

はじめに
企業が保有する情報資産の大半は非構造化データであると言われています。情報資産に隠された(埋もれた)データを整理して、人またはシステムが利用できるようにすることで RAG のような単なる情報検索容易性に留まることなく(または RAG の精度を向上させる前処理として)、情報の利活用のステージが1段階上がると考えられます。
情報資産の利活用を1歩進めるために、非構造化データから特定のデータを抽出し構造化データとして扱うことが重要になってきます。本記事ではテキスト、画像、動画等の非構造化データから特定の情報を抽出し、構造化できる Amazon Bedrock の Data Automation と呼ばれる機能について解説します。
Bedrock Data Automation (BDA) とは
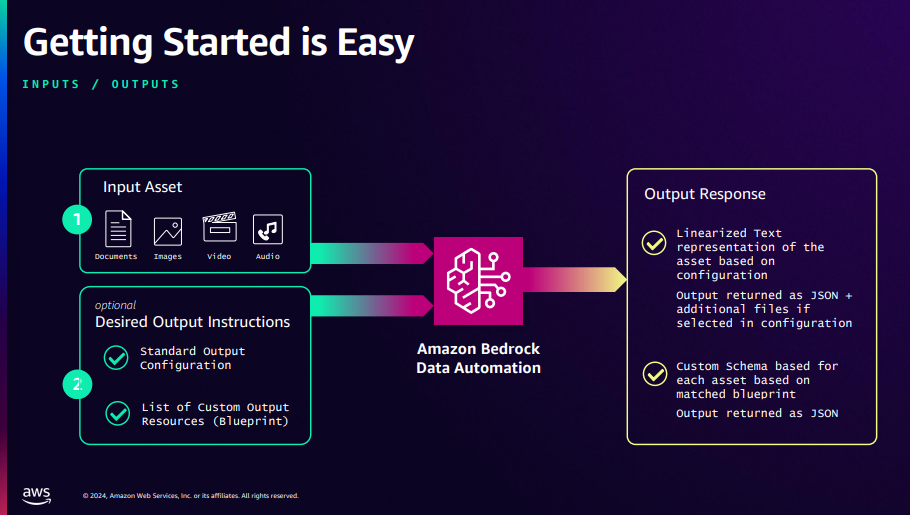
BDA では構造化データをどのように抽出するかを、次セクションで記述する2種類の出力方式(上図)によって設定します。出力の設定は Project という単位で管理され、マネジメントコンソール上では用意したデータを読み込ませてテストすることもできます。出力のルールに従って、BDA は構造化されたデータを JSON 形式で返します。
構造化データの出力方式には大きく 2 種類存在する
構造データの出力方式は、ユーザーが追加のルールを設定(または選択)するか否かによって出力方式が異なります。それらは Standard Output と Custom Output 呼ばれます。
Modality
現在、BDA では扱うファイルの形式によって以下の4つのタイプ(Modality と呼ばれる)に分類されます。
解析対象のファイルをアップロードすると、自動的に上記の Modality のうちいずれかが割り当てられます。ファイル形式と Modality の関係を以下に記載します。
