

はじめに
LLMアプリケーションを開発していると、こんな悩みはありませんか?
- プロンプトのチューニングをしているけど、どの変更が改善につながったか分からない
- ユーザーがどんな使い方をしているのか把握できない
- エラーが発生しても、何が原因なのか追跡できない
- トークン使用量やレスポンス時間を可視化したい
こういった課題を解決してくれるのが、LLMアプリケーション向けの可観測性プラットフォーム「Langfuse」です。
Langfuseを使うと、LLMアプリケーションの動作をトレース(追跡)し、プロンプトの履歴管理、パフォーマンス分析、コスト管理などが簡単にできるようになります。まさにLLMアプリケーション開発者にとっての「見える化ツール」です。
今回は、AWSが提供するサンプルリポジトリを使って、Langfuse v3をAmazon ECS/Fargateで簡単にデプロイする方法をご紹介します。
アーキテクチャ
今回構築するLangfuse環境のアーキテクチャは以下の通りです。

前提条件
今回の手順を実行するには、以下のセットアップが必要です。
必要なもの
- AWSアカウント
- AWS CLI
- AWS CDK (Cloud Development Kit)
- Python 3.9以上
- OpenAI APIキー(サンプルアプリで使用)
- Git
デプロイ手順
それでは実際にLangfuseをデプロイしていきましょう。30分もあれば環境構築が完了します。
1. リポジトリのクローン
まずはAWSのサンプルリポジトリをクローンします。
git clone https://github.com/aws-samples/deploy-langfuse-on-ecs-with-fargate.git cd deploy-langfuse-on-ecs-with-fargate/langfuse-v3
2. Python環境のセットアップ
Python仮想環境を作成して、必要なパッケージをインストールします。
python3 -m venv .venv source .venv/bin/activate # Windowsの場合は .venv\Scripts\activate pip install -r requirements.txt
3. 設定ファイルの準備
cdk.context.jsonというファイルを作成して、デプロイの設定を記載します。サンプルファイルをコピーしてから編集しましょう。
cp .example.cdk.context.json cdk.context.json
次に、セキュリティ関連の値を生成します:
# 各種シークレット値を生成 echo "SALT (共通): $(openssl rand -base64 32)" echo "ENCRYPTION_KEY (共通): $(openssl rand -hex 32)" echo "NEXTAUTH_SECRET: $(openssl rand -base64 32)"
生成された値をcdk.context.jsonの該当箇所にコピペしていきます。
{ "langfuse_worker_env": { "SALT": "ここに生成されたSALT(共通)の値を貼り付け", "ENCRYPTION_KEY": "ここに生成されたENCRYPTION_KEY(共通)の値を貼り付け", ... }, "langfuse_web_env": { "NEXTAUTH_SECRET": "ここに生成されたNEXTAUTH_SECRETの値を貼り付け", "SALT": "ここに生成されたSALT(共通)の値を貼り付け", "ENCRYPTION_KEY": "ここに生成されたENCRYPTION_KEY(共通)の値を貼り付け", ... } }
※SALT値とENCRYPTION_KEY値はworkerとwebで同じ値を使用してください。
4. Aurora PostgreSQLのバージョン修正
デフォルトのコードではAurora PostgreSQL 15.4を使用していますが、このバージョンが利用できない場合があります。事前にバージョンを修正しておきましょう。
# aurora_postgresql.pyを編集 vim cdk_stacks/aurora_postgresql.py
68行目付近を以下のように修正します:
# 修正前 rds_engine = aws_rds.DatabaseClusterEngine.aurora_postgres(version=aws_rds.AuroraPostgresEngineVersion.VER_15_4) # 修正後 rds_engine = aws_rds.DatabaseClusterEngine.aurora_postgres(version=aws_rds.AuroraPostgresEngineVersion.VER_15_10)
5. AWS環境の準備
CDKを使うための初期設定(ブートストラップ)を行います。
export CDK_DEFAULT_ACCOUNT=$(aws sts get-caller-identity --query Account --output text) export CDK_DEFAULT_REGION=$(aws configure get region) cdk bootstrap
6. デプロイ実行
いよいよデプロイです。全部で15個ほどのスタックが順番に作成されます。
# まずはどんなスタックが作られるか確認 cdk list # デプロイ実行(50分ほどかかります) cdk deploy --all
各スタックごとに変更内容の確認が求められるので、yを入力して進めてください。CloudFormationコンソールで進捗を確認できます。
7. アクセスURLの確認
デプロイが完了したら、LangfuseのURLを確認します。
aws cloudformation describe-stacks \
--stack-name LangfuseWebECSServiceStack \
--region ${CDK_DEFAULT_REGION} | \
jq -r '.Stacks[0].Outputs | map(select(.OutputKey == "LoadBalancerDNS")) | .[0].OutputValue'
表示されたURLをブラウザで開けば、Langfuseの画面が表示されます!
