

概要
この記事では 「AWS Configの高度なクエリ機能を用いて、AWS Lambdaをランタイムごとにクエリする方法」とその応用について紹介します。
【本記事でわかること】
・AWS Config 高度なクエリの使い方 ・高度なクエリを利用した特定のLambdaランタイムの検索方法 ・高度なクエリでLambda関数タグのクエリ方法
はじめに
こんにちは!カスタマーサクセス部 CS1課の圡井です! この冬余った鍋つゆはお肉に漬け込んで下味にするのがオススメです!
さて、皆様はAWS Lambda活用していますか? Lambdaは他サービスと組み合わせることで、
- APIGatewayと連携したWeb API
- Secrets Managerのキーローテーション
- Stepfunctionsによるデータ変換パイプライン構築
など、様々な役割を担うことができます。
さらにLambdaの実行には事前にインフラストラクチャを待機させておく必要はありません。
そんなLambdaですが、定期的にメンテナンスが必要な要素があります。 それが LambdaランタイムのEOL(End Of Life) です。
Lambdaを活用していくうちに、どんどんLambda関数の数が増え、開発者のメイン言語や構築時期によって様々なランタイムで作成され、管理が複雑になっていきます。
そこで、本記事では、AWSアカウント上に構築されたLambda関数からEOLが近い(またはEOLを迎えた)ランタイムを使用しているものをAWS Configを使って検索する方法について記載します。 また、実際に使ってみてつまづいた"タグ"の取り扱いについて記載します。
Lambdaランタイム EOLとは
まずは、Lambdaランタイム EOLとは何か、その確認, 変更方法について簡単におさえていきましょう。
ランタイム EOLとは
Lambda関数で利用可能な言語の各バージョン(ランタイム)はAWSによってメンテナンスされています。 ランタイムでセキュリティ問題が発見されると、各環境をスキャンし自動的にセキュリティパッチが適用されます。 それらランタイムがEOLとなることで、パッチ更新が行われなくなり、脆弱性を利用した攻撃のリスクが高まります。 利用者はランタイムを更新することで、脆弱性のチェック、パッチ適用が行われる環境下でコードを実行できます。
EOLスケジュールの確認
LambdaランタイムのEOLは以下のページで確認できます。
※英語ページが最新かつ正とされるため、英語ページを添付しています。
そこには3つの日付が記載されています。これらはそれぞれ、
- Deprecation date:ランタイムの廃止作業が開始される日付
- Block function create:該当ランタイムで新たにLambda関数が構築できなくなる日付
- Block function update:該当ランタイムで作成されているLambda関数の 更新ができなくなる 日付
を示しています。
Lambdaランタイムの変更方法
上記EOLスケジュールの「1.」「2.」では、Lambdaの設定上で更新が可能です。

ですが、「3.」に到達してしまうと「新たなランタイムLambda関数を作成し、入れ替える」という作業が必要となり、変更リスクが高まります。
また、注意点として、各ランタイムのメジャーバージョンには下位互換性は保証されないため、変更する前に動作確認する必要があります。
高度なクエリでLambda関数を探す
ここからが本題となる高度なクエリの利用方法です。 AWS Configコンソールの左ペインより「高度なクエリ」を選択することでクエリ一覧画面が開きます。 ここでAWS公式のテンプレートとして「Lambda Function using nodejs6」があるので選択します。
「クエリエディタ」が開くので、画面下部のエディタにSQLライクな形式で記述します。
テンプレートの内容
SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = 'nodejs6.10'
この公式テンプレートはNode.js 6.10ランタイムを利用しているLambda関数から、
「リソース名」「リソースタイプ」「ランタイム名」「最終更新日」「Lambda関数の説明」の値を取得しています。
高度なクエリで利用できるパラメータは以下のGitHubリポジトリにまとめられています。
特定のランタイムを持つLambda関数を探すのみであれば以上のクエリを実行するのみです。 さらに出力欄の右上の「名前をつけてエクスポート」ボタンからJSONまたはCSV出力を行うことができるので、 一覧として手元で管理することもできます。
以下に、Node.js 22.xを利用したLamdba関数を作成し、クエリをしてみます。

クエリ文:
SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = 'nodejs22.x'

