

飛行機代を省略したのをいいことに、またIYHしたカメラマンの竹永です。
次の目標は三脚です。次の次の目標は洗濯機でしょうか。
前回、前々回とFluentdを扱いましたが、S3に入っていくデータは貯めるだけで何にも使っていませんでした。
今回は、色々なところにあるデータを色々なところへ一気にガガッと突っ込めるEmbulkをご紹介します。
今日のレシピ
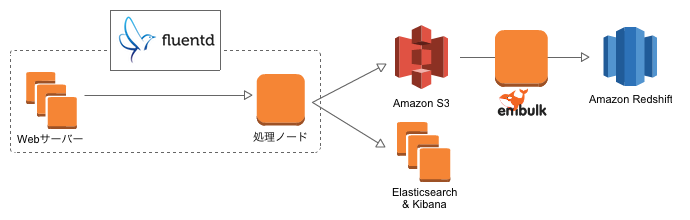
どんどん足されていった構成図ですが、今回は下図のような構成を作っていきます。
RedshiftとEmbulkが増えました。EmbulkはどこかのEC2にインストールします。
どこかのEC2で使うソフトウェアのバージョンは下記の通り。
- amzn-ami-hvm-2015.09.0.x86_64-gp2 (ami-9a2fb89a)
- Java 1.7.0_91
- Embulk 0.7.9
Embulkってなにもの
つぶらな瞳のシャチがかわいいバルクデータローダーです。
Fluentdのバルク(バッチ)版と考えるのが一番簡単です。
Embulkは、色々なところにあるデータを一気に読み込んで、色々な格納先に一気に流し込みます。
自分でやるととてつもなく面倒くさい、エラー処理・リジューム・クレンジング・繰り返し処理を全部やってくれます。
「俺は意地でもFluentdだけでデータを転送するんだ!」という方は、中の人が用意してくれたstdinプラグインを使うと幸せかもしれません。
Fluentdはもともとバルクロードするツールではないので、おすすめはしません。おすすめはしません。大切なことなので2回(ry
ロゴがかわいいソフトウェアに悪いソフトウェアなんてありません。きっとそうだ。
なんでRedshift?
Redshiftが居るだけで、一般的なBIツールでデータにアクセスしやすくなります。
というのは建前で、Redshiftって書くだけで誰かしらが釣れそうな気がしたためです。
Redshiftにデータを挿入する一番簡単でシンプルな方法としては、Fluentdプラグインを使ったデータ挿入です。
しかし、Fluentdを分散していくとRedshiftストレージ内に入っているデータのソート順がカオスになる可能性があり、VACUUM祭りを開催しなければならない可能性もでてきます。
VACUUMをサボるために、意地でも時系列順でデータを挿入したかったので、Embulkをつかって綺麗かつ一気にデータを流し込みます。
インストール
公式ドキュメントのQuick Startに載っているコマンドを黒い画面にコピペします。
実際にコピペした時の様子は下記の通り。
$ curl --create-dirs -o ~/.embulk/bin/embulk -L "http://dl.embulk.org/embulk-latest.jar"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
100 37.4M 100 37.4M 0 0 2157k 0 0:00:17 0:00:17 --:--:-- 4287k
$ chmod +x ~/.embulk/bin/embulk
$ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
$ source ~/.bashrcバージョンは下記のコマンドで確認できます。
$ embulk --version
embulk 0.7.9次に必要なプラグインをインストールします。
S3からJSONL形式のファイルを読み込んでRedshiftへロードしたいので、下記3つのプラグインをインストールする必要があります。
インストールするコマンドは下記の通りです。
$ embulk gem install embulk-input-s3
$ embulk gem install embulk-parser-jsonl
$ embulk gem install embulk-output-redshiftあっさり終わったので設定します。
設定ファイルづくり
ここから本気を出す必要があります。
Embulkはやりたいこと毎に、YAML形式の設定ファイルを作ってそれを読み込ませます。
今回はEmbulkのドキュメントとかプラグインのドキュメントやドキュメントやドキュメントを使って、下記のような設定ファイルを作りました。
# s3-to-redshift.yml
in:
type: s3
bucket: example-bucket
path_prefix: access-logs/
endpoint: s3-ap-northeast-1.amazonaws.com
access_key_id: AKIAACCESSKEYHOGEFUGA
secret_access_key: hereissecretKey/hogefugahungaaaaaaaa
out:
type: redshift
host: example-redshift.abcdefghijklmn.ap-northeast-1.redshift.amazonaws.com
user: example
password: userpassword
database: exampledb
table: www_access_log
access_key_id: AKIAACCESSKEYHOGEFUGA
secret_access_key: hereissecretKey/hogefugahungaaaaaaaa
mode: insert
iam_user_name: exampleiamuser
s3_bucket: example-bucket
s3_key_prefix: embulk-redshift-tmp/書くのが面倒な項目があったので色々と必須パラメーターが抜けて落ちており、このままでは使えたもんじゃありません。
しかし、Embulkは適当に書いた設定ファイルと実際に読み込んだデータを元に、適切な設定を推測してくれます。シャチえらい。
実際に推測させるときは下記のようなコマンドを実行します。 -g jsonl は推測に使うプラグインをカンマ区切りで指定します。たぶん。
$ embulk guess -g jsonl s3-to-redshift.yml
2015-11-16 09:07:58.043 +0000: Embulk v0.7.9
2015-11-16 09:07:59.315 +0000 [INFO] (guess): Loaded plugin embulk-input-s3 (0.2.3)
2015-11-16 09:08:00.519 +0000 [INFO] (guess): Loaded plugin embulk/guess/gzip from a load path
2015-11-16 09:08:00.532 +0000 [INFO] (guess): Loaded plugin embulk/guess/csv from a load path
2015-11-16 09:08:00.548 +0000 [INFO] (guess): Loaded plugin embulk-parser-jsonl (0.0.1)
in:
type: s3
bucket: example-bucket
path_prefix: access-logs/
endpoint: s3-ap-northeast-1.amazonaws.com
access_key_id: AKIAACCESSKEYHOGEFUGA
secret_access_key: hereissecretKey/hogefugahungaaaaaaaa
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: CRLF
type: jsonl
schema:
- {name: host, type: string}
- {name: user, type: string}
