

この記事では、Databricksで利用されるUnity Catalogにおけるデータの階層構造と、その各コンポーネントの役割を解説します。本記事の最終的な目標は、公式チュートリアルに取り組む際に、Unity Catalog独自の用語でつまずかないように基礎知識を身につけられるレベルです。
- Unity Catalogのコンポーネントと階層
- カタログ (Catalog)
- スキーマ (Schema) / データベース (Database)
- 第3階層のオブジェクト群
- テーブル (Table)
- ビュー (View)
- ボリューム (Volume)
- ファンクション(Function)
- databircks公式のチュートリアル集
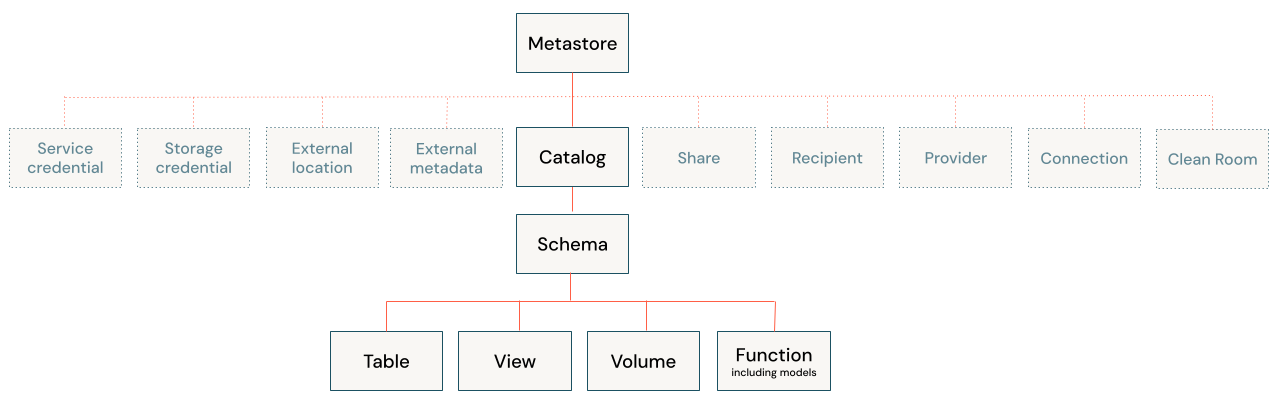
Unity Catalogのコンポーネントと階層
Unity Catalogは、データを管理するために3層の名前空間(catalog.schema.object)を採用しています。これにより、整理されたデータガバナンスを実現します。

{kind=link}
| コンポーネント | 役割 | 階層 |
|---|---|---|
| カタログ(Catalog) | データの最上位コンテナ。アクセス制御やガバナンスの境界を定義します。 | catalog.schema.object (1階層目) |
| スキーマ(Schema)・データベース(Database) | データやAI資産を論理的に整理するコンテナ。Catalogの下位に位置します。 | catalog.schema.object(2階層目) |
| テーブル(Table) | 行と列で構成された構造化データ。SQLでクエリを実行する際の基本単位です。 | catalog.schema.table(3階層目) |
| ビュー(View) | 1つ以上のテーブルに対する保存されたクエリ。仮想的なテーブルとして扱えます。 | catalog.schema.view(3階層目) |
| ボリューム(Volume) | クラウドストレージ上の非構造化データの管理単位。ログファイルや画像、機械学習モデルなどを格納します。 | catalog.schema.volum(3階層目) |
| ファンクション(Function) | 再利用可能なカスタムロジック(ユーザー定義関数)。AIエージェントのツールとしても利用できます。 | catalog.schema.function(3階層目) |
カタログ (Catalog)
Unity Catalogにおける最上位の論理的な組織単位です。複数のスキーマを内包し、データ資産全体のガバナンスとアクセス制御の主要な境界線として機能します。
カタログでは、配下のオブジェクト群(スキーマ、テーブル等)のメタデータ(構造情報)とガバナンスポリシー(アクセスルール)を管理する枠組みを提供します。
データ資産をカタログ単位で分ける場合の主な分け方の例
環境分離 dev(開発)、staging(ステージング)、prod(本番)のように環境ごとにカタログで分離する
組織・部門分離 営業部、マーケティング部、人事部のように部署ごとに取り扱うデータを分ける
セキュリティレベル分離 取り合扱うデータの機密性レベルによってカタログの境界を設ける
カタログレベルで設定したセキュリティポリシーは、配下のすべてのスキーマやテーブルに継承されます。
新規のカタログはdatabricksのフリープランでは新規作成ができません。
スキーマ (Schema) / データベース (Database)
カタログの下に位置する第2層の論理的なグループ化単位です。Unity Catalogでは「スキーマ」と「データベース」は同義語として扱われます。
関連するテーブル、ビュー、ボリューム、関数などを整理・格納するために使用します。従来のRDBMSにおけるデータベースの概念に最も近く、具体的なデータオブジェクトのコンテナとなります。
主な用途
- 特定のプロジェクト、部門、またはデータソース(ごとにスキーマを作成し、データを論理的に分離・整理する
