

さとうです。
表題の通りですが、データ分析基盤のジョブをStep Functionsで実装する場合とGlue Workflowで実装する場合の違いをまとめてみようと思います。
まとめと言う割には大長編になってしまいました!
- 前提
- 本題
- まとめ
前提
データ分析基盤をAWSに構築するにあたって、ETLジョブの構築をする必要がありました。 そこでGlue WorkflowとStep Function、どちらを使う?という問題に差し当たって色々比較検討した、というのがこの記事の経緯です。
データ分析基盤に必要なETLパイプライン
データ分析基盤ではDatabricks社が提唱するメダリオンアーキテクチャのように、データを複数の階層に分けて段階的に処理するような構成を取ることが多いと思います
(例:生データ→クレンジングデータ→BIデータ)。
メダリオンアーキテクチャ (medallion architecture) | Databricks
このようなデータ分析基盤における一連のデータ処理の流れのことをETLジョブと呼んだりすることもあると思いますが、ここではGlue ETL Jobなどのサービス名と分別するためにETLパイプラインと呼ぶことにします。
GlueでこのETLパイプラインを実装する場合、主にGlue ETL JobとCrawlerを利用することになります。
- Glue ETL Job: ETLコードをサーバレスで実行できるサービス
- Glue Crawler: データソースのメタデータ(カラム情報など)を動的に読み取りGlue Data Catalogに連携するサービス
たとえばGlue ETL Jobでデータの取り込みまたは加工を行ったのち、Glue Crawlerで処理後のデータを読み取るといった処理を順番に繋ぎ合わせていくことで、ETLパイプラインを実装していくことになります。
図にするとこのようなイメージです(Databricks社の表現に倣ってデータ処理階層をBronze、Silver、Goldと呼ぶことにします)。
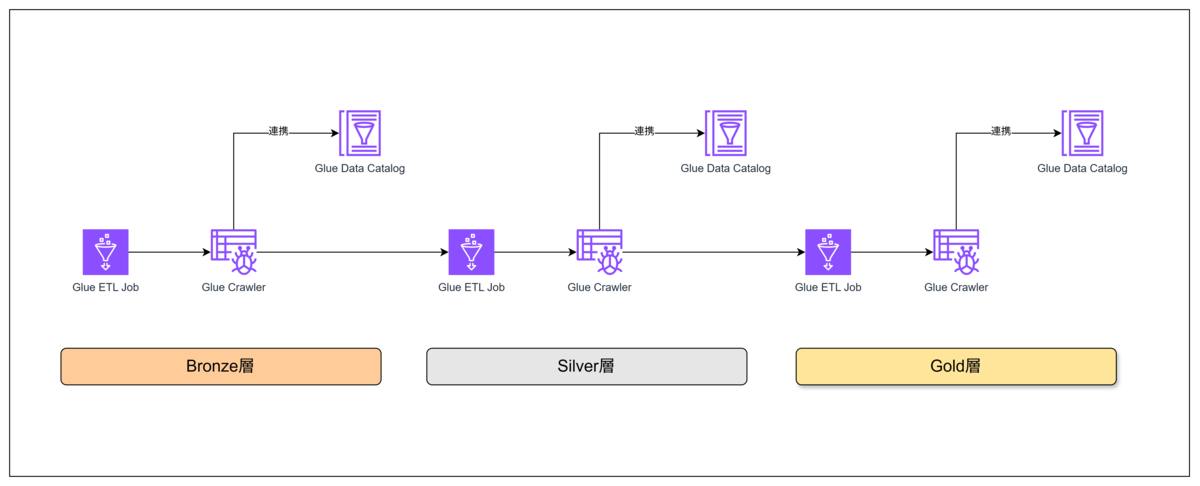
Glueで実装するETLパイプライン、何で制御するか問題
上記のようなパイプラインを実装する上で考える必要があるのが、パイプラインの一連の処理を何で制御(オーケストレーション)するのかという問題です。
川上から川下にタスクを流せば解決というわけではなく、たとえば同じ層のETL JobとCrawler、異なる層のETL Job同士には明らかに依存関係があります。
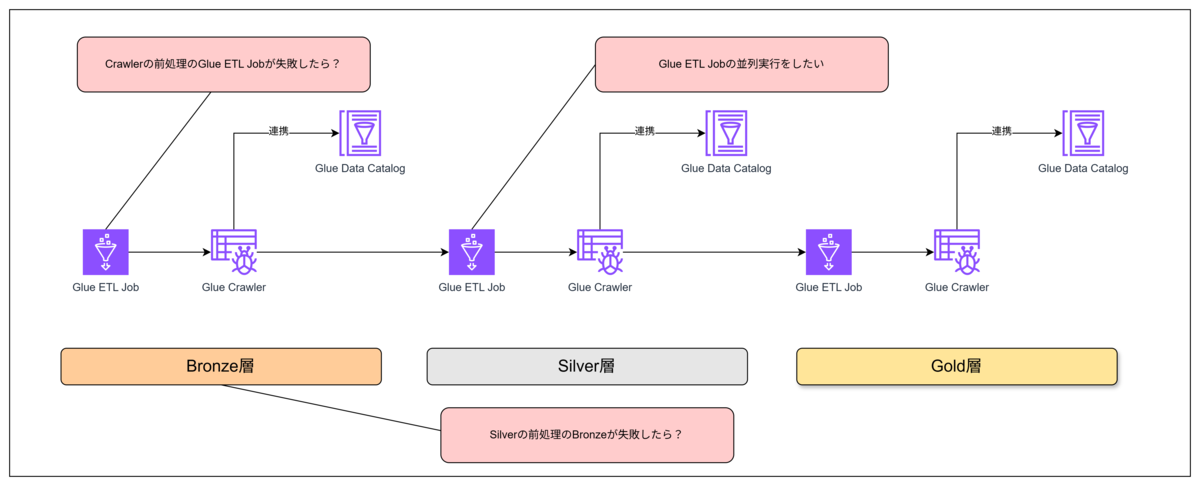
- 依存関係にある前工程の処理に失敗したら後続の処理を行わないようにする(エラーハンドル)
- 前工程が終わる前にフライングで後工程が始まらないように、実行順序を制御する(同期処理)
