

CI部 佐竹です。
本日は AWS Database Blog の記事翻訳をしながら RDS のコスト最適化について記載します。
- はじめに
- 本題
- Optimizing costs in Amazon RDS
- Approach
- Tagging and tracking the resource utilization
- Defining the utilization policies for the Amazon RDS resource
- Educating the owners and implementing the policies
- Learning and optimizing the policies and processes
- Additional Amazon RDS cost considerations
- RDS instance policies summary
- Summary
- 停止に関する補足
- まとめ
はじめに
本ブログでは RDS DB インスタンス のコスト削減について記載します。
RDS には Compute Optimizer がない
RDS のコスト削減には、現時点で良い推奨機能がありません。EC2 Instance には Compute Optimizer という便利な機能が存在しますが、RDS は表示されません。
2024年6月20日 Compute Optimizer が Amazon RDS MySQL と RDS PostgreSQL に対応
以下の通り、2024年6月20日に、Compute Optimizer が Amazon RDS MySQL と RDS PostgreSQL に対応しました。しかし、Amazon Aurora には未対応のままです。
更新についての追記は以上です。
また現在、私から以下のブログで示している RDS のコスト削減手法は以下の通りです。
- 検証環境における RDS の Multi-AZ オプションを外してシングル構成とする
- 長期間利用されていない RDS DB インスタンスを Snapshot 作成後に削除する
- Cloud Automator の機能で RDS DB インスタンスを夜間&土日祝に停止する
- RDS: Reserved DB インスタンスを購入する
それぞれ詳しく見てみましょう。
検証環境のコスト最適化(Multi-AZ)
先に記載しました1つ目の手法「検証環境における RDS の Multi-AZ オプションを外してシングル構成とする」は、コスト配分タグを付与することが重要です。
もしくは AWS アカウントを用途ごとに分離します(本番環境と検証環境で異なる AWS アカウントとする設計)。
AWS アカウントを用途ごとに分離していない場合、1つの AWS アカウント内に存在する複数の RDS の利用料が入り混じるために、RDS の各利用料が本番環境のものなのか検証環境のものなのか判断ができなくなります。その判断を可能とするため Environment などのタグキーを利用して、コストをタグ別に配分します。タグを付与することで、月額利用料を分析する時に Environment = Staging , Development となっている値を確認することで Multi-AZ のオプションが検証環境に利用されているかどうか判断が可能です。
AWS アカウントを用途で分離している場合は、RDS の構築において Multi-AZ 自体を禁止する IAM Policy や Organizations の SCP、Config Rules 等で制御や発見的統制が可能です。
AWS Organizations については以下でハマりどころをまとめていますのでよろしければご覧ください。
Trusted Advisor のコスト最適化に Idle RDS の項目が存在する
Compute Optimizer はないものの、上に記載した一覧にある「長期間利用されていない RDS DB インスタンス」に値する項目は Trusted Advisor で検知が可能です。
Amazon RDS のアイドル状態の DB インスタンス
Amazon Relational Database Service (Amazon RDS) の設定をチェックし、アイドル状態だと思われる DB インスタンスがないか確認します。DB インスタンスへの接続が長期間にわたって行われていない場合は、コストを削減するためにインスタンスを削除できます。そのインスタンスのデータに関して永続的ストレージが必要な場合は、DB スナップショットを作成して保管するなど、より低コストの方法を使用できます。手動で作成した DB スナップショットは、削除するまで保持されます。https://aws.amazon.com/jp/premiumsupport/technology/trusted-advisor/best-practice-checklist/
