

おなかが痛くてもコーヒーは飲む、近藤恭平です。
本ブログは AWS Certified AI Practitioner (AIF-C01) 試験ガイド の内容に沿って AI/ML の基礎知識をまとめるシリーズの1作目(ドメイン1)です。
想定読者
- 主にこれから AWS Certified AI Practitioner (AIF-C01) を受験する人
- AI/ML の学習を始めた人
タスクステートメント 1.1: AI の基本的な概念と用語を説明する
AI、機械学習、深層学習の関係
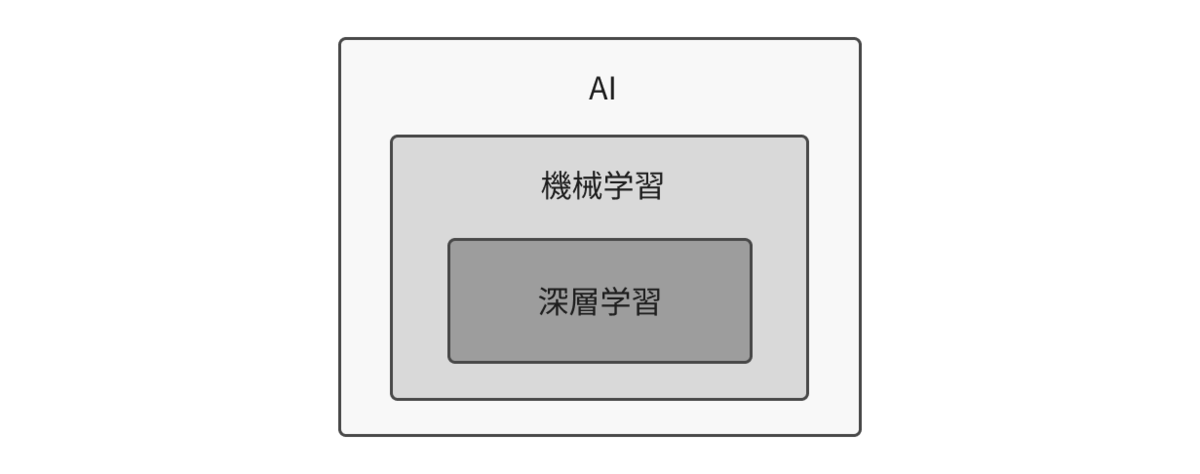
AI(Artificial Intelligence) は「人工知能」を意味する広い概念ですが、近年のAIの多くは 機械学習 に基づいており、観測データから現象を近似・予測するためのモデルを学習によって構築します。
AI には、機械学習を使わない手法もあります。1つの例が エキスパートシステム です。これは専門家の知識をルールとして登録し、推論エンジンによって結論を導く仕組みです。たとえば、症状に応じて病気を診断するシステムや、機械の故障原因を特定するトラブルシューティングシステムなどがこれにあたります。
機械学習は、データからパターンや規則性を見つけ出し、未知の入力に対しても予測や分類ができるようにする技術です。手法にはさまざまな種類があり、線形回帰やロジスティック回帰のようなシンプルな統計モデルから、決定木・ランダムフォレスト・サポートベクターマシン(SVM)のような非線形モデルなど幅広く存在します。
その中でも 深層学習(ディープラーニング) は、2012年の ImageNet コンペティションでニューラルネットワークが従来手法を大きく上回る性能を示したことをきっかけに注目を集め、画像認識・音声認識・自然言語処理といった分野で急速に主流となりました。深層学習は機械学習の一部に位置づけられますが、より大量のデータと計算資源を必要とする点が特徴です。
https://arxiv.org/pdf/1803.01164
データの基本構造と AWS のデータストア
ここでは機械学習固有の話ではなく、利用する元データの構造とそれに適したデータストアのサービスについてまとめます。
| データの種類 | 特徴・例 | 代表的なAWSサービス |
|---|---|---|
| 構造化データ | - 行と列で構成される表形式 - スキーマ(項目の定義)が明確 - 例: 顧客名簿、売上台帳 |
Amazon RDS, Amazon Redshift |
| 半構造化データ | - 部分的に構造を持つが柔軟 - JSON, XML, ログファイルなど - スキーマレスで扱いやすい |
Amazon DynamoDB, Amazon DocumentDB |
