

- 2024年8月15日 の ECS のアップデート
- 検証内容
- ECS サービス単体で必須コンテナが「はい」の場合
- 注意事項
- ECS サービス単体で必須コンテナが「いいえ」の場合
- ALB と紐付けた ECS サービスの場合
- 再起動ポリシーのパラメータを試してみる
- まとめ
- 余談
2024年8月15日 の ECS のアップデート
Amazon ECS に新しい機能が追加されました。この機能は、タスクを再起動せずに特定のコンテナだけを再起動できるようにするものです。これにより、ネットワークの問題や予期しない停止があったときに、自動でコンテナを再起動できます。以前は、重要なコンテナが停止すると、タスク全体を再起動する必要がありましたが、今回のアップデートでその必要がなくなります。 必須コンテナの場合も、そうでない場合も再起動ポリシーを設定できます。
これまでのやり方
- コンテナが停止すると、タスク全体を再起動していました。
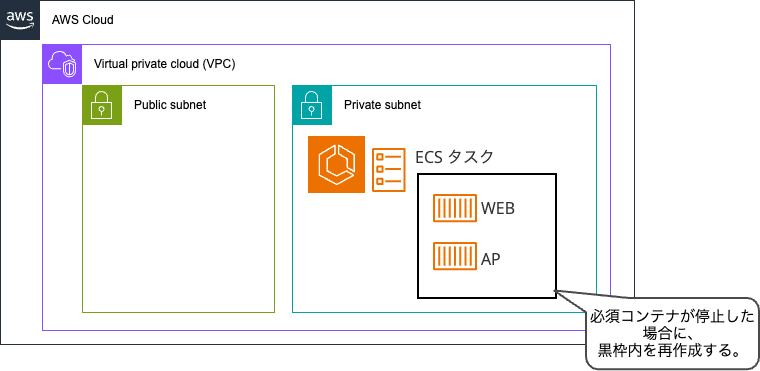
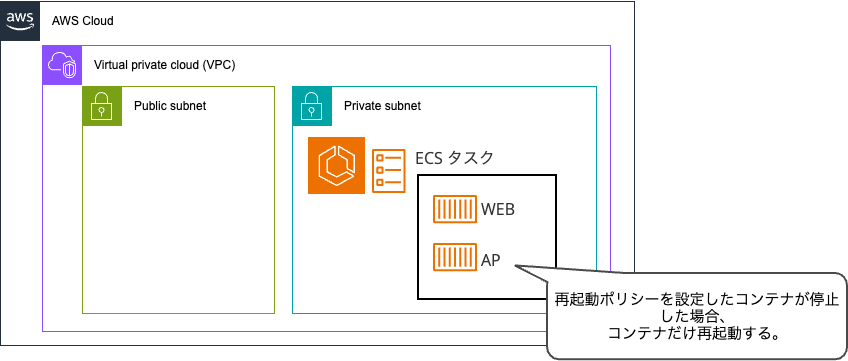
新しいやり方
- 「再起動ポリシー」を設定することで、停止したコンテナのみを再起動できます。
公式ドキュメントのリンク
関連のある公式ドキュメントのリンク
検証内容
