

ES課研修中の佐藤(こ)です。
突然ですが、つい最近AWS re:Invent 2024でも発表されていたAmazon S3 MetadataがついにGAとなりました!
Amazon S3 Metadata is now generally available - AWS
東京リージョンではまだ利用できませんが、この機能によりオブジェクト単位のメタデータの加工や可視化が一層便利になるのは間違いありません。
この機能を使って「オブジェクトをメタデータで管理したい」といった需要は今後高まってくるのではないでしょうか?
独自定義のメタデータをどのように管理するか
メタデータを使ってオブジェクトを管理したい場合、 独自定義のメタデータ を使いたいというケースは少なくないと思います。
例えば以下のようなケースです。
- オブジェクトに機密レベルを設定する(
confidential_level=Sなど) - アクセス制御に使う(ABACベースの制御を行うなど)
- オブジェクトのライフサイクルルールのフラグ管理をする(
to_archive=Trueが付いたオブジェクトはGlacierに移行するなど)
このような要望を叶える機能として、Amazon S3(以下:S3)では従前から以下の機能が存在していました。
- オブジェクトタグ(リソースのタグと区別するために、この機能のことをオブジェクトタグと呼びます)
- オブジェクトメタデータ(広義のメタデータと区別するために、この機能のことを以下略)
ところでこの2つは何が違うのでしょうか。
マネジメントコンソールからオブジェクトを見ると別個に管理されていることはわかりますが、Ker-Valueで管理するという点においてはどちらも同じに見えます。
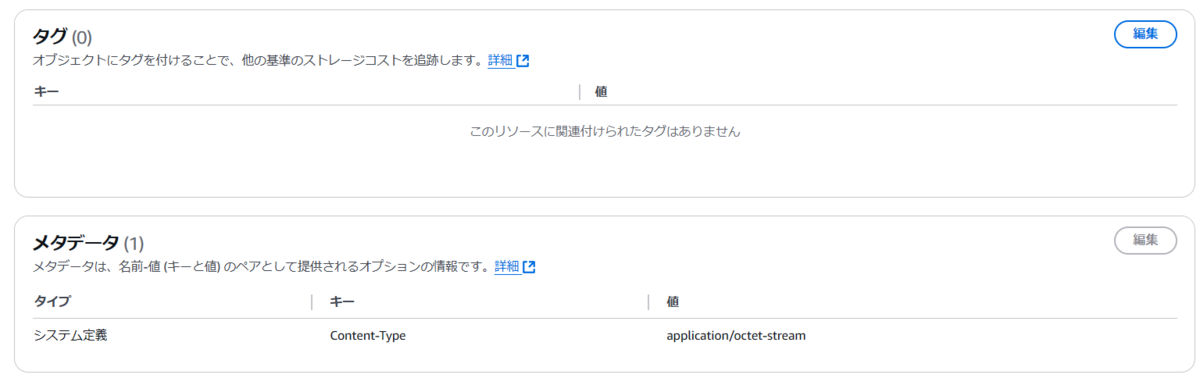
ちなみにいずれもS3 Metadataのテーブルスキーマのドキュメントを確認すると、それぞれobject_tagsとuser_metadataとして同じMap型でカラムが用意されていることがわかりますので、S3 Metadataとしての使い勝手という観点でも同じです。
S3 Metadata tables schema - Amazon Simple Storage Service
【結論】オブジェクトタグとオブジェクトメタデータの違いは?