- ETLパイプラインの実行時間をなるべく短縮するため、並列可能なタスクはなるべく並列で実行する(非同期処理)
など、パイプラインの処理間の依存関係を制御するための仕組みが必要です。
その制御のための仕組みとして、今回は2つのサービスを比較したいと思います。
なんとなく名前にGlueがつくGlue Workflowがよさそうな気もしますが、今回の記事の結論としては複数のデータソースを扱うような一定規模のデータ分析基盤を構築する場合はStep Functionsを推奨します。
- Glue Workflow: Glue専用のワークフロー構築サービス
- Step Functions: AWS汎用のワークフロー構築サービス
ETLパイプラインのユースケース(必要になることが多い機能)
要件によってさまざまですが、一般的には以下のような機能を必要とすることが多いのではないでしょうか。
- ①定時実行したい(スケジュール)
- ②ジョブにパラメータを渡したい(フラグなど)
- ③タスク間の同期処理・非同期処理を制御したい
- ④パイプラインを入れ子構造にしたい(疎結合にしたい)
- ⑤Glue以外のAWSサービスと連携したい(Lambdaなど)
- ⑥エラーハンドルを追加したい
本題
(結論)ユースケースに着目したGlue WorkflowとStep Functionの違い
前段で整理したETLパイプラインのユースケースに沿って、できる/できないとその方法を比較した表が以下です。
1つずつ補足説明を入れていきたいと思います。
| ユースケース | Glue Workflow | Step Functions |
|---|---|---|
| ①定時実行したい | 〇(サービス内) | 〇(EvetBridge) |
| ②ジョブにパラメータを渡したい | 〇 | 〇 |
| ③タスク間の同期処理・非同期処理を制御したい | 〇 | 〇 |
| ④パイプラインを入れ子構造にしたい | × | 〇 |
| ⑤Glue以外のAWSサービスと連携したい | × | 〇 |
| ⑥エラーハンドルを追加したい | 〇 | 〇 |
①定時実行したい
ETLパイプラインは日次でバッチ処理的に定時実行するケースが大半になるかと思います。
そのため、ETLパイプラインの実行をトリガーするための機能が必要となります。
Glue Workflowの場合
Glue Workflowの場合、定時実行する機能(トリガー)が埋め込まれているのでEventBridgeを使う必要がないというメリットがあります。
ジョブとクローラの時間ベースのスケジュール - AWS Glue
もちろん、EventBridgeを使用したイベント連携や定時実行にも対応しています。
Amazon EventBridge イベントによる AWS Glue ワークフローの開始 - AWS Glue
Step Functionsの場合
