

こんにちは! カスタマーサクセス本部 CS4課 櫻庭です。 今回は、Bedrockナレッジベースの構造化データストアについて紹介させて頂きます。
はじめに
従来のBedrock ナレッジベース(ベクトルデータストア)について
従来のBedrock ナレッジベースでは、OpenSearch Serverless等のベクトルデータストアと連携したRAG(検索拡張生成)が実現できます。ユーザーが自然言語で質問すると、システムが自動的に必要情報をS3等に配置した社内文書から検索し(実際にはS3に都度アクセスしている訳ではありませんが)、その結果をもとに自然言語で回答を提供する、という流れとなります。
構造化データストアを利用したナレッジベースについて
今回ご紹介する構造化データストアは、昨年(2024年)12月にリリースされたもので、データソースとしてRedshift等の構造化データストアを指定します。 自然言語で質問すると自然言語で回答してくれるのはベクトルデータストア利用時と同様ですが、回答に必要な情報を検索する際に、 データベース構造や過去のクエリ履歴を踏まえたSQLを自動生成・実行してRedshiftから検索してくれる、というものになります。 構造化された状態のデータ(データベース)を扱うため、必要な情報をSQLで効率的に抽出・加工でき、より正確な情報取得が期待できます。(SQL生成はAIの領域ですが、データ加工処理自体はSQLで厳密に処理されます) 自然言語でお手軽にデータ分析ができそうですね。
構造化データストアと連携したナレッジベース作成の流れ
それでは早速試してみましょう。ざっくり、以下のような流れで進めます。
- Redshiftの作成