| 非構造化データ | - 明確な構造を持たない - テキスト、画像、音声、動画など - 全データの大部分を占める |
Amazon S3 |
| 時系列データ | - 時間の経過に沿って記録された連続データ - 例: 株価、センサー値、アクセスログ |
Amazon Timestream |
学習(Training)と推論(Inference)

機械学習には大きく学習(Training)と推論(Inference)の2つのフェーズがあります。上図の左図のように、トレーニングデータを用いてモデルを更新することを学習と呼びます。そして右図のように学習済みのモデルに対して、未知のデータ(学習に使用されていないデータ)を入力として結果を得ることを推論と呼びます。
3種類の機械学習

機械学習には大きく3つの手法があり、それぞれ教師あり学習、強化学習、教師なし学習と呼ばれます。この中でも教師あり学習と強化学習は、外部からの追加情報を用いてモデルが学習(訓練)される手法です。
教師あり学習
教師あり学習では、例えば「猫の画像」に対して「猫」というラベル、画像データに対してそこに写っているものの正解がセットになったデータを扱います。多数の正解データを用意し、その正解を表現できるようにモデルが訓練されます。
強化学習
強化学習は自身のアクションに対して報酬が得られ、その報酬を最大化するようにモデルが更新されます。例えば、特定の形状のコースを走るミニチュアの車が、コース通りに走れれば報酬を得られ、外れてしまえば得られないような環境を用意します。初めはランダムに動いていた車が、報酬を最大化するアクションを取るようになり上手くコースを走れるように訓練されます。
AWS DeepRacer というサービスを利用すると、ブラウザ上でモデルを強化学習により訓練してシミュレーターで仮想走行させることができます。
教師なし学習
教師なし学習は、教師あり学習や強化学習とは異なり、正解や報酬といった外部の評価指標を持たない学習手法です。データが何を表すかはわからないが、データの特徴を捉え、それぞれの関係を導き出すのに適した手法です。図のように、データを分類(クラスタリング)するようなことができます。
モデルの性能を悪化させる過学習(Overfitting)と学習不足(Underfitting)

モデルは、入力 x(独立変数)、出力 y(従属変数)、そしてそれらを結びつけるパラメータ w(重みやバイアス項)で表現されます。どのようなモデルを定義するかによって、誤差を含む実際のデータに過剰に反応したり、データから真の分布を表現し損ねたりしてしまいます。これらはそれぞれ、過学習(Overfitting)と学習不足(Underfitting)と呼ばれ、汎化性能※1を悪化させる要因です。

上図は多項式回帰の例を表しています。左から、1次回帰(線形回帰)、3次回帰、15次回帰です。これらの数字にバイアス項分の1つを足した数がモデルのパラメータ数です。パラメータ数が増えるほどデータ点の近くを通るような結果を得ることが分かります。
