

データドリブンな人間を目指している香取です。
最近 Databricks では生成 AI 関連のアップデートがどんどん追加されており、AI エージェントを簡単に構築できるようになってきています。
そんな中 AI エージェント構築の一連の流れを体験できる公式チュートリアルを発見したので、Free Edition で実践してみました。
- はじめに
- 0. デモに必要なパッケージ一式をインストール
- 1. ツールの作成
- 2. エージェントのデプロイと評価
- 3. ナレッジベース (RAG) の追加
- 4. Databricks Apps を使ったエージェントのデプロイと顧客フィードバックの収集
- 5. エージェントへのモニタリングの追加
- 6. エージェントがビジネス指標に与える影響を追跡する (ダッシュボード作成)
- おわりに
はじめに
このチュートリアルは Databricks Apps でのエージェント作成だけでなく、RAG の追加、アプリケーションのデプロイ、モニタリング、ビジネス指標の追跡まで一通りの流れを体験できるものになっています。
2025年9月時点では英語資料のみの提供のようだったので、日本語での補足も入れつつ進めていきます。
実行するコードは実際のノートブックを見ればわかるので、この記事ではポイントとなる部分を抜粋して解説します。
チュートリアルの流れ
- ツールの作成
- エージェントのデプロイと評価
- ナレッジベース (RAG) の追加
- Databricks Apps を使ったエージェントのデプロイと顧客フィードバックの収集
- エージェントへのモニタリングの追加
- エージェントがビジネス指標に与える影響を追跡する (ダッシュボード作成)
前提
- Databricks on AWS (Free Edition) にて実施
- そのまま実行してもエラーになってしまった箇所があったり、Free Edition で実施するために設定変更が必要だったので、少しコードを変更しながら進めていきます
- 想定所要時間
- コードを実行してデプロイするだけなら30分程度
- ある程度理解しながら進めるなら1〜3時間程度
- 「5、6」の章はエージェントデプロイ後の運用管理的な側面が強いので、RAG アプリを構築したいだけなら「4. Databricks Apps を使ったエージェントのデプロイと顧客フィードバックの収集」まででも良いかと思います
構築するアプリのイメージ
Databricks にユーザー情報や以下のような PDF をテーブルへテキスト情報として保存したものをデータソースとし、

このような形で回答してくれる AI エージェントを構築します。

「データソースを参照したうえで、顧客満足度調査のやり方を簡単に教えてください」という質問に対して、AI エージェントが『顧客満足度調査手順書』という社内文書を参照し、その内容に基づいて「①調査の設計 → ②展開 → ③データ収集 → ④モニタリングと報告」という一連のプロセスを分かりやすくまとめて回答してくれています。
チュートリアルのコードのままだと回答の整形や日本語対応ができていませんが、その部分はこの記事では割愛します。
0. デモに必要なパッケージ一式をインストール
デモリソースをインストールするためにノートブックを実行するので、ワークスペース内の任意の場所にノートブックを作成します。
私は「ai-agent-tutorial」という名前でフォルダを作成し、その中にノートブックを作成しました。
以下のコードをそれぞれセルで実行していきます。
%pip install dbdemos -U
「Note: you may need to restart the kernel using %restart_python or dbutils.library.restartPython() to use updated packages.」というメッセージが出るので、指示に従ってカーネルを再起動しておきます。
dbutils.library.restartPython()
このまま実行すればワークスペース内に ai-agent というフォルダが作成され、main カタログの dbdemos_ai_agent スキーマが作成されます。(名前は任意のものに変更可能です)
import dbdemos dbdemos.install('ai-agent', catalog='main', schema='dbdemos_ai_agent')
ai-agent/01-ai-agent-introduction にイントロダクションのノートブックが作成されるので、内容を確認しておきます。

それでは順番に各フォルダ内のノートブックを実行していきましょう!
1. ツールの作成
./ai-agent/01-create-tools/01_create_first_billing_agent ではエージェントで使用するツール (関数) を Unity Catalog に登録します。
- get_customer_by_email : メールアドレスをキーに customers テーブルから顧客情報を取得する SQL 関数
- get_customer_billing_and_subscriptions : 顧客 ID をキーに請求情報とサブスクリプション情報を取得する SQL 関数
- calculate_math_expression : LLM が苦手な数学計算を実行するための Python 関数
すべてのセルを実行したら、カタログ内に以下のようなテーブルや関数が作成されていることが確認できます。