この文章では、ECS on Fargate で新機能を検証しました。Fargate を使用する場合、プラットフォームバージョンは 1.4.0 以降である必要があります。なお、ECS on EC2 については別の機会に取り上げます。
使用上の考慮事項等はドキュメント もお読みください。
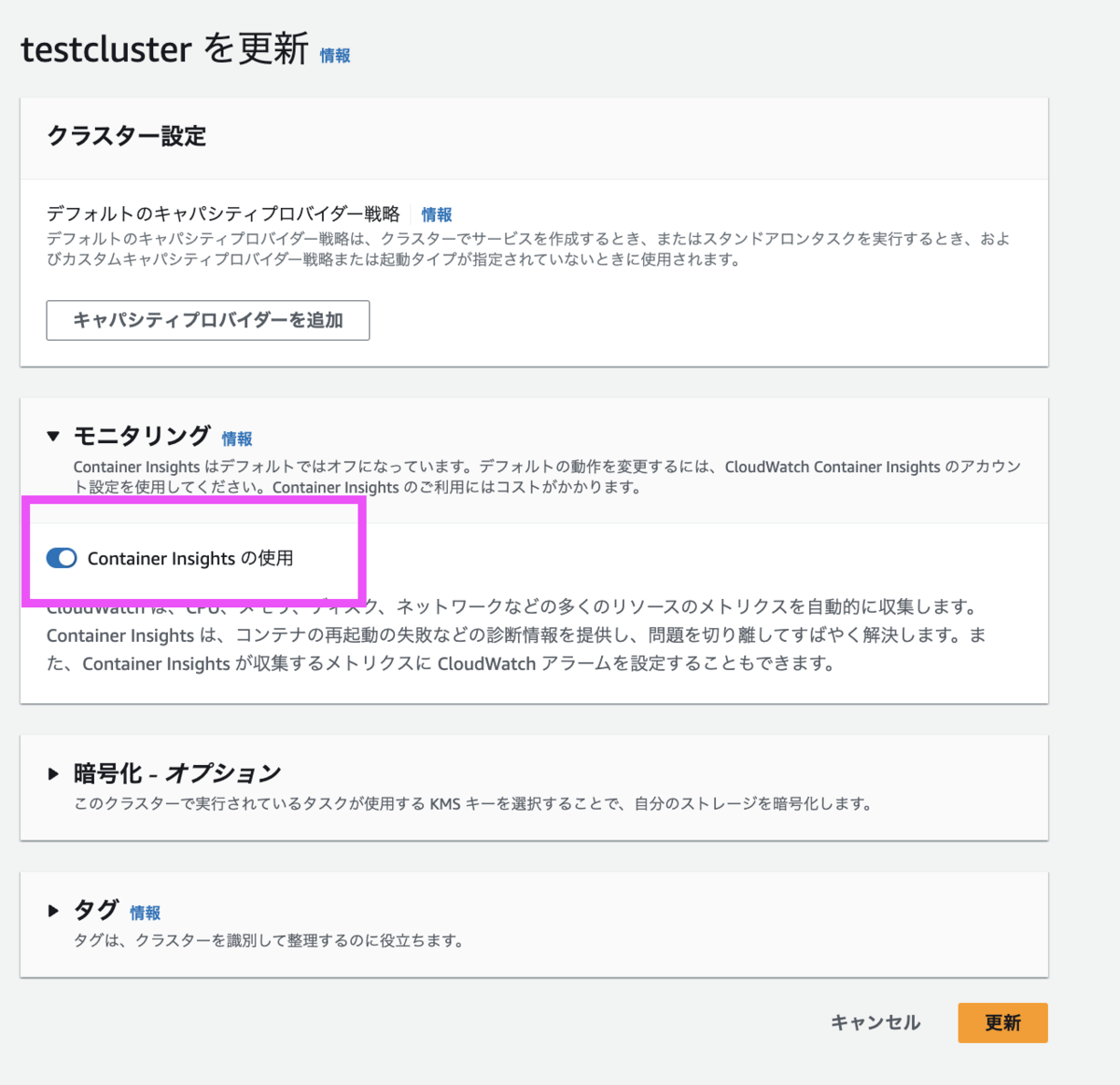
Container Insights の設定
クラスターの 「Container Insights の使用」をオンにすると、RestartCount というメトリクスで、コンテナ再起動の回数が見れるようになります。
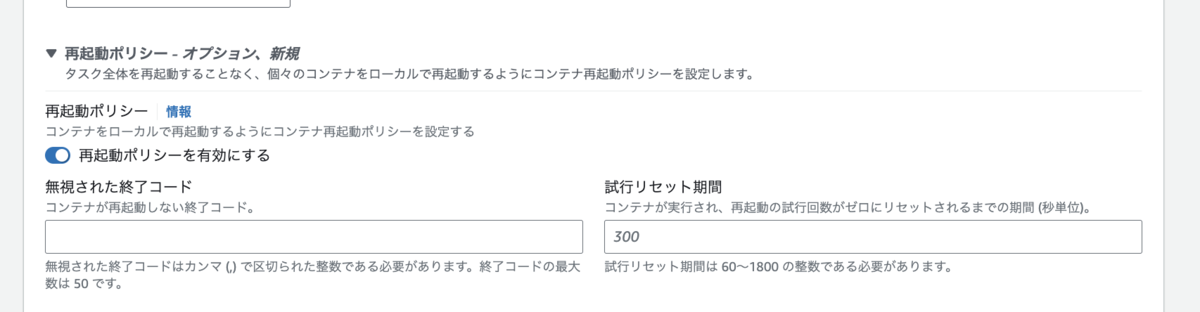
再起動ポリシーの設定
- タスク定義に再起動ポリシーを設定することができます。「再起動させない終了コード」や、「再起動を試みる前にコンテナを実行する必要がある時間」も指定可能です。
「再起動ポリシーをオン」のみの動作を確認しましょう。
ECS サービス単体で必須コンテナが「はい」の場合
結果:コンテナの再起動はほぼ、想定通り動作しました。
イメージ:
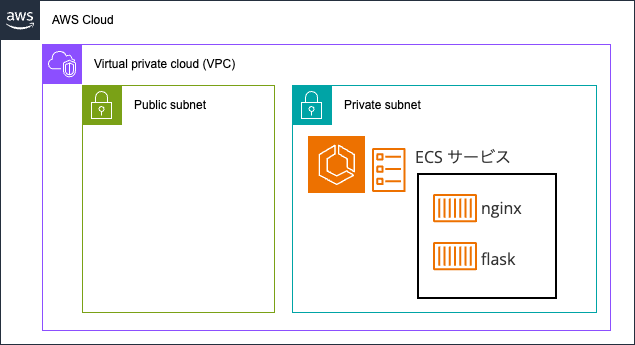
タスク定義の中で nginx コンテナの「必須コンテナ」属性を「はい」にします。
サービスを作成し、タスクを1つ起動しました。