EventBridgeを使用してトリガーを設定することになります。
Amazon EventBridge スケジューラを使用して Step Functions ステートマシンの実行を開始する - AWS Step Functions
②ジョブにパラメータを渡したい
Glue ETL Jobにはパラメータという機能があります。この機能を活用することでETLパイプライン内のETLジョブに一括でパラメータを渡すことができ、フラグによる条件分岐などパラメータの値でETLジョブの内容を制御するといった作りこみが可能になります。
AWS Glue ジョブでジョブパラメータを使用する - AWS Glue
パラメータの渡し方や取り出し方がGlue WorkflowとStep Functionsで異なりますので注意してください。
Glue Workflowの場合
実行プロパティという機能があり、ここからパラメータを設定することができます。
AWS Glue でのワークフローの実行プロパティの取得と設定 - AWS Glue
上記のドキュメントのサンプルコードにある通り、 getResolvedOptions でジョブをトリガーしたGlue Workflowの名前やIDを取得した上で、 get_workflow_run_properties でGlue Workflowの実行プロパティに設定した値を取得するという二段階の処理が必要となります。
Step Functionsの場合
入力という機能があり、ここからパラメータを設定することができます。
入力とは、Step Functionsの実行時に渡す引数のようなものです。なお、JSONで渡す必要があります。
Step Functions の入力および出力処理 - AWS Step Functions
ちなみにStep Functionsの書き方がJSONataかJSONPathかでGlue ETL Jobへの渡し方が変わってくるのですが、今回はJSONPathを使用した渡し方の紹介になります。JSONataについてはまた別の記事でまとめたいと思います。
たとえば入力で実行時に以下のようなJSONペイロードをStep Functionsに渡したとします。
{"--test_param": "test_param"}
これをGlue ETL Jobに渡すには、 Step Functionsにアクションの Glue: StartJobRun を追加し、APIパラメータとして以下のように渡します。
{ "JobName": "<Glue ETL Jobの名前>", "Arguments.$": "$" }
Step Functions固有の書き方が多分に含まれているので、要素を分解して補足します。
- Arguments:
Glue: StartJobRunのプロパティ(パラメータをJSONで渡す) - .$: 値にJSONパスを使用することを明示するための識別子(キーの末尾に