2. エージェントのデプロイと評価

このノートブックでは以下のような流れでエージェントの作成、評価、改善、デプロイを行います。
- 2.1. エージェントの構築と登録:
- agent_config.yaml ファイルで、エージェントの設定(LLM エンドポイント、システムプロンプト、使用するツールなど)を定義
- LangChain を使用してエージェントを構築
- MLflow のログを有効化
- エージェントを MLflow モデルとして登録
- 2-2. エージェントの評価:
- 評価用データセットを作成し、MLflow に登録
- MLflow GenAI 評価機能を使用して、エージェントを評価
- カスタムガイドラインを追加し、エージェントが内部の使用ツールについて言及しないように設定
- 2-3. エージェントの改善と再評価:
- カスタムガイドラインに沿ってエージェントの回答を評価
- システムプロンプトを改善し、内部の推論ステップも言及しないように指示を追加
- 改善されたプロンプトで新しいエージェントバージョンを MLflow に再登録し、再度評価を実行して、パフォーマンスが向上したことを確認
- 2-4. エージェントのデプロイ:
- 評価スコアが良好な最新バージョンを Unity Catalog に登録
- 登録されたモデルをリアルタイムエンドポイントとしてデプロイし、アプリケーションで使用できるようにする
2-1. エージェントの作成と登録
./ai-agent/02-agent-eval/02.1_agent_evaluation では agent.py で Langchain を使用してツールをパッケージ化し、評価実行用の最初のエージェントバージョンとしてデプロイします。
1.1/ Define our agent configuration > update our configuration file のセルで RAG の設定ファイルを作成しています。
Free Edition では使用できる LLM モデルが限られているため llm_endpoint_name を databricks-gpt-oss-120b に変更しています。
import yaml import mlflow rag_chain_config = { "config_version_name": "first_config", "input_example": [{"role": "user", "content": "Give me the orders for john21@example.net"}], "uc_tool_names": [f"{catalog}.{dbName}.*"], "system_prompt": "Your job is to provide customer help. call the tool to answer.", "llm_endpoint_name": "databricks-gpt-oss-120b", # ← ここを変更 "max_history_messages": 20, "retriever_config": None } try: with open('agent_config.yaml', 'w') as f: yaml.dump(rag_chain_config, f) except: print('pass to work on build job') model_config = mlflow.models.ModelConfig(development_config='agent_config.yaml')
これを実行すると設定が記載された ./ai-agent/02-agent-eval/agent_config.yaml が作成されます。

7個目のセルの実行結果で output に CSV データが返ってきていますね。

エクスペリメントタブからモデルの実行履歴が確認でき、ユーザーからの質問とエージェントの回答、フィードバックなどを見ることができます。 どの回答が正解だったのか、間違っていたのかを確認しながらプロンプトを改善していく時に役立ちます。

2-2. エージェントの評価
2.1/ Evaluate the agent with Agent Evaluation には以下のような記載があります。 今回は独自に評価データセットを作成する方法で進めていきます。
このデモの一部として、すぐに使用できる評価データセットを準備しました。ただし、複数の戦略が存在します:
- 独自に評価データセットを作成する(今回実施する方法)
- MLFlow の既存トレースを利用し、データセットに追加する (API または実験 UI から)
- Databricks Genai Eval による合成データセット作成を利用する (例は PDF RAG ノートブックを参照)
- MLFlow UI を直接使用し、専門家からの知見を得られるラベリングセッションを作成!
注:既存の LLM 呼び出しをトレースから選択し、UI で評価データセットに追加することも可能です。または API を直接使用することもできます:
traces = mlflow.search_traces(filter_string=f"attributes.timestamp_ms > {ten_minutes_ago} AND attributes.status = 'OK'", order_by=["attributes.timestamp_ms DESC"])
./ai-agent/config
カタログ名とスキーマ名を指定します。
ここでも LLM_ENDPOINT_NAME を databricks-gpt-oss-120b に変更しています。
catalog = "rag_demo_catalog" schema = dbName = db = "ai_agent" volume_name = "raw_data" VECTOR_SEARCH_ENDPOINT_NAME="dbdemos_vs_endpoint" MODEL_NAME = "dbdemos_ai_agent_demo" ENDPOINT_NAME = f'{MODEL_NAME}_{catalog}_{db}'[:60] # This must be a tool-enabled model LLM_ENDPOINT_NAME = 'databricks-gpt-oss-120b'
./ai-agent/_resources/04-eval-dataset-generation
5つ目のセルの以下の部分も LLM モデルを変更しておきます。
# Step 5: Register and call AI_QUERY df_clean.createOrReplaceTempView("customer_test_questions") final_df_raw = spark.sql(""" SELECT question, AI_QUERY("databricks-gpt-oss-120b", prompt) AS expected_facts_json FROM customer_test_questions """)
実行結果
14個目のセルで評価データセットが作成されます。