しかし、高次の関数(パラメータが豊富なモデル)が適切なモデルであるとは限らず※2、汎化性能の高いモデルを選択する必要があります。
※1 モデルは学習時に使用されたデータに対してではなく、未知のデータに対しても対応できるかが重要です。そして、どれだけ未知のデータに対応できるかを表す指標は汎化性能と呼ばれます。
※2 これまでパラメータの数を増やすほど過学習を引き起こしやすく、汎化性能を悪化させるとされていました。しかし、これに反して LLM のようなモデルではパラメータを増やすほど性能が向上するという「スケーリング則」が示されています。
https://arxiv.org/pdf/2001.08361
タスクステートメント 1.2: AI の実用的なユースケースを特定する
AI を使用しないケース
投資対効果の判断
以降 AI のユースケースについて説明していきますが、一方で AI を使用しない判断ができることも重要です。AI のプロジェクトを開始する際にははじめに投資対効果(ROI)を説明できる必要があります。例えば、業務効率化のために AI を導入したいと思っても、導入・運用コストが削減されるコストを超えていなければ投資判断ができないかもしれません(大きな効果が得られないとしても AI の技術進歩に追従するための投資と判断されることもあるかもしれませんが)。
解釈可能性の判断
また、効率化のために必ず AI が必要か、という問いも必要です。LLM のような深層学習で訓練されたモデルは、学習を経てなぜそのようなモデルに生成されたかはわかりません。つまり、入力と出力のみを見てそのモデルの性質を判断し、それらの関係についてはブラックボックスです。
このような 解釈可能性 の低いモデルは、医療におけるカウンセリングや金融におけるローン審査といった、倫理的な問題に対するソリューションとして適さない可能性があります。一般的にパフォーマンスと解釈可能性はトレードオフの関係にあります。どちらを優先するかを判断し、深層学習モデルかルールベースシステムのような決定論的手法を採用するかを決定しなければいけません。
AI の応用例
| 利点 (メリット) | 説明 | 応用例 | 活用できるAWSのAIサービス例 |
|---|---|---|---|
| 自動化と効率化 | 人が行う定型作業を高速・正確に実行 | 製造ラインの自動検査、帳票処理、倉庫ロボットのピッキング | Textract、Comprehend、Bedrock |
| 精度向上とエラー削減 | 大量データから高精度な予測・分類 | 医療画像分類、不良品検出、異常検知 | Rekognition、Comprehend |
| パーソナライズ | 個々の嗜好・履歴に応じた最適提案 | レコメンド、パーソナライズ広告 | Personalize |