- Redshiftのテスト
- ナレッジベースの作成
- ナレッジベースのテスト
Redshiftの作成
Redshiftを作成します。(ナレッジベースと連携させたいRedshiftを既にお持ちの場合はスキップ)
サーバレスでもナレッジベースとの接続は可能ですが、ここではサンプルデータ準備の簡略化の都合により、クラスターを作成します。(なお、テーブル作成・データ投入は別途必要になりますが、ほとんどクエリしない前提だと、サーバレスの方が安く済みます)
※ナレッジベースを作成するリージョンに作成します。
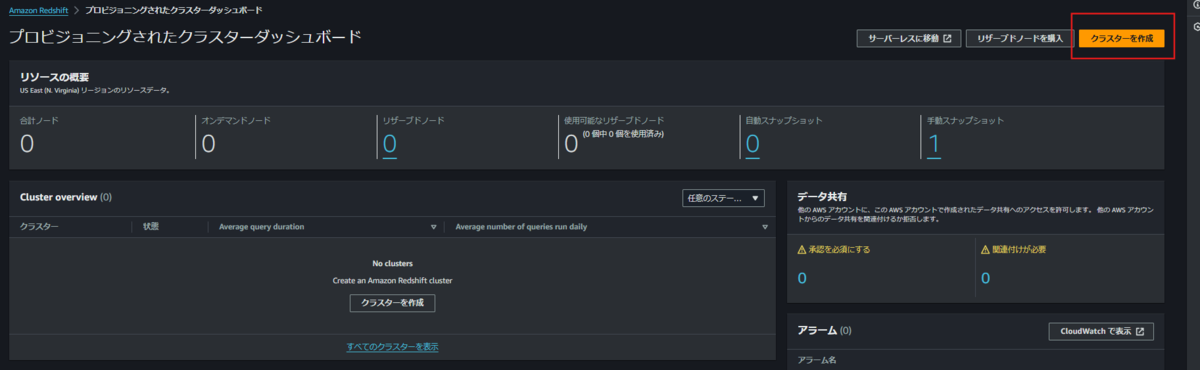
ここでは、構造化データストアを試すことさえ出来れば良いので、費用を抑えるために以下の設定にします。
- ノードの種類: dc2.large