エクスペリメントタブから評価データセットの実行履歴が確認できます。 ここでは 15% の評価が合格となったようです。

2-4. エージェントのデプロイ
私の検証時には 30個目のセルにてエラーが出たため、以下のように agents.deploy のパラメータに scale_to_zero=True を追加して実行しました。
from databricks import agents # Deploy the model to the review app and a model serving endpoint if len(agents.get_deployments(model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version)) == 0: agents.deploy( UC_MODEL_NAME, uc_registered_model_info.version, endpoint_name=ENDPOINT_NAME, tags = {"project": "dbdemos"}, scale_to_zero=True # ←これを追加 )
サービングタブからエンドポイントが作成されていることが確認できます。

3. ナレッジベース (RAG) の追加
このノートブックではナレッジベースの追加を行います。
- 3-1. PDF 情報の抽出とテーブル作成
- ai_parse_document という Databricks の組み込み SQL 関数を使用して、PDF ファイルからテキストコンテンツを抽出
- 抽出したテキストを保存するために、knowledge_base という Delta テーブルを作成
- 後で Vector Search で使用できるように Change Data Feed (CDF) を有効化
- 3-2. ベクター検索テーブルの作成
- VectorSearchClient を使ってベクター検索エンドポイントを作成
- knowledge_base テーブルの上にベクター検索インデックスを作成
- Databricks がテキストコンテンツから埋め込みベクトルを自動的に生成し、インデックスに同期
- 構築されたインデックスをテスト
- 3-3. 既存エージェントへのリトリーバーの追加
- agent_config.yaml を更新し、ベクター検索インデックスをリトリーバーとしてエージェントのツールに追加
- 更新された設定で新しいエージェントバージョンを MLflow に再登録
- 3-4. エージェントの再評価とデプロイ
- generate_evals_df 関数を使用して新しいドキュメントベースへの質問を含む評価データセットを生成
- 既存の評価用データセットと新しく生成されたデータセットの両方を使用して、更新されたエージェントを評価
- 評価結果に基づいて、最もパフォーマンスの良いエージェントバージョンを Unity Catalog に登録し、リアルタイムサービングエンドポイントとしてデプロイ
準備
Free Edition では 1つのベクトルサーチエンドポイントしか作成できないため、もしすでにエンドポイントを作成している場合は「コンピュート > ベクトル検索」から既存のエンドポイントを削除しておきます。
3-1. PDF 情報の抽出とテーブル作成
データソースの PDF は rag_demo_catalog.ai_agent.raw_data.pdf_documentation というボリューム内に保存されていて、プレビューすることも可能です。
3-2. ベクター検索テーブルの作成
まずは ai_parse_document 関数を使って PDF からテキストを抽出し、knowledge_base テーブルに保存しています。
ただ、10個目のセルがそのままだと content の中身がうまく抽出できていなかったため以下のように parsed_document:document.pages となっていた箇所を parsed_document:document.elements に変更しました。(返り値の構造が変わった?)
%sql INSERT OVERWRITE TABLE knowledge_base (product_name, title, content, doc_uri) SELECT ai_extract.product_name, ai_extract.title, content, doc_uri FROM ( SELECT ai_extract(content, array('product_name', 'title')) AS ai_extract, content, doc_uri FROM ( SELECT array_join( -- transform(parsed_document:document.pages::ARRAY<STRUCT<content:STRING>>, x -> x.content), '\n') AS content, transform(parsed_document:document.elements::ARRAY<STRUCT<content:STRING>>, x -> x.content), '\n') AS content, path as doc_uri FROM ( SELECT ai_parse_document(content) AS parsed_document, path FROM READ_FILES('/Volumes/rag_demo_catalog/ai_agent/raw_data/pdf_documentation/', format => 'binaryFile') LIMIT 5 -- ADDED FIX LIMIT FOR DEMO COST - DROP IT IN REAL WORKLOAD ) ) );
次に VectorSearchClient を使ってベクター検索エンドポイントを作成します。
ベクター検索エンドポイントは、インデックスが配置されるエンティティです。検索リクエストを処理するエントリポイントと考えてください。
13個目のセル (VectorSearchClient の SQL) が完了すると、「コンピュート > ベクトル検索」にエンドポイントが作成されていることが確認できます。(私の実行時はプロビジョニング完了まで10分以上かかりました)

