

マネージドサービス部 佐竹です。
本ブログでは、2025年10月20日(月)より発生しておりました AWS us-east-1 リージョンの障害に関連し、仮説を含めた技術的な考察を行いたいと思います。
- はじめに:本ブログの立ち位置
- 2025年10月 us-east-1 障害の概要
- STS グローバルエンドポイントの透過的リージョン分離についての参考情報
- 仮説検証:もし STS リージョン分離が完了していなかったら?
- STS リージョン分離と障害に関する今回の学び
- 2025年10月24日 追記
- まとめ
はじめに:本ブログの立ち位置
本ブログの目的は、障害の詳細を解説したり、その影響を扇動的に取り上げたりすることではございません。今回の障害から得られる「学び」に焦点を当てています。
具体的には、「もし、2025年4月に完了していた『AWS STS のリージョン分離』が事前に実施されていなかったら、今回の障害は us-east-1 に留まらず、全世界のリージョンに波及する大惨事になっていたのではないか?」という技術的な仮説を検証・考察することです。
あくまで発生した事実と公開情報(AWS re:Inforce 2025 のセッション内容など)に基づいた技術にフォーカスした仮説検証であり、障害を煽る意図は一切ないことを最初にお断りしておきます。
2025年10月 us-east-1 障害の概要
詳細は AWS の公式報告に譲りますが、今回の障害は以下のような連鎖によって引き起こされたと報告されています。
10 ステップで理解する障害の概要
以下は「health/status」に記載のあった英文を日本語へと翻訳し、要約したまとめです。
- 2025年10月20日 15:49 (JST) より、us-east-1 リージョンでエラー率とレイテンシーが増加
- 初期原因は DynamoDB のエンドポイントにおける DNS 解決問題と特定された (10/20 18:24 JSTに解決)
- DNS 解決後、DynamoDB に依存する EC2 内部サブシステムで障害が発生し、インスタンス起動に失敗
- 続けて、ネットワークロードバランサー (NLB) のヘルスチェック障害が発生し、Lambda や CloudWatch 等で接続性問題が拡大
- IAM や DynamoDB グローバルテーブルなど、us-east-1 に依存するグローバル機能にも影響が及んだ
- AWS は復旧のため、EC2 起動や SQS キュー処理、Lambda 呼び出しなど一部操作を一時的にスロットリング(制限)
- ネットワークロードバランサー (NLB) のヘルスチェックは10月21日 01:38 (JST) に回復
- スロットリングの段階的解除と復旧作業を進め、10月21日 07:01 (JST) までに全サービスが正常運用に復帰
- 復旧時点で、AWS Config、Redshift、Connectなど一部サービスはバックログ処理を継続
- 詳細は別途、AWS によるイベント後サマリーが提供される予定となっている
この障害は us-east-1 リージョン、および同リージョンに依存する一部のグローバル機能に大きな影響を与えました。
ただし注目すべきは、東京リージョンや大阪リージョンなど、他の多くのリージョンで稼働するワークロードは、本障害の直接的な影響を受けず、大きな実害もなく稼働を継続できていたという点です。
これはこの後詳しく記載していきます、AWS の「リージョン分離」の設計原則が機能した成果と言えるかも知れません。
もし AWS が「見えない改善」を2025年4月までに行っていなかったら、一体今回の障害の影響はどれほどになっていたでしょうか…?ということを本ブログでは考えてみます。
STS グローバルエンドポイントの透過的リージョン分離についての参考情報
本考察で重要になるのが、AWS が2025年の春に完了させたと報告している「AWS Security Token Service (STS)」の改善プロジェクトです。
この詳細は、私が以前レポートした「AWS re:Inforce 2025」のセッション SEC202 でも詳しく解説されていました。
- 【AWS re:Inforce 2025】AWSの「回復性への執念」は、逆境への備えをどう支えるか (SEC202)
- AWS STS グローバルエンドポイントがデフォルトで有効になっているリージョンでのリクエストのローカル処理を開始
以下は上記 Whats New からの引用です。
AWS Security Token Service (AWS STS) では、お客様がワークロードをデプロイしている AWS リージョンで、グローバルエンドポイント (sts.amazonaws.com) へのリクエストがすべて自動的に処理されるようになりました。これにより、回復力とパフォーマンスが向上しました。これまでは、STS グローバルエンドポイントへのリクエストは、すべて米国東部 (バージニア北部) リージョンで処理されていました。
この機能拡張により、リクエストがワークロードと同じリージョンで処理されるため、アプリケーションのレイテンシーの低減と障害分離を実現できます。例えば、アプリケーションを米国西部 (オレゴン) で実行していて STS グローバルエンドポイントを呼び出す場合、リクエストは米国東部 (バージニア北部) にルーティングされるのではなく、米国西部 (オレゴン) でローカルに処理されます。
このアップデートは、デフォルトで有効になっているすべての AWS リージョンで利用できます。この強化された機能を利用するためにお客様に必要な手続きはありません。デフォルトで有効になっていないリージョン (オプトインリージョンなど) から STS グローバルエンドポイントへのリクエストは、引き続き米国東部 (バージニア北部) で処理されます。
これらの情報を元にしながら、以下引き続き解説を続けます。
前提:「STS」とは何か?