// `my_catalog` カタログ内に `my_schema` という名前のスキーマを作成 CREATE SCHEMA IF NOT EXISTS catalog_name.schema_name;
このコマンドでカタログネームを指定して特定のカタログネームの下にスキーマを作成することができます。
第3階層のオブジェクト群
スキーマの配下には、用途に応じてさまざまなデータオブジェクトを格納できます。
テーブル (Table)
行と列で構成される構造化データを格納する基本単位です。 Databricksでは、ACID特性(原子性、一貫性、分離性、耐久性)を保証するDelta Lake形式が標準で推奨されており、データの実体はクラウドのオブジェクトストレージにファイルとして保存されます。
CREATE OR REPLACE TABLE catalog_name.schema_name.table_name ( test1 INT, test2 STRING, test3 STRING, test4 STRING );
こちらのSQLをコマンドを入力することで、指定したカタログネームとスキーマの下に任意のテーブルを作成することができます。
ビュー (View)
1つまたは複数のテーブル(や他のビュー)に対するクエリ結果を保存した仮想テーブルです。 複雑なクエリを簡略化したり、元のテーブルの一部の列や行のみを特定のユーザーに公開するなど、セキュリティを強化する目的で利用されます。
CREATE VIEW catalog_name.schema_name.view_name AS SELECT test1, test4 FROM catalog_name.schema_name..table_name;
こちらのSQLをコマンドを入力することで、指定したカタログネームとスキーマの下にビューを作るためのテーブル名を指定して任意のビューを作成することができます。
ボリューム (Volume)
非構造化・半構造化データ(ファイル)を管理するためのオブジェクトです。 CSV、JSON、PDF、画像、動画、ログファイルなど、テーブル形式に収まらない多様なデータを、Unity Catalogのガバナンス下で管理できます。実体はクラウドストレージ上のパス(フォルダ)を指しており、ファイルシステムのように直接アクセスできます。
これにより、データレイクの柔軟性を維持しつつ、データウェアハウスのような厳格なガバナンス(アクセス制御、監査、リネージ)を非構造化データにも適用できます。
// `my_catalog.my_schema` 内にボリュームを作成 CREATE VOLUME catalog_name.schema_name.volume_name;
このコマンドでカタログ名とスキーマ名を指定して特定のカタログネーム。スキーマ名の下にボリュームを作成することができます。
ファンクション(Function)
SQLやPythonで記述したロジックを再利用可能にするユーザー定義関数(UDF)です。 繰り返し利用する計算やビジネスロジックを関数として登録しておくことで、誰でも簡単に呼び出すことができます。
ファンクションがテーブルなどと同じ階層にあるのは、データと同様にアクセス権を管理するためです。テーブルにSELECT権限を与えるように、ファンクションにはEXECUTE(実行)権限を付与できます。これにより、「誰がどのロジックを実行できるか」までを細かく制御し、データリネージ(データの来歴追跡)の対象に含めることが可能になります。
databircks公式のチュートリアル集
ここで紹介した階層構造の知識は、以下の公式チュートリアルを進める上で役立ちます
チュートリアル1 ノートブックからのデータのクエリと視覚化
こちらのチュートリアルはサンプルのデータを使って簡単なクエリの使いかたとグラフによる可視化を行うチュートリアルです。
チュートリアル2 ノートブックから CSV データをインポートして視覚化する
こちらのチュートリアルは外部のCSVをUnity Catalogのボリュームにインポートし、Databricksで視覚化をしてワードクラウドを作るチュートリアルとなっています。こちらの作業を行う際に、先ほどの概念を理解することでチュートリアルを進めやすくなります。