

マネージドサービス部 佐竹です。
AWS re:Inforce 2025 に現地参加してきましたので、そのログを順番に記述しています。
はじめに
2025年6月16日から18日にかけて、ペンシルベニア州フィラデルフィアで AWS のセキュリティに特化したカンファレンス「AWS re:Inforce 2025」が開催されました。
参加したセッションのレポートを「1日のまとめ」に書いていこうとしたらあまりにも文章量が増えすぎてしまったので小分けにしています。
本ブログは「【AWS re:Inforce 2025】現地参加レポート 2日目 6月17日(火) 佐竹版」より SEC202 How the AWS obsession with resilience helps customers build for adversity の解説です。
私の感想やコメントは解説の邪魔になると感じたので「脚注」として記載しています。ただし大きく補足が必要な場面では別途いくつか補足を記載しています。
SEC202 How the AWS obsession with resilience helps customers build for adversity 解説
翻訳すると「AWSのレジリエンスへの執念が、お客様の逆境への備えにどのように役立つか」となります。
なお本セッションは re:Inforce 2日目の 13:30 から行われましたイノベーショントークの1つです。このセッションは1時間枠のため少々セッション自体が長いため、私が重要と感じたポイントに絞って記載しているつもりです。
補足①:本ブログを読む前に知っておきたい話
AWS は「AWS Security Token Service グローバルエンドポイントの今後の変更のお知らせ(Announcing upcoming changes to the AWS Security Token Service global endpoint)」を2025年の1月末に公開しました。以下はその日本語ブログです。
要約しましょう。AWS STS グローバルエンドポイント (sts.amazonaws.com) の動作変更に関するお知らせが本ブログの趣旨です。
歴史: AWS STS は2011年8月に米国東部(バージニア北部)の単一グローバルエンドポイントで開始されました。その後、単一リージョンへの依存を減らし、パフォーマンスと信頼性を向上させるため、2015年2月にリージョナルエンドポイントが導入されました*1。
変更の概要: リージョナルエンドポイントが提供された後も、多くの利用者が依然としてグローバルエンドポイントを使用しているため、AWS は利用者側のアクション不要でその動作を変更することとしました。デフォルトで有効なリージョンからのグローバルエンドポイントへのリクエストが、リクエスト元のリージョンでローカルに処理されるようになり、耐障害性とパフォーマンスが向上します。