- ノードの数: 1
また、適当なデータでナレッジベースからReshiftを参照した回答を確認出来ればよいので、自前でテーブル作成やデータ投入の手間を省くため、以下にチェックを入れます。
- サンプルデータをロード
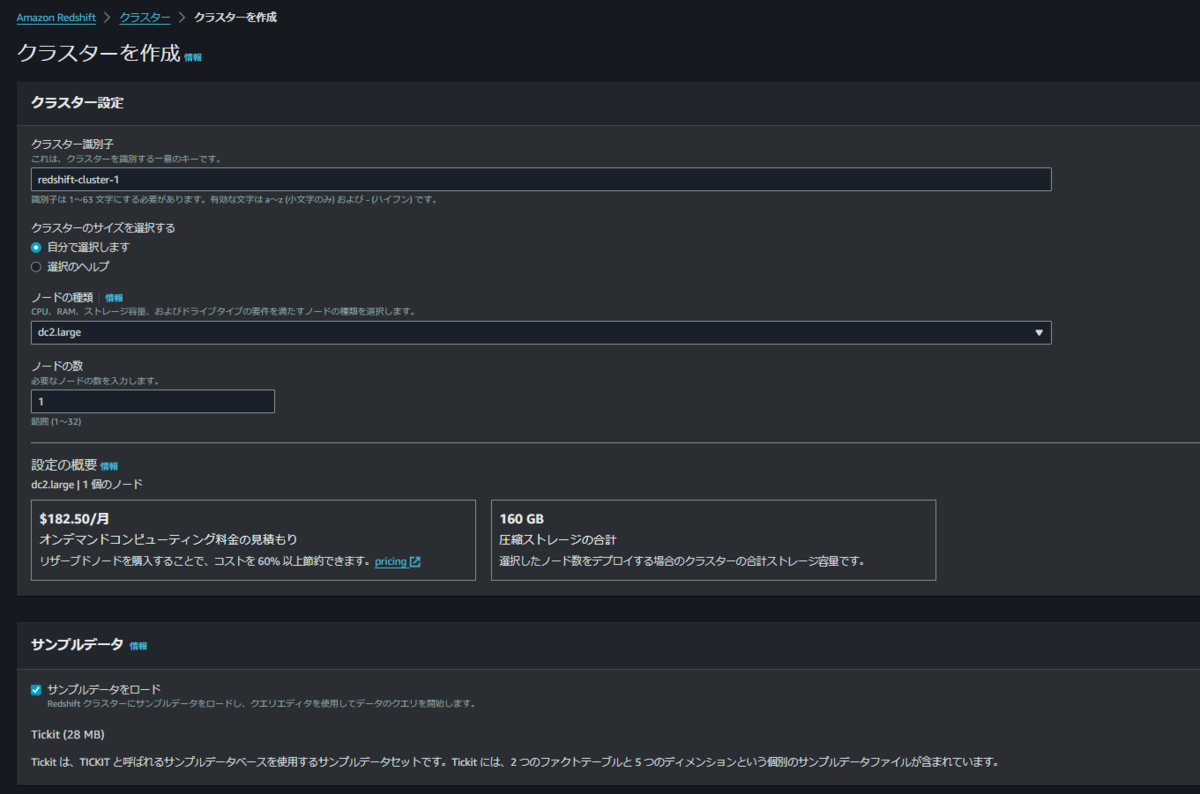
管理者パスワードはSecrets Managerを利用します。パスワードの生成や、管理者パスワードを手動で設定することも可能です。
Redshiftのテスト
クラスターの作成が完了したら、念のためRedshiftの挙動を確認します。「クエリデータ」からクエリエディタ(v2)に遷移します。
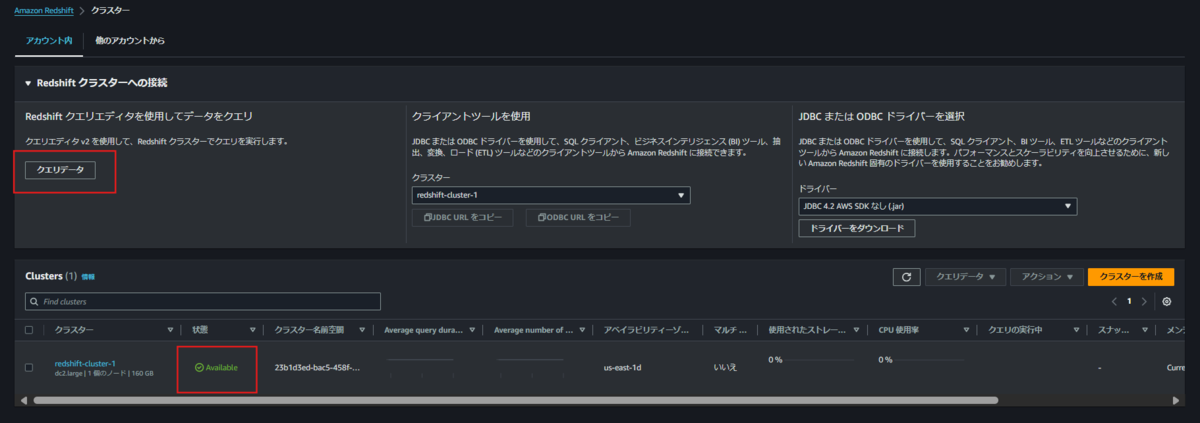
作成したクラスターの右側の「︙」から、「Edit Connection」をクリックします。
