

はじめに
アプリケーションサービス部の鎌田(義)です。
AWSを中心にデータ活用基盤を構築する際のデータ収集の一例としていくつかのパターンを紹介したいと思います。
データソースをRDBMSとし、RedshiftをDWHとして活用する場合を想定していますが、補足的に別のDWHを選択するパターンについても一部触れています。
前提
データソースはAuroraMySQLを例にしていますが、
収集パターンとしてはRDSやPostgresでもそこまで大きく違いはないかと思います。
AuroraとRedshiftは異なるAWSアカウントに存在することを想定した構成イメージとしています。
パターンの紹介をメインとしている為、パターン毎の詳細な実装方法には触れていません。
データ収集パターン
Redshift ZeroETL
構成イメージ
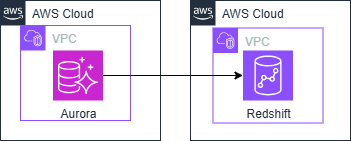
特徴
- 収集間隔の調整が可能
- AuroraMySQLの場合 (デフォルト0秒~432,000秒(5日)の範囲で設定可)
- ゼロETL対象とするテーブルのフィルタが可能
- 異なるAWSアカウントでもVPCピアリングなしで利用可
課金対象となる主な要素
- データ転送料金
- Redshift Serverlessの場合、RPUに応じた料金
- Aurora側のI/O料金
前提・考慮事項
- Redshift Serverlessまたは、RA3ノードタイプのみ利用可
- AuroraとRedshiftは同じリージョンに存在する必要がある
- 一部データ型に非対応
- DELETE/UPDATE CASCADE 参照テーブルに非対応
- DBクラスターパラメータグループの設定が必要
- Aurora MySQLの場合、Aurora MySQLバージョン3.05.2 以上が対応
構成検討時のポイント
- ETL開発工数は非常に少なく済む
- Redshift Serverless利用かつ、更新頻度の高い多数テーブルをリアルタイムに収集する場合など、料金が高額になる可能性あり
参考リンク
- 料金 - Amazon Redshift | AWS
- Amazon Redshift との Aurora ゼロ ETL 統合 - Amazon Aurora
- ゼロ ETL 統合 – Amazon Aurora と Amazon Redshift - AWS
- Amazon Redshift とのゼロ ETL 統合でサポートされているリージョンと Aurora DB エンジン - Amazon Aurora
Redshift FederatedQuery
構成イメージ
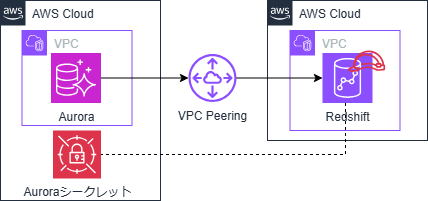
特徴
- Redshift上に外部スキーマを作成する
- RedshiftからAuroraに対してSELECT文が実行できる
課金対象となる主な要素
- データ転送料金
- Redshift Serverlessの場合、RPUに応じた料金
- Aurora側のI/O料金
- SecretsManagerシークレット
前提・考慮事項
- DBクラスターパラメータグループの設定が必要
- Aurora MySQLの場合、MySQLバージョン5.6以降のみが対応
- VPC間でIPアドレス範囲の重複がないこと
構成検討時のポイント
- 毎時全データを取得するような利用の場合、Aurora側に負荷がかかる
- 分析専用のレプリカとエンドポイントを用意して利用することを推奨
- 異なるAWSリージョン間でのデータ参照となる場合など、クエリ時のレイテンシが多少高くなる可能性がある
参考リンク
- Amazon Redshift Serverless での請求 - Amazon Redshift
- Amazon Redshift での横串検索を使用したデータのクエリの実行 - Amazon Redshift
- Amazon Redshift でフェデレーティッドデータにアクセスする際の考慮事項 - Amazon Redshift
- Redshift 横串検索を使用して、簡略化された ETL およびライブデータクエリソリューションを構築する | Amazon Web Services ブログ
DMS
構成イメージ