エンドポイントが作成されたら、あとは既存テーブル上にインデックスを作成するよう指示するだけです。
Databricks が提供するベクトル検索には3種類あります:
マネージド埋め込み: Databricks がテキストフィールドから埋め込みを生成し、Delta テーブルをインデックスに同期します(今回使用する方法) 自己管理型埋め込み: ユーザー自身が埋め込みを計算し Delta テーブルに保存、Databricks が Delta テーブルをインデックスに同期 直接アクセス: VS インデックス化をユーザー自身が管理(Delta テーブル不要)
15個目のセルで create_delta_sync_index を使用してインデックスを作成します。
テキスト列と埋め込み基盤モデルを指定するだけで、Databricks が自動的にインデックスを構築・同期してくれます。
セルが完了すると、knowledge_base テーブルに紐づいたインデックスが作成されていることが確認できます。

3-3. 既存エージェントへのリトリーバーの追加
インデックスの準備が整ったので、あとは既存のエージェントにリトリーバーとして追加するだけです。
agent.py と agent_config.yaml ファイルを再利用して、リトリーバーの設定を追加するだけで、エージェントが利用可能なツールの一つとして追加してくれます。
19個目のセル実行後に ./ai-agent/02-agent-eval/agent_config.yaml を確認すると、retriever_config が追加されていることが確認できます。

3-4. エージェントの再評価とデプロイ
エージェントが PDF をデータソースとした RAG に対応できたので、改めて評価をして回答精度が向上していることを確認します。
ただ、現状の評価データセットには PDF に関する情報が存在しません。
Databricks では generate_evals_df を使って評価用データセットを簡単に構築できます。
エージェントの説明と質問のガイドラインを与えるだけで、ナレッジベースに含まれるドキュメントに関する質問を含む評価データセットを生成してくれます。
from databricks.agents.evals import generate_evals_df docs = spark.table('knowledge_base') # Describe what our agent is doing agent_description = """ The Agent is a RAG chatbot that answers technical questions about products such as wifi router, Fiber Installation, network information, but also customer retention strategies or guidelines on social media. The Agent has access to a corpus of Documents, and its task is to answer the user's questions by retrieving the relevant docs from the corpus and synthesizing a helpful, accurate response. """ question_guidelines = """ # User personas - A customer asking question on how to troubleshoot the system, step by step - An internal agent asking question on internal policies # Example questions - How do I troubleshoot Error Code 1001: Invalid Return Authorization when a customer can't submit their return request? - I'm getting Error Code 1001 when trying to deploy a survey. What could be causing this and how do I fix it? # Additional Guidelines - Questions should be succinct, and human-like """ # Generate synthetic eval dataset evals = generate_evals_df( docs, # The total number of evals to generate. The method attempts to generate evals that have full coverage over the documents # provided. If this number is less than the number of documents, # some documents will not have any evaluations generated. See "How num_evals is used" below for more details. num_evals=10 , # A set of guidelines that help guide the synthetic generation. These are free-form strings that will be used to prompt the generation. agent_description=agent_description, question_guidelines=question_guidelines ) evals["inputs"] = evals["inputs"].apply(lambda x: {"question": x["messages"][0]["content"]}) display(evals)
2. エージェントのデプロイと評価 > エージェントのデプロイ と同様に31個目のデプロイのセルでエラーが出たため、パラメータに scale_to_zero=True を追加して実行しました。
from databricks import agents # Deploy the model to the review app and a model serving endpoint endpoint_name = f'{MODEL_NAME}_{catalog}_{db}'[:60] if len(agents.get_deployments(model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version)) == 0: agents.deploy( UC_MODEL_NAME, uc_registered_model_info.version, endpoint_name=endpoint_name, tags = {"project": "dbdemos"}, scale_to_zero=True # ←これを追加 )
4. Databricks Apps を使ったエージェントのデプロイと顧客フィードバックの収集
このノートブックでは Databricks Apps を使ってエージェントをデプロイします。
- 4-1. アプリケーションの作成とデプロイ
- モデルサービングエンドポイントの名前を含む設定ファイル(chatbot_app/app.yaml)を作成
- databricks-sdk を使用して、Databricks App を作成
- アプリケーションをデプロイし、アプリケーション URL を取得
デプロイされたアプリの確認
16個目のセルの出力を確認すると、アプリケーションの URL が表示されています。
アクセスするとこのような Gradio ベースのチャットアプリが確認できます。