nginx コンテナ、flask コンテナがあります。
Amazon ECS Exec を使ってコンテナにログインし、nginx のプロセスを再起動し、コンテナを停止させます。
もちろん、 service nginx stop でも大丈夫です。

コンテナ再起動はせずに、タスク自体が停止しました。
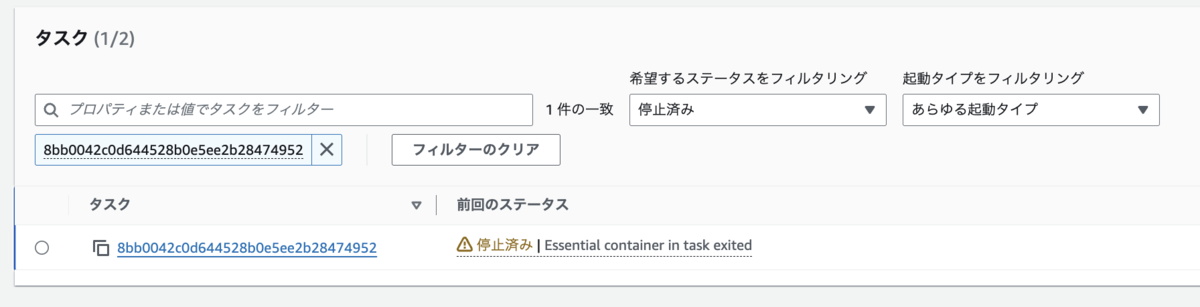

そして、新しいタスクが起動していました。
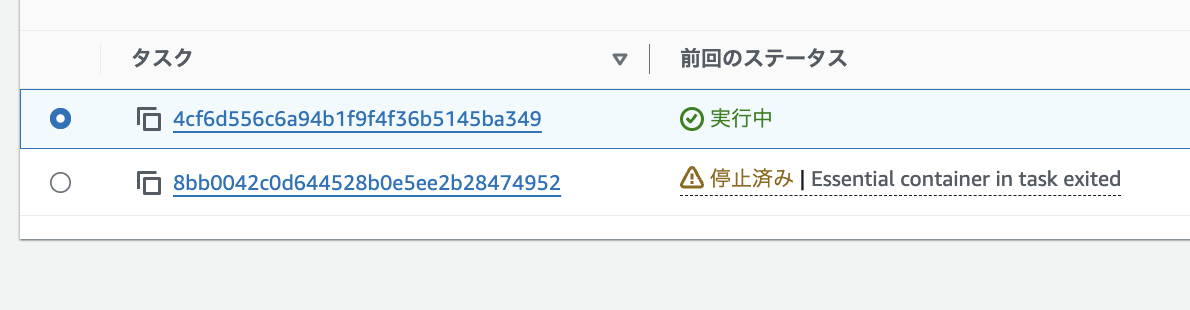
コンテナ再起動は、起きていませんでした。
CloudWatch メトリクスから RestartCount のメトリクスを参照しても、0 になっていました。
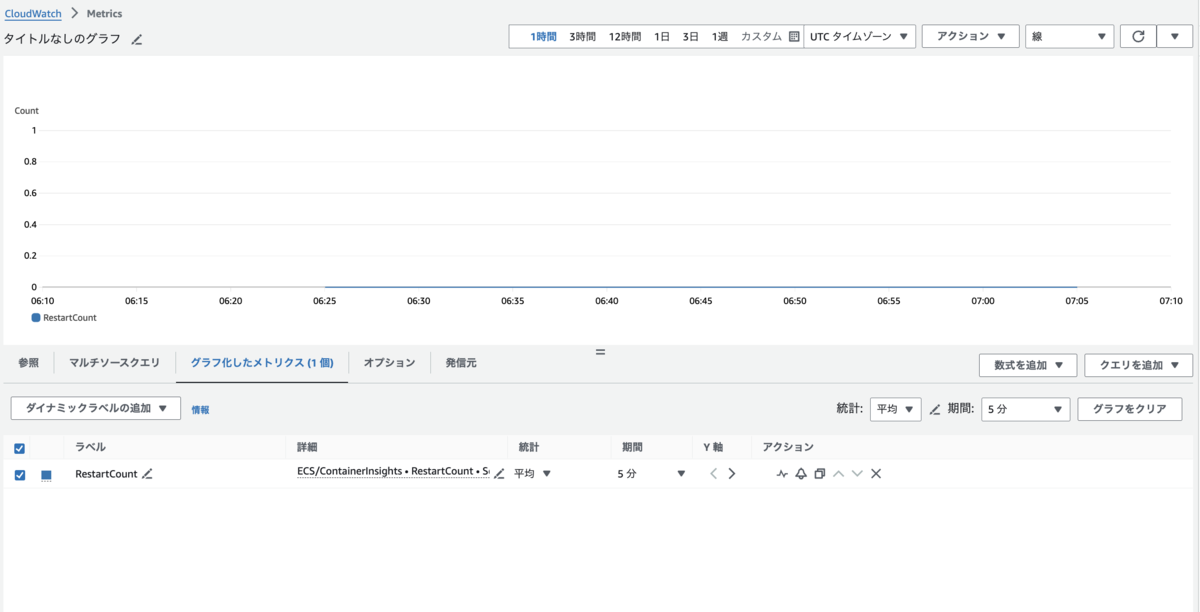
これは、想定外です。
何度タスクを停止して、新しく作り直しても、コンテナの再起動が実行されません。
原因は、ECS サービスにタスクが起動してすぐに、nginx のプロセスを再起動 (service restart nginx)したことでした。
ドキュメント の「考慮事項」に以下の記載があります。
Amazon ECS エージェントは、コンテナの再起動ポリシーを処理します。予期しない理由で Amazon ECS エージェントに障害が発生したり、実行されなくなったりすると、コンテナは再起動されません。
