

はじめに
今日は、Amazon Athena クエリのパフォーマンスを向上させる方法についてご紹介します!
Athena とは、Amazon S3 に保存されているデータを中心に、SQL を使ってさまざまなデータソースにクエリを実行できるサービスです。
クエリのパフォーマンスを向上させる方法はいくつかありますが、その中でも効果が大きいのが「スキャンするデータ量を減らす」ことです。
Athena の料金はスキャンしたデータ量に応じて発生するため、パフォーマンスを向上だけではなくコストも最適化できます。
Athena がスキャンする必要があるデータ量を減らすための方法として、パーティションとバケッティングというものがあります。
今回は、パーティションとバケッティングをどのように使い分け、併用すればよいか解説します!
パーティションとは
パーティションとは、S3 上のデータをフォルダ(プレフィックス)単位で整理することです。
例えば、日付でパーティション化すると以下のようになります。

2025 年 10 月のデータだけをクエリしたいときは、 year=2025、month=10 のフォルダだけをスキャンすればよく、全データを読み込む必要がなくなります。
バケッティングとは
バケッティングは、データをバケットと呼ばれるカテゴリに整理する方法です。
※ ここで言う「バケット」とは、「Amazon S3 のバケット」とは別物です。
どのバケットにデータが入るかは、ハッシュ関数を使って決まります。
バケットはそれぞれファイルとして保存され、バケットごとにデータが分かれて格納されます。
例えば以下のイラストのように、customer_id を指定してクエリを実行する場合、 どのファイルに目的のデータがあるかがすぐに分かるため、クエリの実行が高速になり、スキャンするデータ量も削減できます。
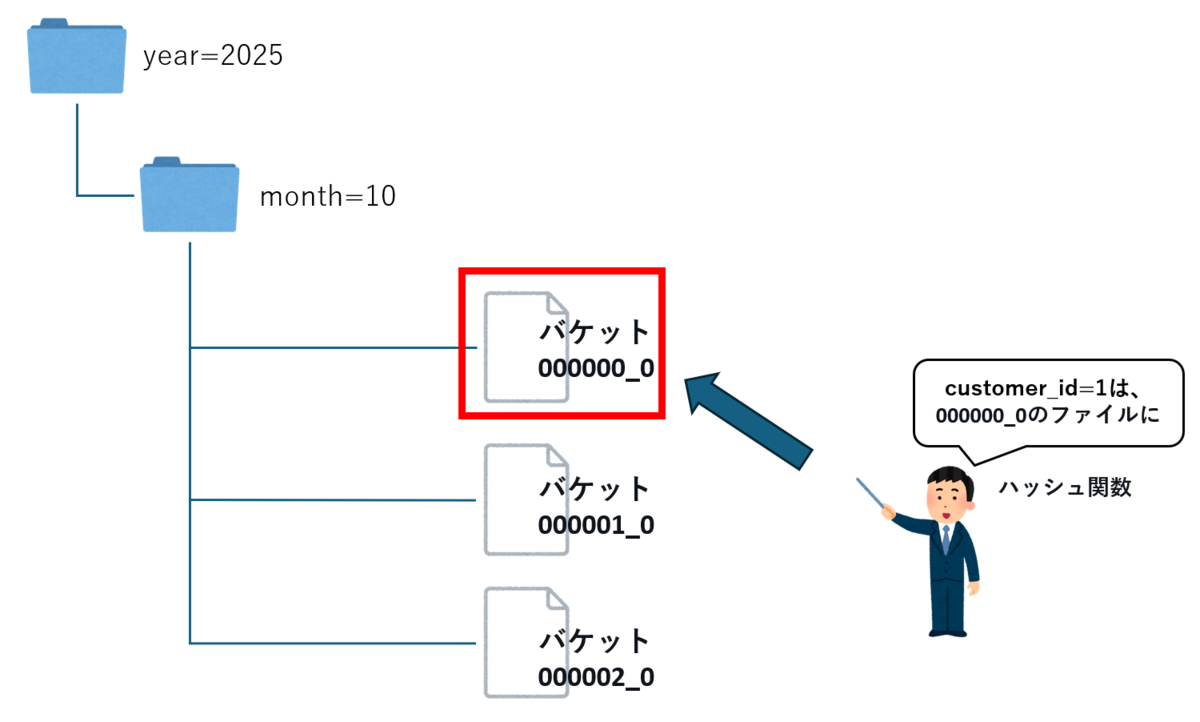
※ 上記のイラストは、パーティション + バケッティングの例です。
パーティションとバケッティングの違い
- パーティション:フォルダ単位で絞り込む
- バケッティング:ファイル単位で絞り込む
パーティションとバケッティングのどちらを使うか
パーティションとバケッティングのどちらを使えばいいか決めるヒントになるのが、「カーディナリティ」です。
カーディナリティとは、「そのカラムに含まれる異なる値の数」のことです。
- 高カーディナリティ(顧客数:customer_id)
- 値の種類が多い(顧客ごとに id が全て異なるため、数万、数十万の値が存在)
- 低カーディナリティ(商品カテゴリー:product_category)
- 値の種類が少ない
高カーディナリティの場合は、「バケッティング」。低カーディナリティの場合は、「パーティション」を使います。
例えば上記の場合、顧客 ID(customer_id)をパーティションにしてしまうと、フォルダが何万、何十万個も作られてしまい、クエリが遅くなってしまいます。
customer_id をバケッティングすると、以下の挙動になります。
- バケッティングで、customer_id をハッシュ関数で分散し、決まった数のバケット(ファイル)に整理
- Athena はクエリ時に「この顧客はどのバケット(ファイル)に入ってるか?」を計算で即特定できるため、無駄なファイルを読まずにクエリ
どうやってバケット化するのか?