| リアルタイム意思決定 | ストリーム/センサーを即時処理し瞬時に判断 | 自動運転制御、トレーディング、セキュリティ検知 | Bedrock |
| コスト削減 | 在庫・需要・エネルギーなどの最適化 | 需要予測、在庫最適化、設備保全 | Forecast |
| 新しい価値創造 | 生成AIで新サービス/体験を創出 | コンテンツ生成、要約/翻訳、コード支援、AIアシスタント | Bedrock、Translate、Comprehend |
| スケーラビリティと24時間稼働 | 疲れず並列に大量タスクを処理 | カスタマーサポートボット、FAQ応答 | Lex、Kendra、Bedrock |
| セキュリティ/不正検知 | 異常パターンを検出し被害を未然防止 | クレカ不正検知、アカウント乗っ取り検出 | Fraud Detector |
| 文書/帳票のデジタル化 | 紙/画像からテキスト・構造化データ抽出 | 請求書の取り込み、契約書解析、ナレッジ検索 | Textract、Comprehend、Kendra |
| 音声・映像の活用 | 音声/映像の認識・合成・理解 | 字幕生成、会議要約、音声ナレーション | Transcribe、Polly、Lex、Rekognition |
| カスタムモデル開発 | 既存サービスでは対応できない独自の機械学習モデルを構築・学習・デプロイ | 特殊な画像分類、独自の言語モデル、業界特化予測モデル | SageMaker |
タスクステートメント 1.3: ML 開発ライフサイクルについて説明する
AI(ML)プロジェクトのライフサイクル
1. データの収集
機械学習プロジェクトの第一歩は、必要なデータを整理することです。前述したデータストアなどから、ストリーミングやバッチで S3 のようなストレージにデータを集めます。次に、教師あり学習用に正しい答え(ラベル)を付けます。 SageMaker Ground Truth を使用すると、自動ラベル付けと人手による確認を組み合わせて効率的にデータを作成できます。それらを実施するワーカーはMechanical Turk、外部ベンダー、社内チームなどから選択可能です。
2. データの前処理
ラベル付きデータが揃ったら、次は学習に使える形に整えます。まず探索的データ分析で全体の傾向を確認し、欠損値や外れ値を見つけます。欠損しているデータは削除するか、平均値や前後の値で補完します。ラベルやカテゴリ名に揺れがあれば統一します。また、必要に応じて機密情報のマスキングや削除を実施します。
次に、データを学習用、検証用、テスト用に分割します。一般的には 8:1:1 の比率で分割し、学習で使うのはトレーニングと検証だけです。テストデータはデプロイ前の最終確認のために残しておきます。