Fargate の場合は、ECS エージェントを意識する必要はないので、普段は全く気にしていませんでした。
何回か試していて、タスクが開始して「実行中」状態になってから数分してから、service nginx restart を実行すると、コンテナの再起動が実行されることに気が付きました。
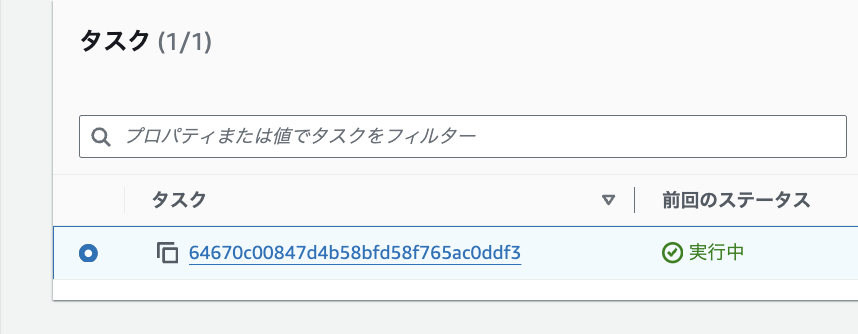
「実行中」状態になってから数分待たないと、コンテナを停止しても、コンテナの再起動は実行されないようです。 この機能をお試しの際にはお気をつけください。
2024/10/19 背景が分かりましたので追記します。
タスクを起動してすぐの状態ではコンテナの再起動が実行されない背景は、再起動ポリシーの「試行リセット期間」のデフォルト値が関係していました。
再起動ポリシーの「試行リセット期間」は「再起動を試みる前にコンテナを実行する必要がある時間」です。
デフォルト設定値が 5分 (300 秒) なので、タスクを5分ほど起動していないと、コンテナを停止しても再起動できなかったのです。
 ユーザー側で 60 秒から 1800 秒の間で任意に変えることができます。詳細は「試行リセット期間」の章をお読みください。
ユーザー側で 60 秒から 1800 秒の間で任意に変えることができます。詳細は「試行リセット期間」の章をお読みください。
