

クラウドインテグレーション部の村上です。
今回はSageMaker Autopilotをやってみたブログです。 チュートリアルではなく、Kaggleのコンペで使ってみたらどうなるんだろう?という内容です。
興味があれば読んでください!
Kaggleってなに?
ここではKaggleの用語や参加したコンペの特徴を簡単に説明します。
Kaggleとは
分析コンペのプラットフォームです。 主催者から与えられたデータを使って、参加者はデータ分析の腕を競います。
参加したコンペってどんなの?
- American Express - Default Predictionです。
- 顧客IDごとの「支払い」や「残高」に関するデータが与えられ、債務不履行になるかどうかを予測します。
- 与えられたcsvデータがめちゃくちゃ大きいです。
- 学習データが16GB、推論するテストデータが33GBほどあります。
Submitについて
Kaggleでは推論したデータをSubmit(提出)して、スコアを競います。 私は初参加で割とガチで取り組みましたが、残念ながらメダル圏外という結果に終わりました。。。
SageMaker Autopilotはコンペ期間中にやる余力がなかったので、今回はコンペ終了後でもSubmitできる「Late Submission」という仕組みを使います。
Amazon SageMaker Autopilotとは
機械学習の深い知識がなくてもモデルを作成できる素晴らしい機能です。欠損値の処理や数値変換などのデータ前処理はAmazon SageMaker Autopilotがやってくれます。
表形式のデータセットを提供し、予測対象の列を選択するだけで、SageMaker Autopilot が自動的にさまざまなソリューションを探索し、最適なモデルを見つけます。
対応できるタスクの種類は以下のとおりです。
- 回帰
- 二項分類
- 多クラス分類
やってみた
こちらのチュートリアルを参考にしつつ、進めていきます。以下、記載するコマンドは実行したもののうちの一部ですので、詳細はチュートリアルを参照してください。
以下のような流れで進みます。
- データの準備
- 学習データとテストデータを用意します。
- トレーニング
- 学習データを使ってモデル作成のためのトレーニングを行います。
- 推論
- 作成したモデルでテストデータの推論をします。
データの準備
大まかな流れは以下のとおりです。
- データセットをS3にアップロード
- SageMaker Studioを起動し、データセットをダウンロード
- (補足)検証データは作成してもしなくてもいい
データセットをS3にアップロード
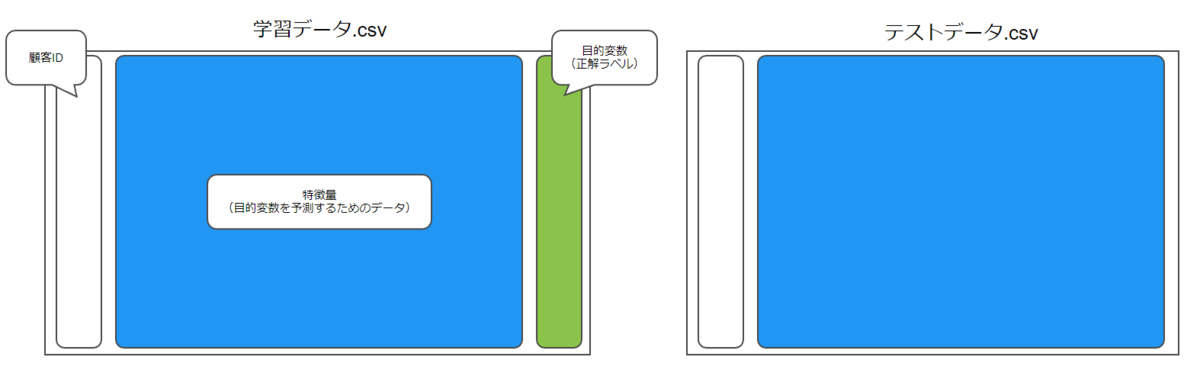
データセットには学習データとテストデータがあり、学習データには顧客ごとの正解ラベルが含まれています(以下のようなイメージ)。これらを任意の方法でS3にアップロードします。
parquet形式にも対応していてうれしい
チュートリアルに沿って進めていると、Notebookに「csvしかダメよ」って注意書きがあり困りました。
Currently Autopilot supports only tabular datasets in CSV format.