加えて Trusted Advisor は以下の Organizational view を活用することで、コスト最適化項目を組織内の全AWSアカウントまとめて確認が可能です。
検証環境のコスト最適化(停止)
「Cloud Automator の機能で RDS DB インスタンスを夜間&土日祝に停止する」は、本番環境以外で運用します。
Multi-AZ のケースと同様に、コスト配分タグもしくは AWS アカウント単位で利用料を分析することで用途の判断が可能です。
月次の利用料で確認するべきポイントは「Running Hours(起動していた時間/月)」で、720時間(31日だと744時間になります)のものが常時起動と判断可能です。コスト配分タグキーとして設計した Name タグを必ず設定し、そのバリューとして DB Instance Identifier を入力する運用を行うことで、どの RDS インスタンスが夜間停止しているのか判断できます。また Environment キーでも正常に夜間停止できているか等の判断が可能です。
加えて Cost Explorer では Hourly の表示を有効活用することで夜間停止が視覚的に確認できます。
実際に夜間と土日に停止している RDS DB インスタンスは以下のような利用料推移になります。平日の営業時間中には利用料が発生していますが、平日夜間と土日は利用料が $0 で推移しています。
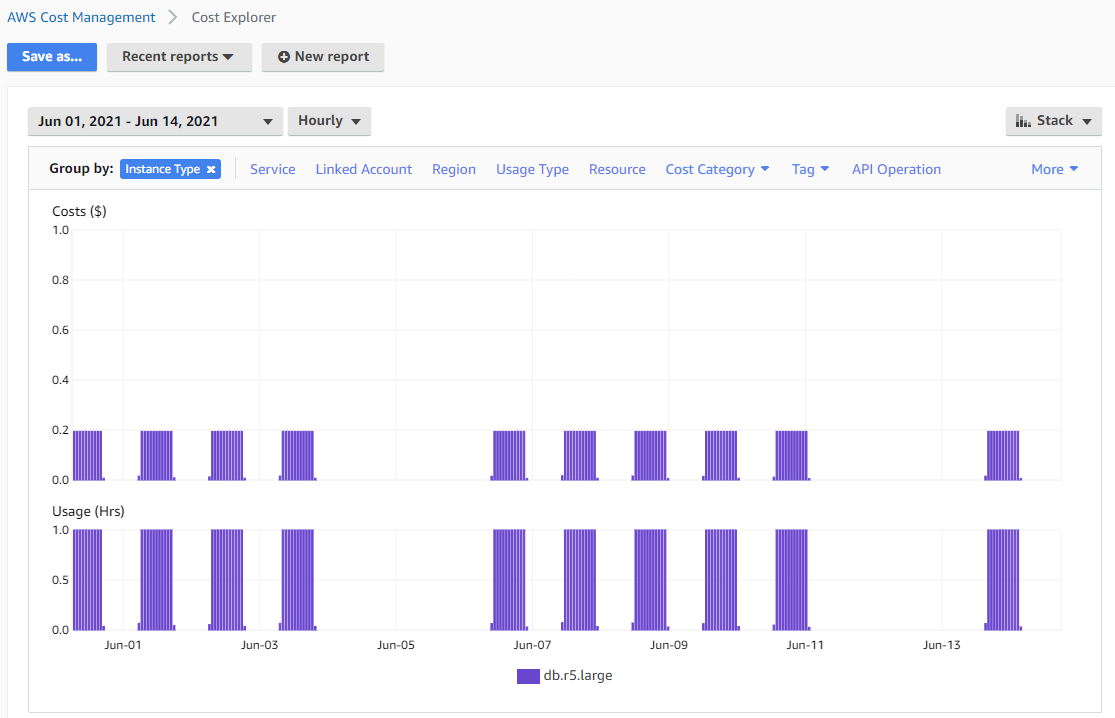
RDSは7日間連続で停止していると自動的に起動する仕様のため、7日間以上停止する場合は注意が必要です。その他 RDS の停止に関するデメリットは以下に記載しておりますので合わせてご覧ください。
さらなる注意点として、この後記載しますリザーブドインスタンス (RI) とどちらがコスト最適化に有効なのかは比較が必要です。「土日でも平日と同様の時間帯に起動が必要」な場合には、常時起動としリザーブドインスタンスを購入するほうがコスト最適化される場合もあるためです。特に RDS の停止には先のブログに記載しましたデメリットもありますので、環境の安定化を優先しリザーブドインスタンスでのコスト最適化を行う判断もあり得ます。
本番環境のコスト最適化(RI)
「RDS: Reserved DB インスタンスを購入する」の項目は常時起動となっている RDS、つまり基本的に本番環境に対して行うコスト最適化です。
RDS の RI に関するFAQは以下にまとめておりますので、こちらも合わせてご覧ください。
少しトリッキーな使用方法となりますが、「RI の推奨項目を逆手に取ったコスト削減手法」も存在します。
以下は Organizations の Payer(Management Account)で確認した推奨です。Generate recommendations based on: はデフォルトで全アカウントをまとめた推奨になっていますが、個別アカウントごとの推奨値も表示できます。個別表示にし、さらに Based on the past を 7 days に設定します。
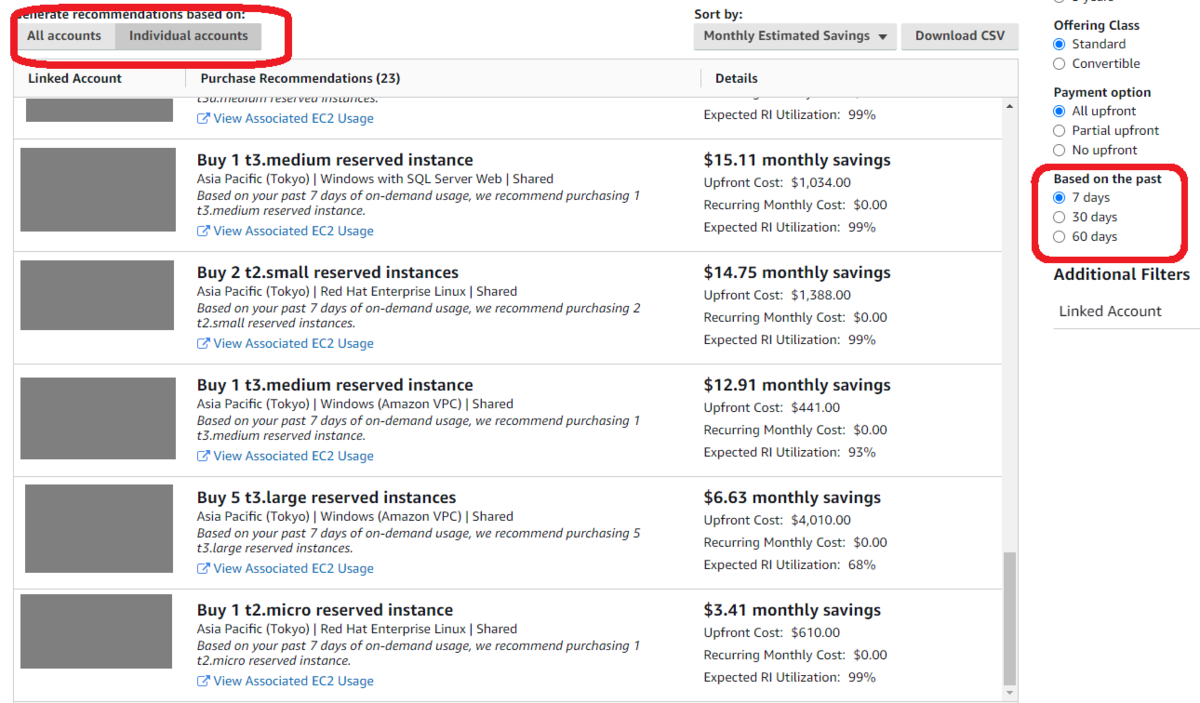
この表示における一覧は、その AWS アカウントに直近7日間「常時起動(もしくはそれに近い稼働時間)の RDS がある」ことがわかります。この推奨一覧に表示された AWS アカウントがもし「検証用 AWS アカウント」であれば推奨に表示されたのは「検証環境なのに常時起動になってしまっている RDS が存在するのでは?」と簡易的に判断できます。Cost Explorer を見て判断するよりも判断が容易なため、是非この方法も取り入れてみてください。
補足
これら4つの手法が RDS のコスト最適化における「全ての手法」ではありませんが、この機会に以前記載した内容を解説させて頂きました。
本題
さて、ここまで書いてきて最初に書いた「RDS には Compute Optimizer がない」という話に戻ります。
「RDS のインスタンスクラスが大きすぎるのではないか?」「どうすればインスタンスクラスを下げるべきかどうか判断できるのか?」というのが疑問点になります。これを解明すべく、以下の英語ブログを和訳します。
また本ブログは以下のブログに続く AWS Database Blog の翻訳記事第2弾になります。
ここから先はブログ記事「Optimizing costs in Amazon RDS」の翻訳になります。なお「補足:」と記載している箇所は全て私による補足部分であり、原文には存在しません。
Optimizing costs in Amazon RDS
