

はじめに
世の中では MCP に関する話題で盛り上がっています。ここではちょっとだけ過去に戻り、Retrieval Augmented Generation (RAG) の基本と、AWS における実装例についてまとめます。こちらのブログでも言及されていることに関連して、MCP は LLM にとって多様な データソース に対する繋ぎこみの規格を定め、それをツールとして使用することで単なるチャット AI ではなく、AI エージェントとして振舞えるよう(振舞いやすくするよう)にするための仕組みです。
今回まとめる RAG は、エージェントと横並びで比較する技術ではなく、エージェントアプリケーションの中に組み込まれる 1 要素です。個人や組織の情報など、OpenAI や Anthropic といった AI プロバイダが提供する LLM が、学習過程で利用されることのないデータを コンテキスト に含めて回答精度を上げるための重要な要素であると考えられます。
RAG を支える技術要素
LLM
大規模言語モデルは RAG の視点からみると最も基礎的な技術要素です。様々な組織が 事前学習済み のモデルをインターネット経由で使用できるサービスを提供したり、ローカルで稼働させるためにモデル自体を共有しています。
以下にサービスのプロバイダと主な言語モデルをまとめます。
| 組織 | 提供モデル例 |
|---|---|
| Anthropic | Claude 3.7 Sonnet, Claude 3.5 Haiku |
| Gemini 2.0 Flash, Gemini 2.0 Flash-Lite | |
| Meta | Llama 4, Llama 3.3 |
| OpenAI | GPT-4o, GPT-4.5, o3-mini, o1-pro |
※ 2025.04.16 時点のモデルのシリーズを記載(プレビューを除く)
埋め込み(Embedding)
「今日の東京の天気予報は一日雨なので、家を出るときには」
上記の文章に続く文章は何になるでしょうか。いくつか回答が考えられるかもしれませんが、1 つの例として「傘を忘れないようにしよう」のような文章が想像されます。
このように「傘」という単語(厳密にはトークンと呼ばれる単位の文字)を予想するための計算が行われています。そして、この計算を実行できるように数式に落とし込む際に用いられる基礎的な技術が Embedding です。
例えば以下の文章を扱う際には、まずそれぞれのトークンに対して数字を割り振ります(ここはまだ Embedding ではありません)。
Nuclear fusion is a reaction in which two or more atomic nuclei combine to form a larger nuclei, nuclei/neutron by-products.
OpenAI Tokenizer を利用すると Web 上で実際に文章をトークンに分解することができます。上記の文章は以下のように各トークンに対して ID が振られました。
[45, 53079, 48115, 382, 261, 21416, 306, 1118, 1920, 503, 945, 50468, 165125, 21700, 316, 1625, 261, 12384, 165125, 11, 165125, 167881, 141437, 656, 136589, 13]
ここから Embedding が機能します。1 トークンに対応する各要素に関して、Embedding を行い、以下のような 2 重配列が作成されます。
[ [0.21, -0.03, ..., 0.77], # ID 45 に対して Embedding が作用した ... [0.55, 0.12, ..., -0.01] # ID 13 に対して Embedding が作用した ]
Embedding は LLM が文章を生成する過程で用いられており、トークンをベクトル化することによってそれぞれのトークンの関係性を数学的に扱えるようにしています。
※ 後述しますが、Embedding はトークンという単位に作用させる方法だけではなく、トークンの集まり(文章)に対しても作用させることができます。
Bedrock で利用可能な Embedding モデル
