

サウナの水風呂はちょっと高めで長めに浸かりたい派の小菅です。
AWSリソースにおいては、「各種ログをS3に出力する」という機能が結構あり設定されている方も多いと思います。 その各種ログをAthenaで分析したい!そのためにテーブル化される方も多いと思います。 その中には「ログが大量にあるのでParquet形式にしたいけど、ETL処理を考えて組むのはちょっとめんどうだよなぁ~」と思ってる人もいると思います。
その人向けのブログとなります。
本ブログでは、S3に出力されるようなログ達をGlue Visual ETLとGlue Workflowsを利用して列指向フォーマットであるParquet形式に変換するまでを解説させていただきますので、ETL処理の方法の一つとして参考にいただければ幸いです。
尚、コストについては以下を参照ください。
概要
このブログでは、AWS Network Firewallログを例にして実践していきます。 また、AWS Network Firewallログはログ記録が既に有効化されていてS3へ出力されていることが前提となります。 尚、配信されるログファイルはJSON形式です。
ETLに関して図にすると以下のようなイメージとなります。

Glue Visual ETLは名前の通り、視覚化されたコンソールから設定を行います。 後述しますが、パーティション設計まで実装するため、「Source」と「Target」の間に「Transform」を入れることで、SQLで新たにパーティションとなるカラムと値を抽出します。
では実装していきます。
Glue Visual ETLジョブの作成
AWS Glueコンソールに移動し、ナビゲーションペインより「ETL jobs」 > 「Visual ETL」を選択します。

1. Glueジョブ作成
まずはジョブに名前を付けます。今回はnetwork_firewall_log_etl_jobと命名しました。

「job details」タブで、適切なIAMロールを選択します。 以下権限が付与されているIAMロールであればOKです。
- Glueサービスの実行権限
- ソースS3バケットからの読み取り権限
- ターゲットS3バケットへの書き込み権限
- CloudWatch Logsへの書き込み権限
Glueバージョンは最新でOKです。

重要な設定になりますが、Job bookmarkを「Enable」に変更してください。 Job bookmarkは、Glueが以前の実行で処理したファイルを追跡し、次回の実行では新しいファイルのみを処理するようにします。 これは、同じログファイルを繰り返し処理することを防ぐために不可欠な設定となります 。

2. ビジュアルエディタでETL処理作成
「Visual」タブに戻ります。 ビジュアルエディタの「Sources」メニューから「Amazon S3」を選択し、キャンバスに追加します。

ノードを選択し、「データソースのプロパティ - S3」タブで以下を設定します。

設定箇所は以下の通り。
- S3 URL: Network Firewallのログ(JSON形式、.log.gz)が保存されているS3パスを指定します。サブフォルダも再帰的に含めるように設定します。
- Data format: JSON
- 「Infer schema」をクリック。スキーマ推測によりもし不正確の場合は、手動でスキーマを定義することも検討する。
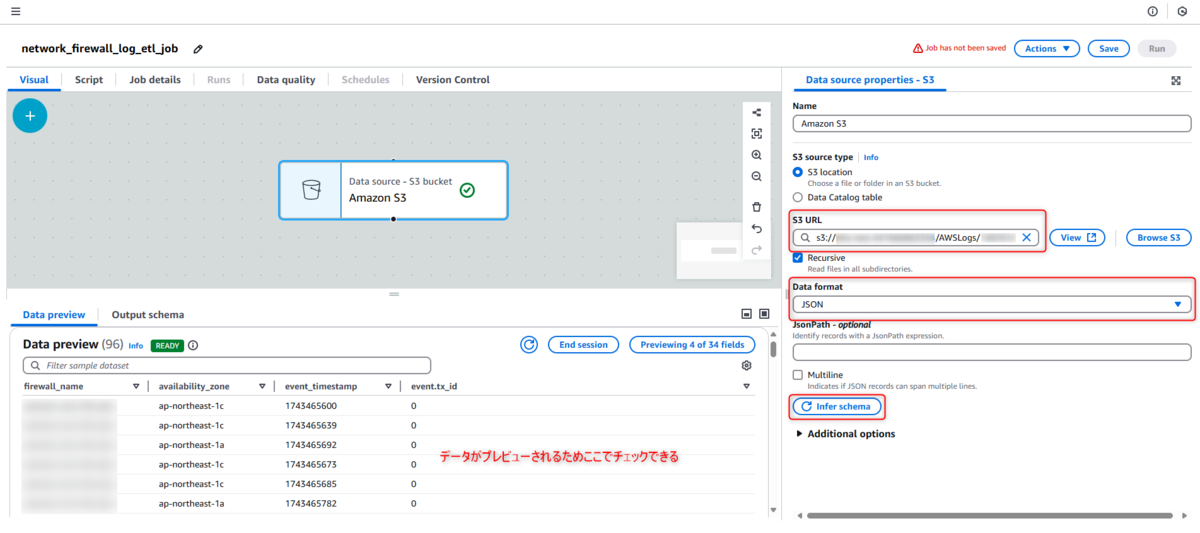
Sources設定2
エポックタイムスタンプからパーティションキーを抽出するため「SQL Query」変換ノードを追加します。 「SQL query」で実行したいSQL文を記述します。