AWS の主な利点の1つとして、アプリケーションが必要とするリソースの数をプロビジョニングし、要件の変化に応じてスケールアップまたはスケールダウンできる柔軟性があります。これには、現在のリソース使用率を監視し、必要に応じて対応アクションを実施するポリシーを運用することが求められます。これらの事前準備がない場合、リソースのプロビジョニングが不足または過剰になってしまう可能性があります。リソースのプロビジョニングが不十分な場合、パフォーマンスに直接影響するため、リソースはエスカレーションされて修正されます。ただし、過剰にプロビジョニングされたリソースは、アプリケーションの中断につながる直接的な機能への影響はないため、見落とされることがよくあります。その結果「過剰に割り当てられたままのリソースを見つけ出し」、「サイズを縮小しコストを最適化する」という対応が運用上必要となってくる場合があります。
本投稿では、ベストプラクティスを使用して、クラウドインフラストラクチャにおける Amazon RDS フットプリント(今まで通ってきた道筋)を最適化するための推奨事項を提供します。
Approach
RDS におけるコスト最適化アプローチは、主に次のステップで構成されます。
- 利用中のリソースにタグを付与し、追跡します
- RDS リソースの利用ポリシーを定義します
- 所有者を教育し、ポリシーを実装します
- ポリシーとプロセスを学び、最適化します
次の図は、このワークフローを示しています。

次のセクションでは、各ステップの詳細を説明します。
Tagging and tracking the resource utilization
コスト最適化に向けた最初のステップは、リソースへ適切にタグを付与し、それらの使用率の追跡を開始することです。 AWS には任意の RDS インスタンスへ容易にタグを付ける機能が提供されています。これを実施するには、Amazon RDS マネジメントコンソールでインスタンス一覧を閲覧します。 [タグ] タブで、RDS インスタンスの所有者を明確に識別するために必要なタグを追加します。タグ付けの詳細については、「Amazon RDS リソースのタグ付け」を参照してください。

アプリケーション名や組織グループなど、Amazon RDS リソースの識別に役立つタグを追加できますが、次の2つのタグをお勧めします。
- データベース所有者(Database owner)
- アプリケーションの所有者(Application owner)
これらの情報は、所有者をすばやく特定することで、コスト最適化を行う必要が出た場合にその連絡を容易にします。
RDS はアクティブなデータベースインスタンスごとに毎分 Amazon CloudWatch にメトリクスを自動的に送信するため、リソース使用率を追跡するために何もする必要はありません。CloudWatch の Amazon RDS メトリクスに追加料金はかかりません。これらのメトリクスの詳細については、「Amazon RDS のモニタリングの概要」を参照してください。
Amazon RDS と CloudWatch の統合により、リソース使用率の追跡が容易になります。次のステップは、コスト最適化の機会(opportunities が原文です)が訪れたことを把握するために役立つポリシーを作成することです。次のセクションではポリシーに焦点を当てます。
Defining the utilization policies for the Amazon RDS resource
このステップでは、(RDS を利用しているシステムの)関係者が「十分に活用されていない RDS インスタンス」を識別するためのポリシーを定義し、そのように判断された RDS が見つかった場合に実行するアクションを定義します。これらのポリシーは、Amazon RDS の主要な3つの側面をカバーしています。
- Read replicas:リードレプリカ
- Unused instances:未使用のインスタンス
- Primary instance:プライマリインスタンス
次のセクションでは各ポリシーにおける推奨事項を記載します。
Read replica policy
Amazon RDS リードレプリカは、RDS DB インスタンスのスケーラビリティと耐久性を強化します。リードレプリカは、リードトラフィックを水平方向にスケーリングする機能を提供します。本機能は読み取りが多いデータベースワークロードにとって特に有益です。
Amazon RDSでは、Multi-AZ とリードレプリカは2つの異なるタイプのインスタンスです。Multi-AZ 用に作成されたスタンバイインスタンスにはアクセスできず、高可用性のためにのみ使用されます。一方、Amazon Auroraでは、Multi-AZ スタンバイはアクセス可能なもう1つのリードレプリカです。そのため、Auroraクラスターの高可用性を実現するには、未使用の場合でも1つのリードレプリカが必要です。

