

最初に
こんにちは。孔子の80代目子孫兼ディベロップメントサービス課の孔です。英語勉強を始めました。そろそろコロナも終わるので、目指せ世界!で、アメリカ旅行を目指して英語勉強をやっています。いつか英語がペラペラになったら英語ブログにもチャレンジしてみたいですね。Hacker Newsに私のブログを載せるのが夢です。
前回までのブログでは、主にRDDを中心にPySparkの使い方を見てきました。今回からは新しいオブジェクトであるDataFrameを見ていきます。最近はRDDよりこちらのDataFrameが使われることが多いため、PySparkを学ぶ上でDataFrameの理解は必須不可欠となります。
それでは、長く言うまでもなく、さっそくDataFrameがどんなもなのか見ていきたいと思います!
DataFrameとは?
本ブログの引用元はすべてブログの最下段の「参考サイト」に記載されています。原文での確認をしたい方は「参考サイト」をご確認ください。
DataFrameの概要
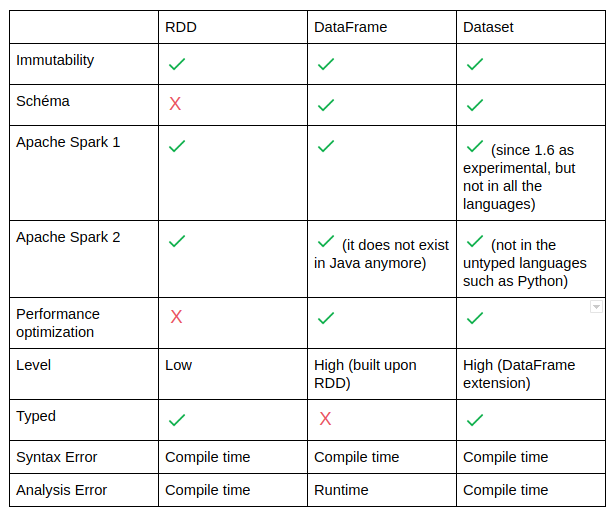
DataFrameは「名前の付いたカラムを持つ2次元のデータ構造」で、関係データベースのテーブルと同じ概念といえます。基本的にDataFrameはRDDをベースで作られたオブジェクトとなるので、障害から復旧が可能なところや、分散処理に強いなど、RDDの特徴を持っています。ただし、RDDにはない特徴がいくつかありますので、以下の表をご覧ください。
 (※4)
(※4)
大きな違いとして、「スキーマの有無」があります。4. 実戦!RDDを操作してプログラムを作ってみるで作ったプログラムで使用したサンプルデータがヘッダーのないCSVファイルを使用したのも、ここが原因となります。RDDはスキーマと持たないため、カラムを指定したりするときは、row[n]のようにインデックスを直接指定する必要があります。しかしDataFrameは「名前の付いたカラムを持つ2次元のデータ構造」であるため、カラムを論理名で指定して操作することができます。よって、データの操作がより楽になります。
基本的に、RDDより使いやすく、よりパフォーマンスよくを実現するために考案されたのがDataFrameなので、これから紹介する特徴はそれを念頭に置いて読んでいただくとよりスムーズに理解できるかと思います、それでは、DataFrameの特徴を見てみましょう。
※ 雑談:RDDとDataFrame以外に、Datasetというオブジェクトも存在しますが、このブログシリーズでは省略します。実は、Spark 2.0になる際に、DataFrameとDatasetは統合されましたが、PySparkではDataFrameが使われています。理由としては表から読み取れる通り、Datasetは型チェックを行うオブジェクトとなりますが、Pythonには型を固定する概念がないため、使用されておりません。
DataFrameの特徴
DataFrameは以下の特徴を持ちます。
性能最適化
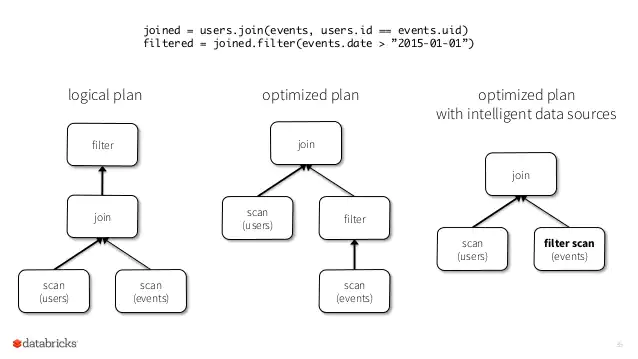
DataFrameは性能を最適化するCatalystと呼ばれるフレームワークが実装されています。このフレームワークはコードを見て、よりコストのかからないような順番でコードを実行します。例えば、「結合処理(Join)→抽出処理(Filter)」をするコードがあったとしたら、結合する前に抽出処理を先にしたほうが結合するレコード数を減らせるので効率よく処理することが可能です。このような実行の順番を最適化する機能を持っています。
 (※2の35p)
(※2の35p)
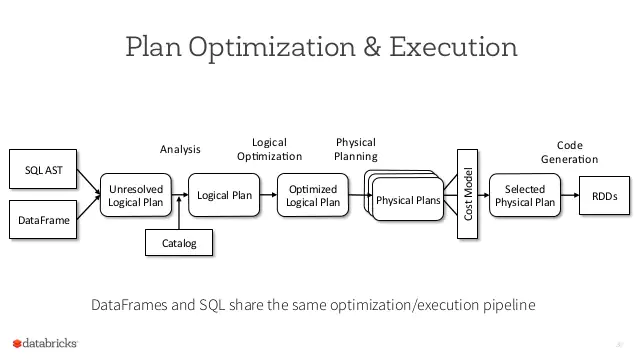
作成したコードでは、JoinをしてからFilterをしていますが、実際実行されるときはFilterを先にやってからJoinが行われることがわかります。まとめると、DataFrameの処理順番は以下のような流れで最適化されます。
 (※2の30p)
(※2の30p)
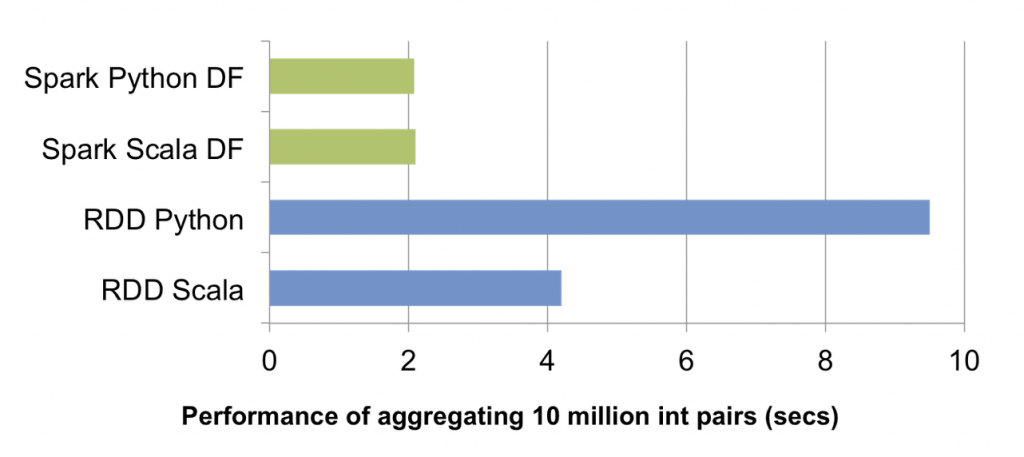
このような最適化によって、RDDよりDataFrameは圧倒的に早いパフォーマンスを見せています。