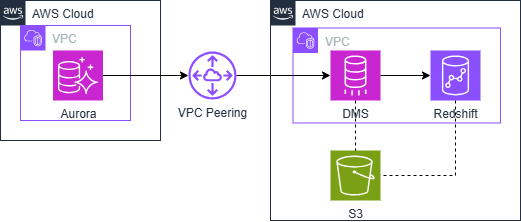 ※ソースにAurora/ターゲットにRedshiftを指定
※ソースにAurora/ターゲットにRedshiftを指定
特徴
課金対象となる主な要素
- データ転送料金
- Redshift Serverlessの場合、RPUに応じた料金
- レプリケーションインスタンス料金
- ストレージ料金(DMSが使用する)
前提・考慮事項
- DELETE/UPDATE CASCADE 参照テーブルに非対応
- DBクラスターパラメータグループの設定が必要
- VPC間でIPアドレス範囲の重複がないこと
構成検討時のポイント
- Redshiftへの個人情報(PII)などの格納がNGな場合や、DWH格納前に簡易的な加工が必要な場合などに対応可能
S3をターゲットとした別パターン
ターゲットにS3を指定し、S3へCDCファイルを格納することでデータレイクとしてS3を活用するパターン。
AthenaやSnowflakeなどをDWHとして使用することも可能となる為
初期フェーズではS3+Athena、次期フェーズでRedshiftへの移行を検討するなど柔軟性を持たせた構成も考えられる。
参考リンク
- 料金 - AWS Database Migration Service |AWS
- AWS Database Migration Serviceのターゲットとしての Amazon Redshift データベースの使用 - AWS データベース移行サービス
- AuroraからS3へのDMSを利用した継続的レプリケーション - サーバーワークスエンジニアブログ
GlueETL
構成イメージ
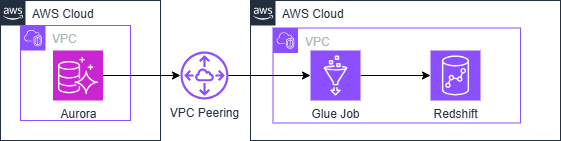
特徴
- 基本的にバッチ処理となりスケジュール実行したい場合は仕組み・設定が必要
- VisualETLを使ったノーコード開発も可能
- 高度な変換、加工処理が可能
- 対象となるテーブル毎に開発が必要
課金対象となる主な要素
- データ転送料金
- Redshift Serverlessの場合、RPUに応じた料金
- Aurora側のI/O料金
- GlueJob実行料金
前提・考慮事項
- VPC間でIPアドレス範囲の重複がないこと
構成検討時のポイント
- 複雑な加工処理が必要なケースや上記いずれのパターンも採用が困難な場合の候補
参考リンク
SnapshotExport
構成イメージ
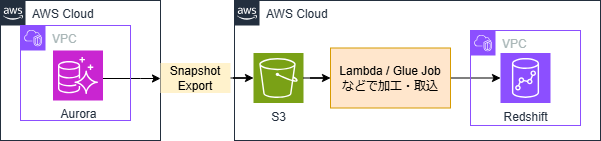
特徴
- 基本的にバッチ処理となりスケジュール実行したい場合は仕組み・設定が必要
- COPYでRedshiftへ取込、またはGlueなどのリソースを利用することで高度な変換を行うことも可能
- エクスポート対象のデータベース、スキーマ、テーブルを指定可能
課金対象となる主な要素
- データ転送料金
- Redshift Serverlessの場合、RPUに応じた料金
- Snapshotエクスポート料金
- ストレージ料金(Snapshotエクスポート先)
- 取込に利用するリソース料金
前提・考慮事項
- なし
構成検討時のポイント
- スナップショットをDBバックアップとしてS3に保存しており、そのまま分析用に流用するケース
- データ量増加に比例してエクスポート時間が増加する
- Export先のS3保存パスがエクスポート毎に都度変わる為、定期的な収集には工夫が必要
外部スキーマとして参照する別パターン
外部スキーマを作成して、Redshift SpectrumやAthenaからS3に格納したファイルを参照することが可能。
参考リンク
- AuroraからS3へのDBクラスターデータのエクスポート - サーバーワークスエンジニアブログ
- Amazon S3 への DB クラスタースナップショットデータのエクスポート - Amazon Aurora
おわりに
紹介させて頂いたパターンが全てという訳ではもちろんないのですが、
基本的なパターンとして5つの例を紹介しました。
また、AWSのみで利用するケースという前提となりますので
マルチクラウドで利用する場合などは、サードパーティ製品やOSS製品も有力な候補となるかと思います。
本記事がどなたかの参考になれば幸いです。
鎌田 義章 (執筆記事一覧)
2023年4月入社 アプリケーションサービス本部ディベロップメントサービス3課