| Modality | File type |
|---|---|
| Document/Image | PDF, JPEG, PNG, TIFF |
| Video/Audio | MP4, MOV with H.264, H.265, VP8, VP9 video codec, FLAC, M4A, MP3, Ogg, WAV |
なお、ファイル形式には以下の制限があり、それぞれ解析をするためにはデータの分割や圧縮といった前処理が必要になります。
| ファイル種別 | 上限 |
|---|---|
| Image | 50 MB |
| PDF, TIFF | 20 pages |
| ファイルサイズ | 200 MB |
Standard Output
追加のルールを設定しない場合、データタイプごとに Bedrock 側で定義されたデフォルトの解析結果が得られます。例えばドキュメントなら要約やテキスト抽出や意味的なグルーピング、画像や動画なら説明文やテキスト検出の結果が返されます。
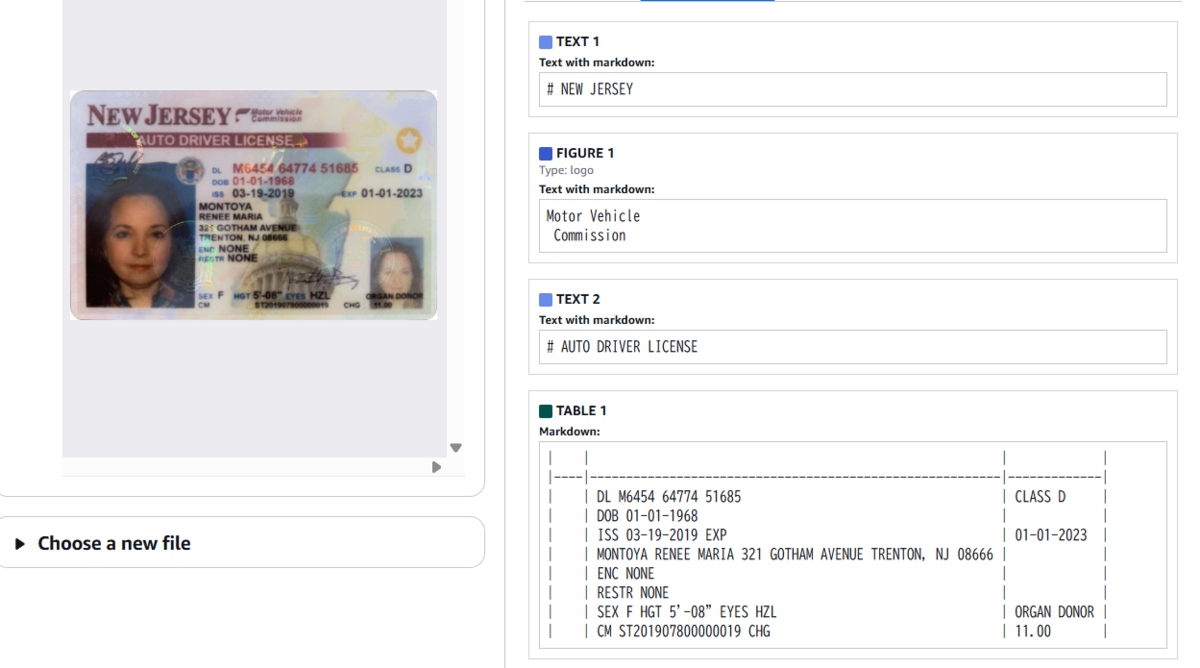
上図は BDA で用意されているデモ環境で、運転免許書の画像のテストデータを用いて解析した結果の一部を示しています。右側に表示されているように、画像内のテキストを読み取り、意味的に分解してブロックに分けて出力されています。
Custom Output
独自で出力内容を設定したい場合はカスタム出力を使います。Blueprint と呼ばれる「この項目を抽出してほしい」「この形式で結果が欲しい」といった設計図をユーザーが定義します。Blueprint は、自然言語やスキーマエディタで記述できます。例えば「請求書から日付と金額と支払者名だけ抜き出す」といった指定が可能です。Project に Blueprint を紐付けておくことで、そのルールに沿った結果を返すようになります。