.$を付ける必要がある) - $: InputのJSONパス(例だと入力全体でジョブパラメータしか渡していないので、ルートを示す
$になります。ネスト構造のJSONを渡す場合はパラメータがあるパスを指定します)
Step Functions ワークフローでパラメータを操作する - AWS Step Functions
あとは以下のドキュメントにある通り、コード内でライブラリを使用することでパラメータを取り出すことができます。
AWS Glue ジョブでジョブパラメータを使用する - AWS Glue
なお、パラメータとしてJSONペイロードを渡す場合には細則があり、キーの先頭に -- を付ける必要があったり、 キーの先頭以外で - を使ってはならないといったルールがありますので気を付けましょう。
getResolvedOptions を使用して、パラメータにアクセスする - AWS Glue
各引数は 2 つのハイフンで始まり、ハイフンなしでスクリプト内で参照されるように定義されていることに注意してください。引数では、ハイフンではなく、アンダースコアのみを使用します。引数の解決のために、この規則に従う必要があります。
③タスク間の同期処理・非同期処理を制御したい
前提で説明した通り、依存関係のあるタスクは同期処理にしたいですし、依存関係がないタスクは非同期で処理時間を短縮したいですよね。
Glue Workflowの場合
同期・非同期ともに実装することができます。
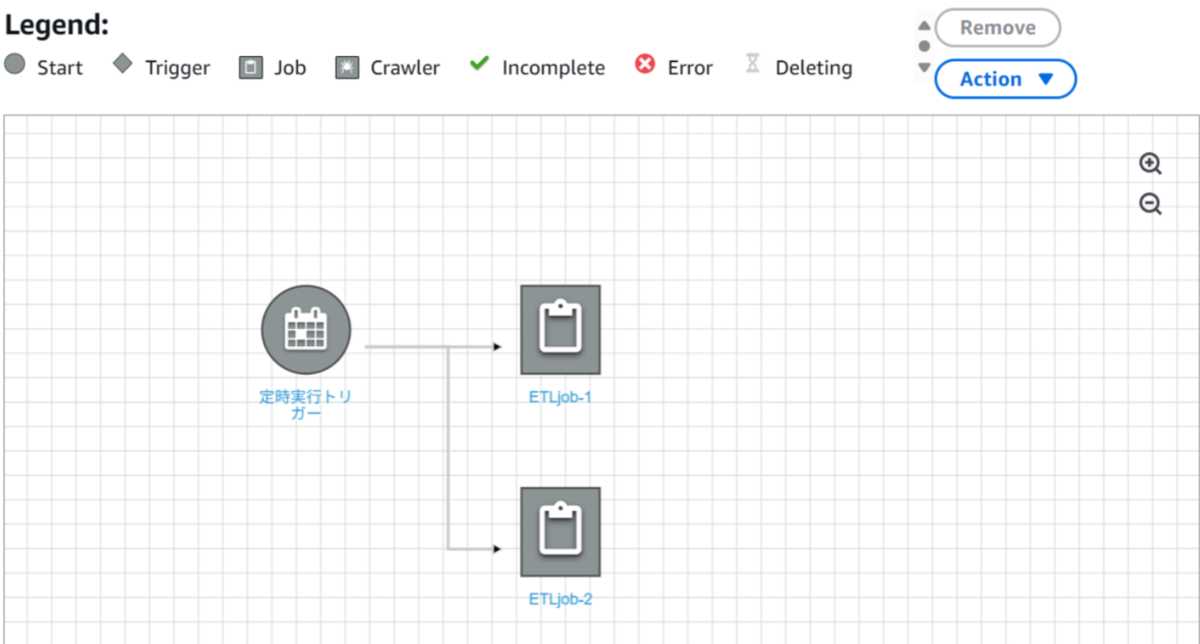
Glue Workflowにはノード(Glue ETL Job/Crawler)とそれらを起動するトリガーという概念があり、トリガーでノードの実行条件を明示していくようなイメージです。
たとえば非同期実行の場合は、以下のようにトリガーの後に非同期で実行したいノードを並べるだけです。
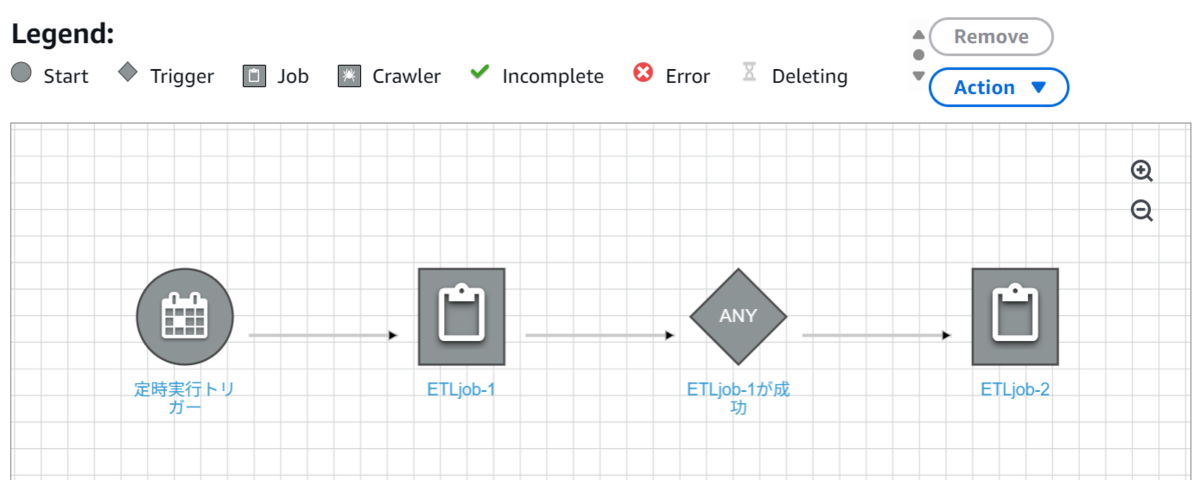
同期実行の場合、ノード1の後にノード1のステータス(成否)を監視するトリガーを作成し、監視条件(成功した場合など)に合致した場合にトリガーが次のノード2を実行する…といった実装方法になります。
つまり、ノードを実行するには必ずトリガーが必要であり、ノード同士を直接繋げることはできません。
Step Functionsの場合
非同期処理の場合はParallelステートメントを使うだけでいいのでシンプルです。 ただし、下記のドキュメントに記載がある通り非同期処理のうち1つが失敗すると他の処理も止めてしまうという仕様があるので、エラーハンドルを組み合わせて処理を継続させるなど実装上の工夫が必要です。
Parallel ワークフローの状態 - AWS Step Functions
Step Functions ワークフローでのエラー処理 - AWS Step Functions
