

はじめに
アプリケーションサービス部の鎌田(義)です。
RDBMSのデータを分析に活用したい、など
本番稼働しているテーブルへ影響を与えることなくデータアクセスをしたいケースがあるかと思います。
その方法の一つとして
本エントリーでは、AuroraのDBクラスターデータエクスポートを使用してS3バケットにデータをエクスポートしてみます。
その後、GlueETL及びAthenaからS3のデータを参照するまでの流れを検証したいと思います。
前提
以下の環境を使用、構築済の前提で進めます。
AuroraMySQL情報
- Engine: Aurora MySQL
- Version: 8.0.mysql_aurora.3.05.2
検証で使用するテーブル
mysql> SELECT * FROM users; +---------+------------+-----------+-------------------+---------------------+---------------------+ | user_id | first_name | last_name | email | created_at | updated_at | +---------+------------+-----------+-------------------+---------------------+---------------------+ | 1 | user | 0 | user0@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | user | 1 | user1@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | user | 2 | user2@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | user | 3 | user3@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | user | 4 | user4@example.com | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +---------+------------+-----------+-------------------+---------------------+---------------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM posts; +---------+---------+--------+----------+---------------------+---------------------+ | post_id | user_id | title | content | created_at | updated_at | +---------+---------+--------+----------+---------------------+---------------------+ | 1 | 3 | title0 | content0 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | 1 | title1 | content1 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | 5 | title2 | content2 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | 1 | title3 | content3 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | 3 | title4 | content4 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +---------+---------+--------+----------+---------------------+---------------------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM comments; +------------+---------+---------+----------+---------------------+---------------------+ | comment_id | post_id | user_id | comment | created_at | updated_at | +------------+---------+---------+----------+---------------------+---------------------+ | 1 | 2 | 2 | comment0 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 2 | 2 | 3 | comment1 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 3 | 3 | 1 | comment2 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 4 | 3 | 4 | comment3 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | | 5 | 5 | 3 | comment4 | 2024-08-11 23:37:41 | 2024-08-11 23:37:41 | +------------+---------+---------+----------+---------------------+---------------------+ 5 rows in set (0.01 sec)
本エントリーで触れないこと
手動でのS3エクスポート実行手順の紹介のみとし定期的に実行する仕組みまでは紹介しませんが、
以下のリポジトリで Lambdaを使用してSnapshotをS3にエクスポートするCDKアプリケーションのサンプルが公開されていますので参考としてリンクを貼っておきます。
S3エクスポート実行手順
各リソースの構築については、基本的にはCLIを使用した手順を記載します。
S3エクスポートタスク作成に必要なリソースの作成
後続で使用する為、AWSアカウントIDを変数にセットしておきます。
AWS_ACCOUNT_ID=`aws sts get-caller-identity \ --query Account \ --output text`
DBクラスターデータ保存先S3バケットの作成
aws s3api create-bucket \ --bucket rds-export-to-s3-${AWS_ACCOUNT_ID} \ --region ap-northeast-1 \ --create-bucket-configuration LocationConstraint=ap-northeast-1