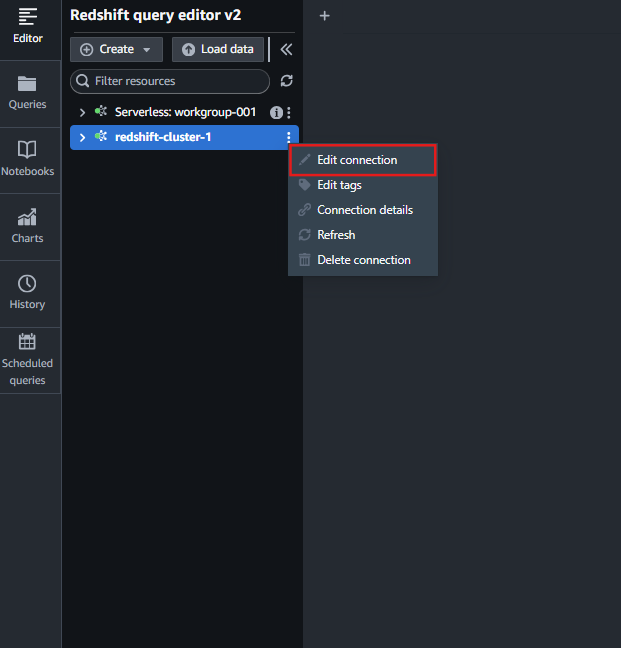
シークレットを選択し「save」します。
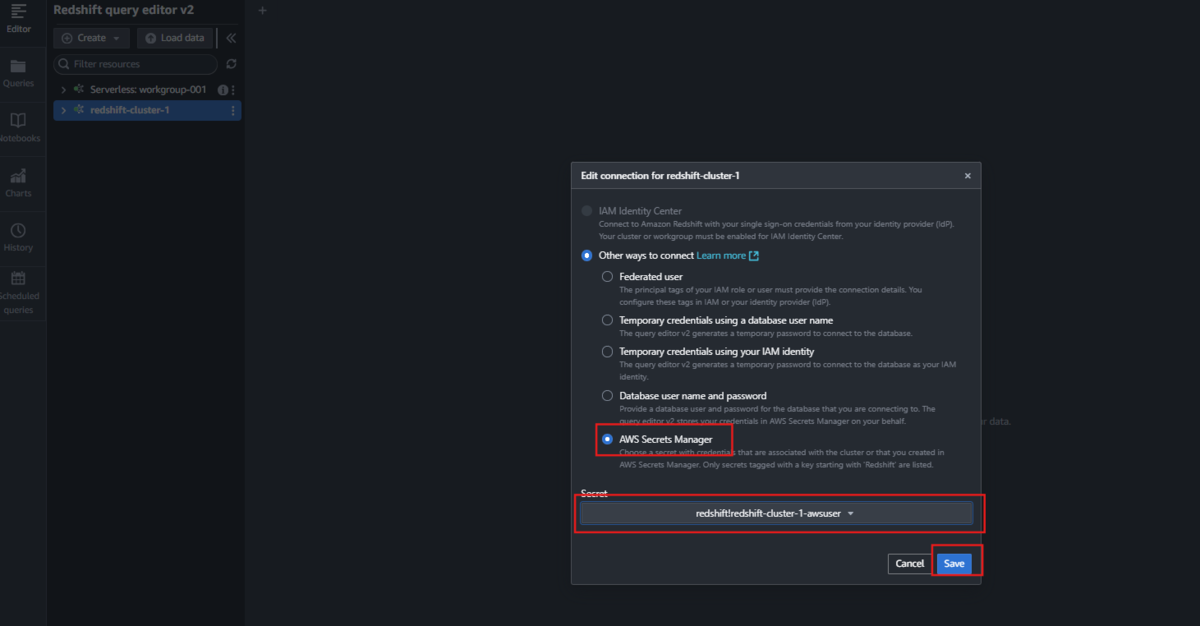
接続成功すると、native databases > dev > public > Tables の配下に、(クラスター作成時にサンプルデータをロードするよう設定している場合は)テーブルと、その中のデータが作成されています。
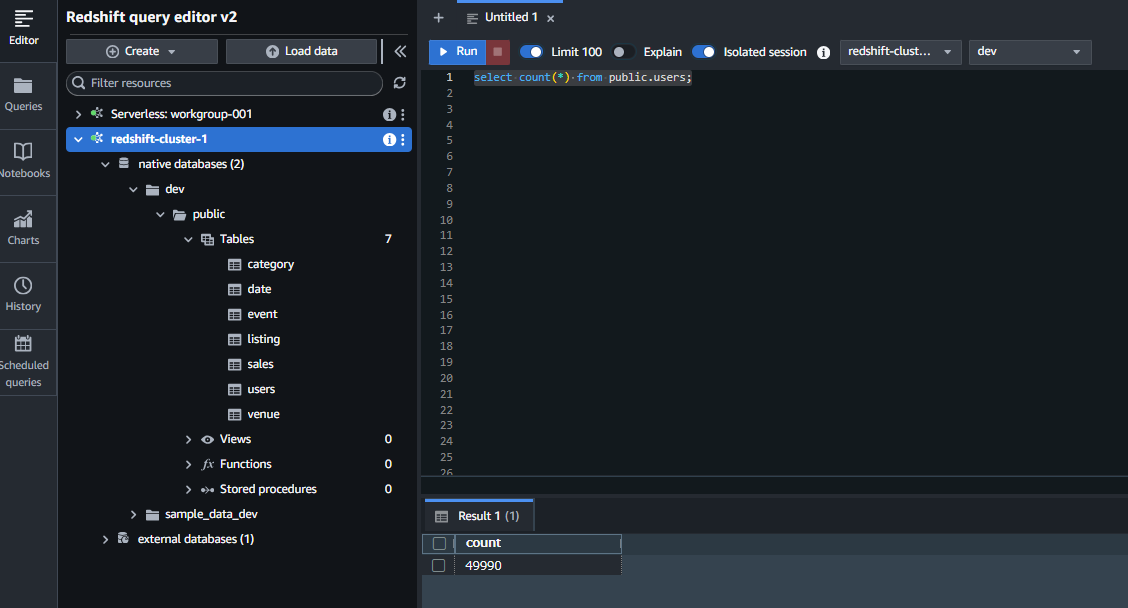
usersテーブルのレコード数を確認してみます。 以下クエリを入力して実行(RUN)すると、「49990」の結果が得られました。
select count(*) from public.users;