ぱっと見の印象は「どっちも同じことができるんじゃないの?」だと思います。
ただ結論から言うと、これらは 制約や使い勝手の面が異なります。
具体的には Key-Valueの数の上限、文字数の上限、使える文字、編集方法 などに明確な違いがあります。
どう違うのかをまとめた表が以下のものです(ドキュメントに明確な記載がない部分もあり、検証ベースの見解が含まれます)。
| 機能 | オブジェクトタグ | オブジェクトメタデータ |
|---|---|---|
| Key-Valueの上限 | 10個まで | なし(容量に抵触しない範囲で) |
| 文字数制限 | Key: 128文字 Value: 256文字 |
ヘッダ全体で2KB以内 |
| 大文字と小文字の区別 | される | されない(全て小文字) |
| 使用できる文字 | Unicode文字列 ※ただし、恐らく以下の正規表現に合致する文字列のみ? ^([\p{L}\p{Z}\p{N}_.:/=+\-@]*)$ |
Unicode文字列 ※ただし非US-ASCII文字列はURLエンコードが必要 |
| 既存オブジェクトの編集方法 | タグだけ編集可能 ※PutObjectTaggingなど専用のAPIオペレーションがある |
単体での編集は不可、オブジェクトごとCOPY(上書き)が必要 |
オブジェクトタグの仕様
仕様はドキュメントに記載がありますが、ファジーな部分のみ抜粋して要約します。
タグを使用してストレージを分類する - Amazon Simple Storage Service
オブジェクトタグの管理 - Amazon Simple Storage Service
使用できる文字
引用にあるリンク先の「タグの制限」ページを確認すると、 「EC2 ではタグ内に任意の文字を使用できますが、他の AWS のサービスでは制限があります。すべての AWS のサービスで使用できる文字はUTF-8 で表現できる英字 (a-z、A-Z)、数字 (0-9)、スペース、および + - = . _ : / @ です。」 という記載があります。
オブジェクトタグで具体何が利用できないかまでは書いていないのですが、少なくとも上記に記載の具体的な文字列は利用可能と推定されます(実際のユースケースで使われがちな日本語に関する言及がないのですが、後ほど検証します)。
タグの制限の詳細については、「AWS Billing and Cost Management ユーザーガイド」の「User-defined tag restrictions」を参照してください。基本的なタグの制限については、「Amazon EC2 ユーザーガイド」の「タグの制限」を参照してください。
オブジェクトメタデータの仕様
仕様はドキュメントに記載がありますが、ファジーな部分のみ抜粋して要約します。
オブジェクトメタデータの使用 - Amazon Simple Storage Service
Amazon S3 コンソールでのオブジェクトメタデータの編集 - Amazon Simple Storage Service
使用できる文字列
「Unicode文字を使うことができる」「US-ASCII以外の文字列を検知するとRFC 2047に従ってデコードとエンコードが行われる(※MIME)」とある一方で、 「表示に伴う問題を回避するために 、REST を使用する場合は US−ASCII 文字を使用してください。」 ともあります。
白黒つかない言い回しでこの文章だけでは何とも判断しがたいのですが、実際に検証した結果を後ほど記載します。
Amazon S3 では、任意の Unicode 文字をメタデータ値で使用できます。
これらのメタデータ値の表示に伴う問題を回避するために、REST を使用する場合は US−ASCII 文字を使用してください。SOAP またはブラウザベースのアップロードを POST 経由で使用する場合は UTF−8 を使用してください。
US−ASCII 以外の文字をメタデータ値で使用すると、指定した Unicode 文字列に US−ASCII 以外の文字が含まれていないかどうか調べられます。そのようなヘッダーの値は、保存される前に RFC 2047 に従って文字デコードされます。さらに、RFC 2047 に従ってエンコードされ、メールセーフになってから返されます。文字列に US−ASCII 文字のみが含まれている場合は、そのまま表示されます。
