

はじめに
こんにちは。孔子の80代目子孫兼ディベロップメントサービス課の孔です。この前久しぶりにリーダブルコードを再読しました。名著は何回読んでも面白いですね。イラストがとても好きで、文章で説明すると2ページかかる内容が絵一枚で説明できるイラストレーターのセンスがとてもいいなと思ってました。
前回のブログでは、Dockerを使ってPySparkの環境を構築してみました。基本的にこのブログは読むだけでもある程度概念の理解やPySparkの使い方が理解できるように書いていますが、手を動かして実際コードをなぞったり、実行してみたりするとより理解が進むと思いますので、ぜひ環境を構築して手を動かしながらブログ内容を追っていただけると嬉しいです。
今回は、実際RDDというPySparkで使用するデータモデルを操作して、データをいじってみましょう。RDDがなんなのか、どのように操作できるのかに関する話が今回のブログの中心となります。それでは、さっそく本題に入りましょう!
RDDとは?
RDDとは「Resilient Distributed Datasets」の略語となります。Resilient Distributed Datasetsの名前を1単語ずつ理解すると、RDDがどのような特徴を持つかがわかります。
Resilient(回復力のある):演算途中で何かしらの障害でメモリからデータが消失しても、回復できる
Distributed(分散された):分散処理を行う複数のノードのメモリに分散される
Datasets(データセット):Sparkのデータモデル
本シリーズの一回目のブログ「1. PySparkとは?」でSparkが「分散処理を用いて大容量のデータを分析するためのフレームワーク」であると話しましたが、肝となる分散処理を実現するためにRDDは上記のような特徴を持ったデータモデルとなりました。それでは、このRDDがどのような原理で動くのかを見てみましょう。
RDDが障害から復旧する原理
結論からいうと、RDDに対してデータ変換処理を行うAPIを実行する際に、RDDは実際変換処理をするのではなく、どのオブジェクトをどの順番で変換処理を行っていくか、を覚えるだけの仕様となるため、障害から復旧ができます。RDDは不変の特性を持ちますので、RDDにFilterやMap処理(代表的な変換処理用API、後ほど紹介します)を行うと、その変換処理の情報を持った新しいRDDが生成され続けます。図で表すと以下のようなDAG(Directed Acyclic Graph、有向非巡回グラフ)(※1)の形態の図になります。
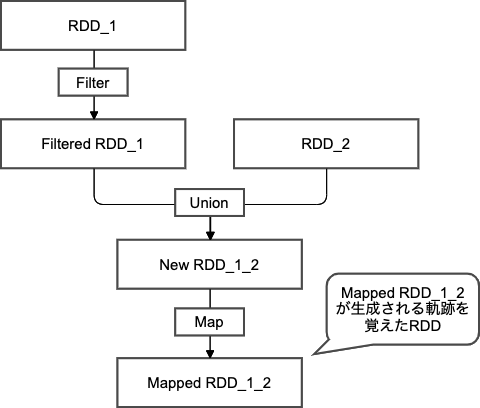
処理の順番さえ覚えておけば、もし処理途中でデータが消失されてもいつでも、覚えていた順序に従ってやりなとせばいいので回復できるようになっています。トランザクションログを残して復旧するデータベースのリカバリ機能と似たようなイメージです。
遅延評価(Lazy Evaluation)
遅延評価(※2)とは、APIがコールされた際に、即時に処理を行わないで、必要な時が来るまで処理を遅延させることです。Pythonだと、ジェネレーター(※3)を遅延評価を使って実装します。遅延評価のいいところは、即時に処理をしてリターンされるデータを保存しておく必要がないので、メモリの使用量を大幅に減らせることができることにあります。Sparkはインメモリ処理で高速処理を実現していますが、それを可能にするのがこのRDDの遅延評価のおかげとなります。
実際、PySparkコードで例を見てみましょう。前回のブログPySparkの環境構築で立ち上げたコンテナ環境のターミナルから実行しています。
(base) jovyan@3eecdb8ae16d:~$ pyspark
Python 3.9.5 | packaged by conda-forge | (default, Jun 19 2021, 00:32:32)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
......(中略)
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.5 (default, Jun 19 2021 00:32:32)
Spark context Web UI available at http://3eecdb8ae16d:4040
Spark context available as 'sc' (master = local[*], app id = local-1627554562955).
SparkSession available as 'spark'.