ナレッジベースの作成
作成したRedshiftクラスターをデータストアとするナレッジベースを作成します。 ※Redshiftを作成したリージョンに作成します。
構造化データストアとしては、2025/04/01現在はRedshiftのみのサポートのようです。
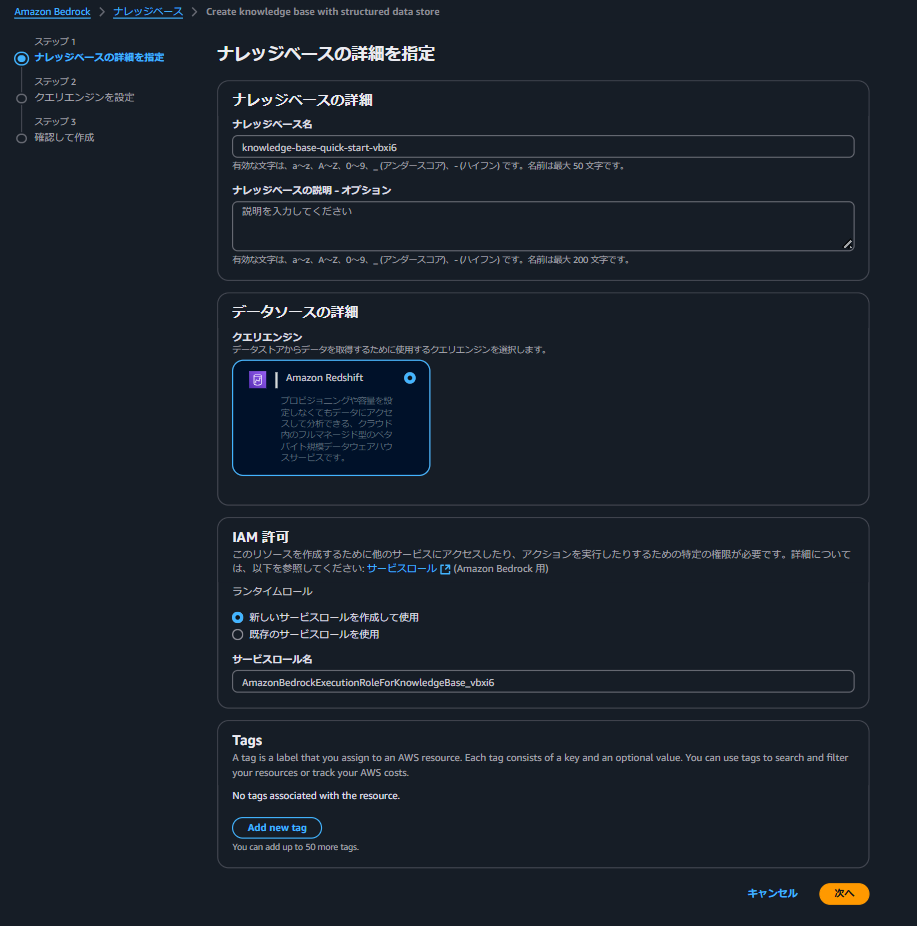
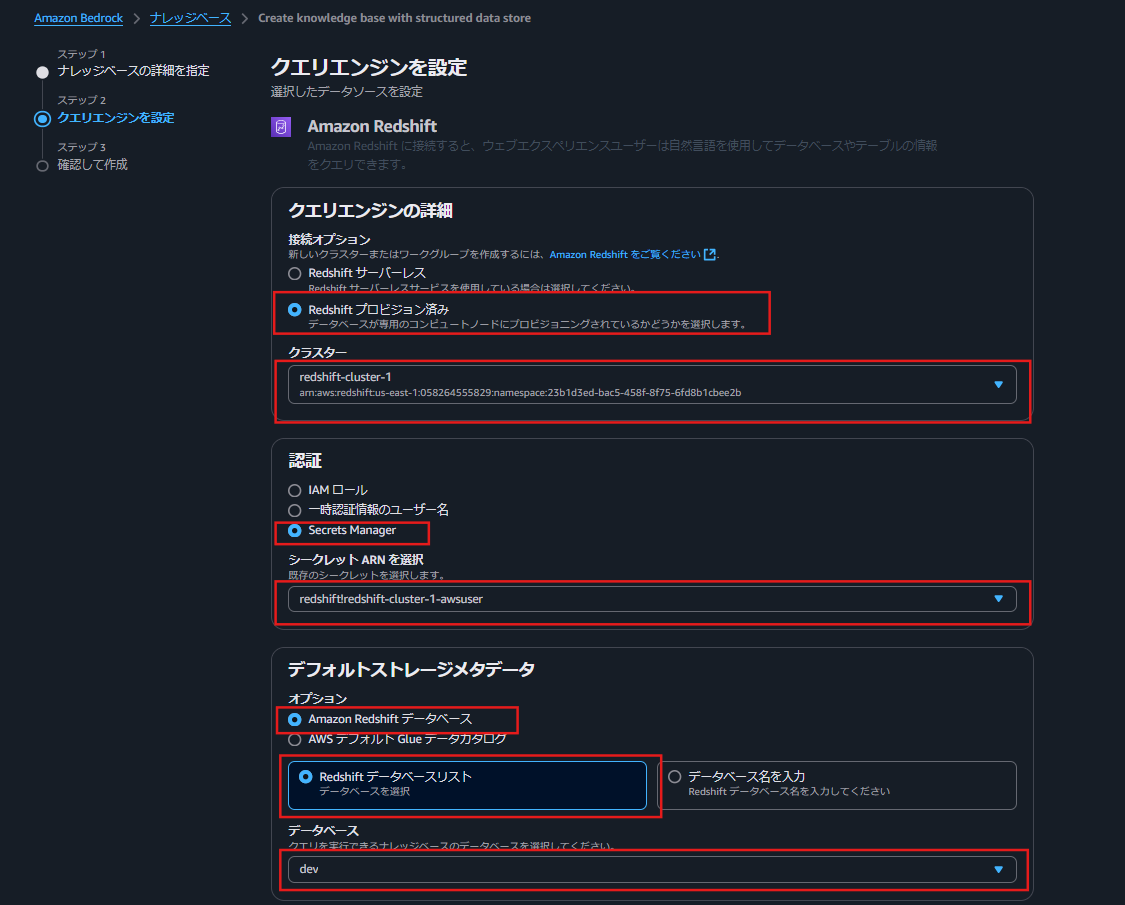
作成したクラスター、シークレット、データベースを指定します。
テーブル(または列)に対する説明、検索対象・検索対象外テーブル(または列)、サンプル質問と期待値のSQLクエリを設定することも可能です。 後から設定することも可能ですので、今回はスキップします。
ナレッジベースのテスト
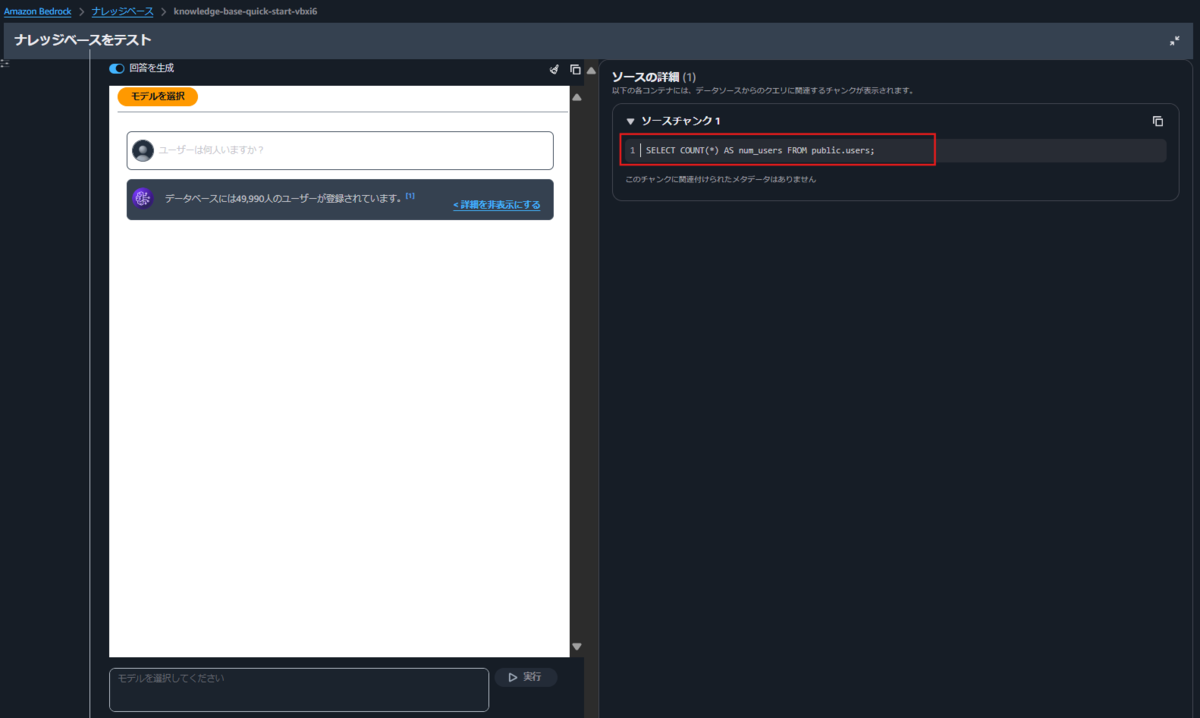