文字数制限
先述したように、リクエストヘッダのうちオブジェクトメタデータが利用可能な領域は2KBまでです。この2KBにはKey(x-amz-meta-*)も含みますし、仮にURLエンコードすれば文字数は増えるので実質的に利用可能な文字数はエンコードされた値をベースに計算する必要があります。
PUT リクエストヘッダーのサイズは 8 KB に制限されています。PUT リクエストヘッダー内のユーザー定義メタデータのサイズは 2 KB に制限されています。ユーザー定義メタデータのサイズは、キーと値それぞれの UTF−8 エンコーディングの合計バイト数を使用して測定されます。
Boto3から試してみる
ドキュメントから仕様を判断しがたい点が多いので、Boto3から実際に検証します。
テストケース
オブジェクトアップロード時に以下2つのカスタムメタデータを付与したいケースがあるとします。
この時、オブジェクトタグとオブジェクトメタデータがそれぞれどのような挙動になるのかを確かめます。
・Company = 100_ServerWorks
・Company_ja = 100_サーバーワークス
実行環境
LambdaのPython 3.13から実行します。
LambdaにはAmazonS3FullAccess権限を持つIAMロールを付与しています。
オブジェクトタグを付与する場合
テストコードは以下です。
APIの仕様上、文字列のURLエンコードが必要な点に注意してください。
import boto3 import urllib.parse s3 = boto3.client('s3') bucket_name = '<bucket-name>' file_name = 'objcet_tag_test.txt' tags = { 'Company': '100_ServerWorks', 'Company_ja': '100_サーバーワークス' } #タグをURLエンコードしてからオブジェクトをアップロード def lambda_handler(event, context): try: tags_encoded = urllib.parse.urlencode(tags) s3.put_object( Bucket=bucket_name, Key=file_name, Tagging=tags_encoded ) return { 'statusCode': 200, 'body': 'Success.' } except Exception as e: return { 'statusCode': 500, 'body': f'Error: {e}' }
実行すると処理が成功し、アップロードされたオブジェクトにタグが付与されていることがわかります。
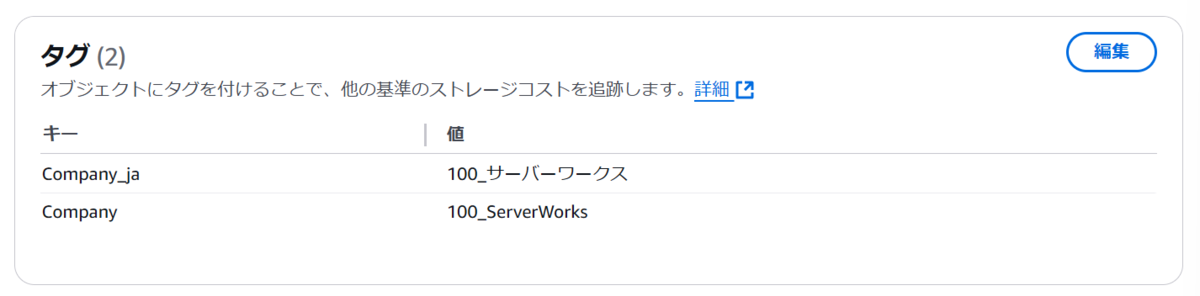
ドキュメント通り、大文字小文字が区別されていることがわかります。
日本語も登録できているようです。
一方でドキュメントには「使えない文字列もある」という趣旨の記載があったので
タグのValueの先頭に#を入れた上で再度実行してみます。
tags = {
'Company': '#100_ServerWorks',
'Company_ja': '#100_サーバーワークス'
}
実行すると今度は以下のようなエラーになりました。
{
"statusCode": 500,
"body": "Error: An error occurred (InvalidTag) when calling the PutObject operation: The TagValue you have provided is invalid"
}
少なくとも#が無効な文字列と判定されていることは確実ですが、バリデーションパターンが明示されていません。
S3のAPIリファレンスを見ても明示されていないように見えましたが、「EC2以外のタグのバリデーションパターン」としてEFSには以下のような記載がありました。