ここからまた、続きをお読みください。
気を取り直して、タスク起動後に数分待ってから、nginx のプロセスを再起動 (service restart nginx) した際のログです。
ログ:

exit でコンテナが終了したと同時刻に、/docker-entrypoint.sh を実行して、コンテナを再起動しています。
コンテナの再起動を実行してくれる ECS エージェントはきっと、特別な存在なのだと感じました。
お客様とミーティングしていた際に、ある方が ECS エージェントを疑ったのをきっかけに、色々試し、原因を発見することができました。感謝です。
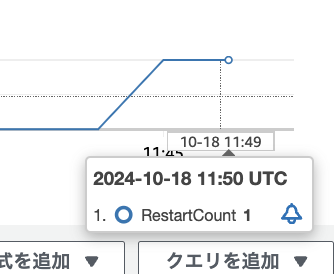
CloudWatch メトリクスの RestartCount が上がっています。
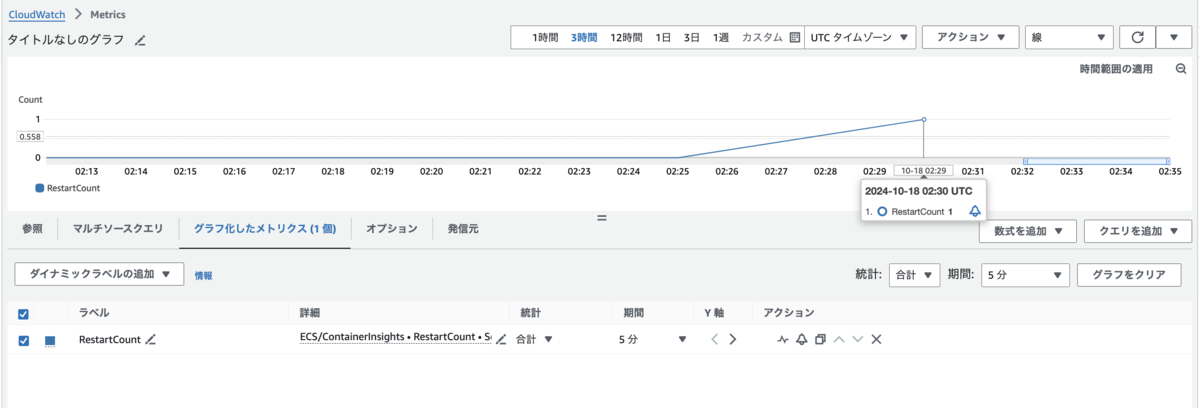
さて、今度は、ECS Exec を使用して、nginx コンテナのメインプロセスに SIGTERM を送信してみます。
service コマンド以外も試してみたいので、実施します。
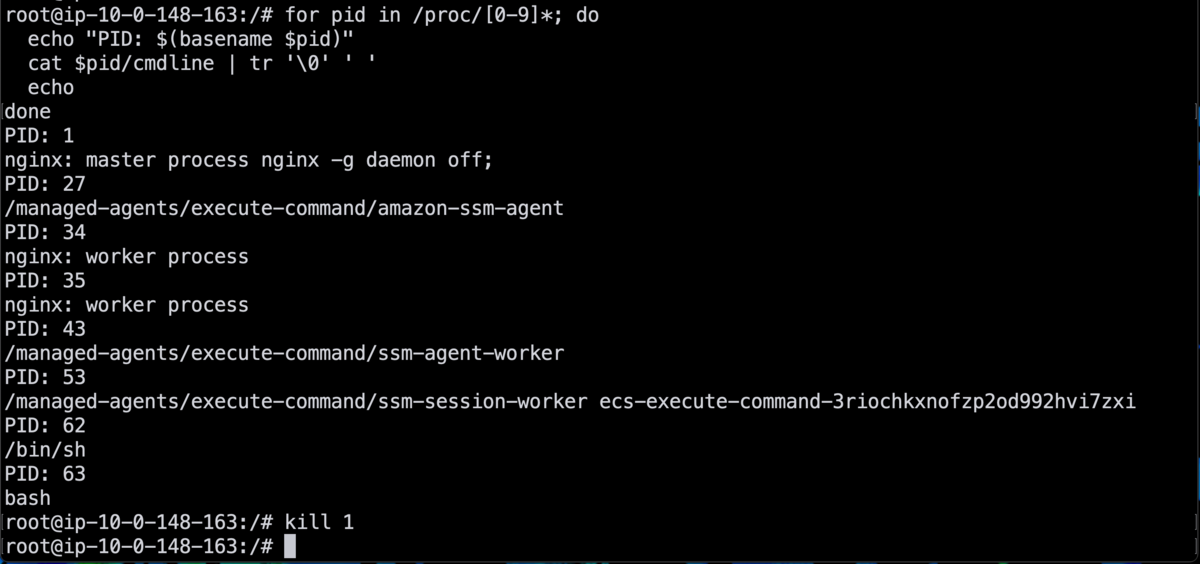
- プロセス ID を取得します。ps コマンドがなかったので苦肉の策です。
