


コーヒーが好きな木谷映見です。
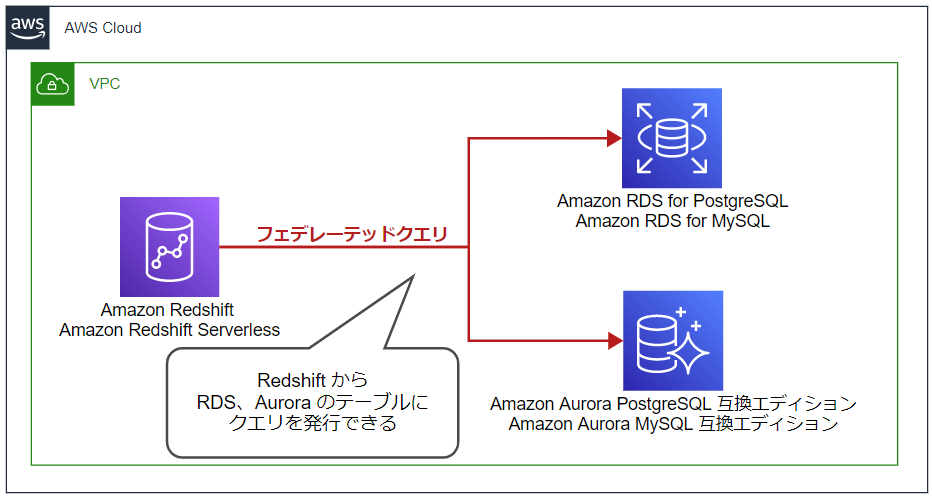
Amazon Redshift はフェデレーテッドクエリをサポートしています。
今回は、フェデレーテッドクエリの概要について記載します。
フェデレーテッドクエリとは
Redshift から外部データベースのテーブルに直接クエリできる機能です。
データ本体は外部データベースに置いたまま、外部データベースのテーブルにクエリを発行して分析に利用できます。
データベースに詳しい方は、データベースリンクの機能と言われるとピンとくるかもしれません。
以下のデータベースに Redshift から直接クエリを発行できます。
- Amazon RDS for PostgreSQL
- Amazon Aurora PostgreSQL 互換エディション
- Amazon RDS for MySQL
- Amazon Aurora MySQL 互換エディション
フェデレーテッドクエリは日本語訳すると「横串検索」と表示されることがありますが、「横串検索」は複数のデータベースを縦断して検索できる機能の総称を表します。「横断検索」とも言うようです。
フェデレーテッドクエリでできること
- 外部データベースを直接クエリできる
- データの実体をコピーすることなく、すばやくデータ変換できる
- 複雑な抽出、変換、読み込み(ETL)パイプライン不要で、データを Redshift のテーブルに読み込める
- BI ツールやレポートアプリケーションにライブデータを組み込むことができる
- ライブデータ:直近の集計されていないデータのこと
フェデレーテッドクエリでできないこと
- 外部データベースへの読み取りアクセスのみ許可されており、書き込みは不可
- 逆方向へのアクセス(外部データベース⇒ Redshift)はできない
フェデレーテッドクエリのユースケース
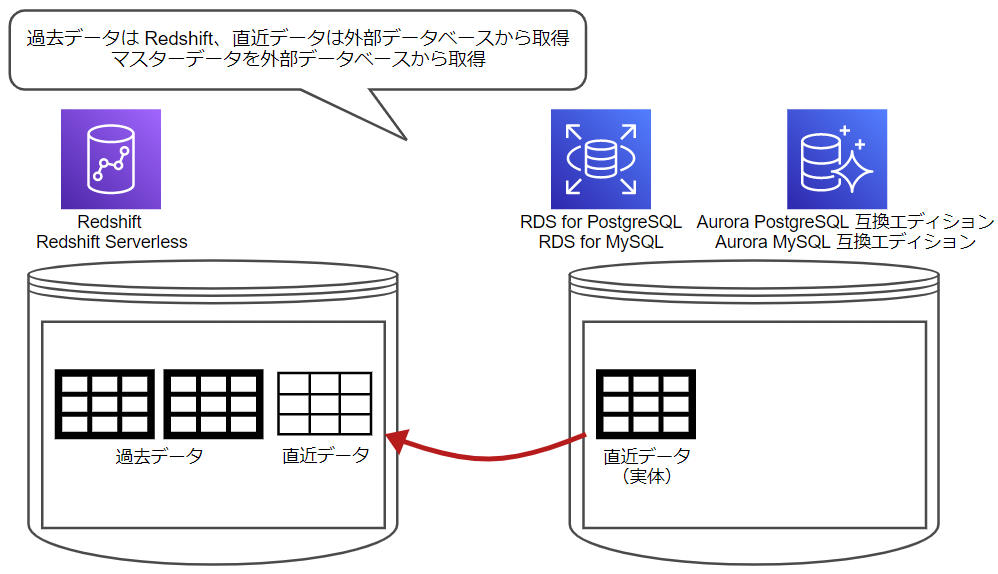
- 過去データは Redshift、直近データは外部データベースから取得