 (※1)
(※1)
内部データをrowオブジェクトで保持
DataFrameは内部で持つデータをすべてrowオブジェクトで保持しており、このrowオブジェクトはDataFrameオブジェクトのプロパティのように使用可能です。以下DataFrameを使ったコードの例の一部となります。
people = spark.read.parquet("...")
ageCol = people.age
peopleはDataFrameオブジェクトで、people.ageの形でDataFrameが持っているageカラムを簡単に取得できます。ただし、ageの型が何なのかはわからないため、型安全ではありません。もし型安全が必要であれば、Datasetを使用する必要があります(その場合、そもそもPythonでない言語を学ぶしかありません…(´;ω;`)ウッ…)
Spark SQLの使用可能
DataFrameがRDDより使いやすい理由のうち一つが、DataFrameではSQLがそのまま使用できるところです。既存の多くのデータ分析コードは、RDBを基盤としたSQLで作成されていることが多いので、そのコードをそのまま引き継ぐことができることは大きなメリットとなります。また、多くのデータ分析を行うエンジニアはSQLはすでにマスターしていることが多いので、慣れた言語でSpark基盤を使用できるのも大きなメリットの一つとなります。以下はPySparkでSQLを使用するコードの例の一部です。
>>> df.createOrReplaceTempView("table1")
>>> df2 = spark.sql("SELECT field1 AS f1, field2 as f2 from table1")
>>> df2.collect()
[Row(f1=1, f2='row1'), Row(f1=2, f2='row2'), Row(f1=3, f2='row3')]
spark.sqlメソッドで、SQLコードをそのまま使用していることがわかります。このように、純粋なSQLコードを使って、データの操作ができるのはDataFrameを使う大きなメリットの一つとなります。
RDDとの互換
一般的なケースではRDDよりDataFrameが性能もよく、使い勝手もいいのでDataFrameが選択されることが多いですが、基本的にDataFrameはRDDより高次元のAPIなのでRDDでしかできない操作が発生することがあります(MapReduce処理など)
この場合、一時的にDataFrameをRDDに変換して処理を行うことが可能です。変換は以下のコードで行います。
rdd = DF.rdd() # DataFrameからRDDへ変換 df = rdd.toDF() # RDDからDataFrameへ変換
Pandasとの連携
Pythonでのデータ分析といえば必須ライブラリ、Pandasがあります。PandasにもDataFrameオブジェクトが存在しますが、実はこのPandasのDataFrameをそのままPySparkのDataFrameとして使用することが可能です。
# Convert Spark DataFrame to Pandas pandas_df = young.toPandas() # Create a Spark DataFrame from Pandas spark_df = context.createDataFrame(pandas_df)
Pandasコードに簡単にPySparkを織り込むことも可能なので、既存のコードを利用してより強力なアプリケーションを実装できるのも、大きな強みの一つですね。
最後に
今回はRDDにとってかわる存在として登場したDataFrameについてみてみました。基本的にPySparkを触る際にはDataFrameを使ってコードを書くのが多くなるかと思いますので、しっかり概念を理解して使いこなしていきましょう。
それでは、次回のブログではPySpark SQLを紹介します。それでは、お楽しみに!
参考サイト
前回の記事
※1. DataFrameリリースブログ
※2. DataFrameリリース発表資料
※3. DataFrameリリース発表動画
※4. 画像の引用元