S3エクスポートが使用するIAMロールの作成
後続で使用する為、作成したIAMロールのARNを変数にセットします。
IAM_ROLE_ARN=`aws iam create-role \ --role-name rds-export-to-s3-role \ --assume-role-policy-document \ '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }' \ --query Role.Arn \ --output text`
IAMロールに権限をアタッチ
DBクラスターデータ保存バケットへのアクセス権限を付与します。
aws iam put-role-policy \ --role-name rds-export-to-s3-role \ --policy-name rds-export-to-s3-policy \ --policy-document \ "{ \"Version\": \"2012-10-17\", \"Statement\": [ { \"Sid\": \"ExportPolicy\", \"Effect\": \"Allow\", \"Action\": [ \"s3:ListBucket\", \"s3:PutObject*\", \"s3:GetObject*\", \"s3:DeleteObject*\", \"s3:GetBucketLocation\" ], \"Resource\": [ \"arn:aws:s3:::rds-export-to-s3-${AWS_ACCOUNT_ID}\", \"arn:aws:s3:::rds-export-to-s3-${AWS_ACCOUNT_ID}/*\" ] } ] }"
KMSキーの作成
後続で使用する為、作成したKMSキーのARNを変数にセットします。
検証目的の為、今回はキーポリシーはデフォルトのまま使用します。
KMS_KEY_ARN=`aws kms create-key \ --query KeyMetadata.Arn\ --output text`
S3エクスポートタスク
S3エクスポートタスク実行
<DB_CLUSTER_ARN>を自身のクラスターのARNに置き換えます。
aws rds start-export-task \ --export-task-identifier rds-export-to-s3-task-yyyymmdd \ --source-arn <DB_CLUSTER_ARN> \ --s3-bucket-name rds-export-to-s3-${AWS_ACCOUNT_ID} \ --iam-role-arn ${IAM_ROLE_ARN} \ --kms-key-id ${KMS_KEY_ARN}
コンソールで確認すると、以下のようなエクスポートのステータスが確認できます。

CLIからも進捗状況を確認できます。
aws rds describe-export-tasks \ --export-task-identifier rds-export-to-s3-task-yyyymmdd
検証では15件程度のレコード数の為、あまり参考にはなりませんが、
エクスポートタスクの起動から開始まで15分程度、開始から完了まで約2分程度かかっていました。
エクスポートファイル確認
