

はじめまして。2025年5月にサーバーワークス(以下、SWX)に中途入社した椿山です。
SWXでは私のような40代後半の中途社員にも4ヶ月間(予定)の研修期間が設けられ、 入社後まずはSWXの社風や文化、規則やルール、AWSの基礎や構築・運用案件の進め方等の研修を受けた後、 現在は模擬案件で実際にAWSの設計・構築~運用代行準備を行ったり、AWSの最新アップデートを課内で発表したりしています。
さて、6月25日~26日に幕張メッセで開催された年に一度のお祭り「AWS Summit Japan 2025」ですが、 私も(数年ぶりに)Day2に行ってきましたので、その様子と特に面白かったセッションについて、前編・後編に分けてご紹介いたします。
前編は、会場の様子と「Aurora DSQL アーキテクチャ詳細」のセッションレポートです。
目次(クリックすると展開されます)
会場の様子
AWS Summitへの現地参加は2019年の幕張メッセ以来、6年ぶりとなります。

とにかく規模が大きい!そして人が多い!

恒例のAWS Outposts(第二世代)のラックも拝んできました。

そしてクッションとAWS認定保持者のステッカー。来年までには全冠を目指します。

弊社ブース
SWXはブースを出展するとともに、カスタマーサクセス部の村上がパートナーセッションにて「生成 AI 活用で見えてきた 3 つの課題 ~精度・セキュリティ・推進体制~」 *1 というタイトルで登壇。

上の写真でブースセッションを準備しているマネージドサービス部の佐竹は前日に特別賞を受賞しています。
SWXの広報ブログもぜひご覧ください。
セッションレポート①:Amazon Aurora DSQL アーキテクチャー詳細
当日は午前のスペシャルセッションに始まり、AWSセッション・事例セッション・パートナーセッションにて様々な発表がありました。 やはり生成AI系の発表が多く、どれを聞くか迷いましたが、久しぶりのAWS Summitということで、 今回はAWSのアーキテクチャ設計や運用のベストプラクティスを中心にセッションを聞いてきました。 そのなかで2つのセッションの内容をご紹介いたします。
1つ目のセッションは、昨年のre:Invent 2024でプレビューが発表され、今年の5月下旬にGA(一般提供)を迎えたAmazon Aurora DSQLです。 今回のセッションは、そのアーキテクチャの核心部分を日本語で非常に分かりやすく解説してくださり、とても有意義な内容でした。 本記事では、その合理的な設計思想と技術的なポイントを整理してご紹介いたします。

AWS-43 Amazon Aurora DSQL アーキテクチャー詳細
Amazon Aurora DSQLとは何か?
Amazon Aurora DSQLは、Amazonが何十年にもわたる運用経験と革新的な技術を結集して開発した、新しいサーバーレスの分散型SQLデータベースです。 セッションでは、その主な特徴として以下の点が挙げられました。
- 優れた拡張性: 従来のモノリシックなデータベースが持つコンポーネント(クエリ処理、トランザクション管理、ストレージ等)を独立したマイクロサービス群に分割。これにより、各コンポーネントが個別に、かつ動的にスケールすることが可能になりました。
- サーバーレス: ユーザーはインスタンスの管理やバージョンアップを意識する必要がありません。提供されるエンドポイントに使い慣れたPostgreSQLクライアントで接続するだけで、すぐに利用を開始できます。
- アクティブ・アクティブ マルチリージョン構成: 複数のリージョンにまたがって、どこからでもデータの読み書きが可能です。これにより、極めて高い可用性を実現します。
- 強い一貫性: マルチリージョン構成でありながら、レプリケーションラグが存在しない完全同期を実現しています。どのリージョンで書き込んでも、即座にその結果が他のリージョンに反映される「強い一貫性」が大きな特徴です。
- PostgreSQL互換: 既存のアプリケーションやツール、スキルセットを活かして利用することができます。
これらの特徴は、AWSがこれまで培ってきたマルチリージョン/マルチAZ構成や同期/非同期処理といった豊富なナレッジやテクノロジーの上に成り立っています。
【用語解説】強い一貫性とは?(クリックすると展開されます)
分散システムにおけるデータの一貫性モデルの一つです。「結果整合性」と対比して理解すると分かりやすいです。
| 項目 | 強い一貫性 (Strong Consistency) | 結果整合性 (Eventual Consistency) |
|---|---|---|
| データの見え方 | データ書き込み完了後、どのノードから読んでも即座に最新のデータが返る。 | データ書き込み後、しばらくすると最新のデータが返るようになる(いずれは一致する)。 |
| 応答速度・可用性 | 全ノードの同期を待つため、レイテンシ(遅延)が大きくなる傾向がある。 ※DSQLではリージョン間通信を COMMIT時の一度に限定するアーキテクチャで影響を最小化している。 |
同期を待たずに応答を返すため、レイテンシが小さく、可用性が高い。 |
| 代表的なユースケース | 銀行の残高照会、在庫管理システム等、1円/1個のズレも許されないシステム。 | SNSの「いいね」数、DNS、Webページのキャッシュ等、多少の遅延が許容されるシステム。 |
アーキテクチャの全体像:トランザクショナルデータベースの再考
DSQLの核心は、その分散アーキテクチャにあります。データベースの機能は、それぞれ独立してスケールする複数のレイヤーに分割されています。