今回使用したSQL文は以下の通りで、元のデータに「year」「month」「day」というカラムを追加した形になります。
select
*,
CAST(YEAR(FROM_UNIXTIME(CAST(event_timestamp AS BIGINT))) AS STRING) AS year,
LPAD(CAST(MONTH(FROM_UNIXTIME(CAST(event_timestamp AS BIGINT))) AS STRING), 2, '0') AS month,
LPAD(CAST(DAY(FROM_UNIXTIME(CAST(event_timestamp AS BIGINT))) AS STRING), 2, '0') AS day
from myDataSource
出力されるデータのスキーマをここで最終確認してください。
もし型変更等あればこの変換ノード内で対応可能です。

「Targets」メニューから「Amazon S3」を選択し、キャンバスに追加します。前の変換ノードの後に接続します 。 ノードを選択し、「データソースのプロパティ - S3」タブで以下を設定します。 設定箇所は以下の通り。
- Format: Parquet
- Compression Type: Snappy
- S3 Target Location: 出力データを保存するS3パスを指定します。

Targets設定1
重要な設定について説明します。
オプション設定でパーティションキーを設定します。今回は作成した新しい列year、month、day を追加します。
この設定により、GlueはデータをHiveスタイルのディレクトリ構造(例: s3://.../year=2025/month=04/day=11/file.parquet.snappy)で書き込みます。
この構造は、Glue CrawlerとAthenaがパーティションとして自動的に認識するために不可欠です 。
「Check data quality」については、テーブル定義とパーティション管理をGlue Crawlerで行う場合はチェックを外します。

設定に問題なければ「Save」を選択し保存します。
Glue Workflowsの作成
Glue ETLジョブをオーケストレーションするためのワークフローを作成します。
3. ワークフロー作成
AWS Glueコンソールで、「Workflows (orchestration)」に移動し、「Add workflow」をクリックします。

まずはワークフローに名前を付けます。今回はnetwork_firewall_log_etl_workflowと命名しました。

作成したワークフローに遷移します。

4. トリガーノード/ジョブノード追加
やることは2つです。トリガーの追加と前項で作成したETLジョブの追加です。
ワークフローのグラフビューで、「Add trigger」をクリックします。

トリガーに名前を付けます。今回はnetwork_firewall_log_etl_triggerと命名しました。
トリガータイプとしてイベントトリガー or スケジュール起動を決めることができます。
今回は「Daily」を選択しましたが、「Custom」を選択するとcron式で記述することもできます。
イベントトリガーの場合は、EventBridgeとソースS3バケット側の設定が必要になります。

トリガーが作成したらグラフビューで、作成したトリガーノードを選択します。
「Action」をクリックし、「Add jobs/crawlers to trigger」を選択します。

前項で作成したETLジョブの選択し、「追加」をクリックします。

トリガーノードとジョブノードが接続されていればOK。

動作確認
実行結果はHistoryから確認できます。

変換されたデータも生成されていることがわかります。

感想
AWSリソースでしばし設定できるログのS3への出力ですが、出力形式によってはデータ量が多い場合、Athenaによるスキャンの時間とお金が気になります(特に私は)。 例えばそんな頻繁に分析することの無いログだったとしても、いざというときには分析しやすい状況がいいに決まっています。 しかしそんな頻繁に利用しないログをParquet形式にして保持するとなると、二重でデータを持つことになるため、実現したいこととコストのバランスを加味して検討いただくのがいいかなと思います。
このブログで紹介した方法については、コードの類はSQLのみとなるため可読性に優れています。またプラットフォーム側のメンテナンスの考慮も不要なので管理するものを減らしたい場合に有効です。 どうしてもParquet形式じゃないと、って方は是非お試しください。
小菅 信幸(執筆記事の一覧)
仙台在住/サウナをこよなく愛するエンジニア
2024 Japan AWS All Certifications Engineers