journey, learning key lessons on scaling chaos engineering across the organization, and how BMW Group conducts large-scale chaos experiments in production, uncovering issues and fostering a culture of greater resilience and continuous improvement.
障害原因として、アプリケーションやミドルウェアのタイムアウト値が適切に設定されていないケースが取り上げられていました。 ミドルウェアによってはデフォルトタイムアウト値が長すぎたり、そもそもなかったりします。
例えば、PythonのRequestsライブラリのタイムアウト値はデフォルト値が設定されていない、という話がありました。 リクエスト先がダウンしていても延々と接続を試みることで、さらに障害を引き起こしかねません。
またシステム障害を多く経験する程、より優れたエンジニアになれる、といった発言もありました。 復旧するための調査手段等がナレッジとして蓄積し、エンジニアを育てるということはあると思います。
デモでは実際に障害を発生させて、復旧を試みていました。
AWS上で疑似障害を発生させる方法
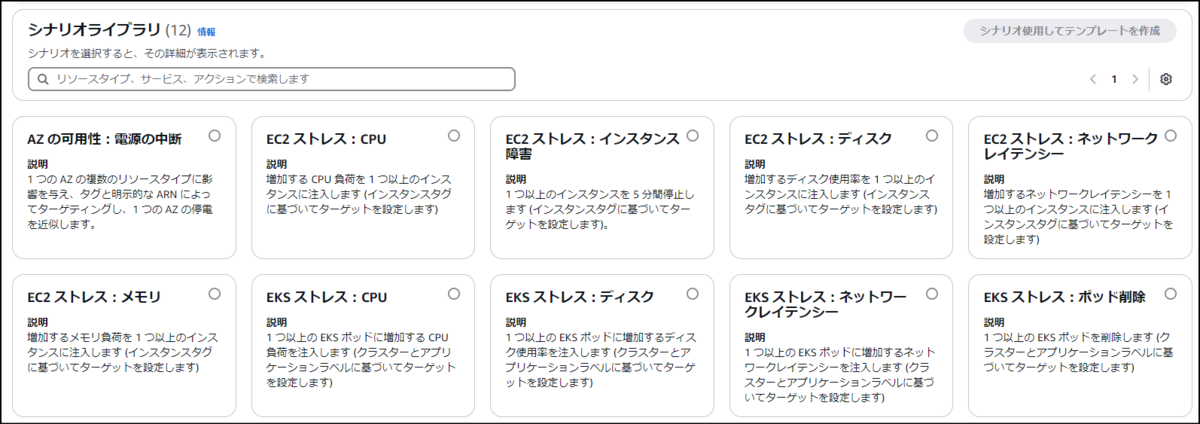 AWS Fault Injection Service (FIS)でAWSのサービスを意図的に障害状態とすることが出来ます。
一例ですが、AZの可用性に問題を引き起こす電源の中断等があります。
記事を書いているだけで手が震えてきました。
AWS Fault Injection Service (FIS)でAWSのサービスを意図的に障害状態とすることが出来ます。
一例ですが、AZの可用性に問題を引き起こす電源の中断等があります。
記事を書いているだけで手が震えてきました。
セッションでは実際にElastiCache(Redisクライアントのタイムアウト値)を例にデモを行っていました。 冒頭で話のあったタイムアウト値に関するアプローチのため、印象に残るデモでした。
セッション後に公開されたブログ
BMW Groupのカオスエンジニアリングについて、セッション後に公開されたブログです。 同社のカオスエンジニアリングの取り組み、AWS FISをどのように利用して訓練したかが記載されています。
最後に
システム障害は完全に防ぐことはとても難しいことです。 私はAmazonのCTOであるWerner Vogels氏が提言されているように障害は発生するものと受け入れます。
対策として例えば、本記事で取り上げたカオスエンジニアリングのような訓練を元に、システムの耐障害性や回復性を考え、安定稼働を目指していきたいです。