

みなさんこんにちは。マネージドサービス課の塩野です。
今回もNew Relicのクエリ言語であるNew Relic Query Language(NRQL)についての話題です。
システム監視の現場でこんな経験はないでしょうか。突然CPUの使用率が急上昇し、アラートが鳴り響く。メトリクスのグラフを見ると、確かに15時30分頃から負荷が異常に高まっています。しかし、グラフだけを見ていても「なぜそのタイミングで負荷が上がったのか」はわかりません。
インフラエンジニアが真っ先に疑うのは「誰かが何かを変更したのではないか」ということです。OSのパッケージを更新したのか、アプリケーションのバージョンを上げたのか、それともサービスを再起動したのか。これらの「変更」を素早く特定できれば、問題の原因究明にかかる時間は劇的に短縮されます。
New RelicのInfrastructureEventは、まさにこの「変更の履歴」を記録し、メトリクスの変化と紐付けて分析できる機能です。本記事では、InfrastructureEventを活用して、システムの負荷上昇やパフォーマンス低下の原因を効率的に追跡する方法を解説します。
InfrastructureEventテーブルとは
InfrastructureEventは、New Relic Infrastructure Agentが収集するイベントデータで、システムの状態変化を記録するテーブルです。このテーブルには、ホスト上で発生した様々な変更イベントが時系列で保存されており、NRQLを使ってクエリすることができます。
記録される主なイベントには、以下のようなものがあります。
パッケージの変更(category='packages')では、yumやaptなどのパッケージマネージャーを通じて行われたパッケージのインストール、更新、削除が記録されます。例えば、nginxのバージョンを1.18から1.20にアップデートした場合や、新しいセキュリティパッチを適用した場合などが該当します。
サービスの状態変化(category='services')では、systemdやその他のサービスマネージャーによって管理されているサービスの開始、停止、再起動が記録されます。アプリケーションサーバーの再起動やデータベースサービスの停止といった操作が、このカテゴリに分類されます。
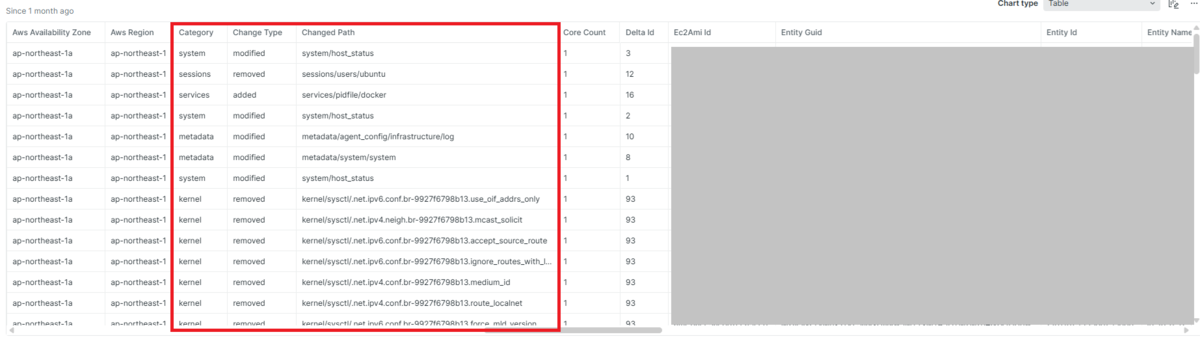
インベントリ全体の変更(format='inventoryChange')では、より広範な設定変更やシステム状態の変化が記録されます。このフォーマットを指定することで、パッケージやサービスに限らず、システム全体のインベントリ変更を包括的に確認できます。
基本的なクエリ例を見てみましょう。過去1日間に発生したパッケージ変更を確認するには、次のようなクエリを実行します。
SELECT * FROM InfrastructureEvent WHERE category = 'packages' SINCE 1 day ago