- マスターデータを外部データベースから取得
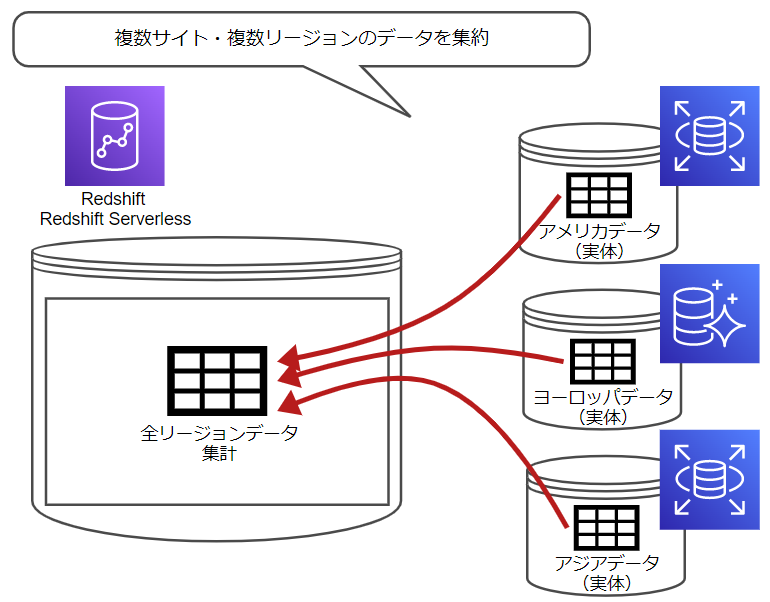
- 複数サイト・複数リージョンのデータを集約
- 外部データベースのデータを SQL で ETL
フェデレーテッドクエリの仕組み
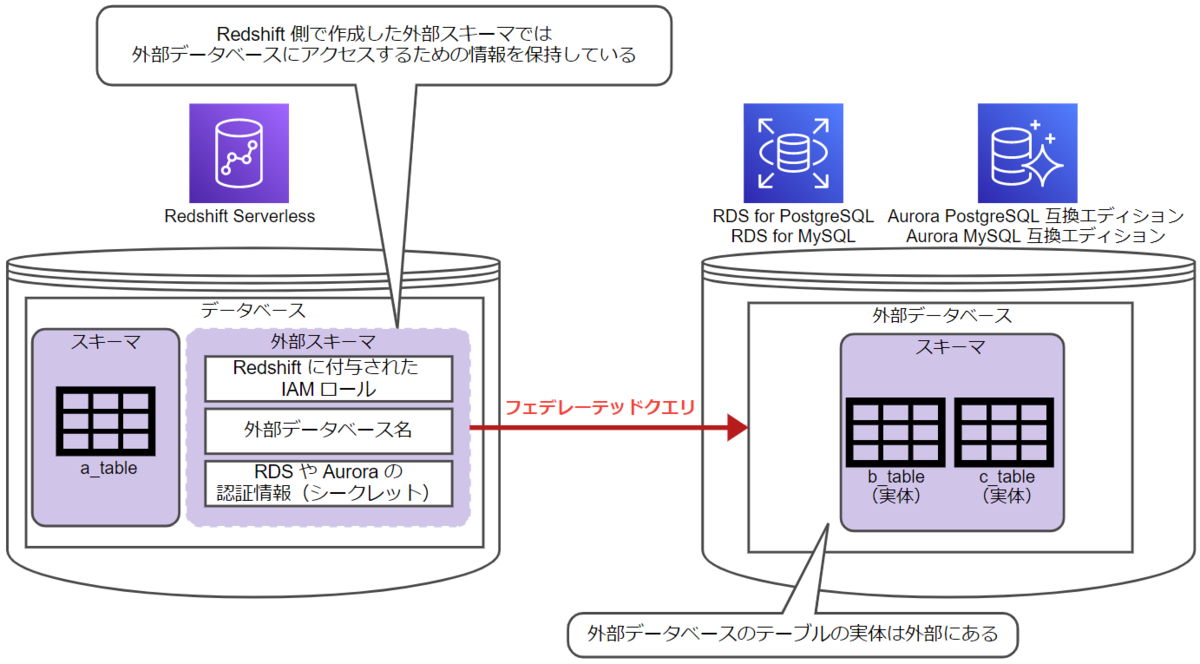
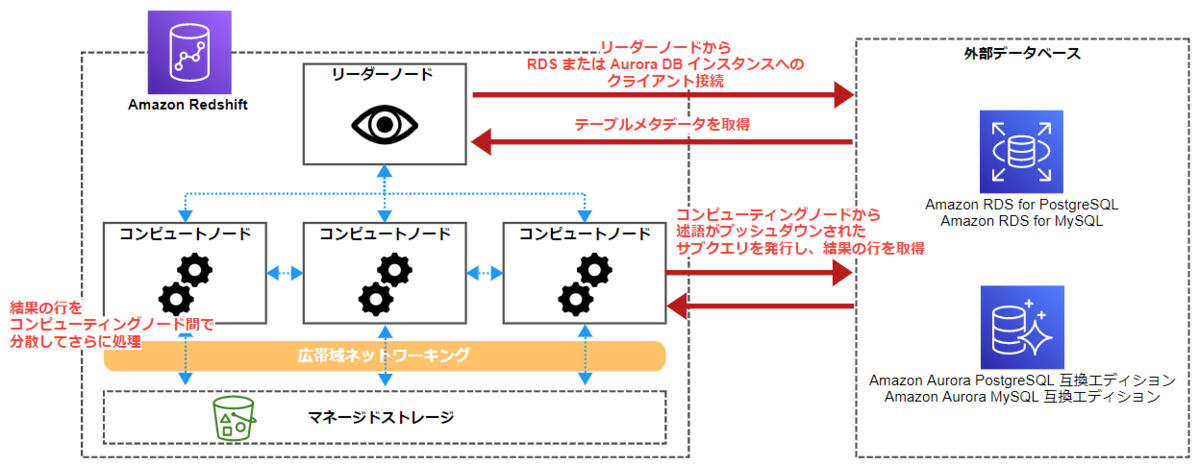
フェデレーテッドクエリでは、Redshift 側で作成する外部スキーマを使用して、外部データベースに接続できます。
Redshift 側で作成した外部スキーマには、外部データベースにアクセスするための情報を与えます。この情報をもとに、外部データベースにアクセスします。外部データベースのテーブルの実体は外部にあります。
ネットワーク上のデータ移動を減らしてパフォーマンスを向上させるため、Redshift はフェデレーテッドクエリの処理の一部を外部データベースに分散します。必要に応じてこれらのクエリの実行をサポートするために、Redshift の並列処理能力も使用します。

フェデレーテッド クエリを実行する場合、Redshift は最初にリーダーノードから RDS または Aurora DB インスタンスへのクライアント接続を行い、テーブルメタデータを取得します。
コンピューティングノードから、述語がプッシュダウンされたサブクエリを発行し、結果の行を取得します。
Redshift は結果の行をコンピューティングノード間で分散してさらに処理します。
Amazon Aurora PostgreSQL データベースまたは Amazon RDS for PostgreSQL データベースに送信されたクエリの詳細は、システムビュー SVL_FEDERATED_QUERY に記録されます。
おわりに
Redshift でのフェデレーテッドクエリの概要についてまとめました。
外部データベースからデータ本体をコピーせずとも直接クエリできるということで、「データをわざわざ Redshift にコピーするほどでもないが直近のデータだけほしい」「外部データベースが多くのリージョンに存在していていちいちデータをコピーしてくるのが面倒」というケースで使えそうだなと感じました。