これらの各レイヤーが水平方向に独立して動的にスケールすることで、DSQLは事実上無制限のスケーラビリティを実現しています。
また、マルチリージョン構成では、2つのアクティブなリージョンとは別に「ウィットネス」として機能するリージョンを配置します(下の写真だと「リージョンB」が該当)。
このウィットネスはJournalのみを持ち、リージョン障害発生時にタイブレーカー(どちらが正しい状態かを判断する役割)として機能します。
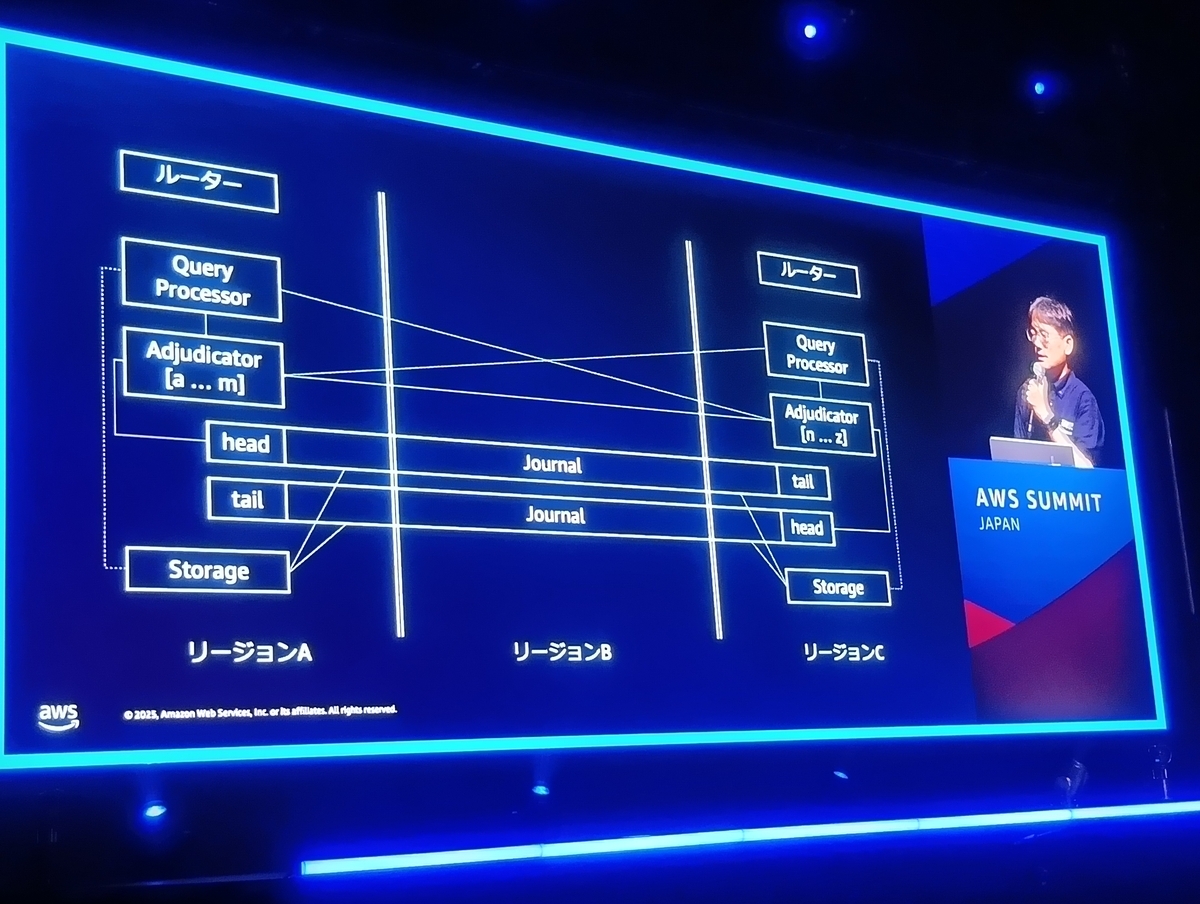
トランザクション処理の深掘り
データベースの信頼性の根幹をなすACID特性は、これらの分散コンポーネントが連携して実現されます。
【用語解説】ACID特性とは?(クリックすると展開されます)
データベースのトランザクション処理において、信頼性を担保するために求められる4つの性質をまとめたものです。
| 特性 | 名称 | 説明 |
|---|---|---|
| A | Atomicity (原子性) |
トランザクション内の処理が「すべて実行される」か「まったく実行されない」かのどちらかになることを保証します。 |
| C | Consistency (一貫性) |
トランザクションの前後で、データベースの状態が予め定められた制約(整合性)を満たし続けることを保証します。 |
| I | Isolation (分離性) |
複数のトランザクションを同時に実行しても、それぞれが独立して実行されているかのように振る舞うことを保証します。 |
| D | Durability (永続性) |
一度完了(コミット)したトランザクションの結果は、システム障害が発生しても失われないことを保証します。 |
DSQLは、Auroraの思想である「The log is the database(ログこそがデータベース)」を踏襲しています。
DSQLではログはJournalが担いますが、書き込み、読み込み処理においては、Journalの前後のレイヤーが重要な役割を果たします。
書き込み(INSERT/UPDATE)とスケーラビリティ
INSERTのような書き込み処理では、まずAdjudicatorがトランザクション間に矛盾がないかを確認します。
問題がなければJournalにログが書き込まれ、この時点でコミットが完了し、クライアントにACK(確認応答)が返されます。
データの永続性(Durability)はJournalが担保しており、Storageはあくまで読み取りの最適化のために存在するという設計が特徴的です。
もしAdjudicatorやStorageに負荷が集中し、ボトルネック(律速)が検知されると、DSQLは自動的にコンポーネントをスプリット(分割)してスケールします。
これにより、書き込みスループットが低下することなく、処理を継続できます。
読み込み(SELECT)とプッシュダウン
SELECTのような読み取り処理では、Query Processorから直接Storageにアクセスします。
この際、DSQLはプッシュダウンという最適化を行います。
これは、Storage層で実行可能な処理(スキャン、集計、射影等)をオフロードすることで、Query Processorとの間でやり取りされるデータ量を削減し、
ネットワーク帯域の消費を抑え、パフォーマンスを向上させる仕組みです。
分離レベルと同時実行制御の工夫
DSQLは、分散環境におけるトランザクションの分離性(Isolation)を、グローバルに同期された高精度な時計(Amazon Time Sync Service)を使って実現しています。
トランザクション開始時にタイムスタンプτを取得し、Storage層はその時刻τに合致したバージョンのデータを返すことで、
MVCC(Multi-Version Concurrency Control)を実現しています。
楽観的同時実行制御(OCC)
DSQLはコミット時の競合判定に 楽観的同時実行制御 (OCC:Optimistic Concurrency Control) を採用しています。
【用語解説】楽観的同時実行制御 (OCC) とは?(クリックすると展開されます)
トランザクションの同時実行を制御する方式の一つです。処理開始時にロックを取得する「悲観的同時実行制御」と対比されます。
| 項目 | 楽観的同時実行制御 (Optimistic) | 悲観的同時実行制御 (Pessimistic) |
|---|---|---|
| 考え方 | 「競合は滅多に発生しない」という前提。 | 「競合は頻繁に発生しうる」という前提。 |
| ロックのタイミング | 処理中はロックせず、コミット時に競合を検証する。 | データを読み取る処理開始時にロックをかける。 |