- {name: method, type: string}
- {name: path, type: string}
- {name: code, type: string}
- {name: size, type: string}
- {name: referer, type: string}
- {name: agent, type: string}
- {name: time, type: string}
out: {type: redshift, host: 'example-redshift.abcdefghijklmn.ap-northeast-1.redshift.amazonaws.com',
user: example, password: userpassword, database: exampledb, table: www_access_log, access_key_id: AKIAACCESSKEYHOGEFUGA,
secret_access_key: hereissecretKey/hogefugahungaaaaaaaa, mode: insert, s3_bucket: example-bucket,
s3-key-prefix: embulk-redshift-tmp/}
Use -o PATH option to write the guessed config file to a file.一番下の行で怒られているように、推測したらとっととファイルに書き込むのが良いようです。
が、僕は僕のスタイルで行きます。
Redshiftの設定部分が残念なことになっていますね。
ドジっ子シャチかわいい。
さて、推測結果を元に設定ファイルを書き換えます。
in をコピペして schema に適切な型を書くだけで完成です。
in:
type: s3
bucket: example-bucket
path_prefix: access-logs/
endpoint: s3-ap-northeast-1.amazonaws.com
access_key_id: AKIAACCESSKEYHOGEFUGA
secret_access_key: secretKeyhogefugahungaaaaaaaa
decoders:
- {type: gzip}
parser:
type: jsonl
charset: UTF-8
newline: CRLF
schema:
- {name: host, type: string}
- {name: user, type: string}
- {name: method, type: string}
- {name: path, type: string}
- {name: code, type: long}
- {name: size, type: long}
- {name: referer, type: string}
- {name: agent, type: string}
- {name: time, type: timestamp, time_format: '%Y-%m-%dT%H:%M:%S%z'}
out:
type: redshift
host: example-redshift.abcdefghijklmn.ap-northeast-1.redshift.amazonaws.com
user: example
password: userpassword
database: exampledb
table: www_access_log
access_key_id: AKIAACCESSKEYHOGEFUGA
secret_access_key: hereissecretKey/hogefugahungaaaaaaaa
mode: insert
iam_user_name: example-iamuser
s3_bucket: example-bucket
s3_key_prefix: embulk-redshift-tmp/Redshiftのテーブルを作る
Embulkが推測してくれたおかげで、Redshiftのテーブルも作りやすくなりました。
と、いうことでRedshift上にテーブルを作成します。
今回作ったのは下記のようなテーブル。
分散キーのことは考えていなかったり、列圧縮の指定をしてなかったりとかなり適当です。
CREATE TABLE www_access_log(
host VARCHAR(255),
"user" VARCHAR(30),
method VARCHAR(10),
path VARCHAR(MAX),
code SMALLINT,
size BIGINT,
referer VARCHAR(MAX),
agent VARCHAR(MAX),
time TIMESTAMP
) SORTKEY(date);なお、設定ファイルに書かれた列名とテーブルの列名が一致していないと、その列は空白になります。
試しに動かす
指定した設定ファイルが正しく動くかどうかを試すことができます。
出力テストは行わないので注意。
$ embulk preview s3-to-redshift.yml
2015-11-16 09:32:58.238 +0000: Embulk v0.7.9
2015-11-16 09:32:59.474 +0000 [INFO] (preview): Loaded plugin embulk-input-s3 (0.2.3)
2015-11-16 09:32:59.514 +0000 [INFO] (preview): Loaded plugin embulk-parser-jsonl (0.0.1)
+-----------------+-------------+---------------+--------
| host:string | user:string | method:string | (ry
+-----------------+-------------+---------------+--------
| 123.456.789.012 | - | GET | …
| 123.456.789.012 | - | GET | …
| 123.456.789.012 | - | GET | …
| 123.456.789.012 | - | GET | …
| 123.456.789.012 | - | GET | …
| 123.456.789.012 | - | GET | …
以下省略。10秒以上応答が返ってこない時や、Error: No input records to preview と怒られるときは、何か間違えている可能性が大です。
回線がよほど遅くなければ、数秒でプレビューが表示されます。
よくやる間違いとしては、日付のフォーマットを間違えていたり、指定を忘れていたり、キャスト出来ない型を指定していたりなどがあります。
プラグインがデバッグログを出力しない場合、 -l debug を指定してもEmbulkが真面目に仕事をしている姿しか見えてこないので、気長に問題調査しましょう。
Redshiftにいれる
Previewができればほぼ完成です。
設定ファイルのバックアップを取って、Redshiftにガガッといれましょう。
$ cp s3-to-redshift.yml s3-to-redshift.yml.orig
$ embulk run s3-to-redshift.yml -o s3-to-redshift.yml-o で設定ファイルを書き出しているのは、最終読み込み位置を設定ファイルに記録する必要があるためです。
今回の設定だと、Redshiftへの書き込みが成功した時点で設定ファイルが更新されるので、同じファイルを2回書き込んだりすることが無くなります。
定期的に実行したい場合は上記の embulk run コマンドをcronに仕込めば勝手に動くはずです。
おわり
Redshiftに入れさえすれば、あとは煮るなり焼くなり好きにできます。 
…最初の目的がデータ分析だったのを今思い出しました。やばい。