for pid in /proc/[0-9]*; do echo "PID: $(basename $pid)" cat $pid/cmdline | tr '\0' ' ' echo done
- メインプロセスである
master process ...を SIGTERM を送信してみます。
kill 1
タスクログを眺めていると、新しい nginx コンテナがサッと動き始めています。
exit のログが出てから1分も経たずに、瞬間的に新しいコンテナの起動が始まります。
RestartCount のメトリクスは、統計を「合計」にすると良さそうです。
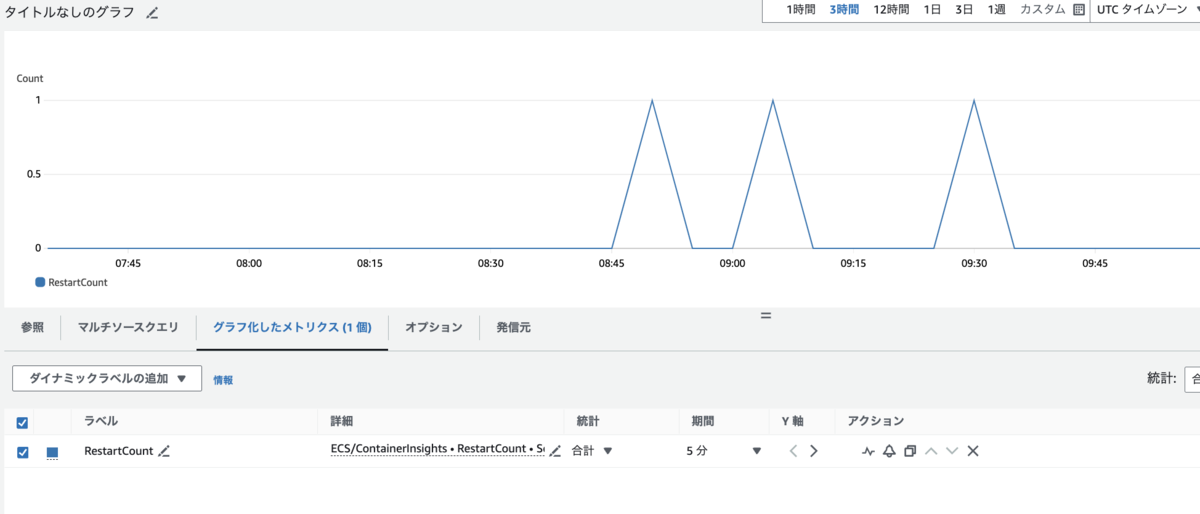
どのコンテナが再起動したかは、わからないのでログを見るしかなさそうでした。
注意事項
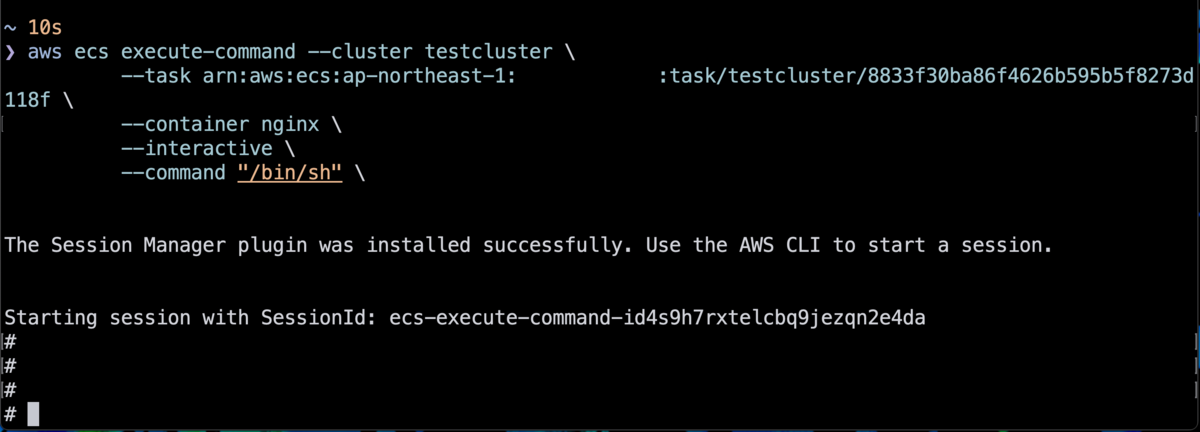
コンテナ再起動のあと、再起動した nginx コンテナに ECS exec でログインしようとしたところ、残念なことにエラーになりました。
An error occurred (TargetNotConnectedException) when calling the ExecuteCommand operation: The execute command failed due to an internal error. Try again later.