変更の完了報告 上記の変更が「April 18, 2025」に行われた追記により*2、正式に完了したことが公にされました。デフォルトで有効な全リージョンにおいて、STS グローバルエンドポイントへのリクエストは、ワークロードが存在するのと同じ AWS リージョン内で自動的に処理されるようになり、耐障害性とパフォーマンスが強化されています。この変更はオプトインリージョンには展開されません*3。AWS は引き続き、可能な限り適切なリージョナルエンドポイントを使用することを推奨しています。
本セッションでは STS の上記変更についての裏側が語られていました。そのため、本情報がここから先のレポートの手助けになります。
概要
本セッションは、AWS が日々向き合っている「回復性(Resilience)」への執着と、それがどのように顧客の利益に繋がっているかを説明するものでした。
AWS はインシデントから学び、改善し、より強くなる「アンチフラジャイル(Anti-fragile)」な組織を目指していると語られました。セッションでは、AWS の信頼性を支える4つの「可用性に関する公理(Availability Axioms)」が紹介され、その具体的な実践例として、特に「AWS Security Token Service (STS)」のリージョン分離を改善した大規模プロジェクトが詳細に解説されました。本ブログでも STS について記載していきます。
またその他に、アベイラビリティーゾーン障害への耐性、厳格なテスト、過負荷からの保護といった分野における最新のイノベーションが紹介され、AWS がいかにしてミッションクリティカルなワークロードを支える基盤となっているかも示されました。
可用性に関する4つの公理 (Availability Axioms)
AWS の回復性を支える文化を全社に浸透させるために、「可用性に関する公理」を定義していると説明されました。その4つが以下です。画像はセッション終盤のものですが、わかりやすいため先に紹介しています。
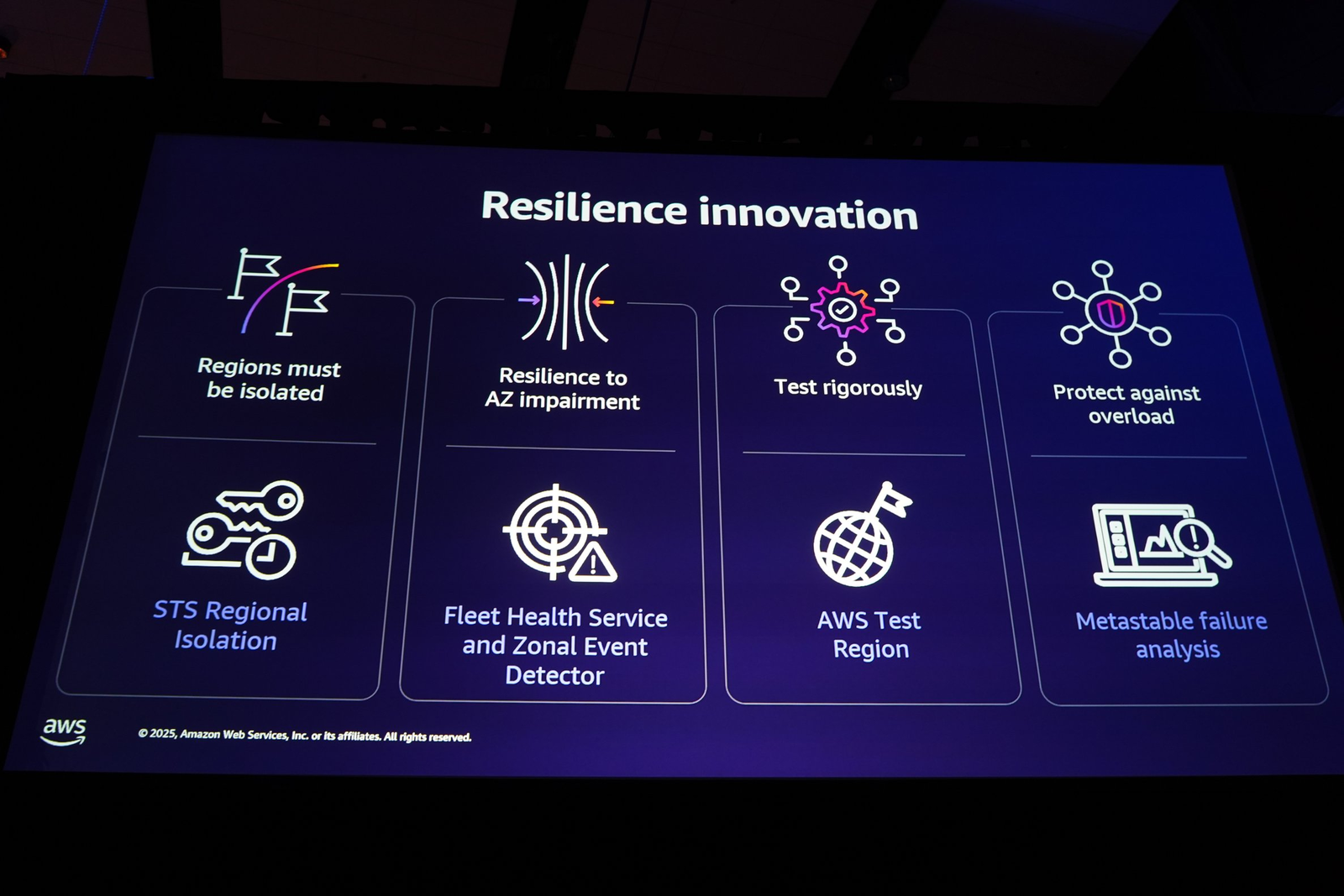
- リージョンの分離 (Regions must be isolated): 各AWSリージョンは高度に独立して運用されるべきである。
- AZ障害への耐性 (Resilience to AZ impairment): 全てのリージョナルサービスは、1つの AZ が機能しなくなっても顧客体験を損なうことなく稼働し続けなければならない。
- 厳格なテスト (Test rigorously): ユニットテストや結合テストといった基本的なテストに加え、カオスエンジニアリングや「ゲームデー」と呼ばれる本番環境での障害シミュレーションを定期的に実施。