Tag - Amazon Elastic File System
Value
Pattern: ^([\p{L}\p{Z}\p{N}_.:/=+-@]*)$
上記の正規表現に#は含まれないので、この正規表現に基づいてタグのValueのバリデーションが行われているのではないかと思われます。EFSのドキュメントなので、推測に留まるのですが…。
参考までに、上記の正規表現をGeminiに解説させたものも載せておきます。
オブジェクトメタデータを付与する場合
オブジェクトメタデータも同じように試してみましょう。
テストコードは以下です。
import boto3 s3 = boto3.client('s3') bucket_name = '<bucket-name>' file_name = 'objcet_meta_test.txt' tags = { 'Company': '100_ServerWorks', 'Company_ja': '100_サーバーワークス' } #タグを渡してオブジェクトをアップロード def lambda_handler(event, context): try: s3.put_object( Bucket=bucket_name, Key=file_name, Metadata=tags ) return { 'statusCode': 200, 'body': 'Success.' } except Exception as e: return { 'statusCode': 500, 'body': f'Error: {e}' }
実行すると100_サーバーワークスが エラーになりました。
Response: { "statusCode": 500, "body": "Error: Parameter validation failed:\nNon ascii characters found in S3 metadata for key \"Company_ja\", value: \"100_サーバーワークス\". \nS3 metadata can only contain ASCII characters. " }
ドキュメントには「REST を使用する場合は US−ASCII 文字を使用してください。」とあったので記載通りのエラーではあります。
一方でこれはAPIではなくBoto3クライアント側のバリデーション処理によるエラーのように見受けられました。
ドキュメントによればUS-ASCII以外の文字列はMIMEエンコードされて格納される…ともあったので
以下のようにbefore-callを使って無理やりヘッダを埋め込むとどのような挙動になるのかを確認してみます。
import boto3 s3 = boto3.client('s3') event_system = s3.meta.events bucket_name = '<bucket-name>' file_name = 'objcet_meta_test.txt' # メタデータにしたいヘッダを指定する def add_custom_header_before_call(model, params, request_signer, **kwargs): params['headers']['x-amz-meta-classification-Company'] = '100_ServerWorks' params['headers']['x-amz-meta-classification-Company_ja'] = '100_サーバーワークス' headers = params['headers'] def lambda_handler(event, context): try: # Event Systemにヘッダ追加関数を登録 event_system.register('before-call.s3.PutObject', add_custom_header_before_call) s3.put_object( Bucket=bucket_name, Key=file_name ) return { 'statusCode': 200, 'body': 'Success.' } except Exception as e: return { 'statusCode': 500, 'body': f'Error: {e}' }