日本語でメッセージを送ってみましたが、文字化けしていてうまく動作していませんね。

英語で質問すると、ちゃんと回答が返ってきました。取り込んだ PDF も参照してくれていそうです。
アプリ本体のコードは ./chatbot_app/main.py にあるので、日本語対応したりデザインを変更したい場合はここを編集することで対応可能です。(今回は割愛します)
今回は Gradio でしたが、Streamlit や Dash、Fast API で作成する場合は以下のような Cookbook (コードスニペット集) もあるのでぜひご参考ください。
5. エージェントへのモニタリングの追加
MLflow の運用監視は、運用トラフィックのサンプルに対して自動的に品質評価を実行し、手動介入なしに GenAI アプリが高品質を維持できるようにするためのものです。
MLflow では、オフライン評価用に定義したのと同じメトリクスを運用環境でも使用できるため、開発から本番環境までアプリケーションライフサイクル全体で一貫した品質評価を実現します。
- AI Gateway 対応の推論テーブルを使用して、提供されたモデルを監視する | Databricks on Google Cloud
- 本番運用 モニタリング | Databricks on AWS
このノートブックは以下のような流れで進みます。
- 5-1. 評価基準の定義
- カスタムガイドラインを Python で定義
- これには、応答の正確性(事実の捏造がないか)や推論ステップの非表示(ツールの使用などに言及していないか)などが含まれる
- 5-2. 評価者の設定
- 組み込み評価者(例:safety、relevance_to_query、groundedness)と、定義したカスタムガイドラインの評価者(GuidelinesJudge)のリストを作成
- groundedness 評価者には sample_rate=0.4 が設定されており、本番トラフィックの40%をサンプリングして評価することを意味する
- 5-3. モニターの作成
- create_external_monitor 関数を使用して、モニタリングジョブを作成
- このジョブは、指定された Unity Catalog のスキーマにデータを書き込み、評価基準に基づき定期的に(初回実行後に15分ごと)自動で実行される
- 5-4. 結果の確認
- ジョブが実行されるたびに、サンプリングされたトレースに対して各評価者がスコアリングを行います
- 評価結果は MLflow Experiment の Traces タブで確認できるほか、trace_logs_<MLflow_experiment_id> という名前で自動生成される Delta テーブルを SQL で直接クエリして分析することも可能です
5-3. モニターの作成
6個目のセルでモニター作成関数 get_or_create_monitor() が定義されています。
デモ作成当時からエラーログの内容が変更されたのか、私の環境では NoMonitorFoundError のエラーログになっていてうまく拾えていなかったため、例外部分の処理を以下のように修正しました。
except Exception as e: if "No monitor found" in str(e): # ←ここを修正 # Create external monitor for automated production monitoring external_monitor = create_external_monitor( # Change to a Unity Catalog schema where you have CREATE TABLE permissions. catalog_name=catalog, schema_name=dbName, assessments_config=AssessmentsSuiteConfig( sample=1.0, # sampling rate assessments=assessments ) )
設定等が確認できたら、7個目のセルのコメントアウト部分を解除して実行します。
# monitor will create a run that will be refreshed periodically (small cost incures). # uncomment to create the monitor in your experiment! get_or_create_monitor()
モニターが作成されると、trace_logs_<MLflow_experiment_id> という Delta テーブルが自動生成されます。
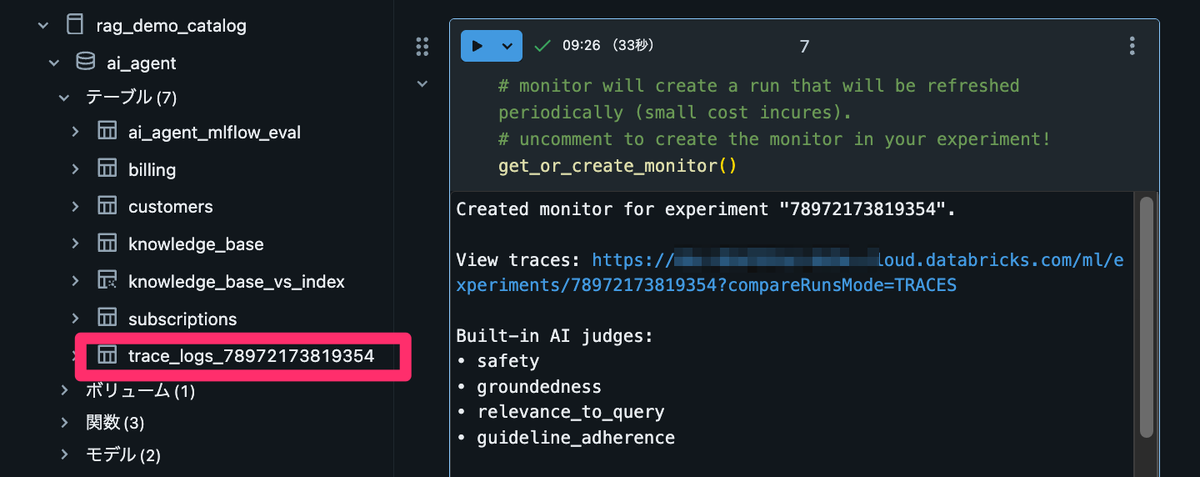
ノートブックに「初回モニタリングジョブが完了するまでには15~30分かかる」と記載があったので2時間ほど待っていたですが、私の環境ではこのテーブルやエクスペリメントタブのトレースにもモニターの実行履歴が反映されませんでした。
こちらについて原因調査中です。