| 競合発生時の挙動 | コミット時の検証で競合が発覚したら、トランザクションをロールバック(失敗)させる。 | 他のトランザクションはロックが解放されるまで待機する。 |
| メリット | ロック待機が発生しないため、競合が少ない環境ではスループットが高い。 | データの一貫性を確実に保証しやすく、アプリケーションの作りがシンプルになる。 |
| デメリット | 競合が多いとロールバックが多発し、かえって効率が悪い。 アプリケーション側で、ロールバックを想定したリトライ処理等のエラーハンドリングが必須。 |
ロック待ちによる性能劣化(スループット低下)が起きやすい。 |
このOCCの採用により、INSERTやUPDATEの処理はまずローカルのQuery Processor内でスプール(一時保持)され、COMMITが実行されたタイミングで初めてAdjudicatorとの調整が行われます。
COMMIT時のみにリージョン間調整を行い、ロック待ちをなくすことで、分散環境でのスループットを最大化することが可能となります。
分離レベル: Strong Snapshot Isolation (REPEATABLE READ)
DSQLがサポートするトランザクション分離レベルは Strong Snapshot Isolation のみとなり、これはPostgreSQLの REPEATABLE READ と同一とのことです。
【用語解説】REPEATABLE READ とは?(クリックすると展開されます)
SQLで定められたトランザクションの分離レベル(Isolation Level)の一つです。 特にPostgreSQLやDSQLのようなMVCCに基づくデータベースでは、トランザクション開始時点のデータのスナップショットを読み続ける挙動となります。
| 項目 | REPEATABLE READ (Snapshot Isolation実装) | READ COMMITTED |
|---|---|---|
| 保証されること | トランザクション開始時点のデータ状態(スナップショット)を、トランザクション終了まで読み続ける。 | クエリを実行するたびに、その時点でコミットされている最新のデータを読み取る。 |
| ノンリピータブルリード (再読込で値が変わる) |
発生しない。 常に同じスナップショットを見るため、値は変わらない。 |
発生する。 読み込むたびに最新データを取得するため、値が変わりうる。 |
| ファントムリード (再読込で行が増減する) |
発生しない。 スナップショットに行が追加/削除されることはない。 |
発生する。 他のトランザクションが挿入した行が見えてしまうことがある。 |
| 特徴 | トランザクションを通して一貫したデータを読み取れるため、安全性が高い。 | 常に最新のデータを扱える柔軟性があるが、トランザクション内での一貫性は低い。 |
注意点として、DSQLは現在 READ COMMITTED をサポートしていません *2 。そのため、既存のアプリケーションが READ COMMITTED の挙動を前提として作られている場合、DSQLへ移行する際にはトランザクション制御の考慮が必要です。
マルチリージョンにおける遅延と障害への最適化
分散データベース、特にマルチリージョン構成では物理的な距離によるネットワーク遅延 *3 が最大の課題となります。 DSQLは、この課題に対して非常に合理的なアプローチを取っています。
ラウンドトリップの最適化
DSQLの最大のポイントは、リージョン間の通信(調整)をCOMMITのタイミングに限定している点です。
BEGINからSELECT, INSERT, UPDATEといった一連の処理は、すべてリクエストを受け付けたローカルリージョン内で完結します。
そして、トランザクションを確定させるCOMMITの時だけ、一度だけリージョン間の調整(ラウンドトリップ)が発生します。
これにより、マルチリージョン構成による性能オーバーヘッドを最小限に抑えています。
読み取り専用のトランザクションであれば、このリージョン間の調整は全く発生しません。
高速フェイルオーバーの実現
DSQLはアクティブ・アクティブで動作するため、原理的にアプリケーションレベルでのフェイルオーバー作業が不要です。 あるリージョンに障害が発生しても、他のリージョンが稼働し続けているため、サービスは中断されません。 開発者や運用者が必要な作業は、アプリケーションの接続先エンドポイントを正常なリージョンのものに切り替えるだけです *4 。
まとめ
本セッションで解説されたAmazon Aurora DSQLのアーキテクチャは、データベースが直面してきたスケーラビリティ、可用性、地理的分散といった課題に対し、 クラウドネイティブなアプローチで正面から向き合った、非常に洗練されたものでした。