それでは早速作成したナレッジベースをテストします。 任意のモデルを選択し、自然言語で質問します。 Redshiftのテスト時にuserテーブルの件数を取得するSQLを実行しているので、同様の結果が得られることを期待して「ユーザーは何人いますか?」という質問にします。
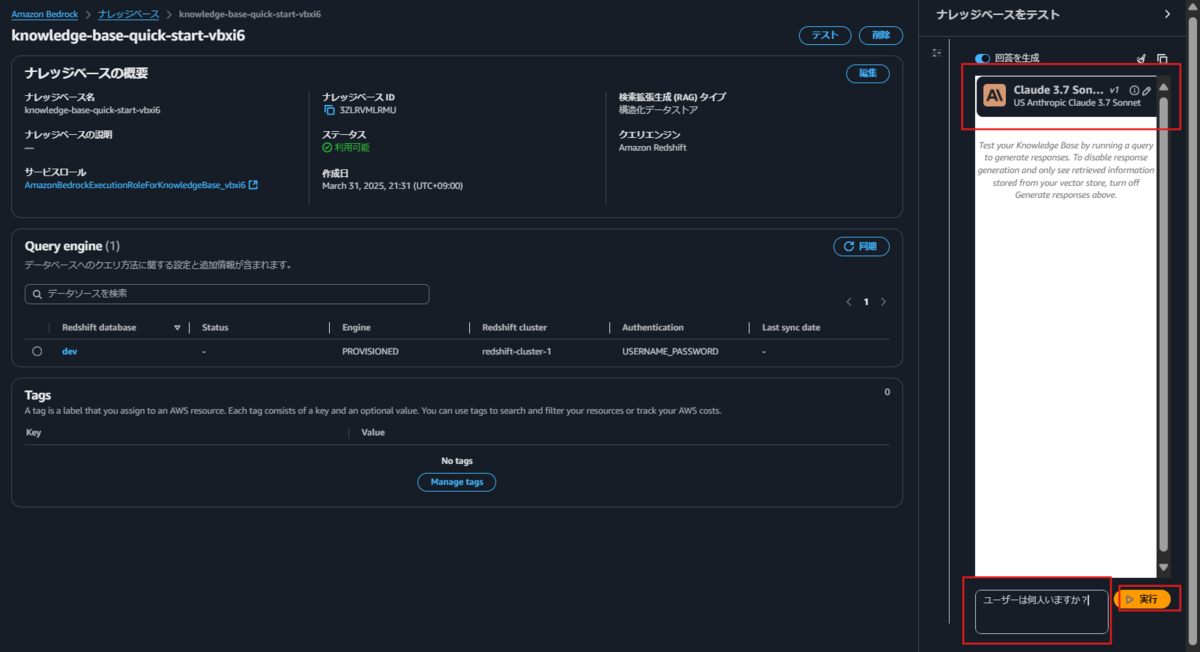
「No metadata found」と言われてしまいました。 このあたりはナレッジベースでベクトルデータストアを利用している場合と同様、事前に「同期」が必要です。
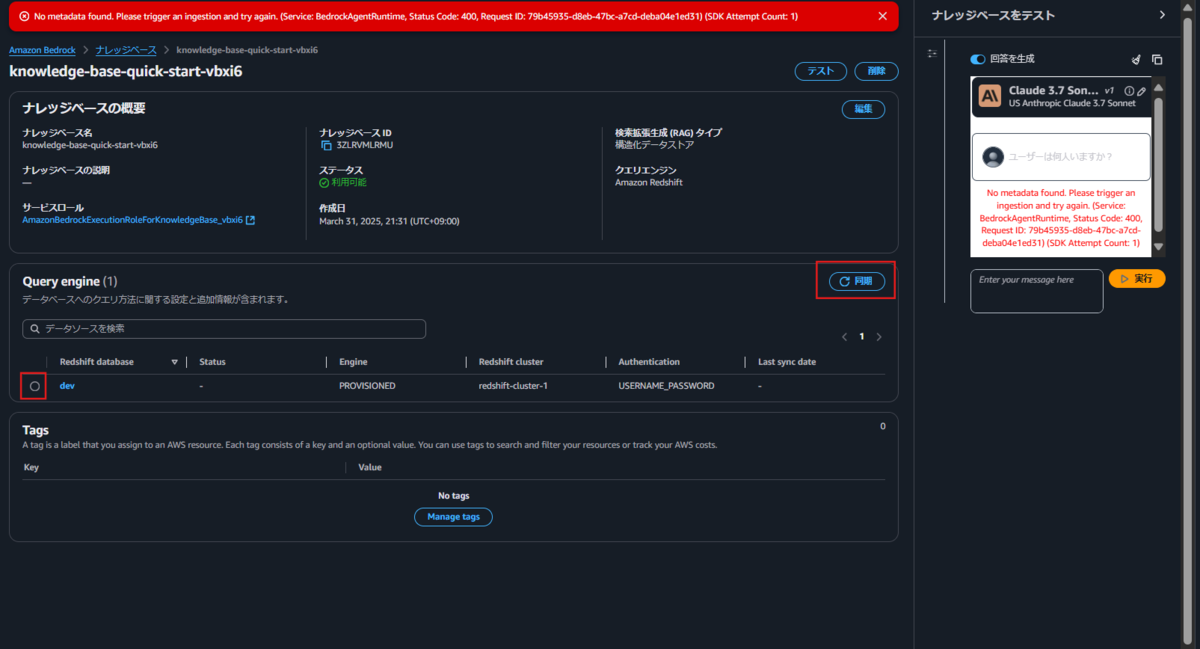
同期完了したため再試行します。
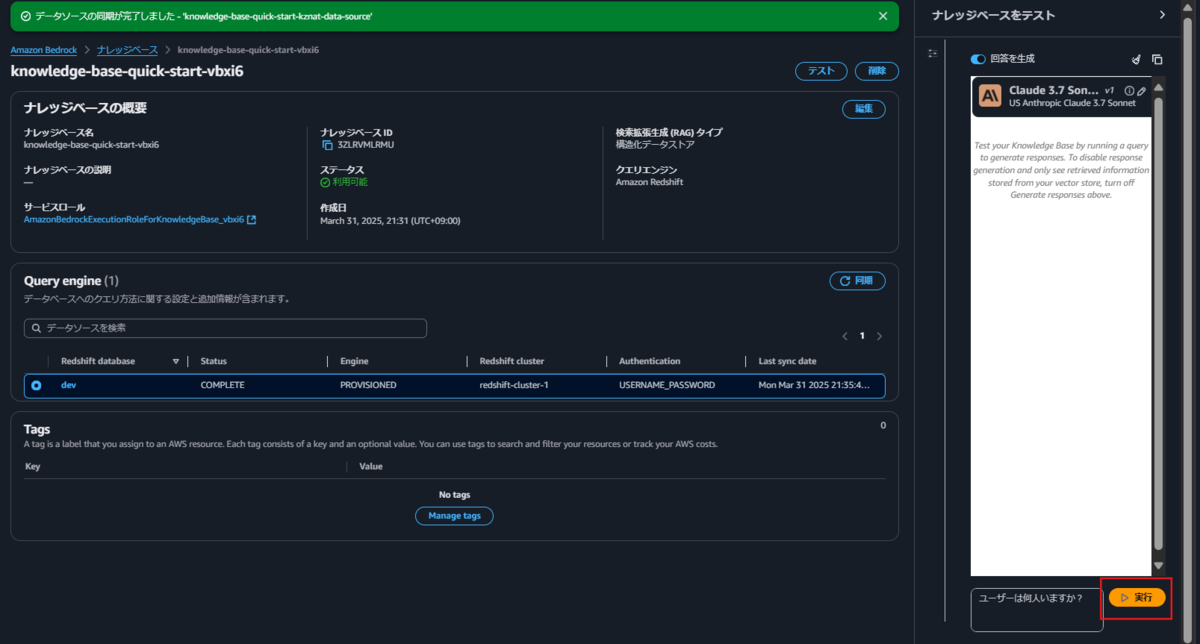