8. 初期設定
Langfuseにアクセスできたら、以下の手順で初期設定を行います。
8.1 アカウント作成
最初にLangfuseにアクセスすると、「Sign in to your account」画面が表示されます。初めての場合は「Sign up」リンクをクリックしてアカウントを作成します。
「Create new account」画面で、名前、メールアドレス、パスワードを入力して「Sign up」ボタンをクリックします。
8.2 組織(Organization)とプロジェクトの作成
アカウント作成後、まず組織(Organization)を作成する必要があります。
「Get Started」画面で「New Organization」ボタンをクリックします。
組織名を入力(例:Blog Organization)して「Create」ボタンをクリックします。

次に、組織メンバーの招待画面が表示されます。今回は一人で使うので「Next」をクリックしてスキップします。
プロジェクト作成画面で、プロジェクト名(例:Blog Project)を入力して「Create」ボタンをクリックします。
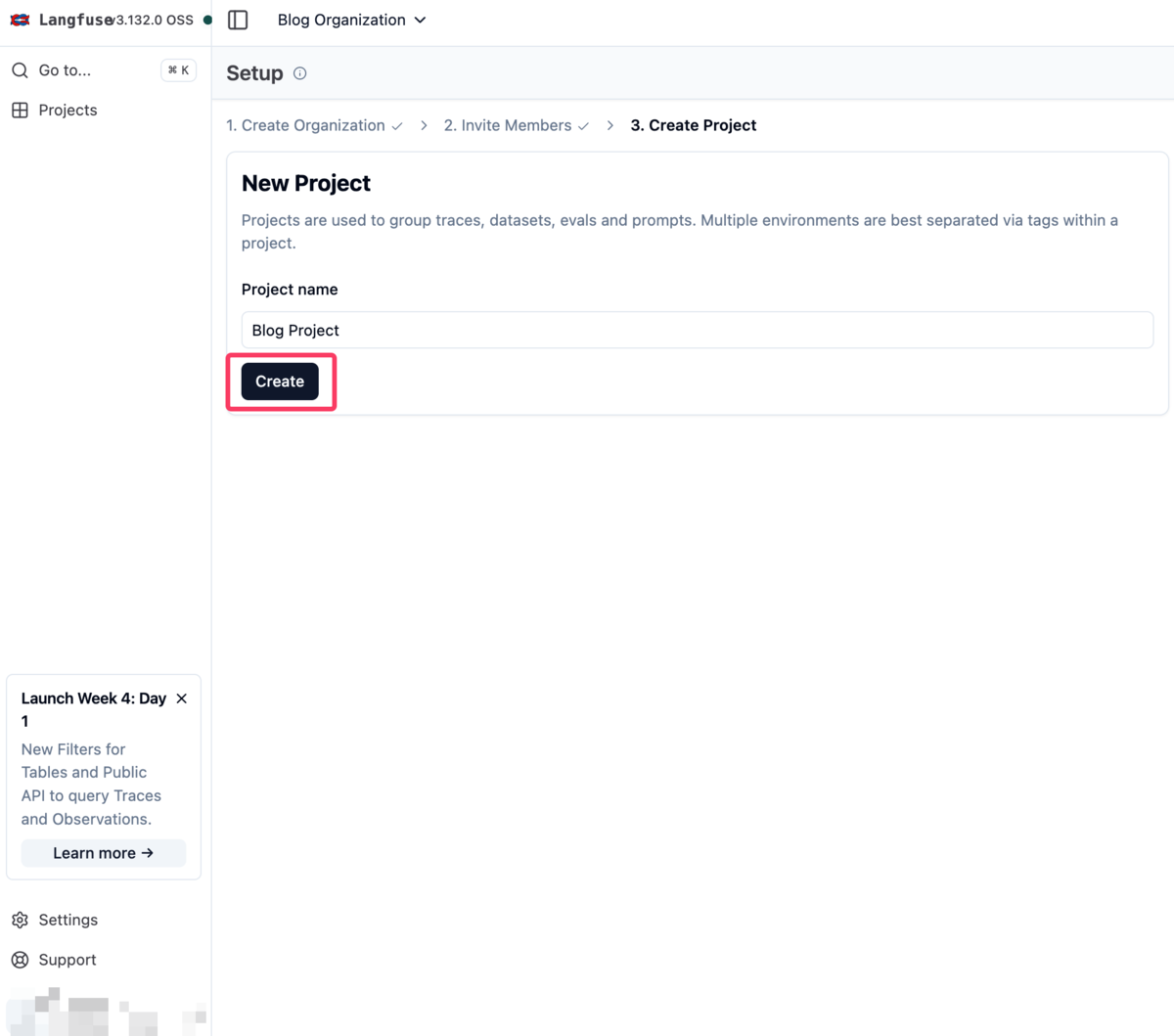
8.3 API Keysの生成
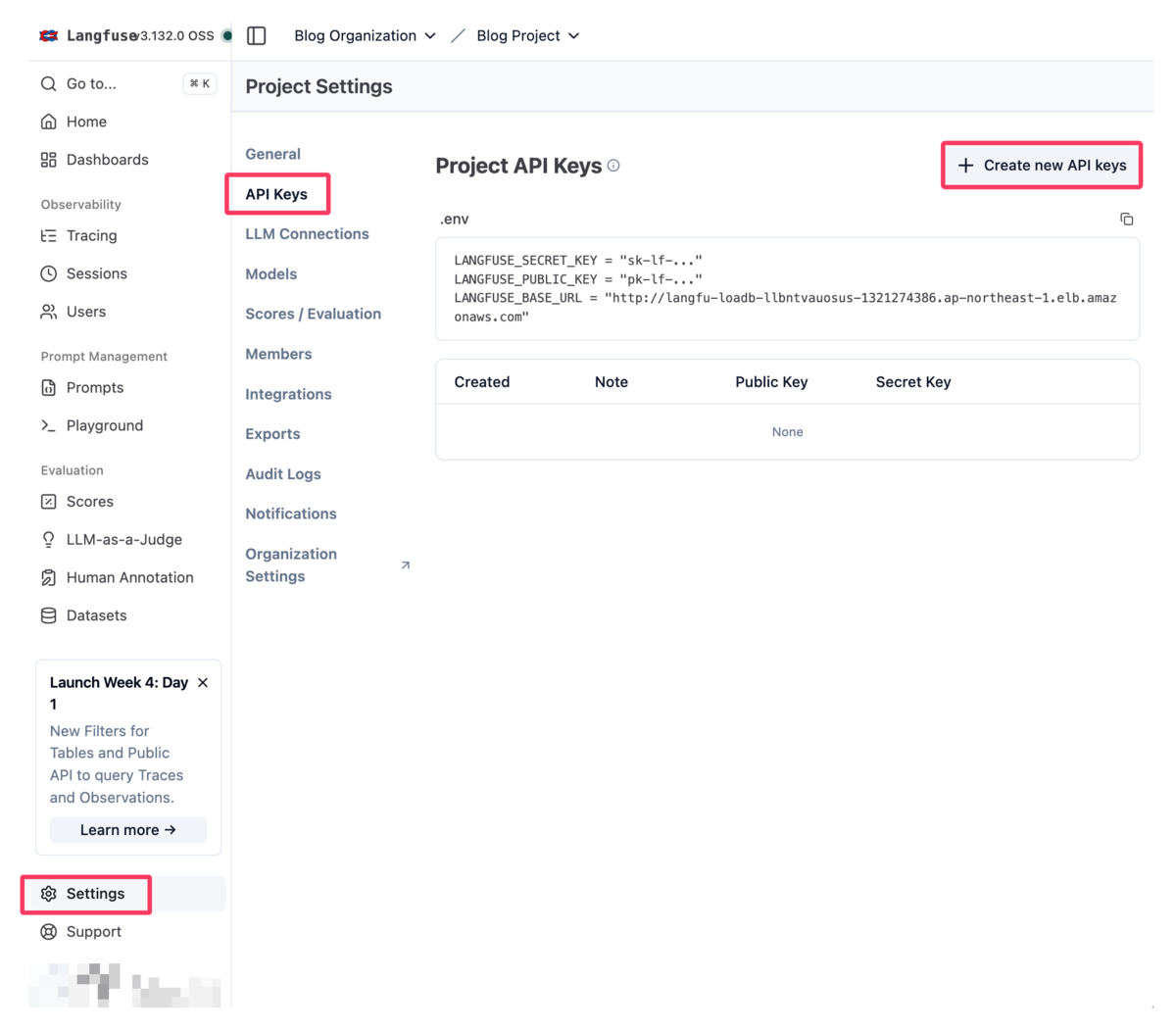
プロジェクトが作成されたら、左メニューの「Settings」をクリックし、「API Keys」タブを選択します。「Create new API keys」ボタンをクリックします。
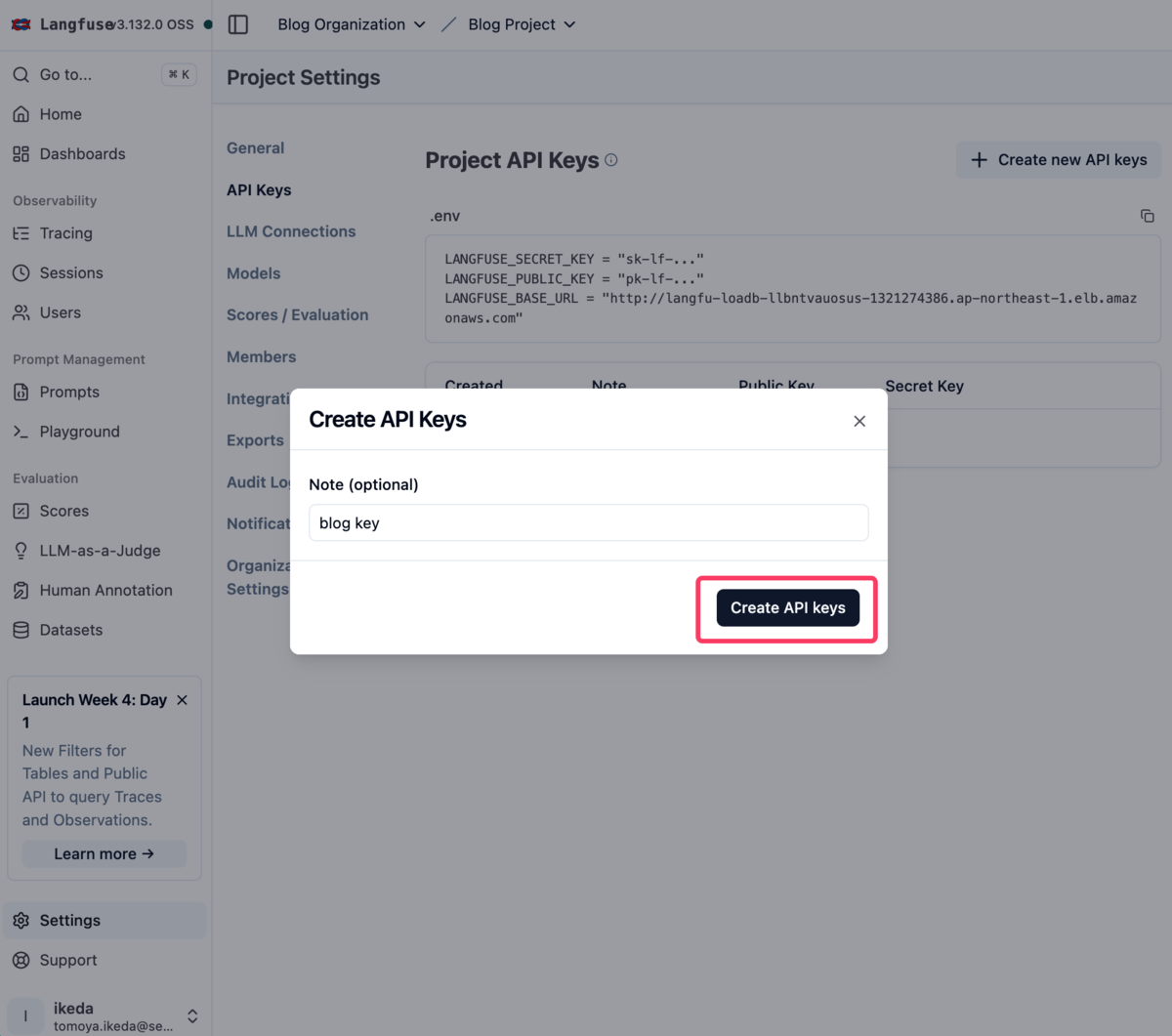
API Key作成ダイアログでNote(任意)を入力して「Create API keys」ボタンをクリックします。