他のすべての Amazon RDS および Aurora リードレプリカの場合、CPU と I/O の使用率を評価して、それらが実際に必要かどうかを判断する必要があります。リードレプリカを決定するときは、次の基準を考慮してください。
- プライマリインスタンスにおける、I/O および CPU 使用率が常に30%未満の場合は、リードレプリカを作成する必要がないと判断します
- リードレプリカにおける CPU および I/O 使用率が常に30%未満の場合は、より小さなインスタンスクラスを使用する可能性を検討してください。プライマリインスタンスにキャパシティ(余裕)がある場合は、負荷をプライマリに転送して、リードレプリカをシャットダウンすることも検討できます
たとえば、使用率が 30% の db.r4.4xlarge(16 vCPU)のリードレプリカを使用している場合は、db.r4.2xlarge(8 vCPU)へのダウンサイジングを検討する必要があるでしょう。vCPUの数が半分になることで、CPU 使用率は約 60% 〜 70% 程度に増加すると予想されます。これにより、予期しないスパイクや将来のトラフィックのオーガニックな増加に備えて、約30%のバッファが残ります。
(補足:ここでのオーガニックとは「オーガニックグロース」などで使われるオーガニックで、そのシステムの利用者等が増加することで将来的に負荷が内側から増加していくということがこの単語で示されていると考えられます)
各インスタンスタイプ(補足:RDSはインスタンスクラスとも記載します)ごとにサポートされる最大 I/O 帯域幅それぞれ予め設定されているため、I/O スループットも非常に重要になります。スケールダウンを行うと、サポートされる I/O 帯域幅も合わせて低下してしまうため、現在の要件が帯域幅の削減後も十分である(満たされている)ことを確認することが重要です。たとえば、db.r4.4xlarge から db.r4.2xlarge にダウンサイズすると、使用可能な最大帯域幅が 7000Mbps から 3500Mbps に低下します。詳細については、DBインスタンスクラスのハードウェア仕様を参照してください。
Production(本番環境)でのリードレプリカの場合、30% をしきい値として判断することを推奨します。機能テストのみに使用されるような Non-Production(非本番環境)の場合、判断のための使用率のしきい値を 50% とより攻めた値にすることができるでしょう。つまり、CPU使用率が 50% 未満のリードレプリカは、より小さなインスタンスクラスへの適正対象候補とされることもあり得ます。
Unused instances policy
未使用の RDS インスタンスは全体的なコストを増加させ、なんら価値を与えません。組織で定義されているポリシーに従い、未使用のインスタンスをすべて識別してシャットダウンすることをお勧めします。インスタンスは、迅速なテストのために Non-Production(非本番環境)として容易に作成されることがあり、またテスト完了後にクリーンアップされることはありません。これらの未使用インスタンスは未使用のままであり、不必要にコストが増加します。未使用のインスタンスを識別するには、次の基準を考慮してください。
- 1か月間(要件によってはそれ以下)データベースへの接続がない
- CPU 使用率と I/O が常に 5% 未満である
十分に活用されていない RDS インスタンスを特定したら、所有者に通知する必要があります。彼らが何も行動を起こさない場合は、問題をエスカレーションする必要があります。次の手順を検討できます。
- DBインスタンスをシャットダウンするため、データベースとアプリケーションの所有者にメールを送信します
- メールの内容にインスタンスシャットダウンまでのデッドラインを記載します。もしくは例外的にそのインスタンスをシャットダウンしないように扱うか記載します
- デッドラインが過ぎたら、シャットダウンをすることのリマインダーを送信し、マネジメント層にエスカレーションします
RDS インスタンスを削除する前に、DB スナップショットを作成することを推奨します。これにより、RDS インスタンスを復元する必要がある場合は、最後のスナップショットを使用して復元できるようになります。
補足1:未使用の RDS は先に記載したように Trusted Advisor にて「アイドル状態の DB インスタンス」としてフックすることが可能です。なお Trusted Advisor の場合は最長14日間の分析になります。記載されているように1カ月間コネクションがない RDS を検知するには、CloudWatch メトリクスを参照する必要があります。詳しくは「コスト削減のため Trusted Advisor の RDS Idle DB Instances を定期通知する」を参考ください。