STS(AWS Security Token Service) は、AWS の中核的な認証サービスです。特に「IAM ロールを引き受ける(AssumeRole)」ために一時的な認証情報を発行する役割を担います。
例えば、EC2 インスタンスが S3 バケットにアクセスしたり、Lambda 関数が DynamoDB を読み書きしたりする際、この STS による認証情報の取得が行われます。
STS は、AWS サービス間連携の時に、裏で認証が常に動くために必要なサービスであり、これが無いことにはサービス間連携が成り立たないという非常に重要なサービスです。
過去の課題:STS の us-east-1 への潜在的依存状態
歴史的に、STS は us-east-1 の単一グローバルエンドポイント(sts.amazonaws.com)で開始されました。その後、リージョナルエンドポイント(例:sts.ap-northeast-1.amazonaws.com)が提供されましたが、互換性維持のため、多くの顧客(および AWS の古い SDK 等)は依然としてグローバルエンドポイントを呼び出し続けていました。
先のブログから自分の記載した文章を引用するのですが、以下の通りだったのです。
2015年にはリージョナルエンドポイントが利用可能になりましたが、10年近く経ってもなお、多くの顧客が従来のグローバルエンドポイント (
sts.amazonaws.com) を利用し続けている実態がありました。
これは実質的に、全世界からの認証リクエストの多くが us-east-1 に依存している、という潜在的なリスクを抱えていたことを意味します。
AWS が行った STS における「見えない改善」
ここで AWS は、顧客に一切のアクション(SDK の更新や設定変更)を求めることなく、この問題を解決するアプローチを取ることにしました。
2025年4月18日までに、VPC 内からグローバルエンドポイント(sts.amazonaws.com)へのリクエストを、AWS 側で透過的に(自動で)最も近いリージョンのエンドポイント(レプリカ)へリダイレクトするように変更したのです。
具体的な方法は、デフォルトで有効な17のリージョン全てに「グローバルエンドポイントの完全なレプリカ」を構築し、VPC 内の Route 53 DNS Resolver からのリクエストを透過的に最も近いリージョンのエンドポイントへリダイレクトするというものでした。
この結果、例えば東京リージョンの VPC から sts.amazonaws.com を呼び出しても、リクエストは us-east-1 まで飛ぶことがなく、東京リージョン内で処理が完結するようになりました。
本画像のグラフで2025年の3月中旬から4月にかけて、クロスリージョンコールの割合が約100%から0%近くまでに低下したことがわかります。
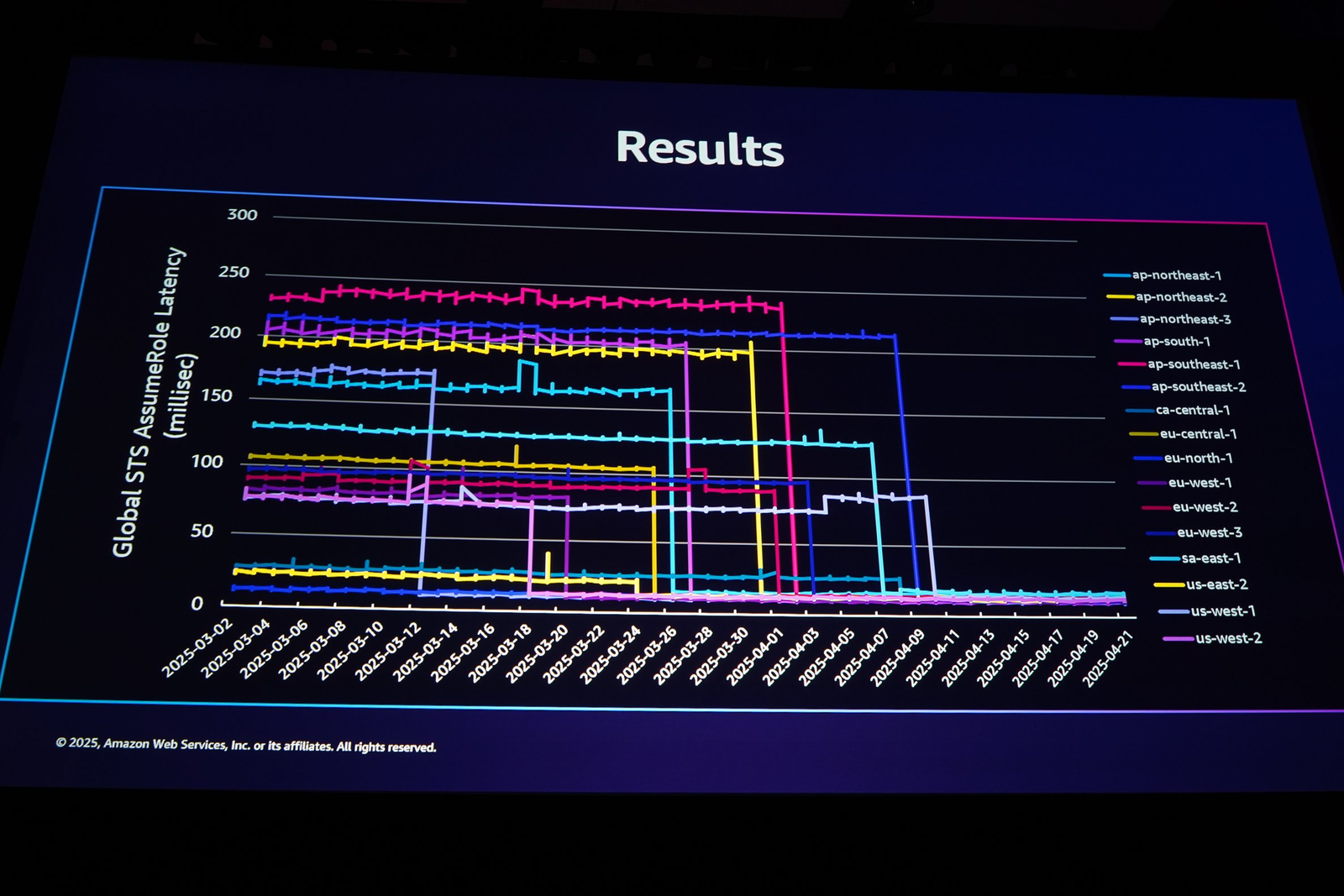
これらの引用も、先の私の記載したブログからです。
参考情報
- AWS Security Token Service エンドポイントとクォータ
仮説検証:もし STS リージョン分離が完了していなかったら?
ここからが本題です。
もし、この STS の透過的リージョン分離が完了していない、わずか半年前のアーキテクチャのまま、今回の2025年10月の障害が発生していたらどうなっていたでしょうか。
「かなり悲惨なことになっていたのでは?」と私は考えます。具体的な想定シナリオを以下に記載します。
シナリオ1:グローバル認証基盤の停止