>>> sample_text = sc.textFile('file:///home/jovyan/sample.txt') # sample.txtファイルからRDDを生成
>>> filtered_sample_text = sample_text.filter(lambda x: 'test' in x) # sample.txtファイルの中で、"test"という文字列を含んだ行のみを抽出
>>> filtered_sample_text.count() # countメソッドで行数を数える
3
>>> sample_text.count()
5
>>> sample_text.count()
5
ここで、「テキストファイルの読み込み」と「フィルタリング」二つを処理はいつ行われるのでしょうか?正解は、countメソッドがコールされたら実際に読み込みとフィルタリング処理が開始します。countメソッドがコールされたら実際に読み込みとフィルタリング処理が開始するため、この処理では3回のファイル読み込みと、1回のフィルタリング処理が実際には行われます。これは、実際間違ったファイルを読み込んでみると簡単に確認できます。
>>> sample_text = sc.textFile('file:///home/jovyan/malnamed.txt') # 存在しないファイルを読み込む
>>> filtered_sample_text = sample_text.filter(lambda x: 'test' in x)
>>> filtered_sample_text.count()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
(中略)
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/home/jovyan/malnamed.txt # countメソッドを実行して漸くファイルがないことでエラーになる
(以下省略)
気を付けるところは、共通処理が発生する場合には、それを毎回行うのは効率が悪いですね(上記の処理でいうと、テキストファイルを読み込む処理を3回もやるのは無駄ですね)そういう時は、RDDobj.persist()(上記の例だとsample_text.persist())メソッドを使用するとメモリに常駐させることができますので、必要な際には適切にご利用ください。
概要まとめ
Sparkの主要な特徴のうち「分散処理」と「インメモリ処理」がありますが、これが実現できるのはRDDというデータモデルのおかげです。最近の主流はData Frameというオブジェクトを使ってデータを操作してますが、Sparkの最も基本となる概念はこのRDDとなりますので、理解しておくとこれからSparkを学んでいくうえで必ず役に立つかと思います(Data Frameに関しても後ほど取り上げます)よりRDDの具体的な内容が知りたい方は、ブログの一番下に参考サイトを載せてますのでご参照ください(※4)
RDDを操作するAPI
それでは、実際RDDを操作してみましょう。ここでは代表的なAPIを紹介します。SparkのRDD操作APIは、大きく「変換(Transformations)」と「実行(Actions)」に分かれます。先ほど見た例で、Filterは変換に、Countは実行になります。それでは、それぞれの処理の概要と代表的なAPIを見てみましょう。
ここで紹介するAPI以外でもっといろいろなAPIを知りたい方は、ブログの一番下の参考サイトにレファレンス載せてますのでご参照ください(※5)
変換API
変換APIは、既存のRDDに対して変換処理を行う(正確にはどんな変換処理を行うか情報を持たせた新しいRDDを生成)APIとなります。返り値は新しいRDDとなります。代表的なAPIは以下のようなものがあります。
map
関数型プログラミング言語でおなじみ、mapです。引数に関数を渡すとRDDの持っているデータをその関数でマッピングしたRDDを返します。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) mapped_rdd = rdd.map(lambda x: x**2) result = mapped_rdd.collect() # collectメソッドは後ほど説明します print(result) >>> [1, 4, 9, 16, 25]
mapValues
Key-ValueペアのRDDに対して、キーを維持したままバリューに対してマッピング処理を行います。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [ ('Fruits', ['Apple', 'Banana', 'Melon']), # (K, V) ('Vegitables', ['Carrot', 'Tomato']), ('Meats', ['Chicken', 'Lamb', 'Pork', 'Beef']), ] rdd = sc.parallelize(data) grouped_rdd = rdd.mapValues(lambda x: len(x)) result = grouped_rdd.collect() print(result) >>> [('Fruits', 3), ('Vegitables', 2), ('Meats', 4)]
groupByKey