今回のデータセットは非常にサイズが大きく、csvよりも軽量なparquet形式を使いたかったためです。
が、よくよく調べてみると、parquet形式にも対応済みのようです。助かった。
SageMaker Studioを起動し、データセットをダウンロード
SageMaker Studio内のNotebookで、以下のコマンドを実行し必要なデータセットをダウンロードします(テストデータも同様にダウンロード)。
sagemaker.s3.S3Downloader.download(
s3_uri='s3://path_to_file/train_data.parquet',
local_path='.'
)
ダウンロードした学習データはpandasを使って、trainという名前で読み込んでおきます。
import pandas as pd train = pd.read_parquet('train_data.parquet')
(補足)検証データは作成してもしなくてもいい
チュートリアルでは学習データの80%をトレーニングに使用し、残り20%のデータを使って推論しています。
絵で表すと以下のようなイメージです。
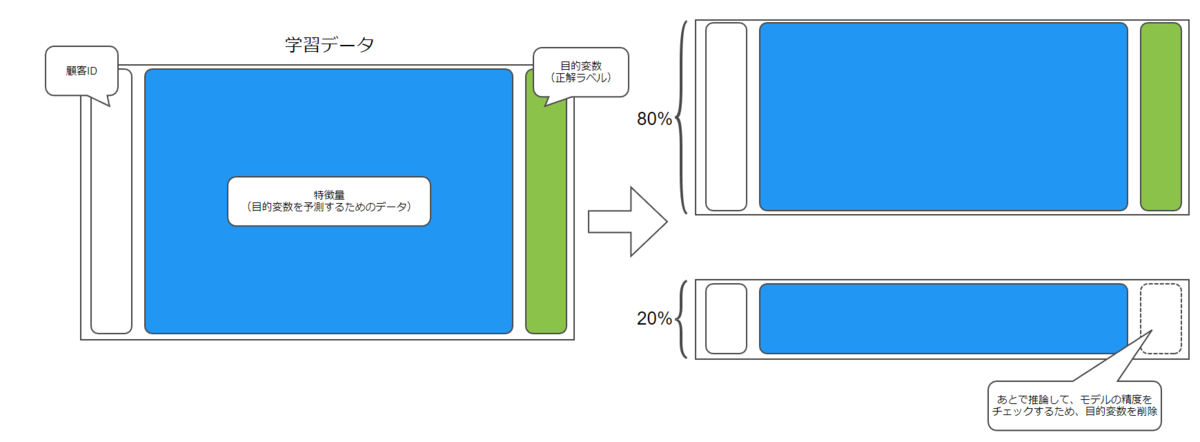
チュートリアルのコードでは以下のように分割しています。
train_data = data.sample(frac=0.8, random_state=200) test_data = data.drop(train_data.index) test_data_no_target = test_data.drop(columns=["y"])
最初にこのコードを見たとき、「モデルの性能評価のために分割するのかな」と思いました。学習データの一部は学習に使用せず検証データとして残しておいて、作成したモデルの評価をするために使うというのは、ホールドアウト法という最も基本的なモデルの評価手法だからです。
作成したモデルで検証データを推論して、どのモデルが一番性能が良いか評価するために使うわけです。
ただ、SageMaker Autopilotでは、入力したデータを自動的に分割し、モデルの評価を行ってくれるようです。 よって、学習データを分割して・・みたいなことはしなくても、モデルが作成できちゃいます。素晴らしいですね。
Autopilot は、入力データをトレーニングセットと検証セットに自動的に分割します。 aws.amazon.com
正確にいうと、
- 入力したデータが1つの場合、データ分割の割合を指定します。何も指定しないと自動的にデータの20%が検証データとして使用されます。
- 入力したデータが2つの場合、一方を学習データ、もう一方を検証データに指定できます。
要はお任せもできるし、自分の好きなようにもできるということですね。 docs.aws.amazon.com
検証データの作成をAmazon SageMaker Autopilotにお任せするときの注意点
検証データの作成はそれなりの機械学習の知識が必要です。単純にデータを分割するだけではダメなときがあります。
今回のコンペのデータがまさにそうで、データ内には同じ顧客IDの情報が複数行あり、ランダムに分割してしまうと学習データと検証データに同じ顧客の情報が混在してしまう恐れがあります(リークといいます)。
作成したモデルで未知のデータを推論して精度を見たいのに、これはよろしくありません。
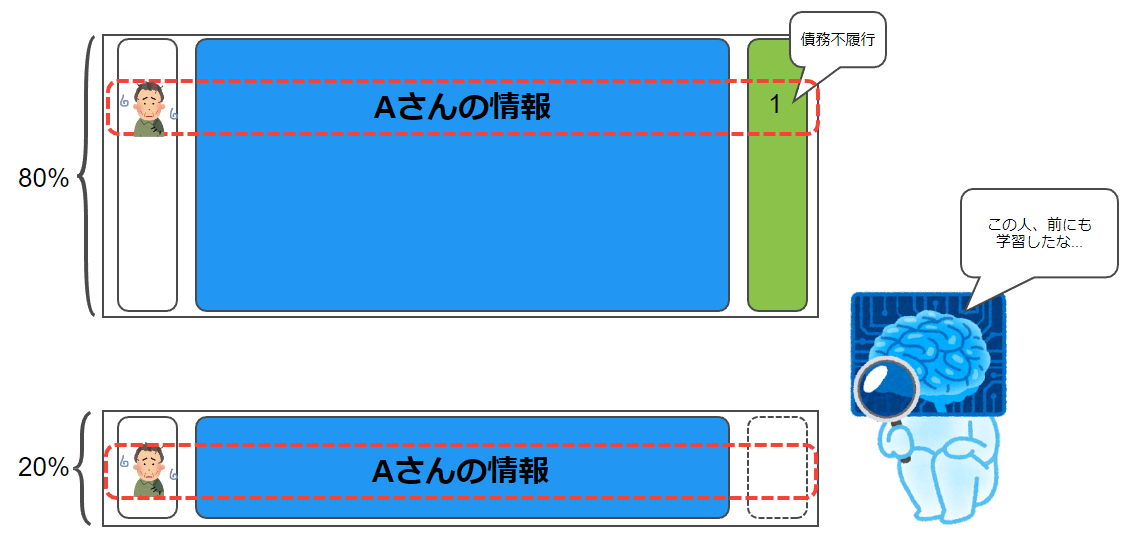
よって、今回は検証データ作成をお任せせず、自分でやることにしました。
from sklearn.model_selection import KFold customer_id = train['customer_ID'] unique_customer_id = customer_id.unique() kf = KFold(n_splits=5, shuffle=True, random_state=71) tr_idx, va_idx = list(kf.split(unique_customer_id))[0] train_group, val_group = unique_customer_id[tr_idx], unique_customer_id[va_idx] is_tr = customer_id.isin(train_group) is_va = customer_id.isin(val_group) train_data = train[is_tr] val_data = train[is_va]