バケット化したテーブルは、Athena の CREATE TABLE AS SELECT (CTAS) ステートメントを使うことで簡単に作成できます。
今回の検証でもこの CTAS を使い、既存のテーブルから新しくパーティションやバケットを設定したテーブルを作成しています。
他にも以下の方法でバケット化できます。
- Athena
- CREATE TABLE AS SELECT (CTAS) を使って、一時テーブルをバケット化して書き出し
- 手軽に試すことができる
- Glue
- Spark ジョブを使って S3 にバケット化された Parquet を出力可能
- 大規模データや ETL フローと統合したい場合におすすめ
- AWS Lambda + AWS SDK for pandas(awswrangler)
- awswrangler.s3.to_parquet() を使って、S3 に直接バケット化して保存
- 小〜中規模データの処理やカスタム ETL に向いている
検証
特定の顧客が 2 か月を通じて購入した製品の名前を検索したときに、バケッティングがどれほど効果的か実験してみます。
以下の sales テーブルを想定します。
| customer_id | product | sales_date |
|---|---|---|
| c00001 | product_1 | 2025-02-28 |
| c00001 | product_66 | 2025-02-28 |
| c00001 | product_22 | 2025-02-28 |
| c00002 | product_2 | 2025-02-28 |
| c00002 | product_22 | 2025-02-28 |
データの用意
以下のプログラムを利用し、S3 にパーティショニング、バケッティングされていない Parquet ファイルを、s3://your-bucket-name/sales/raw_parquet/に作成します。
顧客(1 万人)、商品(100 件)、日付(2025/2/1〜3/31)をランダムで 10 万件のデータを作成します。
import datetime
import random
import boto3
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
bucket_name = "your-bucket-name"
s3_prefix = "sales/raw_parquet/"
local_parquet_path = "sales_data_month.parquet"
# データ作成
num_records = 100_000
customer_ids = [f"c{str(i).zfill(5)}" for i in range(1, 10001)]
product_names = [f"product_{i}" for i in range(1, 101)]
start_date = datetime.date(2025, 2, 1)
end_date = datetime.date(2025, 3, 31)
date_range = (end_date - start_date).days
data = {
"customer_id": [random.choice(customer_ids) for _ in range(num_records)],
"product_name": [random.choice(product_names) for _ in range(num_records)],
"sales_date": [
(start_date + datetime.timedelta(days=random.randint(0, date_range))) for _ in range(num_records)
],
}
df = pd.DataFrame(data)
# Parquetファイルに書き出し
table = pa.Table.from_pandas(df)
pq.write_table(table, local_parquet_path)
# S3にアップロード
s3 = boto3.client("s3")
s3.upload_file(local_parquet_path, bucket_name, s3_prefix + local_parquet_path)
パターン 1:パーティション・バケッティングなし(生データ)
パーティション・バケッティングされていない、parquet ファイルに対してクエリします。
まずは、テーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS sales_raw_parquet ( customer_id STRING, product_name STRING, sales_date DATE ) STORED AS PARQUET LOCATION 's3://your-bucket-name/sales/raw_parquet/';
10 万件のすべてのデータから、顧客 id が c08755 で、2025-02-10 のデータをクエリします。
SELECT * FROM sales_raw_parquet WHERE sales_date = DATE '2025-02-10' AND customer_id = 'c08755';
結果
| 実行時間 | スキャン量 |
|---|---|
| 615 ms | 426.41 KB |
全てのデータをスキャンしたので、スキャン量が大きいです。
パターン 2:パーティションあり、バケッティングなし
sales_date (日付)列でパーティション化されたテーブルに対してクエリします。
パーティションを使うことで、指定した日付のフォルダだけをスキャン対象に絞ることができます。
まずは、パーティション付きのテーブルを CTAS(CREATE TABLE AS SELECT)で作成します。
CREATE TABLE sales_partitioned WITH ( format = 'PARQUET', partitioned_by = ARRAY['sales_date'], external_location = 's3://your-bucket-name/sales/partitioned/' ) AS SELECT * FROM sales_raw_parquet;
顧客 id が c08755 で、2025-02-10 のデータをクエリします。