補足2:RDS を削除する時には、自動バックアップのスナップショットを Retain(維持)する選択も可能なため、本機能を有効活用することができる場合もあるでしょう。但し何らかの理由で自動バックアップを OFF にしている場合もありますので Final Snapshot を取得されることを推奨します
補足3:ここで記載されるシャットダウンとは、RDSにおける「一時的な停止:Stop」なのか「完全な削除:Delete」なのか判断が付かないですが、最後に削除と記載していることから「Delete」のことを示していると想定されます
Primary instances policy
プライマリ RDS インスタンスは、アプリケーションの読み取りおよび書き込みトラフィックを処理します。したがって、アプリケーションの要件を満たすように適切なサイズにすることが重要です。同時に、十分に活用されていないまま放置すべきでもありません。使用率の低いプライマリインスタンスを特定するに、CPU使用率が 30% 未満、I/Oが 30% 未満のインスタンスを繰り返し探し出します。
十分に活用されていないインスタンスを特定したら、次の手順を実行します:
- データベースとアプリケーションの所有者に、インスタンスのサイズを適切に設定するように通知します
- インスタンスのサイズを適切に設定するか、例外的にダウンサイズしないように扱うかデッドラインを含めて記載します
- リマインダーを送信し、期限が切れたらマネジメント層にエスカレーションします
機能テストに使用され、パフォーマンス検証に関連しない Non-Production(非本番環境)プライマリインスタンスの場合、適切なサイズ設定の I/O および CPU 使用率のしきい値を 30% 未満から 50% 未満に増やすことができます。これにより、適切なサイズ設定の候補となり得るインスタンスをさらに特定できるようになります。
補足:パフォーマンス検証は本番環境と同等のスペックが必要となるためパフォーマンスを意図した検証用 RDS は除外すべきという文脈で記載されているようです。機能テストには基本的に速度は必要とされません
Educating the owners and implementing the policies
ポリシーを定義したら、これらのコスト最適化のベストプラクティスについてデータベースとアプリケーションの所有者をそれぞれ教育することが重要です。彼らはこれらのポリシーの重要性と、それがポートフォリオ(資産構成)のコストにどのように影響するかを認識している必要があります。
ステークホルダーが全員参加している状態で、組織全体にポリシーの実装を開始する必要があります。小規模な Amazon RDS データベースフリートの場合、これは月に1回の手動評価で効果が得られるでしょう。大規模な組織の場合、デイリーまたはウィークリーの自動化プロセスを用いて(CloudWatch の)メトリックをチェックし、所有者へ警告のための電子メール通知を送信します。
Learning and optimizing the policies and processes
このプロセスを実装した後も、改善すべき領域を引き続き監視および特定することが重要です。これにより、ワークロードと組織のニーズに合わせてポリシーとプロセスを継続的に進化させることができます。このフェーズでは、自動化を実装して、ワークロードの変化に応じてフリート内のインスタンスを自動スケーリングおよび適切なサイズにすることを検討できます。インスタンスタイプを変更するとダウンタイムが発生するため、ワークロードに影響を与えないように、または最小限の影響しか与えないように計画することが重要です。
Additional Amazon RDS cost considerations
RDS インスタンス使用率ポリシーに加えて、他のいくつかの領域でコストを最適化できます。このセクションでは、アプリケーションの要件に基づいて検討可能ないくつかの追加推奨事項について説明します。
Backups
Amazon RDS バックアップライフサイクルポリシーを確認し、組織のコンプライアンスおよび保持ポリシーに基づいて手動および自動で作成されたデータベースバックアップスナップショットを削除することを検討してください。自動バックアップは、定義した保持ポリシーに従って削除されますが、手動バックアップが自動的に削除されることはありません。詳細については、バックアップの操作を参照してください。
補足:手動バックアップのスナップショットを長期間保持していると無駄なコストが発生するため、それを定期的に削除する運用が推奨されます
Storage