今回の障害の引き金は、us-east-1 の「DNS 解決問題」と「DynamoDB 障害」でした。
もし STS のグローバルエンドポイントがまだ us-east-1 に強く依存していた場合、この障害の影響をまともに受けたことでしょう。sts.amazonaws.com が全世界的に機能不全に陥っていた可能性は極めて高いと考えられます。
シナリオ2:全世界への障害連鎖
sts.amazonaws.com が応答を停止した場合、またリクエストが集中した結果として「輻輳してしまった」場合、一体何が起こるでしょうか。
us-east-1 以外の全リージョン(東京、大阪、フランクフルト、シドニー等)で稼働しているほとんどの EC2 インスタンス、Lambda 関数、EKS/ECS のコンテナ等が、IAM ロールを引き受ける(AssumeRole)ために STS を呼び出した瞬間、そのリクエストは一斉にタイムアウトするか、エラーを返した可能性があるでしょう。
もちろん、明示的に STS でリージョナルのエンドポイントを指定している場合には、指定されたリージョンのエンドポイントが動くため、この被害を回避できました。
しかし、先にも引用した通り、多くの顧客が従来のグローバルエンドポイント (sts.amazonaws.com) を利用し続けている実態がありました。
シナリオ3:壊滅的な影響
一時的な認証情報を取得できなければ、ワークロードは他の AWS サービス(S3、DynamoDB、SQSなど)へとアクセスできません。連携が取れなくなります。
つまり、us-east-1 で発生した障害が引き金となり、全世界の AWS 上で稼働するほぼ全てのワークロードが連鎖的に停止するという、壊滅的なシナリオに発展していた可能性が否定できません。
STS リージョン分離と障害に関する今回の学び
これらの事実と情報からもわかる通り、2025年4月18日までに完了していた「STS のリージョンの分離 (Regions must be isolated)」が、本障害の影響を us-east-1 に留めてくれた可能性があることが示唆されます*1。
2025年10月24日 追記
AWS より、今回の障害レポートが「Summary of the Amazon DynamoDB Service Disruption in Northern Virginia (US-EAST-1) Region」として提供されています。
Redshift に関する不具合について
このレポートで「Redshift」に潜在していました、不具合が1つ明らかになっています。該当箇所を引用します。
In addition to cluster availability impairment, between October 19 at 11:47 PM and October 20 at 1:20 AM, Amazon Redshift customers in all AWS Regions were unable to use IAM user credentials for executing queries due to a Redshift defect that used an IAM API in the N. Virginia (us-east-1) Region to resolve user groups. As a result, IAM’s impairment during this period caused Redshift to be unable to execute these queries. Redshift customers in AWS Regions who use “local” users to connect to their Redshift clusters were unaffected.