同期処理の場合はStep Functionsのサービス統合パターンという機能を使用します。
この機能のうち .sync パターンを使うと呼び出したタスクの処理完了を待って次のタスクを実行するといった処理ができます。
なお、デフォルトでは Request Response パターンになっており、処理の完了を待たずに次のタスクの処理に移ってしまうので注意してください。
ただし、Glue Crawlerを同期処理で組み込む場合には少々工夫が必要です。
というのは、残念ながらサービス統合は全てのサービスでサポートされているわけではありません。
今回のユースケースの場合、2025年6月現在で Glue: StartJobRun は上記のサービス統合を使用することができますが、 Glue:StartCrawler は使用することができません。
サービスと Step Functions の統合 - AWS Step Functions
つまり、Crawlerは常に Request Response で処理の完了を待たずに次のタスク処理へ進もうとします。
ではどうすればいいのかというと、以下のAWS公式ブログに記載があるように自前でCrawlerの実行状況を定期的にポーリングする処理をStep Functions内で組み込む必要があります。記事中にCloudFormationの実装サンプルもあるので参考にしてみてください。
④パイプラインを入れ子構造にしたい
個人的にはこの点が最も大きな差異なのではないかと思います。
Glue Workflowで実装する場合、入れ子構造にできないという制約からETLパイプラインの規模が拡大するにつれてモノリシックな構成になっていきます。
ETLパイプラインの修正や処理対象の追加などのメンテナンスが手間になる、処理失敗時の部分的な再実行が難しくなるなど運用面のデメリットが目立つようになります。
Glue Workflowの場合
入れ子構成はサポートされていません。
また、モノリシックな構成を受け入れるにせよ1つのGlue Workflowに入れられるジョブ、クローラー、トリガーは100個以下という制約がある点にも注意が必要です。
AWS Glue でワークフローを手動により作成および構築する - AWS Glue
ワークフロー内のジョブ、クローラ、トリガーの総数を 100 以下に制限します。100 を超える値を含めると、ワークフローの実行を再開または停止しようとしたときにエラーが発生することがあります。
Step Functionsの場合
アクションの Step Functions: StartExecution を使用することで、Step Functionsを入れ子構造にすることができます。
なお、 input プロパティに上位のStep Functionsから渡したパラメータを指定すれば下位のStep Functionsにパラメータを継承することも可能です。