生成されたAPI情報が表示されます。以下の3つの情報が重要です:
- Secret Key: 認証に使用(一度しか表示されません!)
- Public Key: クライアント側での識別に使用
- .env形式の設定: 環境変数として使用
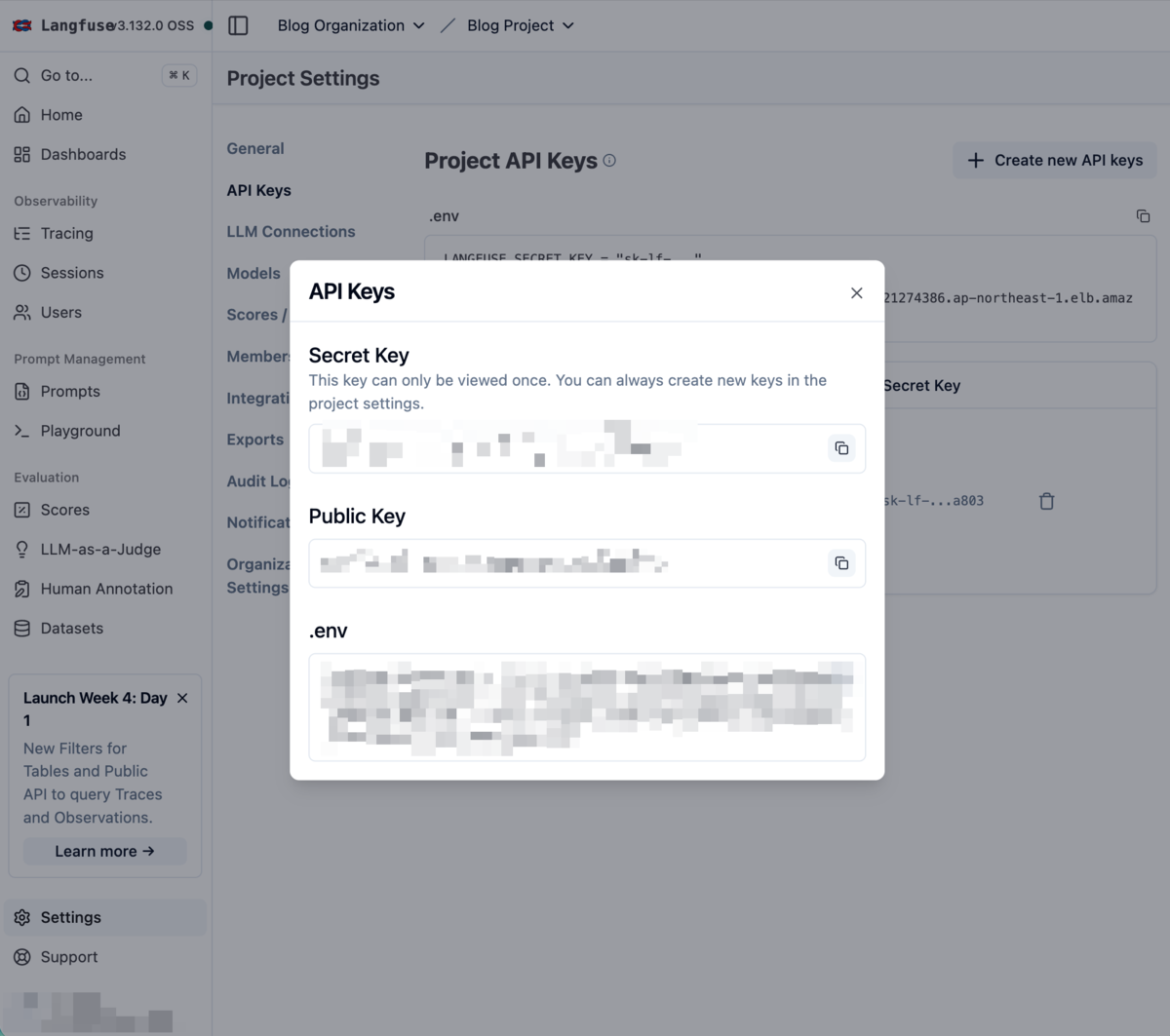
これらの値は必ずコピーして安全に保管してください。特にSecret Keyは二度と表示されないので注意が必要です。
これでLangfuseの初期設定は完了です!次はLLMアプリケーションからこのAPI Keyを使って接続してみましょう。
動作確認
実際にLangfuseにトレース情報を送信してみましょう。
パッケージのインストール
pip install langfuse openai langchain_openai langchain python-dotenv
環境設定
.envファイルを作成して、先ほど取得したLangfuseのAPI情報とOpenAIのAPIキーを設定します。
# .env LANGFUSE_PUBLIC_KEY="pk-lf-..." LANGFUSE_SECRET_KEY="sk-lf-..." LANGFUSE_BASE_URL="http://your-alb-url.ap-northeast-1.elb.amazonaws.com" OPENAI_API_KEY="sk-proj-..."
※実際の値は、先ほどLangfuseで取得したAPI KeysとOpenAIのAPIキーに置き換えてください。
サンプルコード
このサンプルでは、以下の処理を実装しています:
- ランダムなトピック選択: 技術関連のテーマからランダムに選択