名前通りのインターフェースで、同じキーを持ったバリューをグルーピングさせる変換処理となります。もちろん、もともとのデータが(K, V)の形でないと使用できません。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [ ('Fruits', 'Apple'), ('Vegitables', 'Carrot'), ('Meats', 'Chicken'), ('Fruits', 'Banana'), ('Vegitables', 'Tomato'), ('Meats', 'Pork'), ('etc', 'Rice') ] rdd = sc.parallelize(data) grouped_rdd = rdd.groupByKey().mapValues(list) result = grouped_rdd.collect() print(result) >>> [('Fruits', ['Apple', 'Banana']), ('Vegitables', ['Carrot', 'Tomato']), ('Meats', ['Chicken', 'Pork']), ('etc', ['Rice'])]
filter
元のRDDの持った複数のデータの中から、条件に当てはまったデータのみを残したRDDを返します。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) filtered_rdd = rdd.filter(lambda x: x > 3) result = filtered_rdd.collect() print(result) >>> [4, 5]
union
2つのRDDが持ったそれぞれのデータを合わせます(distinct, intersectionもあります)
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data1 = ['aa', 'bb', 'cc'] data2 = ['dd', 'ee', 'ff'] rdd1, rdd2 = sc.parallelize(data1), sc.parallelize(data2) union_rdd = rdd1.union(rdd2) result = union_rdd.collect() print(result) >>> ['aa', 'bb', 'cc', 'dd', 'ee', 'ff']
実行API
実行APIは、RDDにかかっていた変換APIを処理させ、その結果をもって処理を行った結果を返します。返り値はデータセットもしくは実行結果となります。また、外部ディスクに処理結果を書き出すこともできます。代表的なAPIは以下のようなものがあります。
collect
RDDが持っているすべての要素をリストで返します。RDDが現在持っているデータをすべてメモリに乗せるので、大きすぎるRDDに対して使う際には気を付けましょう。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) result = rdd.collect() print(result) >>> [1, 2, 3, 4, 5]
count
RDDが持った要素を数え、intを返します。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) result = rdd.count() print(result) >>> 5
top
リストの中から、トップn個の要素を取り出して新しい降順のリストを返します。演算の際にはRDDをすべてメモリに乗せるので、使う際には注意が必要です。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) result = rdd.top(2) print(result) >>> [5, 4]
reduce
RDDの要素を、引数で渡した関数に従って統合します。関数は2つの引数をとって、一つの値を返す関数のみ使用できます。
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) result = rdd.reduce(lambda x, y: x + y) print(result) >>> 15
saveAsTextFile
RDDの結果をテキストファイルとしてディスクに書き出します。適切にディスクに書き出しながら変換処理を挟めていくと、データが消失された際に最初から処理をやり直さなくても済みます。なので、適宜ディスクに処理結果を書き出すことが実際のプログラムを作る際にはとても重要です。
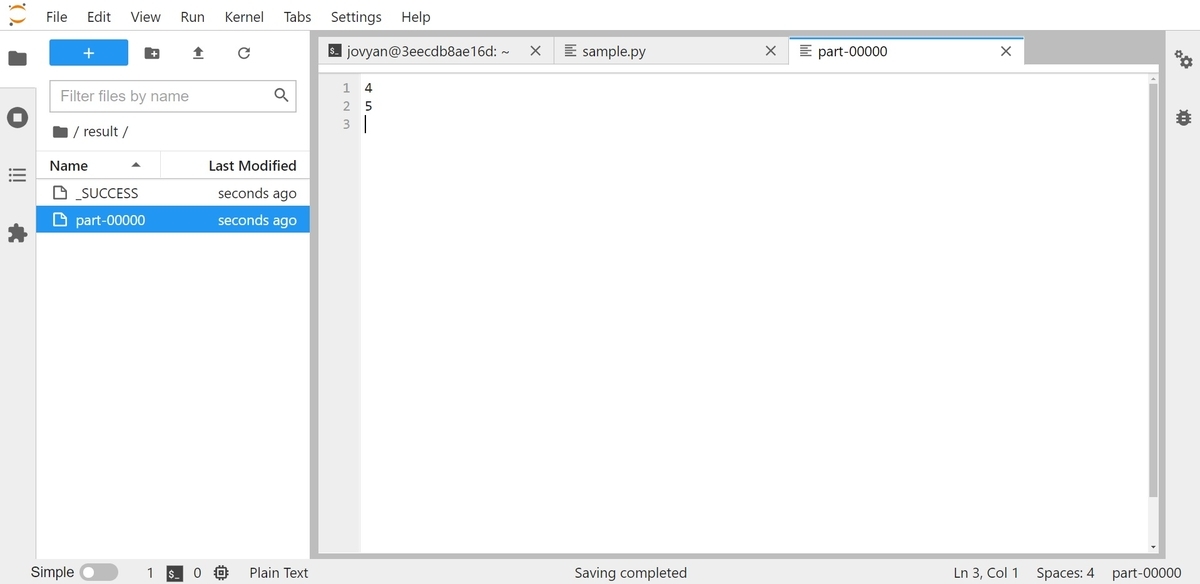
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('blog sample').setMaster('local') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) filtered_rdd = rdd.filter(lambda x: x > 3) filtered_rdd.saveAsTextFile('/home/jovyan/result')
resultフォルダーに生成されるファイルと中身となります。
最後に
今回はRDDがどのようなもので、どんな感じで操作するのかを紹介しました。RDDはSparkにおいて最も基本となるオブジェクトになるので、少し長くなってしまいました。次回は、もう少し実戦に入って、RDDを使った簡単なプログラムを作って、よりRDDを操る際のイメージをつけていけたらと思います。それでは、また会いましょう!
参考サイト
前回の記事
※1. DAG(有向非巡回グラフ)とは
※2. Haskellでの遅延評価
※3. Pythonのジェネレーター
※4. RDDとは
※5. RDDのAPIレファレンス