分割後の学習データをtrain_data、検証データをval_dataとしています。
トレーニングに使用するため、train_dataをS3にアップロードします(val_dataも同様)。
train_file = "train.parquet" train_data.to_parquet(train_file, index=False) train_data_s3_path = session.upload_data(path=train_file, key_prefix=prefix + "/train") print("Train data uploaded to: " + train_data_s3_path)
トレーニング
データの準備が終わったら、いよいよトレーニングです。 以下のような流れになります。
- SageMaker Autopilot ジョブの設定
- SageMaker Autopilot ジョブの起動
- モデルの確認
SageMaker Autopilot ジョブの設定
まず、SageMaker Autopilotがトレーニングジョブを開始するのに必要なパラメータを設定します。
時間短縮のため、トレーニングジョブの最大数MaxCandidatesは4にします。また、利用料節約のため、トレーニングジョブあたりの学習時間は最大45分間としておきます。
auto_ml_job_config = {
"CompletionCriteria": {
"MaxCandidates": 4,
"MaxRuntimePerTrainingJobInSeconds": 2700
}
}
input_data_config = [
{
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://{}/{}/train".format(bucket, prefix),
}
},
"TargetAttributeName": "target",
"ContentType": "x-application/vnd.amazon+parquet",
"ChannelType": "training"
},
{
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://{}/{}/val".format(bucket, prefix),
}
},
"TargetAttributeName": "target",
"ContentType": "x-application/vnd.amazon+parquet",
"ChannelType": "validation"
}
]
output_data_config = {"S3OutputPath": "s3://{}/{}/output".format(bucket, prefix)}
SageMaker Autopilot ジョブの起動
さきほど設定したパラメータを参照して、SageMaker Autopilot ジョブの起動します。
from time import gmtime, strftime, sleep timestamp_suffix = strftime("%d-%H-%M-%S", gmtime()) auto_ml_job_name = "job-" + timestamp_suffix print("AutoMLJobName: " + auto_ml_job_name) sm.create_auto_ml_job( AutoMLJobName=auto_ml_job_name, InputDataConfig=input_data_config, OutputDataConfig=output_data_config, AutoMLJobConfig=auto_ml_job_config, RoleArn=role, )
トレーニングに要した時間は3時間ほどでした。
モデルの確認
以下のように、最も性能のよかったモデルを参照できます。