(翻訳)
クラスターのアベイラビリティ(可用性)障害に加えて、10月19日午後11:47から10月20日午前1:20の間、全 AWS リージョンの Amazon Redshift のお客様は、ユーザーグループを解決するために N. Virginia (us-east-1) リージョンの IAM API を使用するという Redshift の不具合(defect)により、クエリ実行のための IAM ユーザー認証情報を使用することができませんでした。結果として、この期間中の IAM の障害により、Redshift はこれらのクエリを実行することができなくなりました。Redshift クラスターへの接続に「ローカル」ユーザーを使用している AWS リージョンの Redshift のお客様は、影響を受けませんでした。
Amazon Redshift には、IAM ユーザーの所属グループを解決するために、us-east-1 リージョンの IAM API を(リージョンに関係なく)呼び出してしまうという不具合がありました。その結果、us-east-1 の IAM が障害を起こした際、us-east-1 以外の全リージョンの Redshift クラスターでも、IAM ユーザーによるクエリ実行が道連れで失敗してしまいました*2。
つまり、Redshift は STS リージョン分離とはまた別の要因で、今回 us-east-1 障害の影響を受けてしまっていたことが明らかになりました。
まとめ
今回の us-east-1 障害は、AWS にとって(そして利用者にとって)非常に深刻なものであったことは間違いありません。
しかし、その影響が(一部のグローバル機能を除き)他リージョンに拡大せず、ほぼリージョン内に留め置かれた裏側には、AWS が「回復性への執念(Obsession with Resilience)」と呼び、日々実行してきた地道なアーキテクチャ改善があったからではないでしょうか。
特に、障害発生のわずか半年前(2025年4月)に完了していた STS の透過的リージョン分離は、今回の障害が「全世界的な認証停止」という最悪のシナリオに至るのを防いだ、"見えないファインプレー" であったと、技術的に推察します。
障害発生時の対処法を学ぶだけでなく、こうした「障害の影響を最小限に食い止めた」アーキテクチャや設計思想にも注目し、学び続けていくことが重要なのではと思いつつ、本ブログを終えたいと思います。
では、またお会いしましょう。
*1:ただし、あくまで仮説という断りを入れさせてください
*2:Redshift クラスターの DB 内で直接 CREATE USER コマンドを使って作成されたローカルユーザーは影響を受けませんでした
佐竹 陽一 (Yoichi Satake) エンジニアブログの記事一覧はコチラ
セキュリティサービス部所属。AWS資格全冠。2010年1月からAWSを業務利用してきています。主な表彰歴 2021-2022 AWS Ambassadors/2020-2025 Japan AWS Top Engineers/2020-2025 All Certifications Engineers。AWSのコスト削減やマルチアカウント管理と運用を得意としています。