SELECT * FROM sales_partitioned WHERE sales_date = DATE '2025-02-10' AND customer_id = 'c08755';
結果
| 実行時間 | スキャン量 |
|---|---|
| 908 ms | 6.29 KB |
2025-02-10 のパーティションフォルダだけがスキャンされるため、スキャン量は大幅に減少しました。
パターン 3:バケッティングあり、パーティションなし
customer_id をキーに バケッティングのみを行ったテーブルに対してクエリを実行します。
レコードがハッシュ関数によってバケット(ファイル)に分散されるため、Athena は指定された customer_id が どのバケットに入っているかを即座に特定できます。
customer_id をバケットキーとして 8 個のバケット(ファイル)に分けたテーブルを作成します。
bucket_count で、いくつのバケット(ファイル)に分割するか指定します。
CREATE TABLE sales_bucketed WITH ( format = 'PARQUET', bucketed_by = ARRAY['customer_id'], bucket_count = 8, external_location = 's3://your-bucket-name/sales/bucketed/' ) AS SELECT * FROM sales_raw_parquet;
顧客 id が c08755 で、2025-02-10 のデータをクエリします。
SELECT * FROM sales_bucketed WHERE sales_date = DATE '2025-02-10' AND customer_id = 'c08755';
結果
| 実行時間 | スキャン量 |
|---|---|
| 460 ms | 44.27 KB |
バケッティングによって該当バケットだけがスキャン対象となるため、無駄なファイルアクセスが大幅に減り、実行時間が最短になりました。 一方でパーティションによる日付の絞り込みはないため、スキャン量は 2 より多めです。
パターン 4:パーティション+バケッティング併用
sales_date をパーティション、customer_id をバケッティングに設定し、両方の仕組みを組み合わせた構成でクエリを実行します。
CTAS でテーブルを作成します。
CREATE TABLE sales_partitioned_bucketed WITH ( format = 'PARQUET', bucketed_by = ARRAY['customer_id'], partitioned_by = ARRAY['sales_date'], bucket_count = 8, external_location = 's3://your-bucket-name/sales/partitioned_bucketed/' ) AS SELECT * FROM sales_raw_parquet;
顧客 id が c08755 で、2025-02-10 のデータをクエリします。
SELECT * FROM sales_partitioned_bucketed WHERE sales_date = DATE '2025-02-10' AND customer_id = 'c08755';
結果
| 実行時間 | スキャン量 |
|---|---|
| 911 ms | 1.11 KB |
まずパーティションによって sales_date = '2025-02-10' に該当するフォルダのみがスキャン対象となり、 その中でさらにバケッティングにより、該当バケットファイルだけに絞り込まれます。
その結果、スキャン量は最小(1.11 KB)になりました。
比較
| パターン | 実行時間 | スキャン量 |
|---|---|---|
| 生データ(最適化なし) | 615ms | 426.41 KB |
| パーティション(sales_date)のみ | 908 ms | 6.29 KB |
| バケッティング(customer_id)のみ | 460 ms | 44.27 KB |
| パーティション(sales_date)とバケッティング(customer_id) | 911 ms | 1.11 KB |
なぜ実行時間が遅くなったか
今回はデータ量が少ないため(10 万件)、全ファイルをスキャンする時間よりも、どのパーティションやバケットを読むか処理する時間の方が長くなり、パーティションとバケッティングを行った方が処理時間が長くなってしまいました。
パーティションとバケッティングは、データ量がギガバイト、テラバイトと大きくなると「スキャンデータ量の削減」で実行時間が小さくなると思います。
数百万件程度のデータ量であれば、無理に複雑な最適化を行うよりも、Parquet のような効率的なファイル形式で保存しておくだけで十分なことがわかりました。
しかし、スキャン量は圧倒的に小さいことがわかります。
注意点
Athena では、CREATE TABLE AS SELECT (CTAS) クエリごとのパーティション・バケット数は 100 個に制限されています。
HIVE_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions/buckets
また、INSERT INTO 文を使って 既存のバケット化されたテーブルにデータを追加することは、Athena では現在サポートされていません。 そのため、一度作成したバケットテーブルに対して後からデータを追記することができず、検証用に大規模データを用意するのが難しい状況でした。
大規模なデータに対してバケットやパーティションを適用したい場合は、Athena 単体では限界があるため、 Glue や Lambda(awswrangler など)を使って事前にデータを整形しておく必要があります。
結論
パーティションとバケッティングは、Athena でのクエリ効率を大きく左右する重要な仕組みで、使い分けは以下になります。
- 低カーディナリティな列:パーティション
- 高カーディナリティな列:バケッティング
今回の検証では、データ量が少ないためパフォーマンスの差は小さかったものの、 スキャン量は明確に削減されており、設計次第で大きな差になることが分かりました。
クエリの頻度やスキャン量が気になる場合は、バケッティングやパーティションを導入して、S3 上のデータ構造を見直してみるのがおすすめです!