- AI議論シミュレーション: 選択したトピックについてGPTが複数回発言
- 議論内容の要約: LangChainを使って議論全体を要約
- 感情分析: 要約されたテキストの感情を分析
この一連の処理により、複雑なLLMワークフローがどのようにトレースされるかを確認できます。
import os import random from operator import itemgetter from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema import StrOutputParser from langfuse import observe, get_client, propagate_attributes from langfuse.langchain import CallbackHandler from langfuse.openai import openai # 環境変数を読み込む load_dotenv() langfuse = get_client() @observe() def get_random_topic(): """ランダムなトピックを選択""" topics = [ "生成AIの活用方法", "LLMアプリケーションの運用", "デジタル変革の未来", "エンジニアリングチームの生産性" ] return random.choice(topics) @observe() def summarize_content_langchain(content): """LangChainを使ってコンテンツを要約""" # Langfuseハンドラーを初期化 langfuse_handler = CallbackHandler() # チェーンを作成 prompt = ChatPromptTemplate.from_template( "以下の内容を簡潔に要約してください:\n\n{content}" ) model = ChatOpenAI(model="gpt-4o-mini", temperature=0.3) chain = prompt | model | StrOutputParser() # ハンドラーを渡して実行 summary = chain.invoke( {"content": content}, config={"callbacks": [langfuse_handler]} ) return summary @observe() def ai_discussion(rounds: int = 3): """AI同士の議論をシミュレート""" topic = get_random_topic() print(f"議論テーマ: {topic}") # 全ての子観測にメタデータとタグを伝播 with propagate_attributes( metadata={"topic": topic, "rounds": str(rounds)}, tags=["AI議論", "デモ"] ): messages = [ {"role": "system", "content": "あなたは専門知識を持つエンジニアです。建設的な議論を行います。"}, {"role": "user", "content": f"今日のテーマは「{topic}」です。まず最初の意見をお聞かせください。"