高度なクエリで"タグ"を扱う(発展)
ここからは発展的な使い方を紹介します。
利用方法によってはタグを利用してアプリケーション名や担当者を管理している場合があります。
- サービスA用Lambda:{"Service": "HogeSystem", "Manager": "Yamada Taro"}
- サービスB用Lambda:{"Service": "FugaPlatform", "Manager": "John Smith"}
このLambdaを誰が作成したのか、何に使われているのか、誰が更新する必要があるのかを確かめておくことで、 効率よくランタイム更新ができます。
ここから先は、「"タグ"のクエリ方法」と「クエリの際に困ったポイント」について記載します。
クエリの出力にタグ値を取り出すだけであれば、"tags"をSELECT句の項目に追加するのみです。
先ほどの例でタグを出力してみましょう。
SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description, tags WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = 'nodejs22.x'


上記のように"tags"と書かれたカラムが追加されます。
ここでの困ったポイントとして、出力されるタグは1つのセルの中にJSON形式で記載されてしまうことです。 一覧として管理するには少し使いずらいです。
各種タグの値をクエリから取り出して1つのカラムとしたいところですが、Configのクエリエディタでは項目内クエリやAS句がサポートされていません。
そのため、試してみて良かった2つの方法を共有します。
方法1: CLIやBoto3を利用してJSONを処理する
1つ目はCLIやBoto3でクエリし、結果を加工する方法です。
推しポイントとしては、スクリプトを利用することでクエリエディタではフォローできない後処理ができる点です。 ですが、スクリプトを作成する必要があるため、コーディングの経験が必要である点がデメリットと言えます。
スクリプトを利用することで、以下のように結果を取得できます。
resourceId, resourceType, lastModified, description, service, test_tag1,test tag2 config_query_test,AWS::Lambda::Function,2025-04-06T06:18:59.892+0000, , key rotation,test1, test2
作成したPython+Boto3のスクリプトをAIの清書してもらった例を示します。
【スクリプト使用時の注意点】 Pandasライブラリを使用しているので、必要に応じてライブラリのインストールや読み替えを行ってください。
# インストールコマンド pip install pandas
定数定義の部分は適宜、利用するconfig-aggregatorやAWS CLIをご自身の環境のものに置き換えて下さい。
import boto3 import pandas as pd import json # 定数定義 AGGREGATOR_NAME = 'config-aggregator' RUNTIME_FILTER = 'nodejs22.x' CSV_OUTPUT_PATH = f"lambda_{RUNTIME_FILTER.replace('.', '')}.csv" PROFILE_NAME = "default" TAGS = ['service', 'test_tag1', 'test tag2'] def build_query(runtime: str) -> str: return f""" SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description, tags WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = '{runtime}' """ def execute_config_query(client, aggregator_name: str, query: str): response = client.select_aggregate_resource_config( ConfigurationAggregatorName=aggregator_name, Expression=query, Limit=100 ) return [json.loads(result) for result in response.get('Results', [])] def extract_tag_values(tags: list, keys: list) -> dict: tag_dict = {tag['key']: tag['value'] for tag in tags} return {key: tag_dict.get(key, '') for key in keys} def format_results(results: list) -> pd.DataFrame: formatted_rows = [] for item in results: tags = extract_tag_values(item.get('tags', []), TAGS) config = item.get("configuration", {}) formatted_rows.append({ 'lastModified': config.get('lastModified'), 'description': config.get('description'), **tags }) return pd.DataFrame(formatted_rows) def main(): # プロファイルを指定 session = boto3.Session(profile_name=PROFILE_NAME, region_name="ap-northeast-1") # クライアント作成 client = session.client('config') # クエリ作成・実行 query = build_query(RUNTIME_FILTER) results = execute_config_query(client, AGGREGATOR_NAME, query) if not results: print("No Lambda functions found.") return # 展開・整形 tag_df = format_results(results) meta_df = pd.DataFrame(results).drop(columns=["tags", "configuration"], errors="ignore") final_df = pd.concat([meta_df, tag_df], axis=1) # CSV 出力 final_df.to_csv(CSV_OUTPUT_PATH, index=False) print(f"出力完了: {CSV_OUTPUT_PATH}") if __name__ == "__main__": main()
方法2: 詳細情報からクエリする
2つ目はAWS Configが保持しているパラメータからクエリする方法です。
この方法は課内でクエリについて議論していた際に、教えていただいた方法です。
(ありがとうございます!)
Config画面より、各リソースについて確認してみると、「設定項目の表示」というプルダウンが見つかります。
そこではConfigで収集されているリソース情報がJSON形式で一覧できます。
この中のsupplementaryConfigurationという項目の中にタグ情報が格納されています。
このパラメータをクエリから取得していきます。
SELECT句の中にsupplementaryConfiguration.Tags.<タグのキー値>を入力することでクエリ結果に入れることができます。
SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description, supplementaryConfiguration.Tags.service WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = 'nodejs22.x'
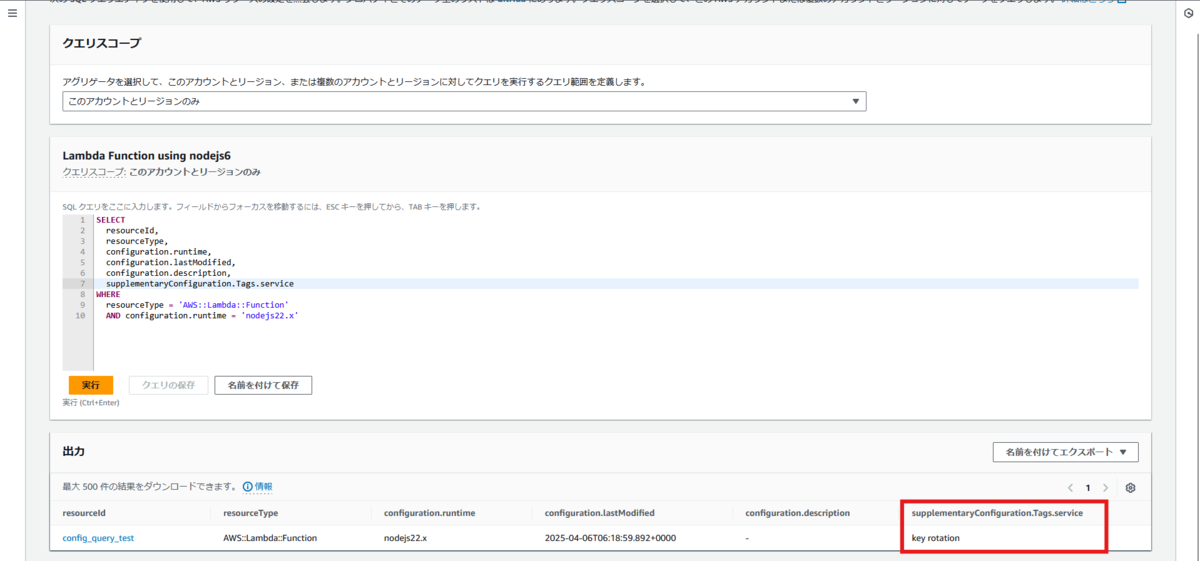
この方法の推しポイントはクエリエディタの中で操作が完結する点です。 さらに"方法1"と同様に取得したいキーのみ載せることができます。
唯一のデメリットとして「キー名に空白を含められない」ということに注意してください。
今回の例ではservice, test_tag1, test tag2の3つのタグがありますが、
このうち空白を含むtest tag2はクエリすることができませんでした。
""や''を利用してどうにか認識させようとしましたが、クエリ文でエラーが発生します。
それを考慮してタグ設計をすることをオススメします。
エラーが発生するクエリ文の例:
SELECT resourceId, resourceType, configuration.runtime, configuration.lastModified, configuration.description, supplementaryConfiguration.Tags.service, --〇できる supplementaryConfiguration.Tags.test_tag1, --〇できる supplementaryConfiguration.Tags."test tag2" --✕どうにもできない WHERE resourceType = 'AWS::Lambda::Function' AND configuration.runtime = 'nodejs22.x'
まとめ
AWS Configの高度なクエリ機能を用いて、AWS Lambdaをランタイムごとにクエリする方法について記載しました。Configの持つパラメータを確認しておけば、簡単に一覧を作成できるのが良いですね。 また、Configは複数アカウント・リージョンの情報を集約できるため、その時にもより真価を発揮しそうですね!
最後まで見ていただきありがとうございました!
圡井一磨(執筆記事の一覧)
23年度新卒入社しました。最近は自炊にはまっています。アパートのキッチンが狭くて困ってます。