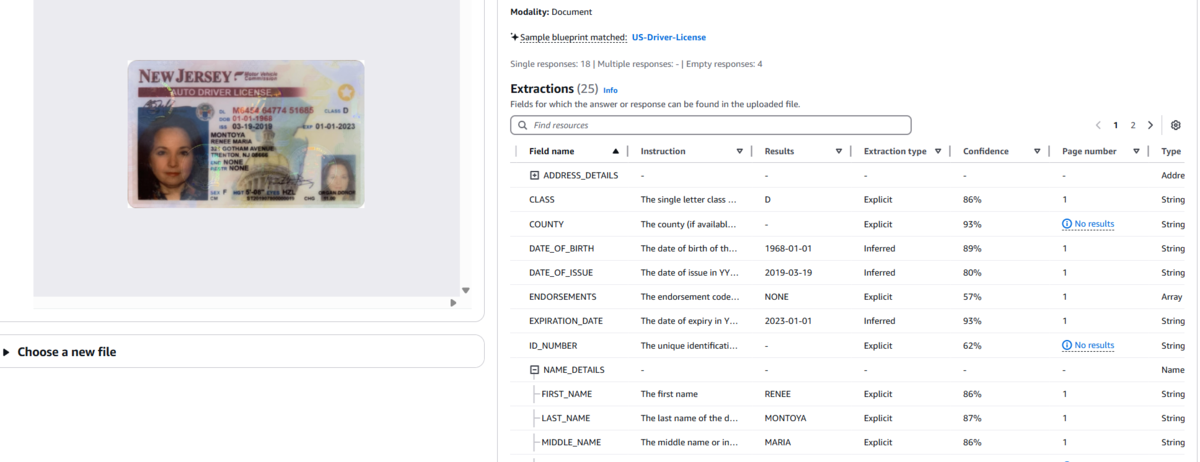
上図のようにテストデータに対して Custom Output の結果も確認することができます。ここでは既に用意された US-Driver-License の Blueprint が使用され、国籍、誕生日、有効期限など、事前定義された対象の情報を抽出できていることがわかります。
構造化されたデータを出力してみる
AWS re:Invent 2024 のセッションの BDA に関する Deck を使用し、情報の抽出を実施してみたいと思います。20 ページを超える PDF のため、前半の 20 ページのみを使用させていただきました。
Project の作成
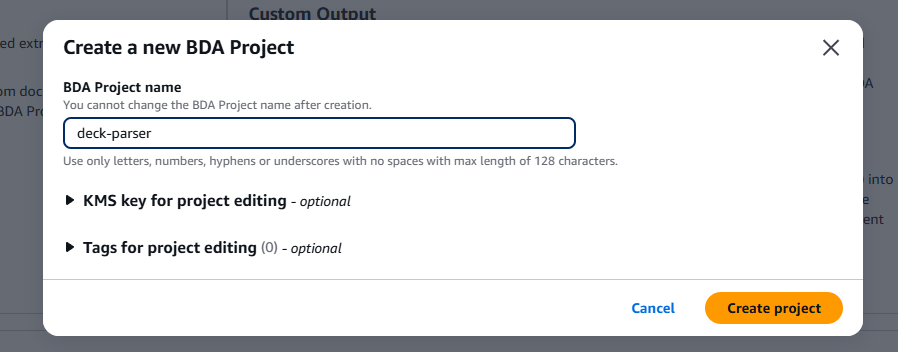
「Data Automation」>「Project」>「Create Project」を押下し、BDA Project name を設定します。ここでは deck-parser と名付けました。
Blueprint の作成
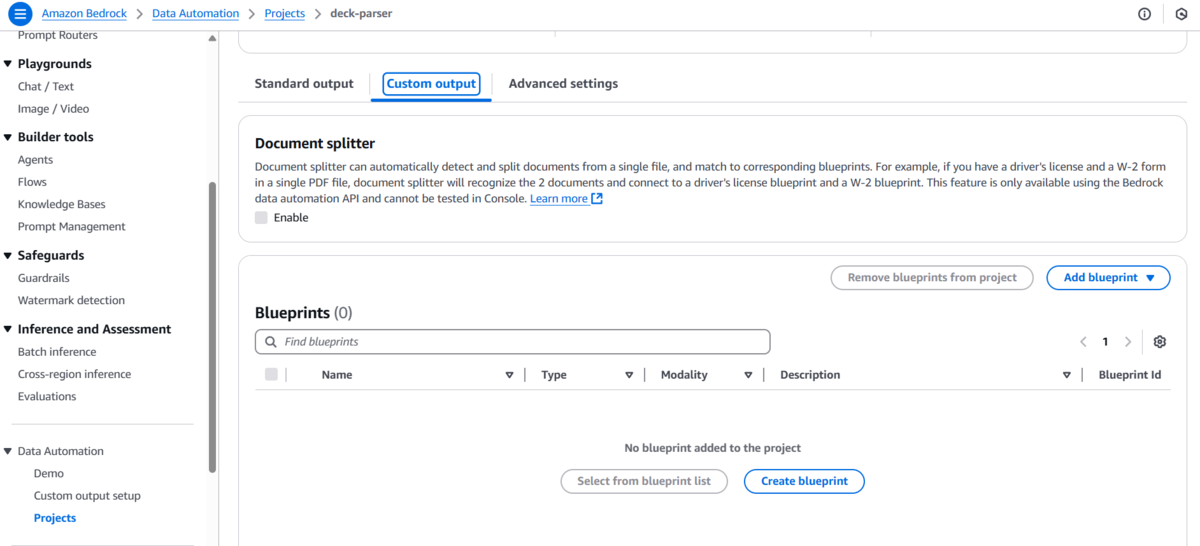
deck-parser のプロジェクトの画面の下部の「Custom output」タブから「Create blueprint」を押下します。
自然言語で作成する
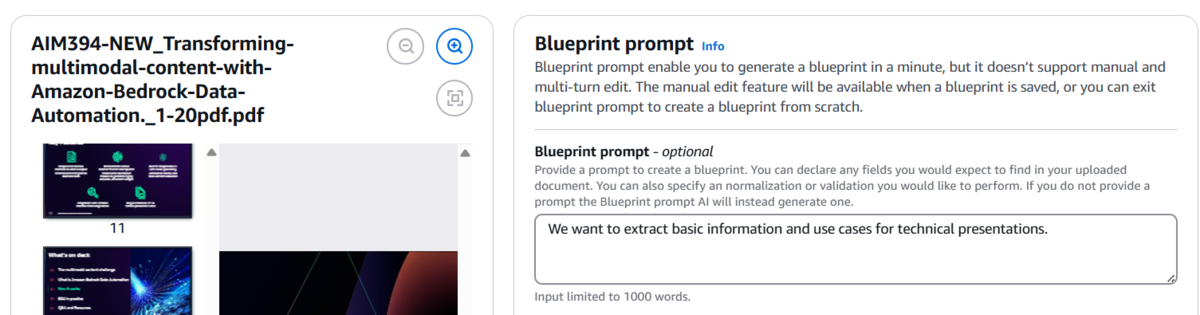
はじめに、Blueprint をスキーマエディタからではなく、自然言語によって自動生成します。遷移後の画面で、対象のファイルをアップロードし、Blueprint prompt に以下の内容を入力して「Generate blueprint」を押下します。
I want to extract basic information and use cases for presentations related to cloud technologies.