すると処理が成功し、ドキュメント通り100_サーバーワークスがMIMEエンコードされ格納されています。
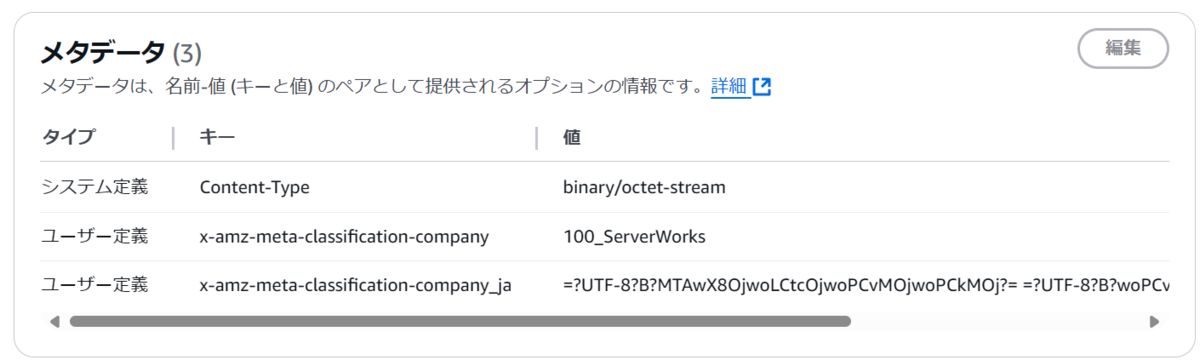
KeyのCompanyがcompanyになり大文字が小文字になっていることも確認できます。
ドキュメントに反してValueは大文字と小文字が区別されているように見えました。
ところが、MIMEでエンコードされた文字列をデコードしてみると、日本語部分で文字化けが発生してしまっています。
$ echo "=?UTF-8?B?MTAwX8OjwoLCtcOjwoPCvMOjwoPCkMOj?= =?UTF-8?B?woPCvMOjwoPCr8OjwoPCvMOjwoLCr8OjwoLCuQ==?=" | nkf -w 100_ãµã¼ãã¼ã¯ã¼ã¯ã¹
調べてみると、ISO-8859-1(Latin-1)と解釈されて文字化けした上でMIMEエンコードされてしまっていることが原因のようでした。
ドキュメントで言及されている 「メタデータ値の表示に伴う問題」 とは、恐らくこのことなのではないかと思います。
# ISO-8859-1で元の文字列を変換すると文字化けの値と一致した $ echo "100_サーバーワークス" | iconv -f ISO-8859-1 100_ãµã¼ãã¼ã¯ã¼ã¯ã¹
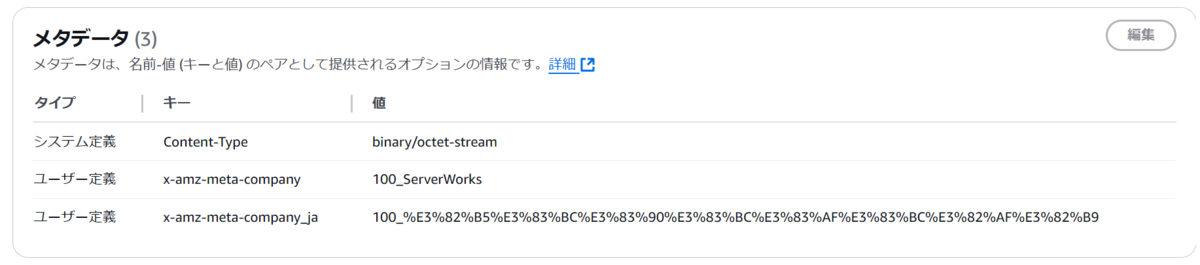
ということで長くなりましたが、オブジェクトメタデータにUS-ASCII以外の文字列を使いたい場合は結局URLエンコードをする必要があります。
import boto3 import urllib s3 = boto3.client('s3') bucket_name = '<bucket-name>' file_name = 'objcet_meta_test.txt' tags = { 'Company': '100_ServerWorks', 'Company_ja': urllib.parse.quote('100_サーバーワークス') } #タグを渡してオブジェクトをアップロード def lambda_handler(event, context): try: s3.put_object( Bucket=bucket_name, Key=file_name, Metadata=tags ) return { 'statusCode': 200, 'body': 'Success.' } except Exception as e: return { 'statusCode': 500, 'body': f'Error: {e}' }
保存できました。
ただ、URLエンコードされた状態で保存されるので抽出する際にクエリでデコードをかける必要があります。
まとめ:結局どう使い分けるといいのか?
調べてみるとバリデーションパターンや文字コードなど、かなり複雑な仕様になっていることがわかりました。
総合的には、 独自のメタデータを運用したいケースではオブジェクトタグを選んでおけば間違いない という印象です。
オブジェクトメタデータを使った方がいいケース
- オブジェクトタグの10個までという制約がノックアウトファクターに触れる場合
- どうしてもオブジェクトタグで使えない文字列を埋め込みたい場合
- たとえば先ほどの
#はUS-ASCIIに含まれるので埋め込める
- たとえば先ほどの
オブジェクトタグを使った方がいいケース
- KeyとValueで大文字と小文字の区別が必要な場合
- US-ASCII以外の文字を使いたい場合
- メタデータを頻繁に編集する場合(オブジェクトメタデータの場合、オブジェクトごと上書きが必要なのでオーバーヘッドが大きい)
佐藤 航太郎(執筆記事の一覧)
クロスインダストリー第1本部 クラウドモダナイズ課
最近はデータエンジニアのようなことをしています。