AWSでは、 Glue DataBrew を使ってGUIで欠損値の削除や型変換などの前処理をノーコードで実行できます。DataBrewのレシピ機能を使えば処理手順を保存し、新しいデータにも同じ変換を再利用できます。
3. 特徴量エンジニアリング
前処理したデータから、モデルが学習しやすい形の「特徴量」を作成します。特徴量とはモデルに与える入力データで、必要に応じて新しい列を作ったり、数値をスケーリングしたり、カテゴリを数学的に扱える形式に(ワンホットエンコード)変換するなどの加工を行います。例えば「日時」から「曜日」や「時間帯」を取り出す、複数のカラムから平均値や差分を作るといった変換がよく行われます。必要に応じて特徴量の数を減らし、学習や推論の処理を軽くします。
特徴量は一度作れば再利用できるように管理しておくと便利です。複数のモデルやプロジェクトで同じ特徴量を使えるようにすることで、重複作業を減らし、学習と本番推論で同じロジックを使うことで精度のずれを削減します。
AWSでは、 SageMaker Canvas を使ってGUIで特徴量を作成でき、 SageMaker Feature Store で特徴量を一元管理できます。Feature Storeに登録すれば、学習時と推論時で同じ特徴量を呼び出せるため、再現性が向上します。
4. トレーニング・チューニング・評価
次に、モデルを学習させます。トレーニングデータでモデルの重みを更新し、検証データで性能を確認します。より良い結果を得るために、アルゴリズムの選択や学習率などのハイパーパラメータ※を調整しながら繰り返し学習します。
AWSでは、 SageMaker Experiments を使って複数の学習結果を管理・比較できます。さらに SageMakerの自動モデル調整 を使えば、ハイパーパラメータ探索を自動化し、精度の高いモデルを発見するコストの効率化が可能です。
学習後は検証データやテストデータを用いてモデルを評価します。分類問題では混同行列から精度、再現率、F1スコアなどを算出し、回帰問題では平均二乗誤差(MSE)や平均絶対誤差(MAE)を使います。
※ モデル自身の特性ではなく、学習プロセスの挙動に関わるパラメータ。例えば学習率は重み更新の変化分に影響するハイパーパラメータであり、モデルの収束スピードに関連する。
5. デプロイ
学習と評価が終わったら、モデルを本番環境に展開します。デプロイとは、学習済みモデルを使って実際のデータに対して推論できるようにすることです。用途に応じて、即時に予測結果を返すリアルタイム推論と、大量データをまとめて処理するバッチ推論を使い分けます。
リアルタイム推論では、SageMakerのエンドポイントを作成しAPI経由で予測を呼び出せます。レコメンドや不正検知など、即時応答が必要なシステムに向いています。バッチ推論では、S3に保存された大量のデータをまとめて処理し、結果をファイルとして出力します。日次バッチ処理などに適しています。
6. モニタリング