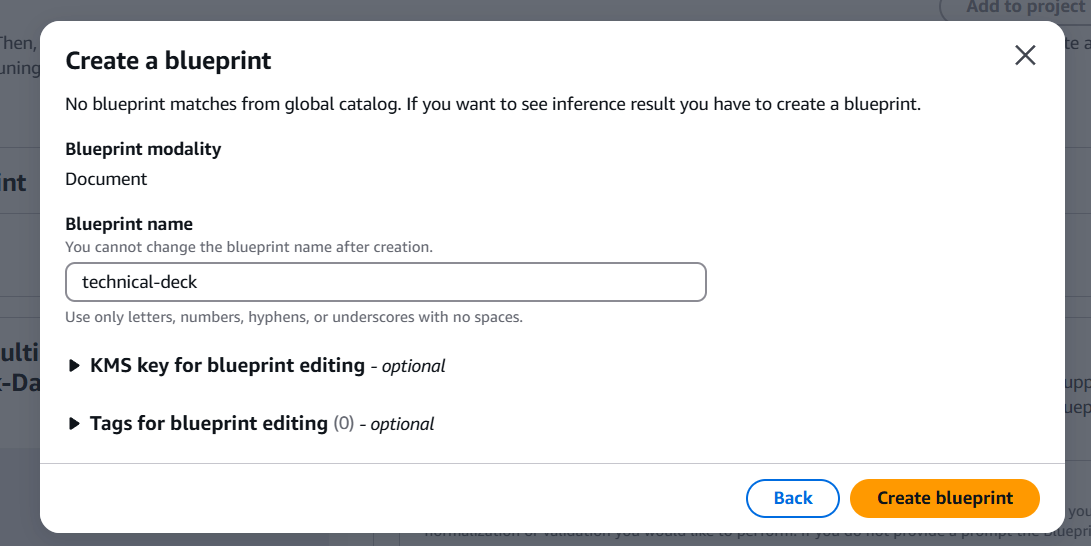
少し待つと Create blueprint というモーダルが表示されるので、Blueprint name に technical-deck と入力し「Create blueprint」を押下します。
ここでは以下のようなスキーマが生成され、併せてアップロードしたファイルに対する出力結果が表示されました。
| Field name | Results | Confidence Score % | Page number | Field type | Extraction type |
|---|---|---|---|---|---|
| Presenter Name | Anushri Mainthia, Rahul Gupta | 74.60937500 | 2 | string | explicit |
| Presenter Title | Principal Product Manager | 62.89062500 | 2 | string | explicit |
| Company | AWS | 84.76562500 | 2 | string | explicit |
| Presentation Sections | The multimodal content challenge, What is Amazon Bedrock Data Automation, How it works, BDA in practice, Q&A and Resources | 82.03125000 | 4 | arrayOfString | explicit |
| Use Cases | Intelligent Document Processing, RAG Applications, Media & Entertainment | 77.34375000 | 16 | arrayOfString | explicit |
プレゼンターの名前やタイトル、ユースケースについてもリストとして抽出されていることが確認できました。
意図したフィールドが作成されていれば画面右上の「Save and exit blueprint prompt」を押下します。
スキーマエディタで編集する
対象のファイルがどのカテゴリに分類されるかを自動で判別したいケースがあると思います。そこで AWS, Azure, Google Cloud のうちどのカテゴリの資料かを識別するためのフィールドを追加します。
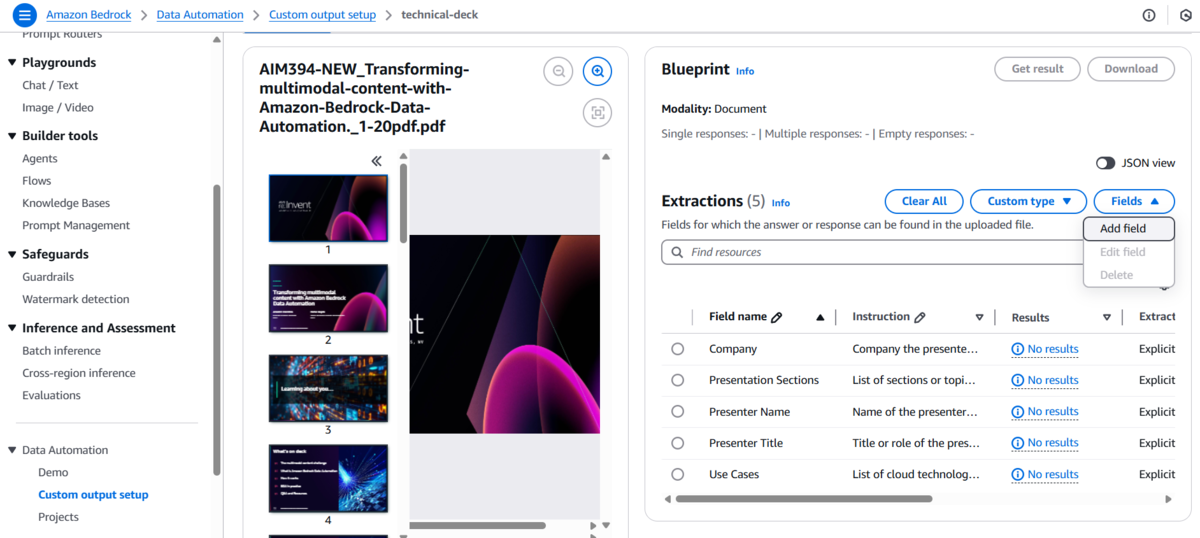
「technical-deck」>「Field」>「Add field」を押下するとフィールドを追加する編集画面が表示されます。以下をそれぞれ入力し「Done」を押下します。
| Field name | Instruction | Type | Extraction type |
|---|---|---|---|
| category_aws | Whether the material describes AWS or not. | Boolean | Inferred |
| category_azure | Whether the material describes Azure or not. | Boolean | Inferred |
| category_google_cloud | Whether the material describes Google Cloud or not. | Boolean | Inferred |
「Save blueprint」>「Save changes」を押下します。
テスト