} ] discussion_content = [] for round_num in range(rounds): completion = openai.chat.completions.create( model="gpt-4o-mini", messages=messages, temperature=0.7 ) response = completion.choices[0].message.content messages.append({"role": "assistant", "content": response}) discussion_content.append(response) print(f"\n発言 {round_num + 1}: {response}") # 次の質問を追加(最後のラウンド以外) if round_num < rounds - 1: follow_up = "その点について、別の観点からの意見はありますか?" messages.append({"role": "user", "content": follow_up}) # 議論全体を要約 full_content = "\n\n".join(discussion_content) summary = summarize_content_langchain(full_content) return summary @observe() def analyze_sentiment(text: str): """感情分析を実行""" completion = openai.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": "テキストの感情を分析し、ポジティブ・ニュートラル・ネガティブで分類してください。"}, {"role": "user", "content": f"以下のテキストを分析してください:\n\n{text}"} ] ) return completion.choices[0].message.content # メイン実行 def main(): print("=== AI議論デモ(Langfuse Decorator版) ===\n") # AI議論を実行 discussion_summary = ai_discussion(rounds=3) print(f"\n議論の要約: {discussion_summary}") # 要約の感情分析 sentiment = analyze_sentiment(discussion_summary) print(f"\n感情分析結果: {sentiment}") print("\n=== Langfuseでトレースを確認してください ===") print(f"URL: {os.environ['LANGFUSE_BASE_URL']}") if __name__ == "__main__": main()
コードのポイント
@observeデコレータ - 関数に付けるだけで自動的にトレースが記録される - 実行時間、引数、戻り値が自動で追跡される
propagate_attributes
- メタデータ(topic、rounds)とタグ(AI議論、デモ)を設定
- 関連する処理をグループ化して分析しやすくする
実行方法
python langfuse_demo.py
Langfuseで確認
実行後、Langfuseで以下を確認できます:
作成されるトレース
- ai_discussionトレース: メイン処理(議論シミュレーション)
- analyze_sentimentトレース: 感情分析処理
合計2つの独立したトレースが作成されます。
1. トレース一覧画面