best_candidate = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)["BestCandidate"] best_candidate_name = best_candidate["CandidateName"] print("CandidateName: " + best_candidate_name) print( "FinalAutoMLJobObjectiveMetricName: " + best_candidate["FinalAutoMLJobObjectiveMetric"]["MetricName"] ) print( "FinalAutoMLJobObjectiveMetricValue: " + str(best_candidate["FinalAutoMLJobObjectiveMetric"]["Value"]) )
今回の場合、モデルの評価に使用されたメトリクスはf1_binaryとなっていました。これは二項分類タスクに使用されるメトリクスです。
私がやったことはデータを与えること、予測する目的変数を設定することのみですが、自動的に二項分類タスクと判断し、それに適したメトリクスを選択してくれています(任意に選択することも可能)。
推論
最後に、作成したモデルを使ってテストデータを推論します。ここではバッチ変換ジョブを起動します。
transform_job_name = "automl-transform-test" + timestamp_suffix transform_input = { "DataSource": {"S3DataSource": {"S3DataType": "S3Prefix", "S3Uri": "s3://path/test_data.csv"}}, "ContentType": "text/csv", "CompressionType": "None", "SplitType": "Line", } transform_output = { "S3OutputPath": "s3://{}/{}/test-inference-results".format(bucket, prefix), } transform_resources = {"InstanceType": "ml.m5.4xlarge", "InstanceCount": 1} sm.create_transform_job( TransformJobName=transform_job_name, ModelName=model_name, TransformInput=transform_input, TransformOutput=transform_output, TransformResources=transform_resources, )
推論が終わると指定したS3に結果が保存されますので、ダウンロードします。
Kaggleに提出するため、データを整形します。細かい部分なので割愛しますが、コンペで定められたカラム名に変更したり、同じ顧客IDの目的変数の平均をとったりしました。
気になる結果は?
さて、結果です。スコアは1に近いほうが良いです。
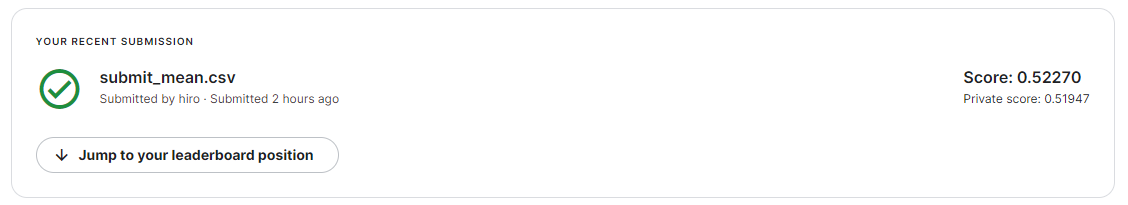
0.51947でした。 ちなみにメダル圏のスコアは0.80711~0.80977、初参加の私が0.80348でした。
芳しくない結果ですが、以下、私が考えた言い訳理由です。
今回の結果でAmazon SageMaker Autopilot の性能は判断できない
今回、Amazon SageMaker Autopilotは顧客が債務不履行になるかどうかを0 or 1(Yes or No)で推論してくれました。
やっていて思い出したのですが、コンペのルールにはyou must predict a probability for the target variable(確率を予測せよ)とあり、このズレが原因でスコアが芳しくないのだと考えます。
なんとも微妙な結末になってしまいごめんなさい。
まとめ
今回やってみた感想です。
- Amazon SageMaker Autopilotは機械学習の深い知識がなくてもモデル作成ができる、すごい。
- とはいえ、機械学習の知識があった方が質の良い検証データ・設定値を指定できるので、モデルの性能は人に依る部分もありそう。
- Kaggleでメダルとる人はしゅごい。
どなたかの参考になれば幸いです。