同様に、サービスの状態変化を確認する場合は以下のようになります。
SELECT * FROM InfrastructureEvent WHERE category = 'services' SINCE 1 day ago
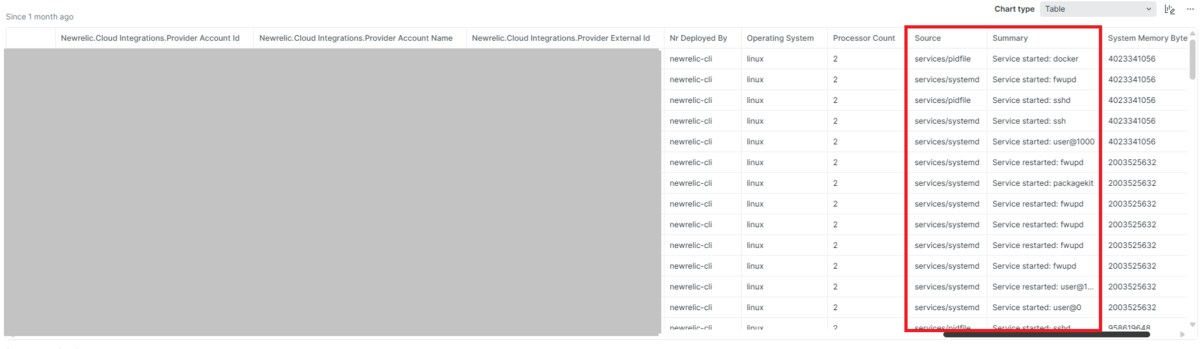
インベントリ全体の変更を確認したい場合は、formatを指定します。
SELECT * FROM InfrastructureEvent WHERE format = 'inventoryChange' SINCE 1 day ago
これらのクエリを実行すると、指定した期間内にどのような変更が行われたかを時系列で確認できます。変更の内容、変更が発生したホスト、変更のタイプなどの情報が含まれており、障害調査の重要な手がかりとなります。
実践:メトリクスとイベントを時系列で重ね合わせる
InfrastructureEventの真価は、メトリクスの変化と変更イベントを同じ時間軸で並べて分析できる点にあります。ここでは、実際の障害調査を想定した活用方法を紹介します。
まず、ダッシュボード上でCPU使用率のグラフを表示している状況を考えてみましょう。15時30分頃から急激にCPU使用率が上昇しています。このとき、同じダッシュボードにInfrastructureEventのチャートを追加することで、その時間帯に何が起きていたかを視覚的に把握できます。
具体的には、CPU使用率のグラフの下に、次のようなクエリでイベントを表示するウィジェットを配置します。
SELECT timestamp, hostname, summary FROM InfrastructureEvent WHERE category = 'packages' SINCE 6 hours ago LIMIT 100
このクエリを実行すると、過去6時間以内にパッケージの変更が行われたタイミングが一覧表示されます。例えば、15時40分頃に特定のホストでパッケージ更新が行われていれば、それがCPU使用率上昇の原因である可能性が高いと判断できます。

サービスの再起動が原因かもしれないと考える場合は、以下のクエリで確認します。
SELECT timestamp, hostname, summary FROM InfrastructureEvent WHERE category = 'services' SINCE 6 hours ago LIMIT 100
このクエリで、アプリケーションサーバーやデータベースサービスの再起動イベントが見つかれば、それが負荷変動の引き金になった可能性があります。

特定のホストに絞り込んで調査したい場合は、WHERE句にホスト名の条件を追加します。
SELECT timestamp, category, summary FROM InfrastructureEvent WHERE hostname = 'web-server-01' AND category IN ('packages', 'services') SINCE 1 day ago
このように、メトリクスの異常が発生したタイミングと、システム上の変更イベントを照らし合わせることで、「何が原因で負荷が上がったのか」という疑問に対する答えが見つかりやすくなります。グラフだけを眺めていても見えなかった因果関係が、イベントデータを加えることで明確になるのです。
実務で役立つクエリパターン集
ここでは、日常的な運用や障害調査で使える実用的なクエリパターンを紹介します。
今日変更があったホストの一覧を確認したい場合は、次のクエリが便利です。
SELECT uniqueCount(hostname) FROM InfrastructureEvent WHERE format = 'inventoryChange' SINCE today FACET hostname
このクエリでは、今日何らかのインベントリ変更があったホストが一覧表示されます。定期的にこのクエリを実行することで、予期しない変更が行われていないかを監視できます。
特定のパッケージが更新されたタイミングを確認したい場合もあるでしょう。例えば、kernelやnginxといった重要なパッケージの更新履歴を追跡するには、以下のようなクエリを使用します。
SELECT timestamp, hostname, summary FROM InfrastructureEvent WHERE category = 'packages' AND summary LIKE '%kernel%' SINCE 7 days ago
summaryフィールドには変更の詳細が記録されているため、LIKE句を使って特定のパッケージ名で絞り込むことができます。
サービス停止イベントの検出も重要です。予期しないサービス停止は、システムダウンの直接的な原因となることがあります。
SELECT timestamp, hostname, summary FROM InfrastructureEvent WHERE category = 'services' AND summary LIKE '%stopped%' SINCE 1 day ago
このクエリで、過去24時間以内に停止したサービスを特定できます。サービス名でさらに絞り込むことも可能です。
変更の種類別に集計して、どのタイプの変更が多いかを把握することも有用です。
SELECT count(*) FROM InfrastructureEvent WHERE format = 'inventoryChange' SINCE 1 day ago FACET changeType
changeTypeを使うことで、パッケージの追加、削除、更新といった変更の種類ごとに件数を集計できます。これにより、システム全体でどのような変更活動が行われているかの傾向を掴めます。