モデルの性能を維持するには、運用中の精度や入力データの状態を継続的に監視・評価する必要があります。時間が経つとデータの傾向が変わり、モデルの予測精度が下がる「ドリフト」が生じることがあります。
AWSでは、 SageMaker Model Monitor を使って本番エンドポイントに対する入出力を継続的にキャプチャし、学習時の制度と乖離がないかを評価できます。問題が見つかったらライフサイクルのフェーズを溯り、データ収集、前処理、再学習特徴量エンジニアリング、学習フェーズを再度見直します。
2 値分類のモデル評価手法
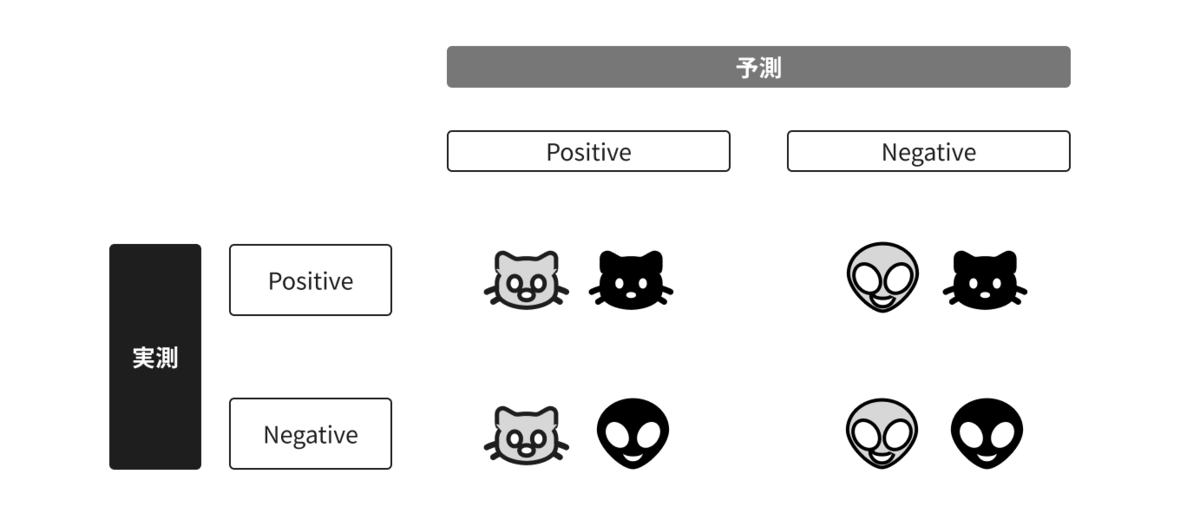
猫か猫以外かを分類するモデルを仮定すると、結果は上図のような4つの予測と実測のパターンで分けられます。
| 判定 | 予測 | 実測 |
|---|---|---|
| 真陽性 | 猫 | 猫 |
| 偽陽性 | 猫 | 猫ではない |
| 偽陰性 | 猫ではない | 猫 |
| 真陰性 | 猫ではない | 猫ではない |
これをもとに、いくつかの評価指標を定義できます。
正解率
全予測の中で正しい割合を表します。データが偏っている場合(例:ほとんどが「猫ではない」)には過大評価になりやすい。
(真陽性 + 真陰性) / 合計
適合率
予測が「猫」であるもののうち予測も「猫」である割合であり、予測結果の信頼性を表します。誤って猫と判断したケース(偽陽性)を嫌うタスク(例:スパム判定で正常メールを誤ってブロックしたくない場合)で重視される。
真陽性 / (真陽性 + 偽陽性)
再現(リコール)
結果が「猫」であるもののうち予測も「猫」である割合であり、見逃しを防ぐ度合いを表します。誤って「猫ではない」と判断したケース(偽陰性)を嫌うタスク(例:病気のスクリーニングで陽性者を取りこぼさない)で重視される。
真陽性 / (真陽性 + 偽陰性)
F1 スコア
適合率も再現率もある程度高くしたいときの総合評価です。
2 × 適合率 × 再現率 / (適合率 + 再現率)
偽陽性率
結果が「猫ではない」もののうち予測が「猫」である割合であり、誤検知のような誤情報の多さを表す。
偽陽性 / (真陰性 + 偽陽性)
真陰性率
結果が「猫ではない」もののうち予測も「猫ではない」である割合です。
真陰性 / (真陰性 + 偽陽性)
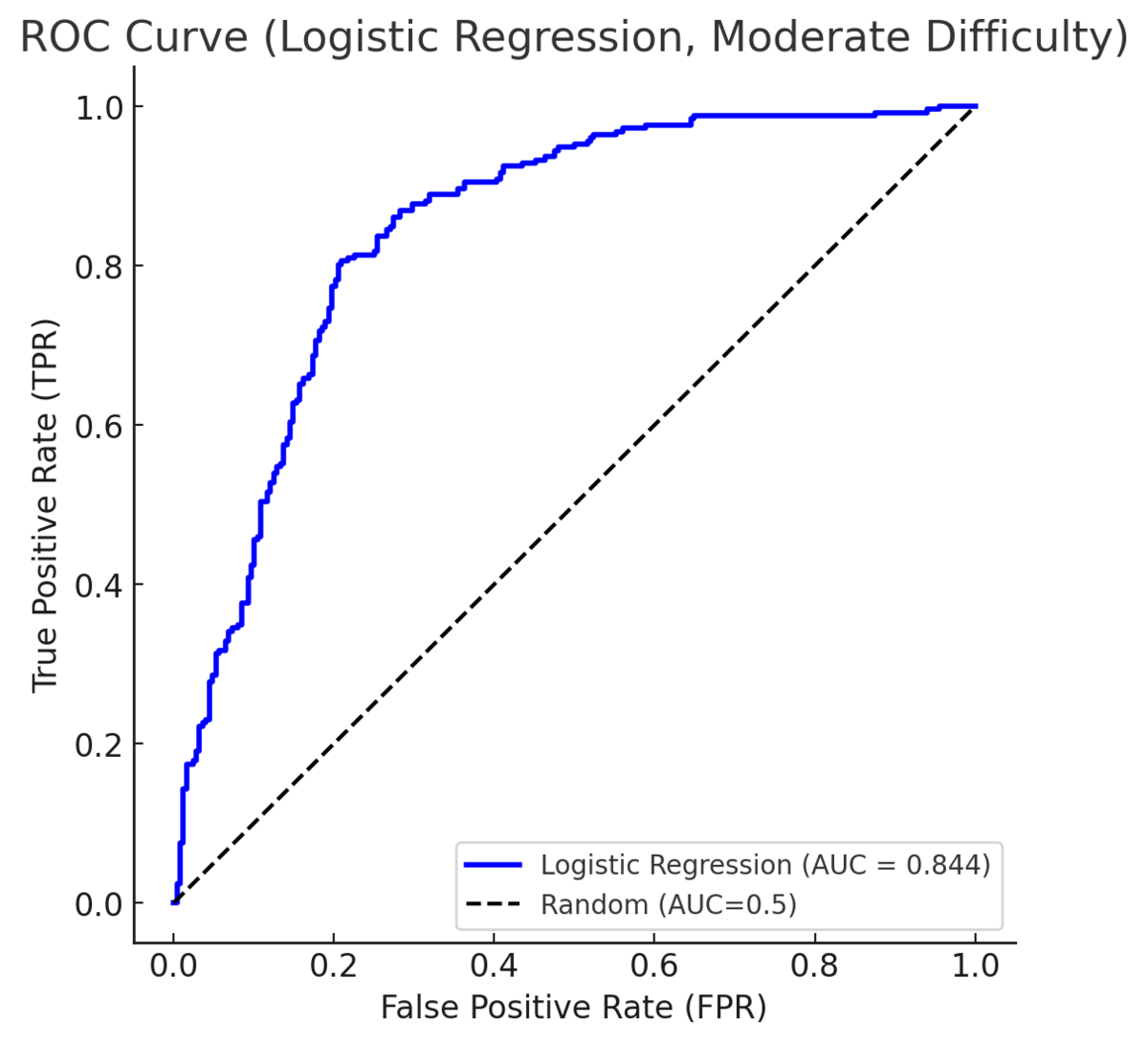
Receiver Operating Characteristic (ROC) 曲線と Area Under the Curve (AUC)
ROC 曲線は、入力データを「猫」である(または「猫ではない」)と判断する閾値を 0 - 1 の間で変化させたときの、真陽性率と偽陽性率の関係をプロットしたものです。AUC は ROC の曲線の下部の面積のことで、この値が1に近いほどモデルの性能が良いと判断されます。