Aurora では、ストレージのタイプを制御しませんが、通常の RDS インスタンスでは、インスタンスで使用する Amazon Elastic Block Store(Amazon EBS)ボリュームタイプを選択できます。多くの顧客と協力して判明したことですが、開発環境およびステージング環境におけるワークロードの大部分は汎用SSDストレージで適切に機能していることが明らかになっています。 I/O が多く必要とされるワークロードの場合には、Provisioned IOPS SSD ストレージは確かに優れたオプションですが、他のワークロードの場合、汎用 SSD で十分に機能するはずです。汎用 EBS ボリュームサイズが 1TB 未満の場合は、EBS バーストモードの概念を理解することが重要です。バーストモードでは、I/O クレジットが利用可能である限り、最大 3000 IOPS に到達できます。 I/O クレジットが消費されるとすぐに、IOPS は実際に使用可能な IOPS 制限まで低下します。詳細については、「Amazon RDS および gp2 でのバーストとベースラインのパフォーマンスについて」を参照してください。最適なパフォーマンスを確保するには、IOPS の使用率を定期的に監視する必要があります。
補足:PIOPS(Provisioned IOPS)は非常に高額なオプションであり、また停止中の RDS でも料金が発生し続けます。PIOPS のオプションを削減するだけで年間数百万円以上のコスト削減ができることもありますので、見直されることを推奨します
Memory
利用可能な RDS インスタンスメモリはデータベースのパフォーマンスに不可欠ですが、ダウンサイズの決定はメモリの使用率に基づくことはできません。これは、インスタンスメモリの大部分が内部データベースバッファ(Oracle の SGA、Aurora PostgreSQL の Shared バッファ)に割り当てられているためです。このため、アイドル状態の RDS Oracle インスタンスにおいては接続がない状態でも、使用されているメモリ量が 70% と表示される場合があります。同様に Aurora PostgreSQL では、shared_buffers はデフォルトで使用可能なメモリの約 75% を使用するように構成されているため、アイドル状態のインスタンスでも使用済みメモリが表示されます。
データベースエンジンは、データブロックをキャッシュするために使用可能なメモリに依存しています。このキャッシュされたデータは、クエリの高速化に役立ちます。アプリケーションがクエリの特定の低レイテンシ SLA を満たす必要がある場合、インスタンスタイプをダウングレードすると影響が生じる可能性があります。たとえば、db.r4.4xlarge から db.r4.2xlarge にダウンサイズすると、使用可能なメモリが 122GB から 61GB に減少します。これにより、データベースのキャッシュが小さくなるため、データベースエンジンはストレージからより多くのページを読み取る必要があります。ストレージからのフェッチはキャッシュフェッチよりも遅いため、クエリ時間が長くなる可能性があります。また、キャッシュが小さいほど、アプリケーションがより多くの IOPS を必要とする可能性があるため、ストレージ I/O が増加することにも注意してください。アプリケーションの所有者は、本番環境でインスタンスをダウンサイジングする前に、レイテンシの影響を受けやすいアプリケーションへの影響を評価することが重要です。Amazon Aurora では、データベースが消費する I/O の利用料を別で支払う仕組みのため、インスタンスタイプのダウングレードを決定する前に、I/Oコストの影響も分析する必要があります。
補足:Amazon Aurora の東京リージョンにおける I/O 料金は現在以下の通りです
| 項目 | 利用料 |
|---|---|
| I/O 料金 | 0.24USD/100 万リクエスト |
Instance type
Amazon RDS は、データベースワークロードに必要なインスタンスタイプ(インスタンスクラス)を選択する柔軟性を提供しています。各インスタンスタイプは、特定の CPU、メモリ、EBS 帯域幅、およびネットワークパフォーマンスをサポートします。アプリケーションの所有者は、ワークロード要件に基づいてインスタンスタイプを選択する必要があります。たとえば、CPU を集中的に使用するワークロードの場合は、M 系ファミリーのインスタンスの方が適していますが、メモリを大量に消費するワークロードの場合は、R 系ファミリーの方が適しています。前のセクションで説明したように、インスタンスタイプを変更するためには、要件を注意深く検討した後となります。データベースワークロードの大部分はメモリを大量に消費するため、最新の R 系および X 系ファミリーインスタンスを使用して評価することも検討してください。詳細については、Amazon RDS インスタンスタイプを参照ください。
補足:「ファミリー」という単語については以下のブログにて説明しておりますのでご参考ください。
RDS instance policies summary