- 過負荷からの保護 (Protect against overload): 全てのシステムは、自身を過負荷から守る仕組みを持つ必要がある。
これにより、数千に及ぶ開発チームが共通の言語でシステムについて議論できるとしています。
STS のリージョン分離と改善
セッションでは、1つ目の「リージョンの分離」をいかに実践したかを示す大規模なプロジェクトとして、先に補足した STS のエンドポイントの動作変更について述べられました。
STS は、IAM ロールを引き受けるために一時的な認証情報を発行する、AWS の中核的なサービスです。
ただし、IAM そのものの API よりもはるかに STS のほうが Call 頻度が高く、その重要性から2014年にはリージョン分離の対象となりました。

2015年にはリージョナルエンドポイントが利用可能になりましたが、10年近く経ってもなお、多くの顧客が従来のグローバルエンドポイント (sts.amazonaws.com) を利用し続けている実態がありました。
これは、顧客側での修正が必要なため、移行が進んでいないということを示しているわけです。
そこで AWS は、顧客に一切のアクションを求めることなく、この問題を解決するアプローチに切り替えました。
具体的な方法は、デフォルトで有効な17のリージョン全てに「グローバルエンドポイントの完全なレプリカ」を構築し、VPC 内の Route 53 DNS Resolver からのリクエストを透過的に最も近いリージョンのエンドポイントへリダイレクトするというものでした。
この変更は細心の注意を払って行われたとのことで、例として CloudTrail ログへの配慮もその一つです。多くの顧客は CloudTrail のログをグローバル設定で1つのリージョンに集めているためです。
これまでグローバルエンドポイントのログは us-east-1 に出力されていましたが、リクエストが仮にオーストラリアリージョン(シドニー)で処理されるようになっても、顧客の既存の設定に影響を与えないよう、ログは従来通り us-east-1 に配送されるようにしました。さらに透明性を確保するため、ログには「実際にリクエストが処理されたリージョン」を示すメタデータが追加されたとのことです。
移行がもたらした成果とは
この大規模な移行の結果、AWS 全体の回復性とパフォーマンスが劇的に向上したとのこと。またそれがグラフでも示されました。
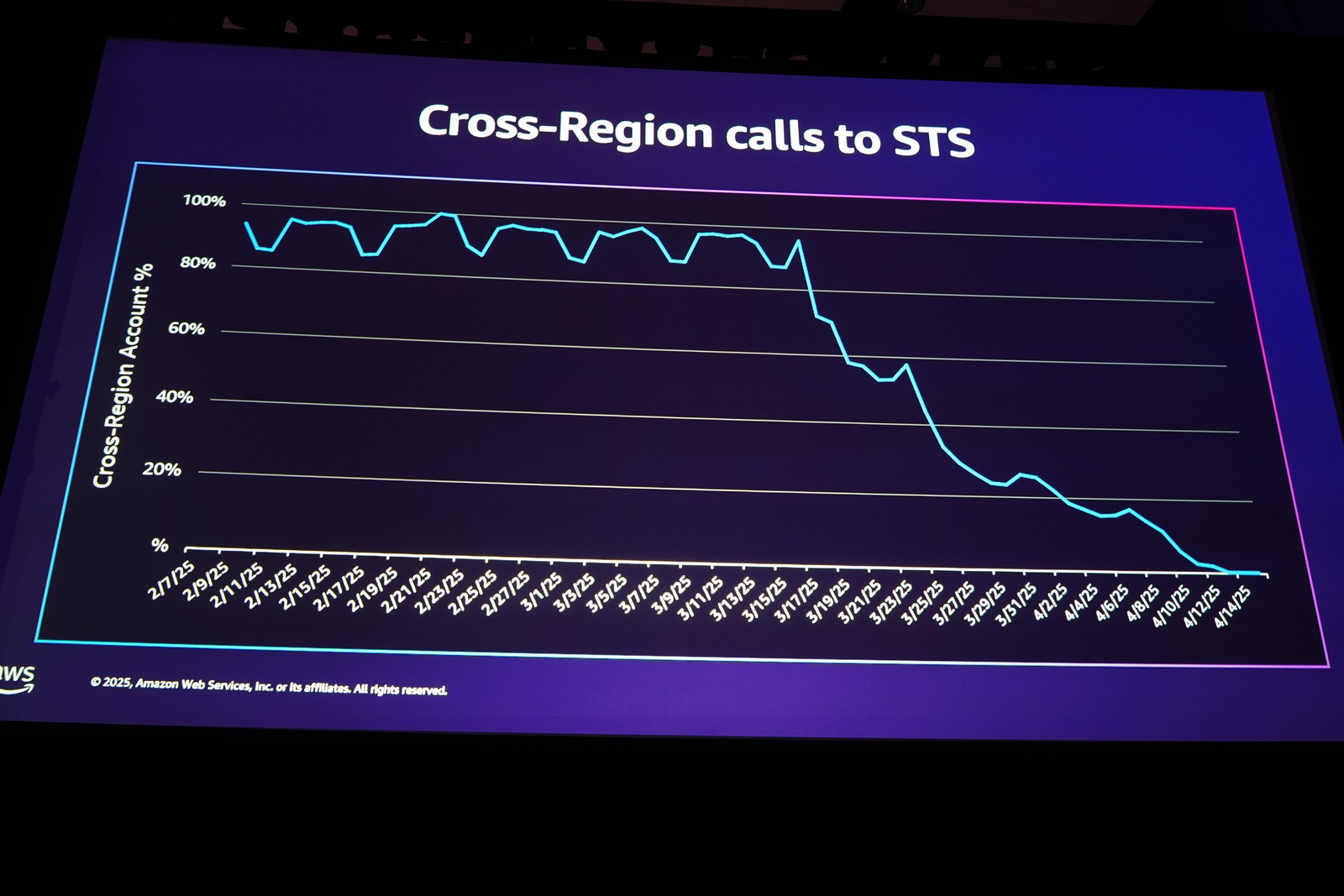
まず、リージョンをまたいで STS が呼び出される「クロスリージョンコール」の割合です。
本画像のグラフで2025年の3月中旬から4月にかけて、クロスリージョンコールの割合が約100%から0%近くまでに低下したことがわかります。
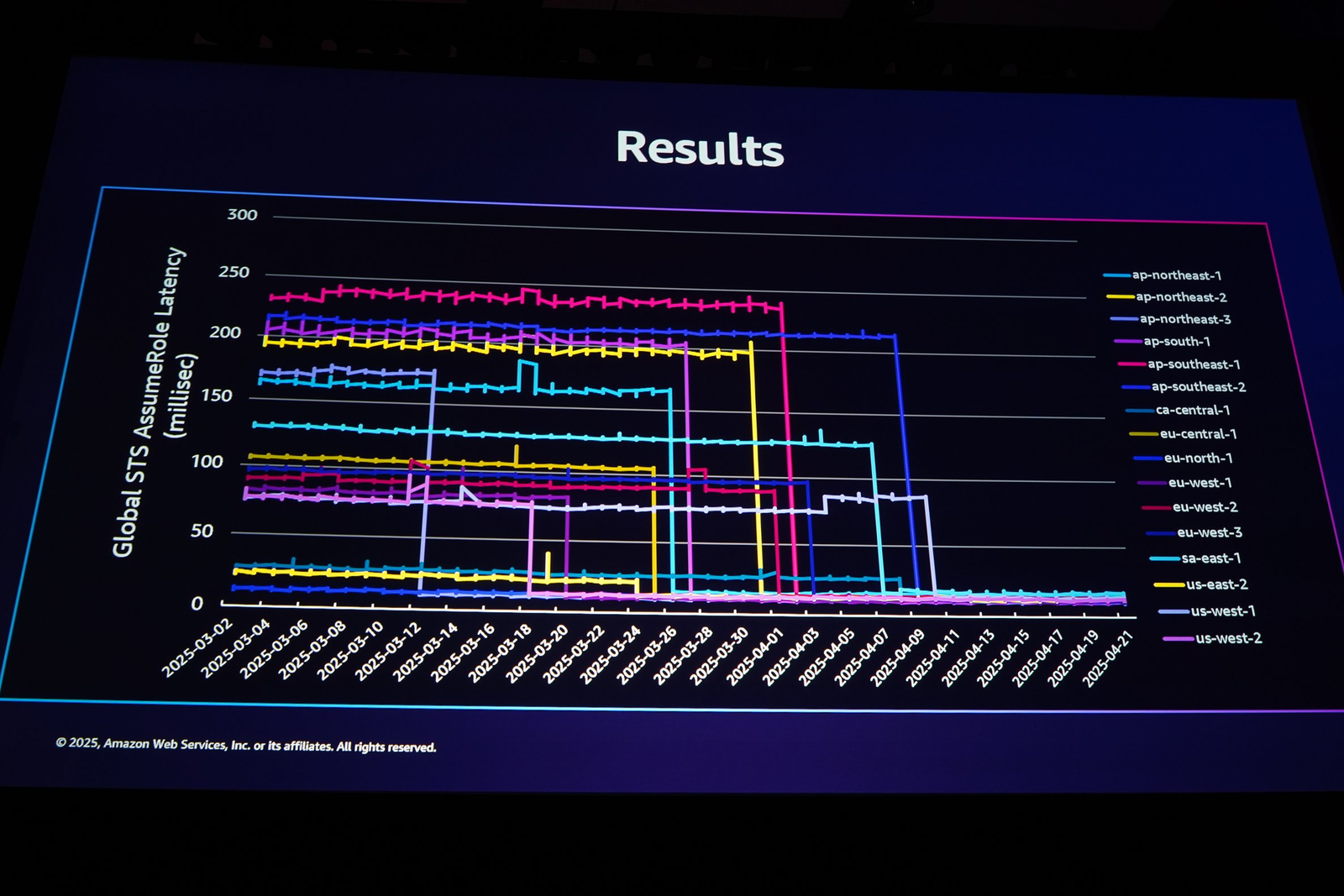
合わせて紹介された画像がこちらです。