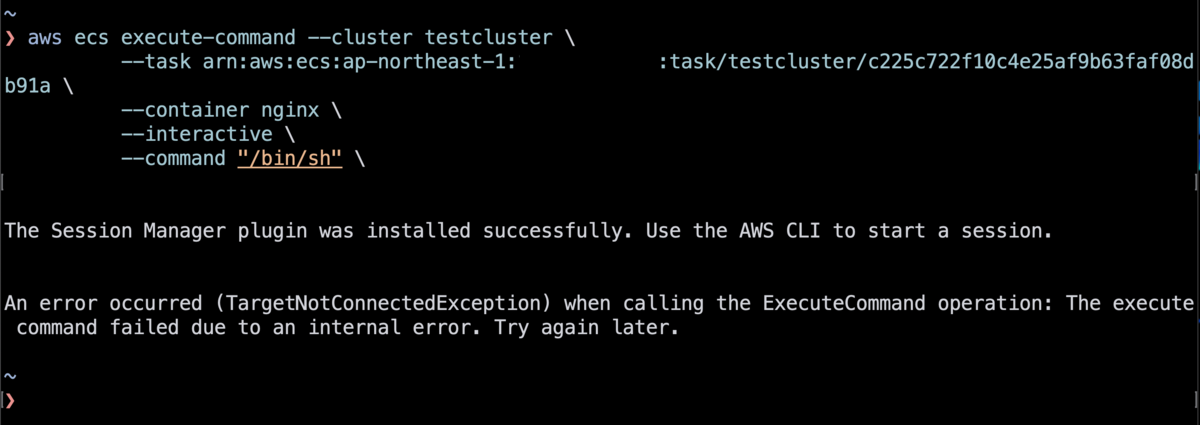
新しいタスクを作成し直した場合には、問題なく ECS Exec を再び使用できました。
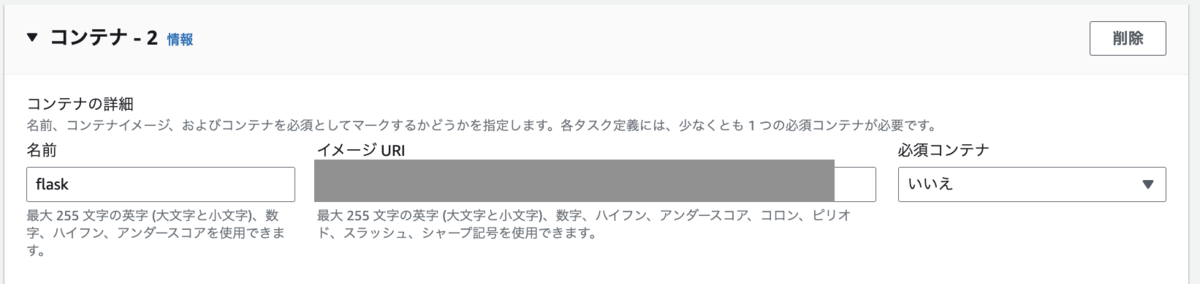
ECS サービス単体で必須コンテナが「いいえ」の場合
結果:コンテナの再起動は「はい」の場合と同様に動作しました。
タスク定義の中で flask コンテナの「必須コンテナ」属性を「いいえ」にします。
flask コンテナ上に動かしている python コードの中で、起動から 5 分後に終了コード 1 を返して強制終了するようにします。
5分の背景はドキュメントの記載に5分 (300 秒) は実行する必要があるとあったことです。再起動ポリシーの「試行リセット期間」のデフォルト設定値です。詳細は「試行リセット期間」の章をお読みください。
デフォルトでは、コンテナを再起動するには 300 秒間実行する必要があります。
from flask import Flask
import threading
import os
import time
app = Flask(__name__)
@app.route('/')
def hello():
return "Hello, World!"
def terminate_after_delay(delay):
# 指定された秒数待機
time.sleep(delay)