実行中の実行から新しい AWS Step Functions ステートマシンを起動する - AWS Step Functions
⑤Glue以外のAWSサービスと連携したい
Glue Workflowの場合
名前にGlueを冠している通り、呼び出せるのはGlue ETL JobとCrawlerのみです。
Step Functionsの場合
Step Functionsが対応するサービスは多岐にわたりますが、APIが提供されているサービスと操作であればほぼStep Functionsから実行することができます。
Step Functions とは - AWS Step Functions
⑥エラーハンドルを追加したい
特定の処理が失敗した場合に全体のロールバックを実行するなど、コードレベルではなくETLパイプラインレベルでエラーハンドルをしたい場合があると思います。
Glue Workflowの場合
先ほど「タスク間の同期処理・非同期処理を制御したい」の項でノードは必ずトリガーから実行されると説明しましたが、トリガーでノードの成否を監視することでエラーハンドルを実装することが可能です。
たとえば以下のように「いずれかのノードが失敗した場合に、特定のノード(ロールバックなど)を実行」といった処理を実装することができます。
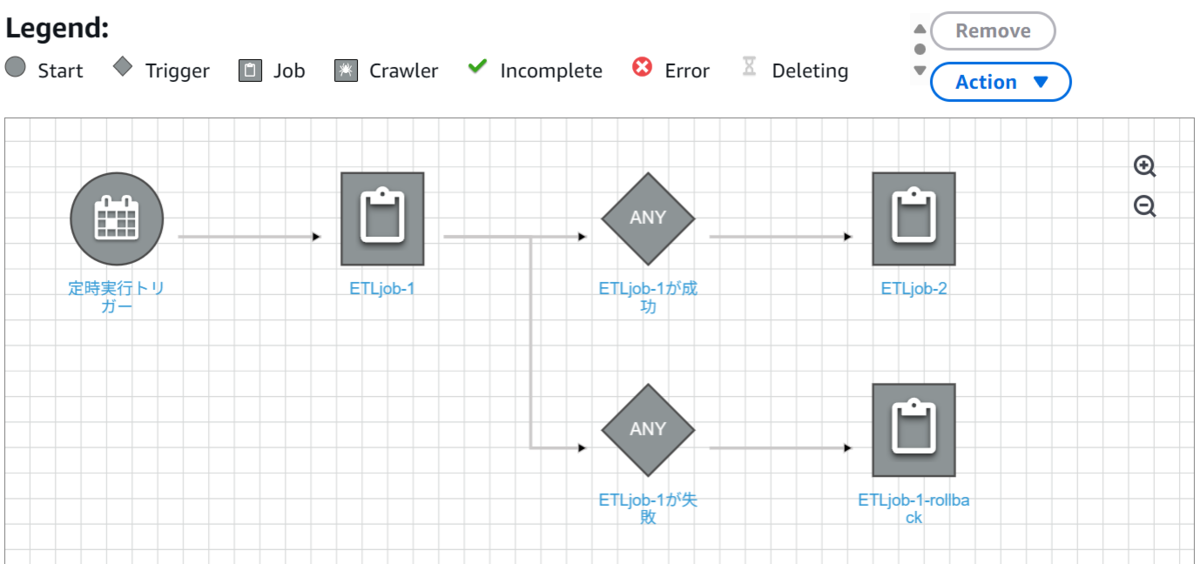
Step Functionsの場合
汎用性が高い分実装方法は多岐にわたりますが、以下に実装がよくまとまっています。
AWS Step Functions のエラーハンドリングを実装しよう - builders.flash☆ - 変化を求めるデベロッパーを応援するウェブマガジン | AWS
アクションの「エラー処理」のタブからシステムエラーを指定して捕捉することもできますし、Choice(if分岐)を使用して条件分岐で正常終了した処理も意図的に例外へ投げるといった処理を作りこむこともできます。
まとめ
基本的に汎用的なワークフローサービスであるStep Functionsの方が機能面では上位互換なので、機能面で迷ったらStep Functionsを選んでおけば間違いないとも言えます。
ただし、Glue WorkflowとStep Functionsの補足量の差でお察しかもしれませんが、厳密なETLパイプラインの制御を実装するためにはStep Functionsの仕様をそれなりに理解する必要があります。これだけ書いてなお、説明しきれていない感があります…。
大規模なETLパイプラインであればStep Functionsを推奨とは言いましたが、データソースの拡張などが見込まれないのであれば手軽に実装できるGlue Workflowを使った方がいいかもしれません。
佐藤 航太郎(執筆記事の一覧)
エンタープライズクラウド部 クラウドモダナイズ課
2025年1月入社で何でも試したがりの雑食系です。