STS の AssumeRole API 呼び出しにおけるレイテンシーの変化です。200ms を超えていたようなリージョンからの呼び出しも、(クロスリージョンをしなくなり)プロジェクト完了後は一貫して20ms以下に収束しています。
これは毎秒数百万に及ぶ STS への Call が本変更の恩恵を受けていることを意味しています*4。
その他の回復性イノベーション
STS の事例に加え、他の公理に関連するイノベーションも詳細に紹介されました。ただ、今回これらの3つについては概要を紹介するに留めたいと思います。
AZ 障害と「グレーな障害」への耐性
Lambda のような大規模サービスでは、1万台のフリートのうち1台だけが不調になる「グレーな障害(Gray Failure)」が問題となります。
ホストが完全に停止するわけではなく、わずかに遅くなったり、エラー率が上がったりするため、検知が非常に困難です*5。
セッションでは「your nines are not my nines.」という言葉が引用されました。例えば可用性が 99.99% だった場合、フリート全体で見れば可用性の低下は0.01%でも、その不調な1台に運悪くワークロードが集中した顧客にとっては、体験が大きく損なわれる可能性があるということです*6。
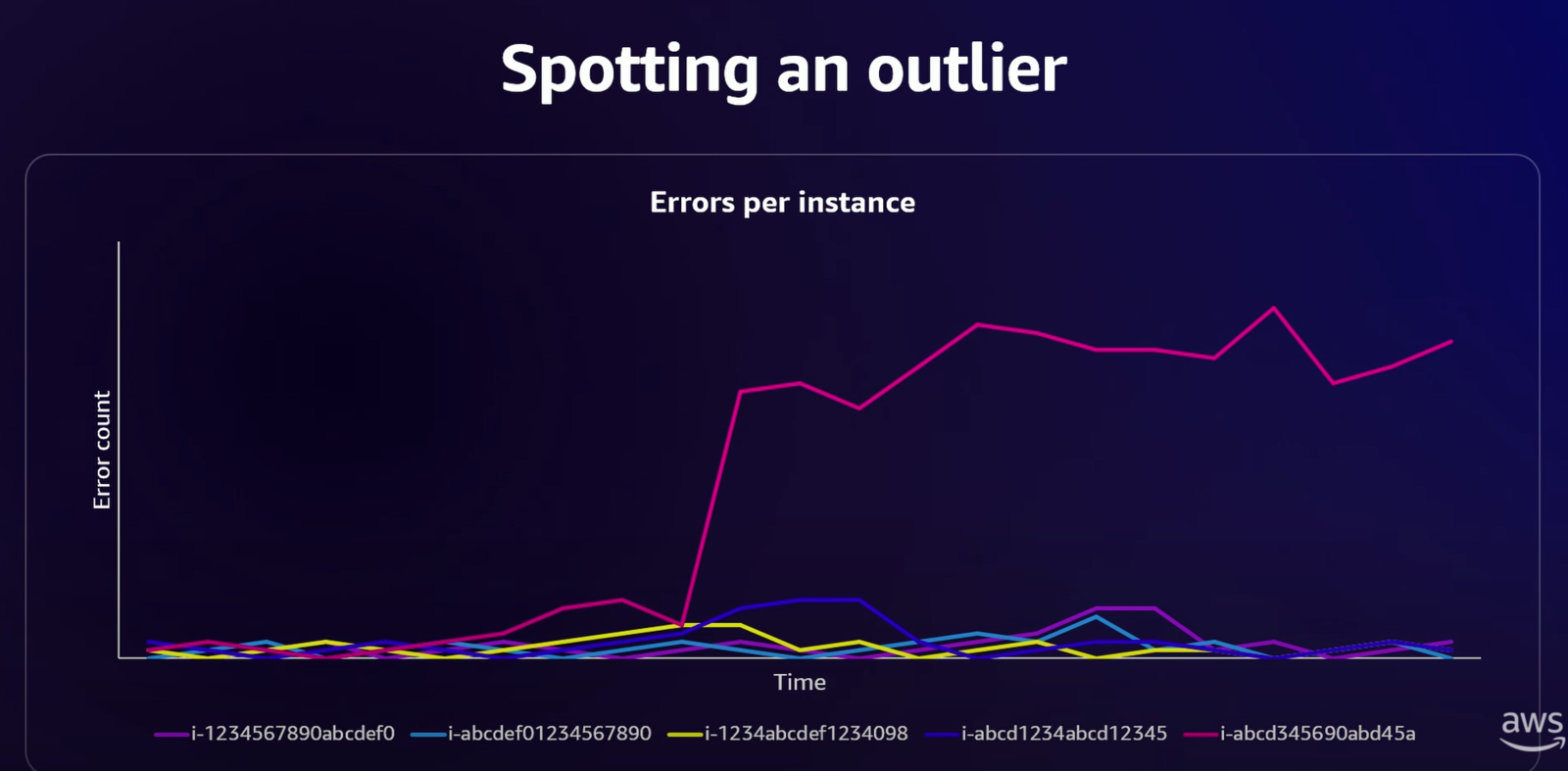
この「干し草の山から針を探す (We're looking effectively for the needle in a haystack.)」のような問題*7を解決するため、AWS は CloudWatch Contributor Insights を活用してフリートの中から異常な振る舞いをする「外れ値(Outlier)」を検出する仕組みを構築しました。
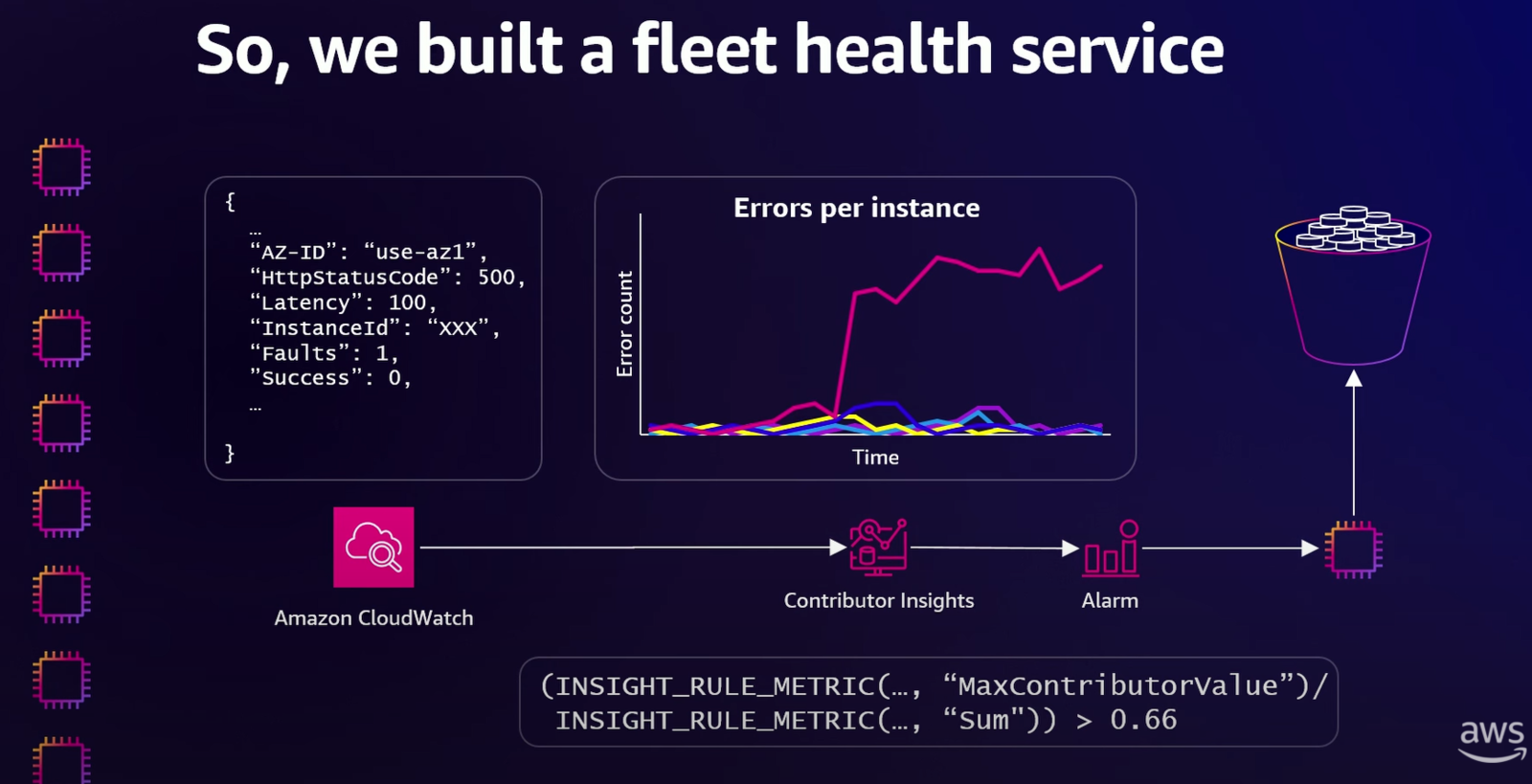
これが「Fleet Health Service」です。各インスタンスから送られるログデータを Contributor Insights で分析し、「ある1台のインスタンス(contributor)が、フリート全体のエラーの66%以上を占める」といったルールでアラームを上げ、問題のあるインスタンスを自動的に隔離・終了させます。この仕組みは元々 Lambda のために作られましたが、今では多くの AWS サービスで利用される汎用的なサービスへと姿を変え、横展開されているとのことでした。
さらに、この「外れ値の検出」のアプローチはインスタンス単位から AZ 単位へと拡張されました。
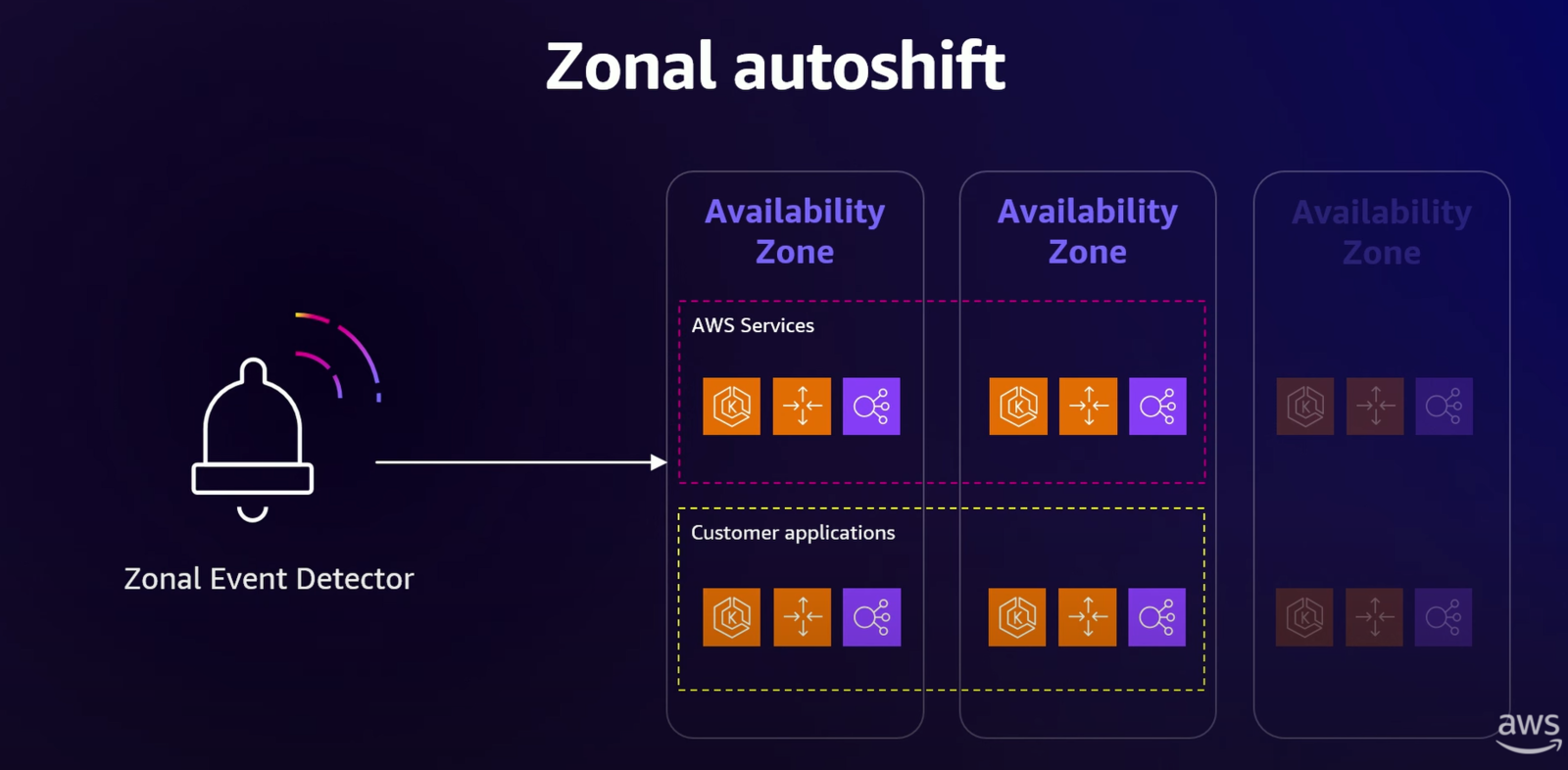
最終的には、AWS が AZ 障害の検知からトラフィックの退避までを全て自動で行う「Zonal Autoshift」が実現されています。