次の表で、本投稿で説明してきたサンプルポリシーの概要を示します。
| 項目 | 環境 | RDSの統計 | アクション |
|---|---|---|---|
| リードレプリカ | All | CPU 使用率 < 30% 且つ I/O スループット < 30% | 負荷をプライマリに転送し、シャットダウンまたはダウンサイズします |
| 使用率の低いRDS (未使用のRDS) |
Prod | 1カ月以上コネクション無し, CPU 使用率 < 5% 且つ I/O スループット < 5% |
所有者に警告を通知、期限までに対応がなされない場合はエスカレーションします |
| 使用率の低いRDS (未使用のRDS) |
Non-Prod | 1カ月以上コネクション無し, CPU 使用率 < 5% 且つ I/O スループット < 5% |
所有者に警告を通知、期限までに対応がなされない場合はエスカレーションします。 期限が過ぎた場合、Snapshotを作成しシャットダウンします |
| インスタンスサイズ適正化 | Prod | CPU 使用率 < 30% 且つ I/O スループット < 30% | 所有者に警告を通知、期限までに対応がなされない場合はエスカレーションします |
| インスタンスサイズ適正化 | Non-Prod | CPU 使用率 < 50% 且つ I/O スループット < 50% | 所有者に警告を通知、期限までに対応がなされない場合はエスカレーションします。 期限が過ぎた場合、Snapshotを作成しダウンサイズします |
CPU 使用率と I/O スループットのメトリクスは CloudWatch にて確認が可能です。CPU 使用率 CPUUtilization は、監視する期間の最大 CPU 使用率とする必要があります。I/O スループットは、読み取りスループット ReadThroughput と書き込みスループット WriteThroughput の合計で、RDSインスタンスが許容可能な(補足:インスタンスクラスによって予め定められている)最大の I/O スループットと比較します。最大許容スループットの詳細については、DB インスタンスクラスのハードウェア仕様を参照してください。
補足:以下、公式ドキュメントの通り、RDS はストライピングによりスループット等のパフォーマンスを向上させます。そのため汎用 SSD を利用している DB インスタンスであっても gp2 の最大スループットである「250 MB/秒」を超える値が CloudWatch メトリクスに記録されることがあります(ストライピングをどの程度のサイズごとに行っていくのかは明かされていません)
要求されるストレージの量によって、Amazon RDS は自動的に複数の Amazon EBS ボリューム全体をストライプして、 パフォーマンスを向上させます。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/CHAP_Storage.html
Summary
この投稿に記載された推奨事項が、RDS インスタンスのコスト最適化に役立てば幸いです。すべてのアプリケーションはアーキテクチャの観点から見ると同じものは1つとしてなく、利用されるパターンと SLA が異なることに注意を払うことが重要です。従って、本番環境に適正化を反映する前には、常に検証とレビューを事前に実施することが不可欠です。一方、Non-Production(非本番環境)のDBインスタンスでは、シャットダウンするか、適切なサイズに変更するかというこれらの処理を自動化してしまうことも可能でしょう。ただし、本番インスタンスの場合は、インスタンスクラスを適正化または停止(補足:原文は Stop です)する前に、アプリケーションの所有者と協力し使用パターンを理解することをお勧めします。
停止に関する補足
本文では常時「shut down」が使われてきていましたが、最後の最後に「Stopping」と明確に Stop (停止) という言葉が出てきました。この言葉は shut down の繰り返しを嫌っただけかもしれませんので、削除もしくは停止、どちらの意味もあるかもしれません。ただ、以下のブログを先にご紹介しました通り、本番環境での停止は推奨される運用ではありません。検証環境やステージング環境においては停止によるコスト削減は有効ですが、本番環境においての停止は仕様をよく理解した上で設定ください。
まとめ
本ブログでは RDS DB インスタンスのコスト削減について記載してきました。
最初に、ブログに記載済の4つの手法を掘り下げました。
- 検証環境における RDS の Multi-AZ オプションを外してシングル構成とする
- 長期間利用されていない RDS DB インスタンスを Snapshot 作成後に削除する
- Cloud Automator の機能で RDS DB インスタンスを夜間&土日祝に停止する