実際のフェデレーテッドクエリ手順は以下のブログをご参照ください。
参考
Amazon Redshift 最前線 ~Dive Deep & Update~
【What's New with AWS?】Amazon Redshift announces general availability for federated querying
【What's New with AWS?】Announcing general availability of Amazon RDS for MySQL and Amazon Aurora MySQL databases as new data sources for federated querying
Amazon Redshift での横串検索を使用したデータのクエリの実行 - Amazon Redshift
Amazon Redshift でフェデレーテッドデータにアクセスする際の制約事項と考慮事項 - Amazon Redshift
Amazon Redshift が Microsoft Azure Active Directory と Microsoft Power BI とのネイティブ統合を発表
「述語プッシュダウン」「プリディケイトプッシュダウン」について、Datastax Enterprise のドキュメントが分かりやすく参考になりました。
【DSE 6.7 開発者ガイド】Spark SQLクエリーでのSpark述語プッシュ・ダウンの使用
述語は、通常はWHERE句にあるtrueまたはfalseを返すクエリーの条件です。述語プッシュ・ダウンは、データベース・クエリー内のデータをフィルター処理し、データベースから取得するエントリーの数を減らすことで、クエリーのパフォーマンスを向上させます。
emi kitani(執筆記事の一覧)
AS部LX課。2022/2入社、コーヒーとサウナが好きです。執筆活動に興味があります。AWS認定12冠。