これにより、顧客は AZ 障害を意識することなく、AWS が自動的に回復アクションを実行してくれるという、高レベルの回復性を享受できるようになっています
補足②:Zonal Autoshift
ゾーンオートシフト(Zonal Autoshift)とは、AWSが自社の内部的な監視データに基づき、ある単一の AZ でレイテンシー増加などの潜在的な障害を検知した際に、顧客に代わって自動的にその AZ からトラフィックを退避させてくれる機能です。
これにより、運用者が夜中にアラートで起きて手動で対応する(Zonal Shiftを行う)必要がなくなり、AWS がプロアクティブに回復アクションを実行してくれるため、アプリケーションの耐障害性がさらに向上します。これは2023年12月に AWS の公式ブログでも解説されています。
なお、本機能の解説の日本語版の AWS のブログは何故か2つあります。
原文(英語の記事)はどちらも同じです。
厳格なテスト
ここでは「ゲームデー」と「テストリージョン」について述べられました。
AWS には「先週テストしていないものは、壊れている (if you haven't tested something in the past week, it's broken.)」という言葉があるそうです。定期的なテストは、AWS の運用文化の一部だとのこと。
これを支える考え方が「能力の包絡線(Competence Envelope)」です。
航空機の安全な飛行範囲(高度や速度)を示すフライトエンベロープと同様*8、システムが安全かつ堅牢に動作することが知られている範囲を定義します。
定期的なテストによってこの範囲を維持・拡大し、「未知 (unknowns)」を「既知 (knowns)」に変えていくことが重要だと述べられました (we do that by turning unknowns into knowns through constant testing.)。
そのための実践が「ゲームデー」です。新リージョンが公開される前には、本番環境で実際に電源障害やネットワーク分断などを発生させ、システムが想定通りに振る舞い、回復することを確認します*9。
そして、このゲームデーをいつでも、より高い頻度で実施するために、AWS は以下の取り組みを行っています。
それが「The AWS Test Region」の構築です。これは、顧客が一人もいない、テスト目的のためだけに構築された、3つのAZを持つ完全な AWS リージョンです。AWS のサービスチームは、このテストリージョンを「顧客がいない本番リージョン」として扱います。これにより、開発環境ではない、本番と全く同じ条件下でテストが可能となっています。
ここでは日常的に AZ の電源を落としたり、依存サービスを停止させたり、まだ誰も見たことのないような稀なイベントを発生させたりして、AWS サービス全体の回復性を継続的に向上させているとのことでした。具体的には以下のようなテストが行われています。