時系列での変更頻度を確認したい場合は、TIMESERIESを使います。
SELECT count(*) FROM InfrastructureEvent WHERE category = 'packages' SINCE 7 days ago TIMESERIES 1 hour
このクエリでは、過去7日間のパッケージ変更件数が1時間ごとにグラフ化されます。変更作業が集中している時間帯や、定期メンテナンスのパターンを可視化するのに役立ちます。

これらのクエリパターンを組み合わせることで、システムの変更履歴を多角的に分析し、問題の根本原因を効率的に特定できるようになります。
ダッシュボードとアラートへの応用
InfrastructureEventは、ダッシュボードやアラート機能と組み合わせることで、さらに強力な監視体制を構築できます。
カスタムダッシュボードでは、システムメトリクスとイベント情報を統合して表示することをおすすめします。例えば、一つのダッシュボードに以下のようなウィジェットを配置します。
上段にはCPU使用率、メモリ使用率、ディスクI/Oといった主要なメトリクスのグラフを配置します。中段には、過去24時間のパッケージ変更イベントとサービス変更イベントをテーブル形式で表示します。下段には、変更頻度の時系列グラフを配置し、変更作業がどの時間帯に集中しているかを可視化します。
このような構成により、メトリクスの異常とシステム変更の相関関係を一目で把握できるダッシュボードが完成します。
アラート設定については、重要なパッケージが更新されたときに通知を受け取る仕組みが有効です。例えば、kernelやOpenSSLといったセキュリティ上重要なパッケージの更新を検知するアラート条件を設定できます。
NRQL条件では、以下のようなクエリを基にアラートを作成します。
SELECT count(*) FROM InfrastructureEvent WHERE category = 'packages' AND (summary LIKE '%kernel%' OR summary LIKE '%openssl%')
この条件で、指定したパッケージに変更があった場合にアラートが発生します。通知先としてSlackやPagerDutyを設定しておけば、重要な変更をリアルタイムで把握できます。
予期しないサービス停止を検知するアラートも重要です。特に、本番環境で稼働している重要なサービスについては、停止イベントを即座に検知する必要があります。
SELECT count(*) FROM InfrastructureEvent WHERE category = 'services' AND summary LIKE '%nginx%stopped%'
このようなアラート条件を設定することで、nginxが停止した瞬間に通知を受け取ることができます。
ベストプラクティスとしては、アラートの閾値を適切に設定することが大切です。変更イベント自体は正常な運用の一部であるため、すべての変更にアラートを出すのではなく、本当に注意が必要な変更のみを通知対象とすべきです。また、アラートメッセージには、変更内容やホスト名などの具体的な情報を含めることで、通知を受け取った担当者が即座に状況を理解できるようにします。
ダッシュボードとアラートを適切に設計することで、システムの変更を継続的に監視し、問題が発生する前に予兆を捉えることが可能になります。
まとめ
New RelicのInfrastructureEventを活用することで、システムの負荷上昇やパフォーマンス低下の原因を、メトリクスだけでなく「何が変わったか」という観点から追跡できるようになります。
パッケージの更新、サービスの再起動、その他のシステム変更といったイベントは、多くの場合、パフォーマンス変動の直接的な原因となります。InfrastructureEventを使えば、これらの変更履歴を時系列で確認し、メトリクスの異常と照らし合わせることで、迅速な原因究明が可能です。
本記事で紹介したクエリパターンやダッシュボード設計の考え方を、ぜひ日々の運用に取り入れてみてください。メトリクスの数値だけを追いかけるのではなく、その背後にある「変更」に目を向けることで、障害対応のスピードと精度が大きく向上するでしょう。
この記事がどなたかのお役に立てれば幸いです。
関連記事
◆ 塩野 正人
◆ マネージドサービス部 所属
◆ X(Twitter):@shioccii
◆ 過去記事はこちら
前職ではオンプレミスで仮想化基盤の構築や運用に従事。現在は運用部隊でNew Relicを使ってサービス改善に奮闘中。New Relic User Group運営。