- RDS: Reserved DB インスタンスを購入する
これらの中に RDS インスタンスクラスのダウンサイズという項目がありません。それは RDS が「Compute Optimizer」に対応していないためですが、そのような状況で「どうすればインスタンスクラスを下げるべきかどうか判断できるのか?」という内容を Database Blog の翻訳をしながら確認したかったというのが目的でした。
Database Blog の翻訳をしていく中で、50%, 30%, 5% という閾値と、さらにメモリが判断材料には使えないということが明確になりました。加えて、リードレプリカのコスト最適化についても学習することができました。
RDS に対するコスト最適化メニュー
そして最後に、翻訳元の記事に記載されていない内容も含め、現時点での RDS に対するコスト最適化メニューを以下に網羅します。
- 検証環境における RDS の Multi-AZ オプションを外してシングル構成とする
- Cloud Automator の機能で RDS インスタンスを夜間&土日祝に停止する(※本番環境を除く)
- 常時起動となっている本番ワークロードに対して RDS: Reserved DB インスタンスを購入する
- 使用率の低いリードレプリカをダウンサイズする、もしくは削除する
- 未使用のリードレプリカを削除する
- 使用率の低い プライマリ RDS インスタンスをダウンサイズする
- 未使用のプライマリ RDS インスタンスを Snapshot 作成後に削除する
- 不要となった手動取得のバックアップスナップショットを削除する
- RDS 削除時に Retain した自動バックアップのスナップショットを削除する
- ストレージの PIOPS(Provisioned IOPS)の IOPS 値を下げるか、オプションの利用を取りやめ、SSD(汎用)に変更する
- 拡張されたストレージを縮小するために、より小さいサイズのストレージを持った RDS を構築し、データを移行することでストレージを縮小する
- Aurora の dynamic resizing を有効活用する
- Amazon RDS において、コストパフォーマンスに優れたGraviton2 プロセッサで動作するインスタンスファミリーに変更する
- Aurora において1時間あたりの利用料の低い Graviton2 で構成された r6g ファミリーに変更する
- 急なスパイクに対応するために、Aurora AutoScaling を活用する
- Amazon Aurora Serverless を活用する
- DMS 等を利用し、DB Engine を有償の MS SQL Server もしくは Oracle DB から OSS の DB Engine へと移行する
RDS for Oracle (BYOL) における RI の柔軟性について
他にも RDS for Oracle (LI) のライセンスを BYOL に移行することにより、リザーブドインスタンスが柔軟性の恩恵を得られることで、同ファミリー内で柔軟に RI が購入&運用できるようになるという手法もあります。具体的には RDS for Oracle (LI) の Single-AZ と Multi-AZ では別のリザーブドインスタンスとして扱われるため「柔軟性がない」となりますが、RDS for Oracle (BYOL) では柔軟性があるために Single-AZ と Multi-AZ のリザーブドインスタンスはそれぞれが柔軟に適用されます。合わせて具体的な例を以下に示します。
| ライセンス | 柔軟性 | RI の柔軟性に関する具体例 |
|---|---|---|
| LI(License Included) | なし | Single-AZ の RI と Multi-AZ の RI はそれぞれ別として扱われる。 db.m5.xlarge の RI と db.m5.large の RI は別として扱われる |
| BYOL | あり | Single-AZの RI は1台分、Multi-AZ の RI は2台分として扱われる。 db.m5.xlarge の RI は db.m5.large × 2台分の RI として扱われる |
長文となりましたがこれにて終了となります。
それではまたお会いしましょう。
佐竹 陽一 (Yoichi Satake) エンジニアブログの記事一覧はコチラ
セキュリティサービス部所属。AWS資格全冠。2010年1月からAWSを業務利用してきています。主な表彰歴 2021-2022 AWS Ambassadors/2020-2025 Japan AWS Top Engineers/2020-2025 All Certifications Engineers。AWSのコスト削減やマルチアカウント管理と運用を得意としています。