- 共通の依存サービスの破壊: 共通で利用される基盤サービスを意図的に停止させ、各サービスがそれらに耐え得るかを検証
- サービスのコールドスタート: サービスを完全に停止させた状態から起動し、全てが正常に回復することを確認
- 過去のインシデントの再現: 過去に発生した障害と、そのために施された修正が実際に有効であるかを、テストリージョンで再現することでそれを検証
過負荷からの保護:準安定障害(Metastable Failures)
4つのテーマの最後の1つは、システムが安定状態から負荷の増加によって脆弱な状態に入り、何らかのトリガーによって過負荷がフィードバックループで維持される「準安定状態」に陥る障害です。一度この状態になると、手動介入なしには回復が困難になります。

この準安定障害のプロセスは、添付の図にある5つのステップで説明できます。
安定状態と負荷の増加 (Stable State & Increasing Load)
システムは通常、安定した状態で稼働しています。ここに、ビジネスの成長などに伴い、継続的な負荷の増加(① Increasing load)が発生し、次の「脆弱な状態」へと向かっていきます。脆弱な状態 (Vulnerable State)
負荷が増加した結果、システムは「脆弱な(② vulnerable)」状態へと移行します。この時点ではまだシステム自体は正常に稼働していますが、障害に対する余裕(マージン)が少なくなっており、次のトリガーに対して非常に敏感になっています。トリガー (Trigger)
脆弱な状態のシステムに、何らかのトリガー(③ Trigger)が加わります。セッションで挙げられた典型的な例は、クライアントからの「リトライの嵐(Retry Storm)」や、依存サービスの急なパフォーマンス低下など、短期的なリクエストの急増です。準安定状態とフィードバックループ (Metastable State & Sustaining Effect)
トリガーによってシステムの応答が遅れると、クライアントが一斉にリトライを開始し、これが新たな負荷となってさらに応答を遅延させる…という過負荷のフィードバックループ(④ Sustaining effect)が完成します。このループにより、システムは自力で回復できない「準安定状態」に陥り、過負荷状態に固定されます。回復 (Recovery)
この状態から脱するには自然回復は困難であり、ロードシェディング(意図的なトラフィックの遮断)*10やシステムの再起動といった、運用者による手動での介入(⑤ Recovery)によって、再び安定状態へと戻す必要があります。
AWS では、このような稀だけれども影響の大きい障害を防ぐ(発生した場合は途中で断ち切る)ための研究と対策も進められています。
関連記事等
セッションの動画
この概要を読んで興味が出た方は YouTube に既に動画がアップロードされているので是非ご覧ください。