感想
初代のAmazon Auroraが発表された当時もクラウドならではの革新的なアーキテクチャに感動しましたが、今回のAmazon Aurora DSQLもそれに近い感銘を受けました。 OCCへの対応等アプリケーション側で考慮すべき点はありますが、それを補って余りあるスケーラビリティとマルチリージョンでの強い一貫性は非常に魅力的です。 ミッションクリティカルなシステムにおけるデータベースの有力な選択肢として、今後もキャッチアップを進めていきたいと思います。
※後編へ続きます。
*1:AWS Summit Japan のイベント登録を行うことで、7月11日まで動画の視聴が可能です。
*2:DSQLのアーキテクチャでは READ COMMITTED と REPEATABLE READ のどちらを選択しても性能的なメリットに差がないため、トランザクション内でのデータ矛盾といった異常をより検知しやすく安全性の高い REPEATABLE READ を採用する方が、開発者体験として優れているだろうとの判断から。
*3:データが光ファイバー内を1ミリ秒に進める距離は約200km(物理限界)。東京→大阪の片道で3~4ミリ秒「も」かかります。
*4:内部的には Adjudicator 等一部コンポーネントのフェイルオーバーが発生しますが、これはユーザーから完全に透過的に行われ、性能や可用性、データ損失に影響を与えることはないとのこと。
椿山 俊和 (記事一覧)
エンタープライズクラウド本部 クラウドリライアビリティ1課
2025年5月に40代後半で中途入社。AWS認定資格全冠。好きなAWSサービスはLambdaとCloudFormation。好きな飲み物はコーヒーとプレモルです。