エクスポートが完了すると、S3バケットにエクスポート名がついたプレフィクス配下に
以下のような形式でParquetファイルが作成されます。
<BucketName>/<ExportIdentifier>/<DatabaseName>/<SchemaName.TableName>/<BatchIndex>/**.parquet
※ファイル名命名規則
GlueETLでデータ確認
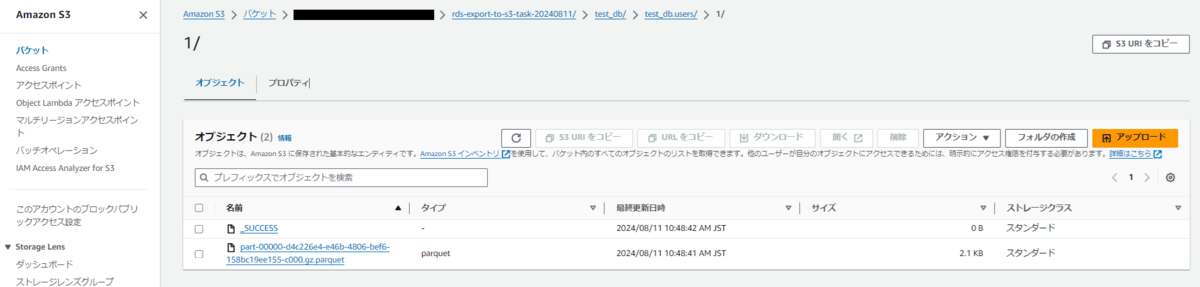
データ確認
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) users_dyf = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={"paths": ["s3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.users/"]}, format="parquet", ) users_dyf.printSchema() users_df = users_dyf.toDF() users_df.orderBy("user_id").show() posts_dyf = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={"paths": ["s3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.posts/"]}, format="parquet", ) posts_dyf.printSchema() posts_df = posts_dyf.toDF() posts_df.orderBy("post_id").show() comments_dyf = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={"paths": ["s3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.comments/"]}, format="parquet", ) comments_dyf.printSchema() comments_df = comments_dyf.toDF() comments_df.orderBy("comment_id").show() job.commit()
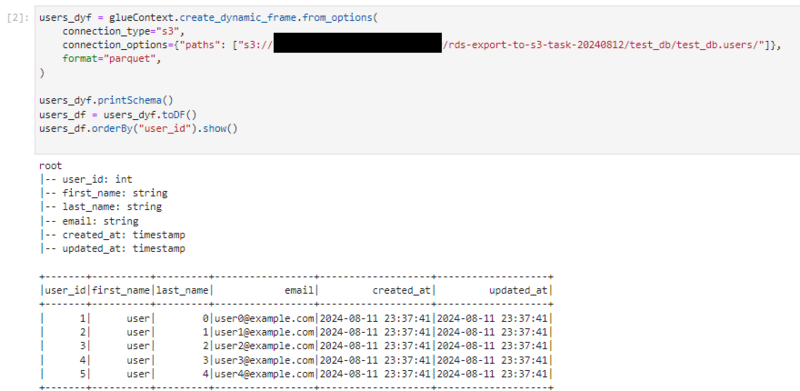
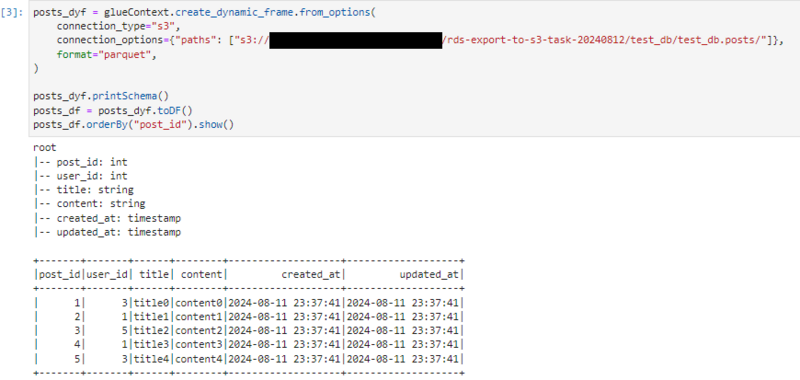
Notebookでの実行結果
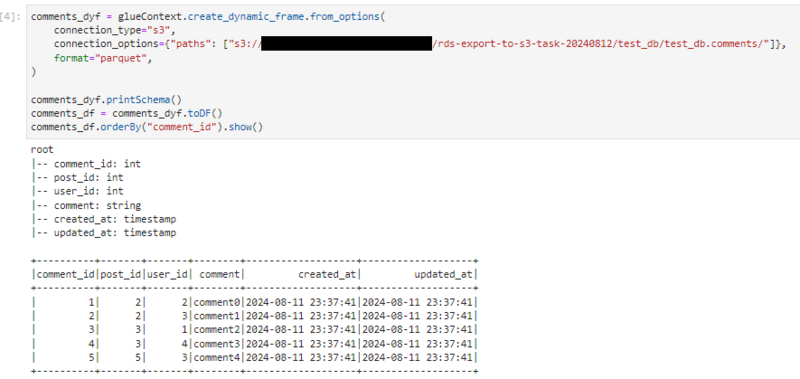
Athenaでデータ確認
AthenaからS3に格納したファイルを確認する為、テーブルを作成する必要がありますが
今回は簡単の為、Glueクローラーを使用せずAthenaクエリからテーブルを作成します。
データベース作成
CREATE DATABASE IF NOT EXISTS rds_export_db;
テーブル作成
users
CREATE EXTERNAL TABLE rds_export_db.users ( `user_id` INT, `first_name` STRING, `last_name` STRING, `email` STRING, `created_at` TIMESTAMP, `updated_at` TIMESTAMP ) STORED AS PARQUET LOCATION 's3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.users/';