Bedrock ではモデルアクセスが有効になっている場合、以下の Embedding モデルが利用できます。
| 提供元 | モデル名 | 入力モダリティ | 備考 |
|---|---|---|---|
| Amazon | Titan Embeddings G1 - Text V1.2 | テキスト | 最大トークン数:8,192。ベクトルサイズ:1536。多言語対応。詳細はこちら。 |
| Amazon | Titan Text Embeddings V2 | テキスト | 最大トークン数:8,192。ベクトルサイズ:256/512/1,024。100 以上の言語に対応。詳細はこちら。 |
| Amazon | Titan Multimodal Embeddings G1 | テキスト、画像 | テキスト(最大 256 トークン)または画像(最大 25MB)を入力可能。詳細はこちら。 |
| Cohere | Embed English V3 | テキスト(英語) | 英語テキスト専用。詳細はこちら。 |
| Cohere | Embed Multilingual V3 | テキスト(多言語) | 100 以上の言語に対応。詳細はこちら。 |
類似度算出
前セクションで紹介したトークンのベクトルに関して、それぞれのトークンがどのような関係性を持つのかについて、簡略化してまとめます。トークンであっても文章であっても、意味的に近いものはベクトルとしても近くに配置されます※。これは、トークンや文章が意味を持ったベクトルに変換されるように Embedding 用のモデルが学習されているためです。
一度ベクトル化されると、ベクトル同士の近さは数学的に算出できます。良く用いられるのが コサイン類似度 で、以下のように表されます。
cosΘ = a・b/|a|b|
Θ は 2 つのベクトル(a, b)の成す角度であり、この値が小さいほどそれぞれのベクトルが近い、つまり意味的に近いものであると解釈します。
※ 実際には近さだけではなく、ベクトルの差も意味を持ちます。
ベクターストア
ここまで紹介した技術により、ユーザーのクエリ文と、ベクトル化された文章の近さから意味的な検索を可能にします。扱うデータの特性からベクトルデータのクエリ処理に特化したデータベースの必要性から、ベクターストア(ベクトルデータベース)が使用されています。
Amazon Bedrock Knowledge base で指定可能なデータベース
| サービス名 | 種類 | 管理方式 | 特徴 |
|---|---|---|---|
| Aurora (pgvector) | RDB (SQL) | マネージド | pgvector による類似検索対応、PostgreSQL ベース |
| Neptune Analytics | グラフ DB | マネージド | GNN やセマンティック検索、グラフ分析と機械学習の統合 |
| OpenSearch Serverless | 検索エンジン | マネージド | ベクトル検索対応のフルマネージド検索、スケーラブル |
| OpenSearch Managed | 検索エンジン | マネージド | OpenSearch クラスタによる高度なチューニングが可能 |
| MongoDB Atlas | NoSQL | サードパーティ | ベクトル検索($vectorSearch)対応、柔軟なドキュメントモデル |
| Pinecone | ベクトル DB | サードパーティ | 高速・高精度な類似検索、RAG に最適化、クラウドネイティブ |
| Redis Enterprise Cloud | インメモリ DB | サードパーティ | Redis 7 以降で VSS 対応、高速、リアルタイム用途に強い |
Amazon Bedrock で構成する RAG
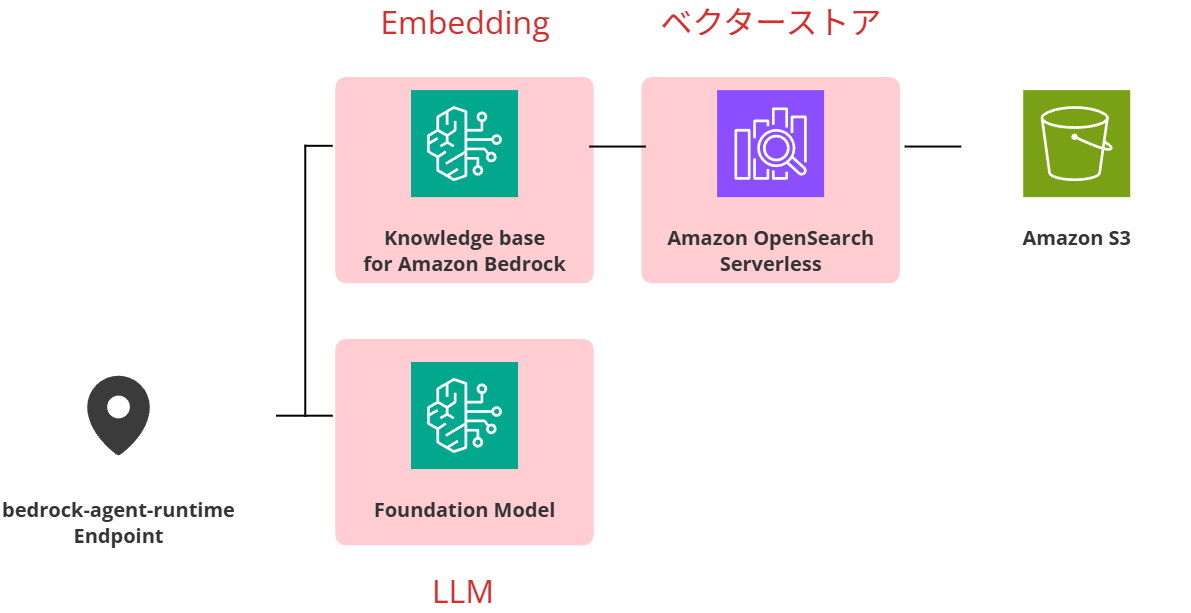
上図は AWS で RAG を構成する 1 例です。赤くハイライトした要素は、本記事で紹介した基本技術に対応する(設定する)サービスです。作成編 のブログでは Amazon Bedrock と Amazon OpenSearch Serverless を使用して独自のドキュメントをもとに回答を生成できるように設定していきます。