「Projects」>「deck-parser」>「Custom output」>「Add blueprint」>「Select from blueprint list」を押下すると blueprint の一覧がモーダルで表示されます。検索欄に technical-deck を入力し、チェックを入れて「Add blueprint」>「Save changes」を押下します。
「Test」から同様に資料をアップロードしてテストします。Custom output の結果を確認すると、以下のような結果が得られました。
| Field name | Results | Confidence Score % | Page number | Field type | Extraction type |
|---|---|---|---|---|---|
| Presenter Name | Anushri Mainthia, Rahul Gupta | 74.60937500 | 2 | string | explicit |
| Presenter Title | Principal Product Manager | 68.35937500 | 2 | string | explicit |
| Company | AWS | 87.50000000 | 2 | string | explicit |
| Presentation Sections | The multimodal content challenge, What is Amazon Bedrock Data Automation, How it works, BDA in practice, Q&A and Resources | 84.76562500 | 4 | arrayOfString | explicit |
| Use Cases | Intelligent Document Processing, RAG Applications, Media & Entertainment | 84.76562500 | 16 | arrayOfString | explicit |
| category_aws | true | 85.54687500 | - | boolean | inferred |
| category_azure | false | 87.50000000 | - | boolean | inferred |
| category_google_cloud | false | 86.32812500 | - | boolean | inferred |
追加したフィールドの内、AWS に関連したドキュメントであることが検知されていることが確認できました。
まとめ
BDA について Standard Output と Custom Output の出力、Blueprint の設定について紹介してきました。
Bedrock Data Automation is also integrated with Bedrock Knowledge Bases, making it easier for developers to generate meaningful information from their unstructured multi-modal content to provide more relevant responses for retrieval augmented generation (RAG).
Bedrock Knowledge Bases とも連携されており、効率的に RAG を構成することも可能になっているようです。次回執筆するブログではパース戦略で BDA を指定して独自データをもとに回答できるようなチャット AI をテストしてみたいと思います。