Announcing upcoming changes to the AWS Security Token Service global endpoint
グレー障害
Zonal autoshift – Automatically shift your traffic away from Availability Zones when we detect potential issues
まとめ
本セッションは、AWS がいかに「見えない部分」でサービスの回復性と信頼性を追求し続けているかを具体的に示した、興味深い内容でした。また最初に紹介しました「可用性に関する4つの公理 (Availability Axioms)」についての解説も完了しております。
このセッションは「セキュリティそのもの」というかは、その前提となる安定性や回復性、運用の重要性が述べられたセッションであると受け取りました。サービスがいかにセキュアであろうとも、不安定であれば顧客体験は非常に悪くなってしまいます。
私は特に AWS Security Token Service (STS) のエンドポイントにおける「リージョン分離」に関するプロジェクトが、その規模と、顧客に一切の負担をかけずにやり遂げたという点で、AWS のエンジニアリング力の高さと顧客視点を感じました。
さて、4つの公理を以下にまとめます。
リージョンの分離 (Regions must be isolated) この原則を徹底するため、AWS は中核サービスである STS のエンドポイントを、顧客に負担をかけることなく透過的にリージョン化しました。
AZ障害への耐性 (Resilience to AZ impairment) 「グレー障害」のような検知が困難な問題を解決する Fleet Health Service や Zonal Event Detector を開発。これは最終的に Zonal Autoshift として、障害からの回復という運用負荷を AWS が肩代わりするイノベーションに繋がっています。
厳格なテスト (Test rigorously) 「テストしていないものは壊れている」という文化を究極の形で実践するため、顧客ゼロの完全な本番環境である「AWS テストリージョン」を構築。これにより日常的に稀な障害シナリオを含め網羅的に検証し、実践的な回復力を得ることに成功しています。
過負荷からの保護 (Protect against overload) 自己増殖的なフィードバックループを持つ「準安定障害」を科学的に分析しています。これにより、稀ではあるものの壊滅的な影響をもたらす可能性のある、複雑な障害モードの予防にも取り組んでいます。
では、またお会いしましょう。
*1:AWS の多くのサービスがバージニアリージョンを起点に実装されているということは、特にエンジニアの多くが認識されているかもしれません