posts
CREATE EXTERNAL TABLE rds_export_db.posts ( `post_id` INT, `user_id` INT, `title` STRING, `content` STRING, `created_at` TIMESTAMP, `updated_at` TIMESTAMP ) STORED AS PARQUET LOCATION 's3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.posts/';
comments
CREATE EXTERNAL TABLE rds_export_db.comments ( `comment_id` INT, `post_id` INT, `user_id` INT, `comment` STRING, `created_at` TIMESTAMP, `updated_at` TIMESTAMP ) STORED AS PARQUET LOCATION 's3://<BUCKET_NAME>/rds-export-to-s3-task-20240812/test_db/test_db.comments/';
データ確認
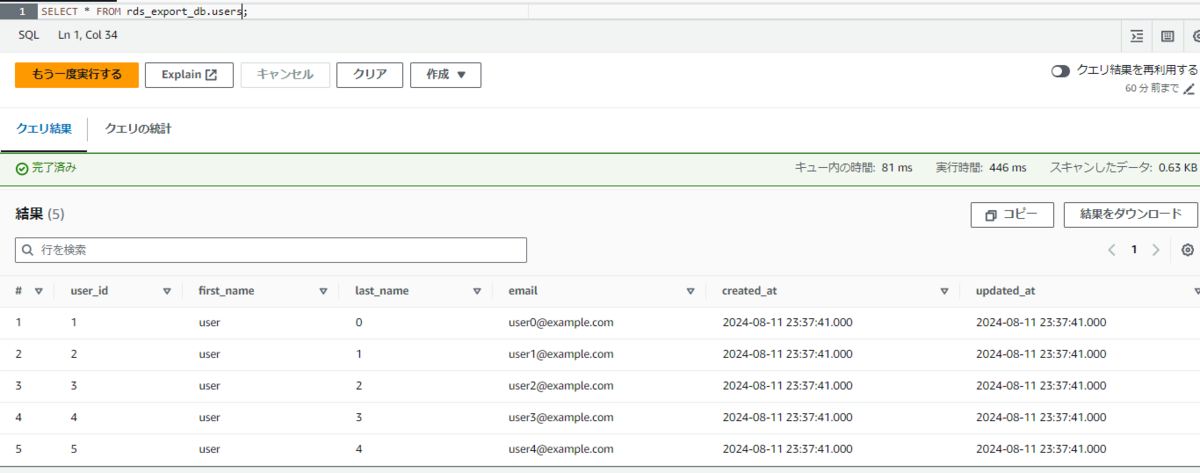
SELECT * FROM rds_export_db.users;
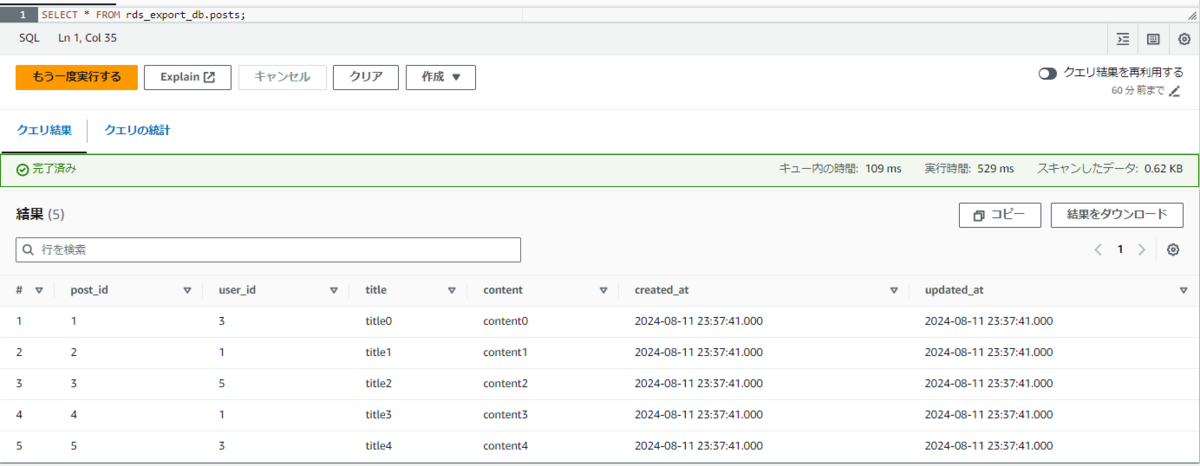
SELECT * FROM rds_export_db.posts;
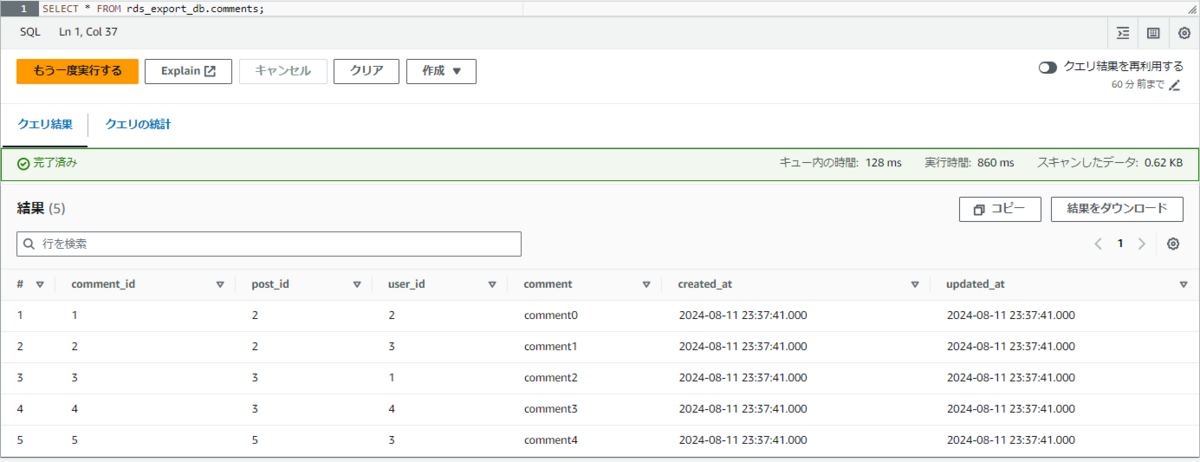
SELECT * FROM rds_export_db.comments;
Glueクローラーの設定例
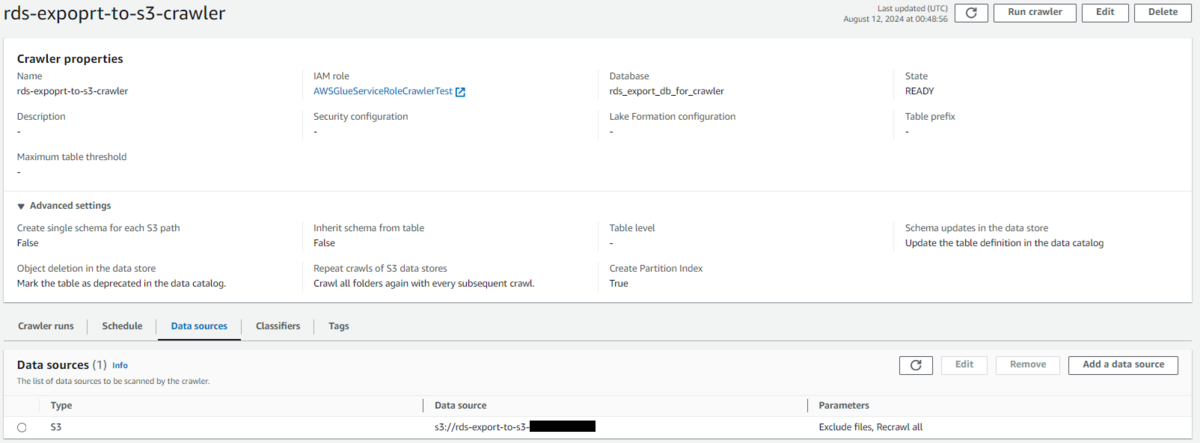
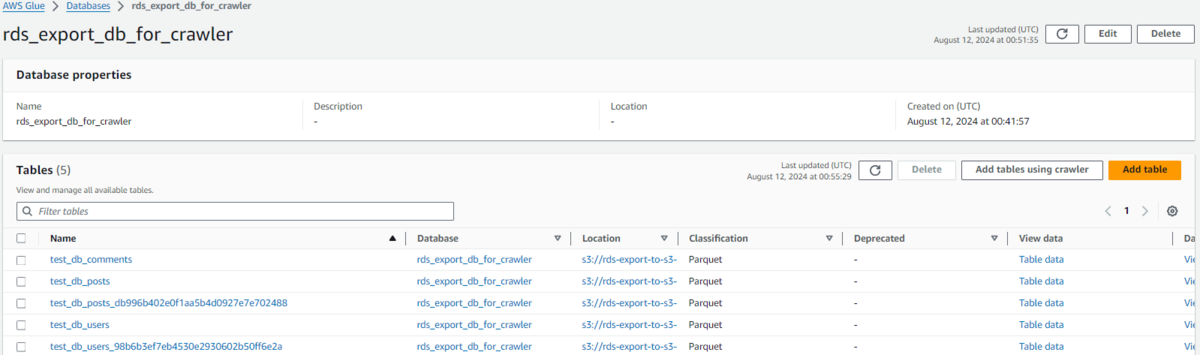
仮に日次でS3へエクスポートしクローラーを実行すると、初回はtest_db_usersテーブルが作成されますが
既に同名のテーブルが存在する場合、同名のテーブルを作成することはできない為、
2回目以降はtest_db_users_98b6b3ef7eb4530e2930602b50ff6e2aのようなハッシュ文字列がサフィックスに追加されます。
※クローラーの仕組み
おわりに
今回は、S3エクスポート機能を利用したデータ移行をご紹介しました。
日次など定期的にエクスポートした上で、GlueやAthenaで扱う際は
都度新規テーブルとして扱う形になる為、リアルタイム性が求められない場合有用かと思います。
また、テーブル側でのスキーマ変更やETL処理の冪等性など、担保しやすく扱いやすい面もあるのかなと思います。
データの送信量によってエクスポート料金が決まる為、事前に見積もりしておくことをおすすめします。
また、データ保存料金の面でもS3バケットのライフサイクルポリシーも合わせて検討するのが良いかと思います。
最後までご覧頂きありがとうございました。
次回は、DMSを使用したS3への継続的なレプリケーションを検証したいと思います。
参考
https://www.youtube.com/watch?v=lyNGeDg6EII
鎌田 義章 (執筆記事一覧)
2023年4月入社 アプリケーションサービス本部ディベロップメントサービス3課