無事、Redshiftのテスト時と同様の数字(49990)が得られました。「詳細を表示」をクリックすると、発行されたクエリを確認できます。
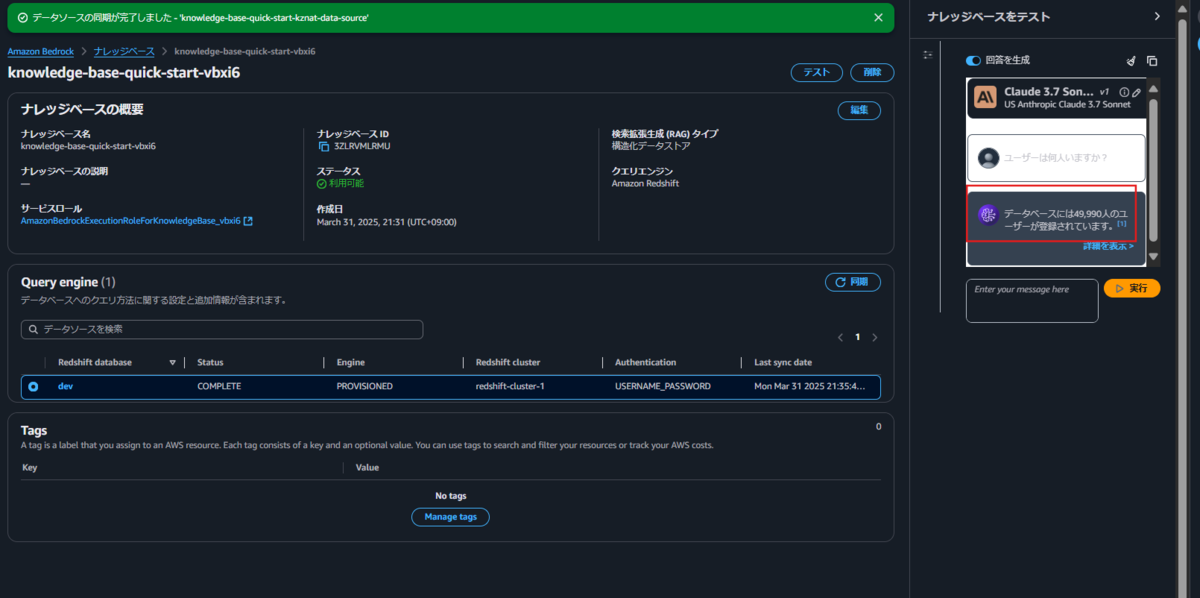
以下のようなクエリが発行されていますね。
SELECT COUNT(*) AS num_users FROM public.users;
まとめ
以上、ごくごくシンプルな設定内容ではありますが、構造化データストアについてご紹介させて頂きました。 意図的にリソースを残す場合を除き、一時的な検証目的で作成されたリソース(特に、Redshiftクラスターは最小構成でもそこそこ高額です)は削除を忘れないようご注意ください!
Yushi.Sakuraba(記事一覧)
アプリ出身クラウドエンジニア(絶賛奮闘中)