*2:本内容は日本語版には記載がありません。英語版のみに追記されています
*3:AWS アカウントを作成した時点では無効化されており、利用するためにはアカウント管理者が明示的に「このリージョンを有効にする」という操作(オプトイン)を行う必要があるリージョンのこと
*4:この変更を利用者に影響なく行ったという事実が AWS の凄いところだと感じます
*5:グレー障害とは、システムが完全に停止する「黒」でも、正常に稼働している「白」でもない、中間的な不具合状態を指します。具体的には、パフォーマンスが著しく低下したり、一部のリクエストにだけエラーを返したりするなど、発見が困難な障害のことです。この障害の兆候は微妙で検知が難しいため、影響を特定し、問題を解決するまでに時間がかかる傾向があります
*6:nine (9) という言葉はあまり日本では馴染みがないと思うのですが、特にクラウドや通信の分野でシステムの可用性=Availability、つまりは「システムが稼働している時間の割合」を示すための一般的な俗語/スラングとなっているということでした。ようは99.99とか99.999とかのことです。具体例として「99.9%」とは、「年に約9時間弱であればシステムが止まっていても許容される」という意味ですが実際この9時間弱に巻き込まれたユーザからは0%に見えるということを伝えています
*7:つまりは、何万もあるインスタンスからたった1つの不調でグレーなインスタンスを探し出す問題
*8:航空機が安全に飛行できる速度、高度、荷重などの限界範囲(安全動作領域)を図で示したものです。この範囲の内側であれば航空機は安定して飛行できますが、範囲の外に出る("fly outside the envelope")と、失速したり機体が破損したりする危険があります。この安全領域を囲む境界線のことを「Envelope」と呼びます。これは手紙を入れる「封筒」ではなく、元々は数学用語の「包絡線(ほうらくせん)」から来ています
*9:さらっと記載していますがこのテストはかなり壮大なものになりそうです
*10:ロードシェディング(Load Shedding)とは、システムが過負荷に陥って全体がダウンするのを防ぐために、あえて一部の処理(負荷)を「shed(切り捨てる)」する防御技術のことです。電力で例えると、計画停電のようなことです
佐竹 陽一 (Yoichi Satake) エンジニアブログの記事一覧はコチラ
セキュリティサービス部所属。AWS資格全冠。2010年1月からAWSを業務利用してきています。主な表彰歴 2021-2022 AWS Ambassadors/2020-2025 Japan AWS Top Engineers/2020-2025 All Certifications Engineers。AWSのコスト削減やマルチアカウント管理と運用を得意としています。