

こんにちは、技術2課の紅林です。ラバーはソフトが正義。学生の頃からタキネス チョップを愛用しています。最近はタキネス チョップ2も気に入っています。
さて、今回、Slackの各チャンネルの利用頻度を可視化するシステムを試作してみましたので、その試みをご紹介します。
はじめに
こちらの記事等でも言及されている通り、サーバーワークスではコミュニケーションツールにSlackを活用しています。各プロジェクト、社内タスクフォース、部活毎にチャンネルを作成しているため、チャンネル数はかなりの数になっています。したがって、もはやどのくらいのチャンネルがアクティブに利用されており、それらがどのくらい利用されているか把握するのは困難です。
そこで、今回、各チャンネルの利用頻度を可視化するシステムを試作してみました、
各チャンネルの利用頻度の可視化結果
各チャンネルの利用頻度を可視化してみた結果をまずはじめに以下にお見せします。今回、BIツールとしてTableau Desktop(以下、Tableau)を使用してみました。データさえあれば、様々な指標での可視化が可能ですが、今回は利用頻度の指標のサンプルとして、「各チャンネルの時系列の投稿数」、「特定時点から現時点までの総投稿数とそれらを投稿したユーザの内訳」を取り上げています。
以下は「各チャンネルの時系列の投稿数」です。一つの折れ線が一つのチェンネルを示します。活動が活発な部活動や、突発的に激しく動いているプロジェクト等がひと目で分かりますね。また、長期的にデータを取得すればチャンネルごとの各時間帯における活動の傾向等も掴めそうです。

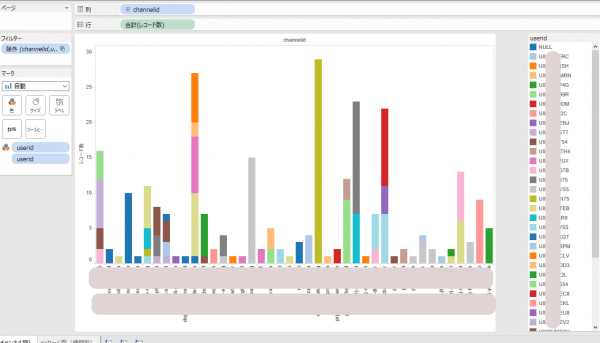
以下は「特定時点から現時点までの総投稿数とそれらを投稿したユーザの内訳」です。各棒グラフがチェンネルを、色はユーザを示します。投稿が多くのユーザで占められているチャンネルは、より活発に利用されている感じがしますね。逆に最近はサーバーワークスでも分報なるものが流行っており、一人でつぶやき続けているチャンネルも結構あったりするのが分かります。
システム概要
さて、以降は、AWSを中心に上記の可視化を行った仕組みをご紹介します。
構成図
まずはじめに、構成図を以下に示します。データとなるSlackの投稿の取得はAWS Lambda(以下、Lambda)からSlack APIの利用により行います。取得したメッセージをLambdaによりS3 Bucketに格納し、格納したデータをCOPYコマンドを用いてRedshiftにロードします。Redshiftに格納されたデータをTableauから利用することにより、可視化を行います。
各処理の概要
システムの各要素の概要を以下に記載します。
Slackからのメッセージの取得
Lambdaのスケジュールイベントにより、特定時間(今回の例では15分前)から現時点までの各チャンネルの全てのメッセージを取得します。Slack APIの利用により、取得します。APIのメソッドとして、channe.list、channel.historyを利用します。
上記の通りにメッセージを取得するnode.jsのコードのサンプルを以下に示します(主要部分のみ抜粋)。実行しているSlack APIが非同期で実行されるようなので、確実に全てのチャンネルのメッセージを取得するため、同期処理を行えるasyncを利用しています。
var Slack = require('slack-node');
var async = require("async");
apiToken = "xxxxxxxx";
slack = new Slack(apiToken);
slack.api("channels.list", function (err, response) {
async.each(response.channels, function (e, callback) {
slack.api("channels.history", {channel: e.id, oldest: getUnixTime15mBefore()}, function (err, response) {
if (err)
console.log(err);
if(response.messages.length != 0){
//必要な処理(メッセージの配列への格納等)を行う
}
callback();
});
}
SlackのメッセージのS3 Bucket、Redshiftへの保存
前項目で取得したメッセージをS3 Buekctにアップロードし、Redshiftにロードします。
Redshiftのテーブル定義
Redshiftのテーブルについてですが、Slack APIのchannel.historyでメッセージを取得すると、リアクション等メッセージの本文以外にも様々な情報を取得出来ますが、今回は単純化のため、以下のとおり、メッセージのチャンネル、投稿したユーザ、メッセージ本文、タイムスタンプの必要最低限の要素のみ定義します。
# create table message (channelid varchar(100), userid varchar(30),text varchar(4000), ts timestamp);
Redshiftへのデータのロード
取得したメッセージはRedshiftへロード可能な形式にパースした上でS3 Bucketに格納し、COPYコマンドによりRedshiftにデータをロードします。今回はAPIから取得したメッセージからのパースが容易のため、JSON形式でのロードを行います。
これには、COPYコマンドがJSONデータを解析するのにJSONPathsファイルが用いられるため、上記のテーブル定義と対応する以下のようなJSONPathsファイルを作成し、S3 Bucketにアップロードしておきます。
{
"jsonpaths":
[
"$['id']",
"$['userid']",
"$['text']",
"$['ts']"
]
}
JSON形式のパースしたメッセージをS3 Bucketにアップロードし、Redshiftにロードするコード(主要部分のみ抜粋)を以下に示します。従来、COPYコマンドの実施にはクレデンシャルの情報を付与して実行する必要がありましたが、先日COPYでIAMロールを指定可能になったアップデートがありましたので、コードには直接クレデンシャル情報は記載せず、IAMロールを作成しRedshiftクラスタに割り当てた上で実施するのがよいでしょう。
var s3Key = 'channels.history' + (date.getTime() / 1000);
var s3 = new AWS.S3({params: {Bucket: '<BucketName>', Key: s3Key}});
s3.upload({Body: messageStr}, function (err, data) {
if(err) console.log(err);
var conString = "tcp:<user>:<password>@<endpoint>:<port>/<ClusterName>";
var client = new pg.Client(conString);
client.connect(function(err){
if(err) console.error(err);
});
var query = client.query("copy message from 's3://<BucketName>/" + s3Key + "'' json as 's3://<bucket>/jsonpaths'");
query.on('error', function(error){
console.log(error);
});
query.on('end', function(row, error){
client.end();
context.succeed(event.key1);
});
});
Tableauで可視化
Redshiftまでデータを格納できたら、後はTableauで好きなように可視化しましょう。
おわりに
今回、各チャンネルの利用頻度をTableauで可視化するシステムを試作し、そのシステム概要をご紹介しました。
ラバーはソフトに限ります。