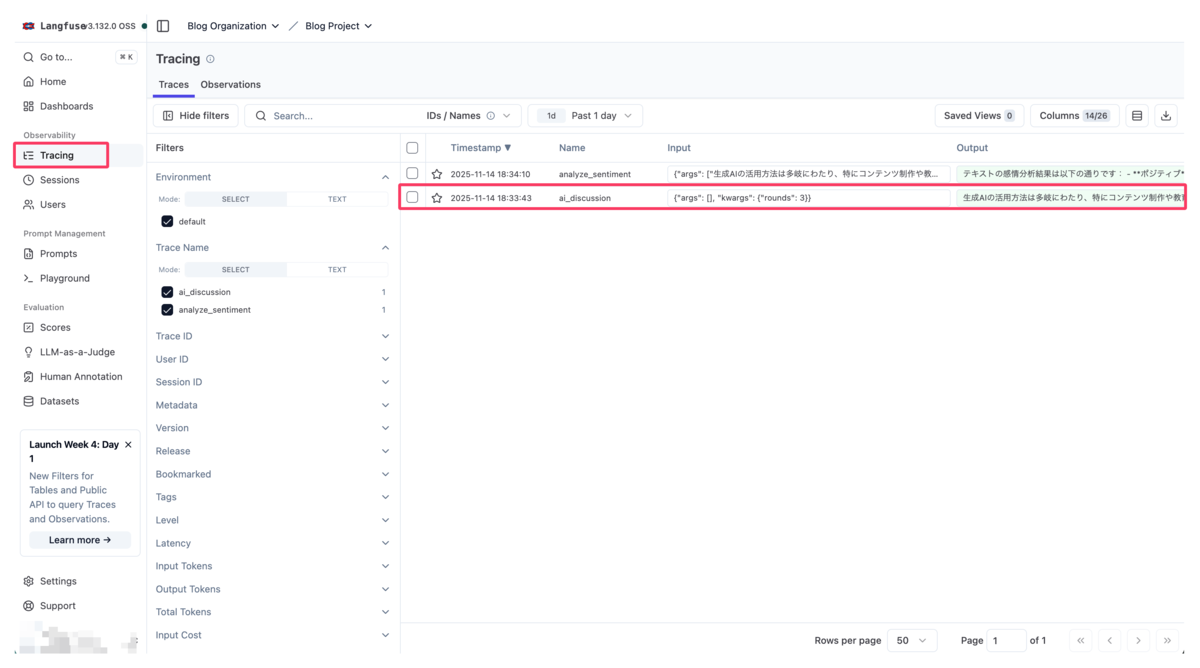
Tracingページでは、実行された全てのトレースが一覧で表示されます。トレースを選択することでトレース詳細を確認することができます。
2. トレース詳細画面
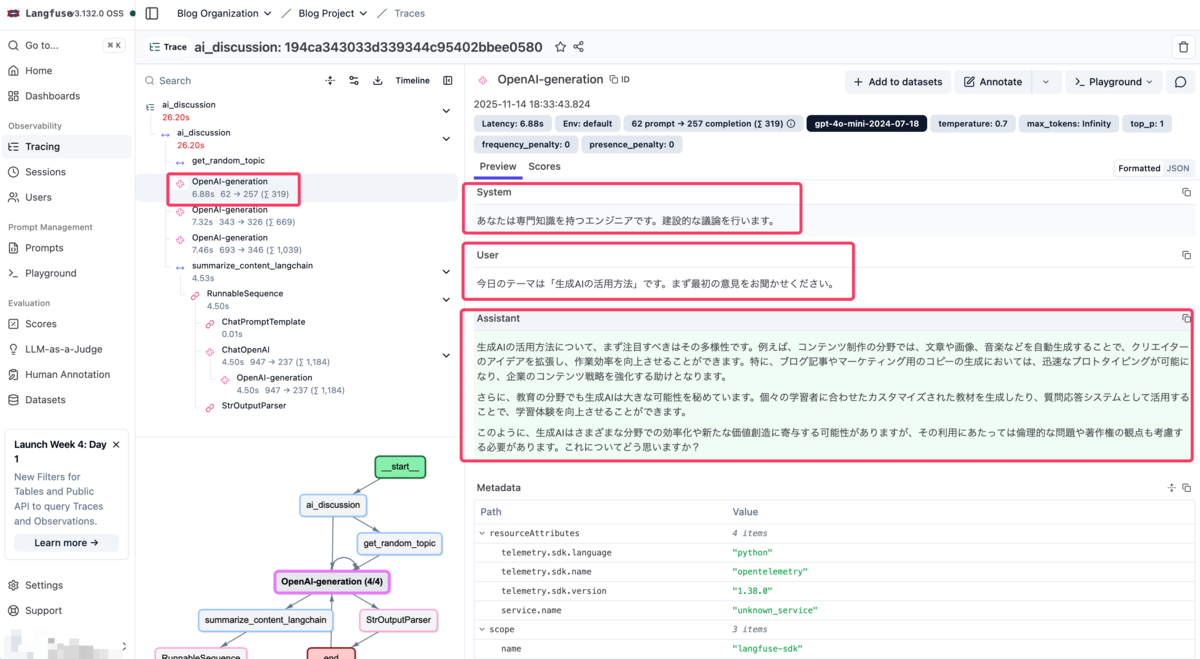
個別のトレースをクリックすると詳細が確認できます。この画面では:
- System: システムプロンプト
- User: 入力
- Assistant: AIからの応答
が順番に表示され、実際にLLMに送信されたプロンプトと応答の全容を確認できます。
3. トレースフロー図

処理の流れが視覚的なフロー図で表示されます。どの関数からどの関数が呼び出されたか、OpenAI APIやLangChainの処理がどこで実行されたかが一目で分かります。
4. メタデータとタグ
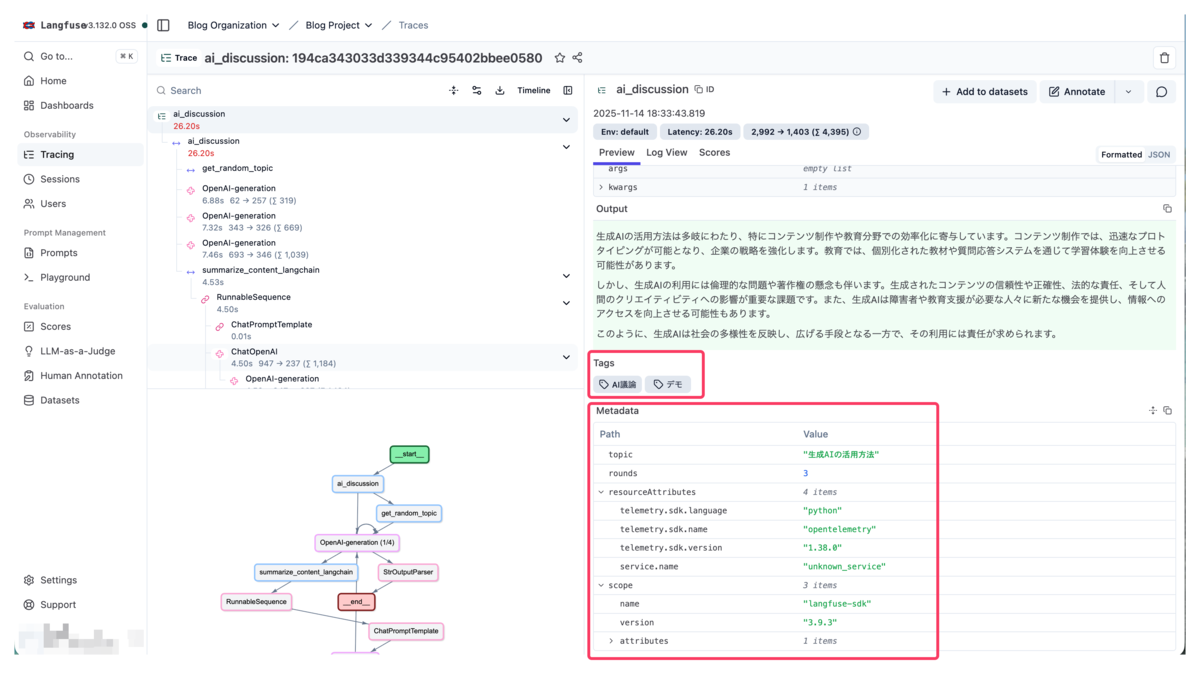
設定したメタデータ(topic、rounds)とタグ(AI議論、デモ)が表示されます。これにより関連する実行を簡単にグループ化して分析できます。
5. パフォーマンス分析
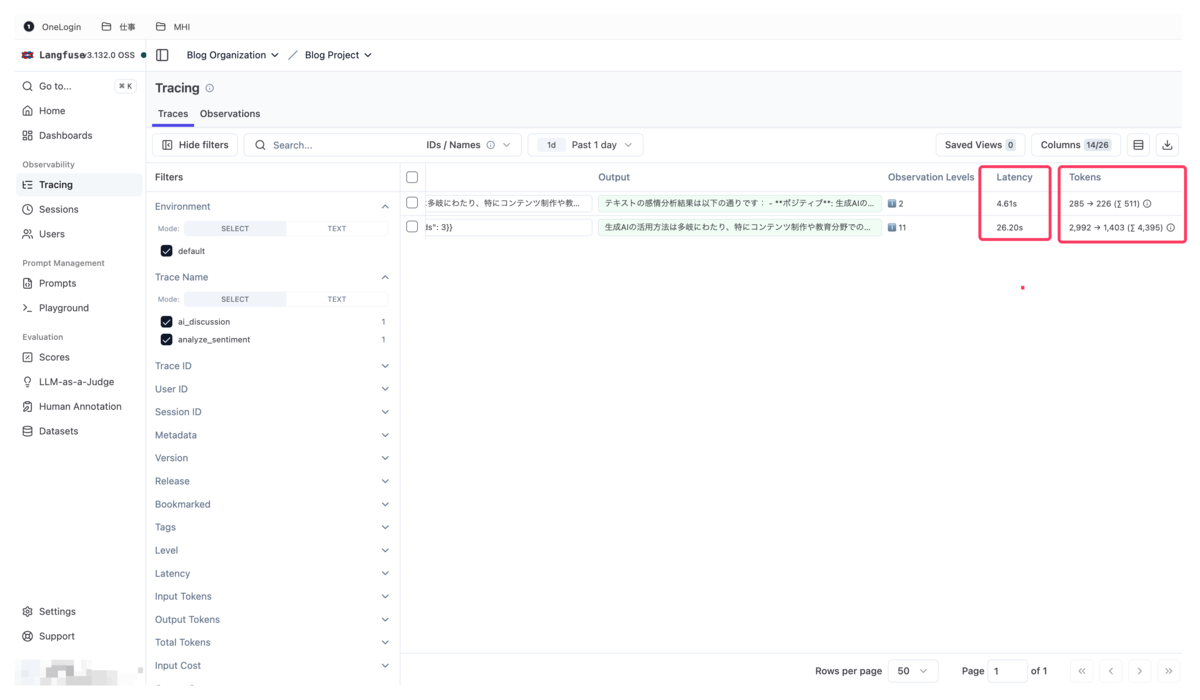
右側にはLatency(応答時間)とTokens(使用トークン数)が表示されます。どの処理がボトルネックになっているか、コストがどの程度発生したかを確認できます。
おわりに
今回は、AWSのサンプルリポジトリを使ってLangfuse v3をECS/Fargateにデプロイし、実際のPythonコードでトレース情報を送信する方法を紹介しました。
LLMアプリケーションでLangfuseを活用して、より効率的で透明性の高い開発・運用を実現してみてください!