6. エージェントがビジネス指標に与える影響を追跡する (ダッシュボード作成)
新しいエージェントを導入したら、それがビジネスに与える影響を追跡できることが重要です。
一般的に、エージェントは以下を達成するべきとされています。
- 解決までの時間を短縮する
- 顧客満足度を高める
- ビジネス成果を促進する
- サポートチームがより多くの業務を、より高品質な対話で遂行できるように支援する...
Databricks なら CRM やチケットシステムを Lakeflow Connect や任意のデータ取り込みツールで連携し、ビジネス指標に関するデータを準備・変換です。
これによってビジネス指標とエージェントが紐づいたダッシュボードを作成し、Databricks Genie でデータに関するあらゆる追跡質問を投げかけられます。
ノートブック実行後にダッシュボードタブを確認すると、「[dbdemos] AIBI - AI-Assisted Customer Support Team Review」というサンプルのダッシュボードが作成されていることが確認できます。

今回は main カタログ内に dbdemos_aibi_customer_support というスキーマが作成され、そこにカスタマーサポートの情報が格納されています。
実務でもこのように Databricks 上のビジネスデータとエージェントのデータを組み合わせて、ビジネス指標に与える影響を追跡できると非常に便利ですね。
おわりに
長かったですが以上で終了です!おつかれさまでした!
このチュートリアルでは単なるエージェントの作成にとどまらず、RAG の追加、アプリケーションのデプロイ、モニタリング、ビジネス指標の追跡まで一通りの流れを体験できるようになっており、Databricks 上で AI エージェントを構築・運用する際の参考になると思います。
エージェントも作成するだけで終わりではないので、こういった運用面まで考慮されているのは非常に良いですね。
このチュートリアルを参考に、ぜひ皆さんも Databricks 上で AI エージェントを構築してみてください!
香取 拓哉 (記事一覧)
2023年度新卒入社
データドリブンな人間を目指しています
好きな食べ物は芽ねぎ