# プロセスを強制終了
os._exit(1)
if __name__ == '__main__':
# 300 秒後に終了するスレッドを開始
timer_thread = threading.Thread(target=terminate_after_delay, args=(300,))
timer_thread.start()
# Flaskアプリケーションを開始
app.run(host='0.0.0.0', port=8080)
5分後のコンテナ再起動1回目:
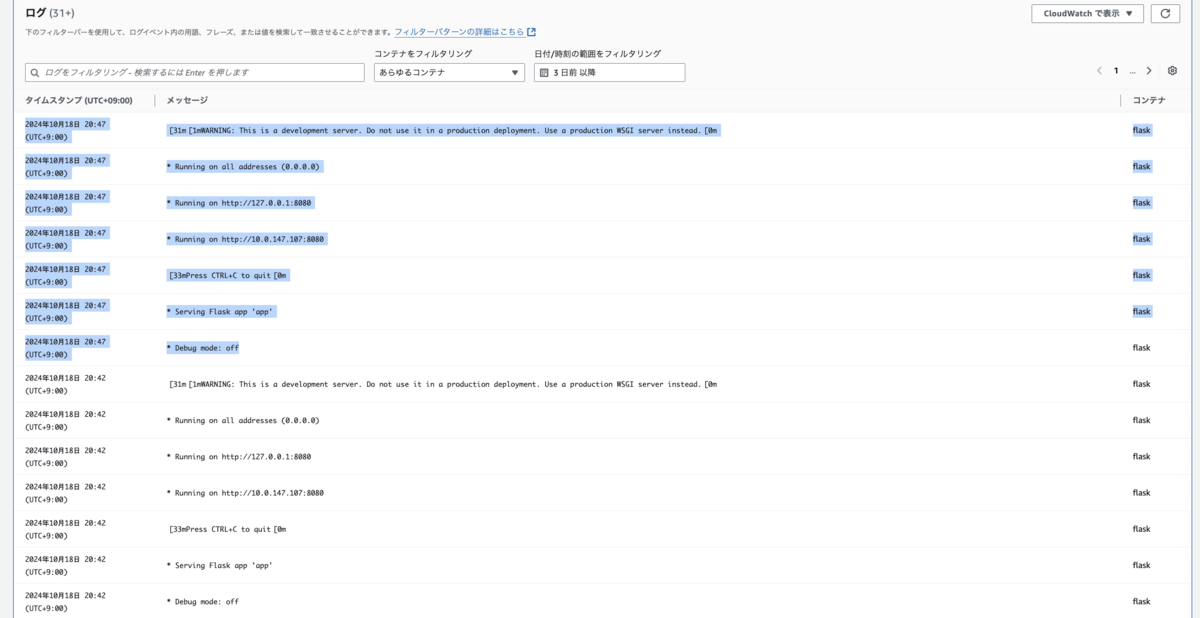
10 分後のコンテナ再起動2回目:
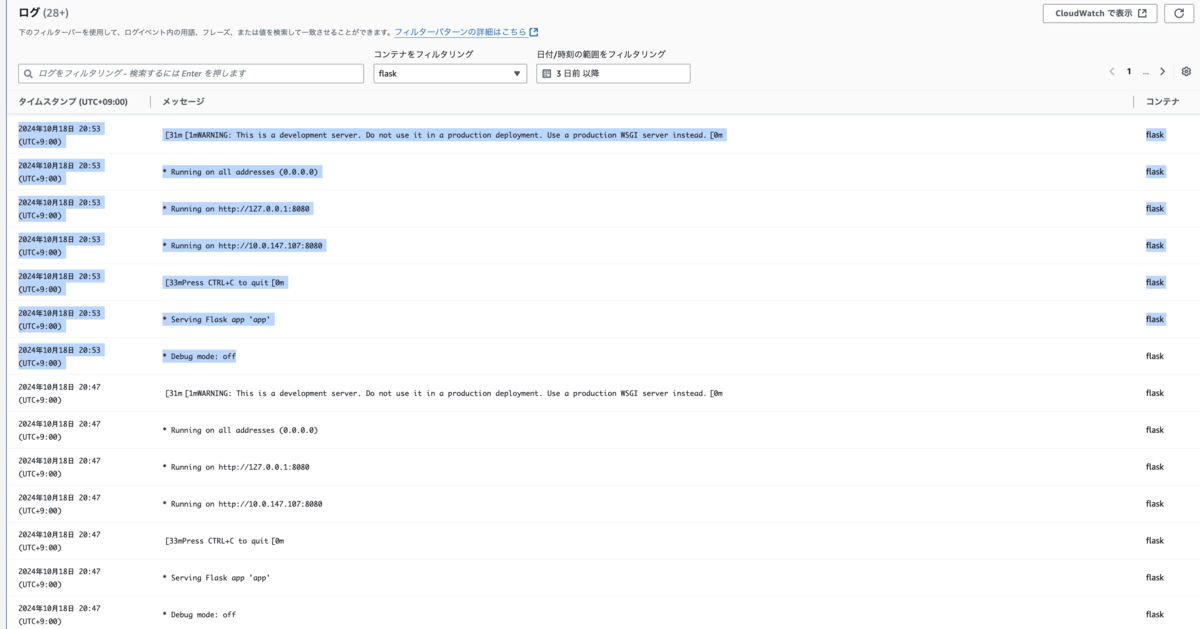
RestartCount :
「必須コンテナ」属性を「いいえ」にしても、同様に再起動しました。
このタスクを動かし続けることは、ECR からコンテナをプルして起動する処理が5分に一回実行することになるので、料金面に注意が必要です。
お試しの際はお気を付けください。
注意事項
コンテナ再起動のあと、再起動した flask コンテナに ECS exec でログインしようとしたところ、残念なことにエラーになりました。
nginx のときと同じなので記載を割愛します。
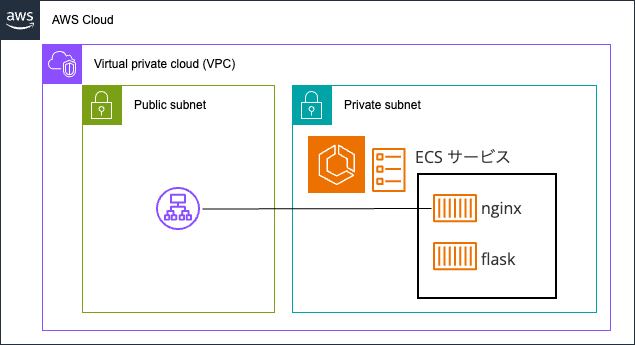
ALB と紐付けた ECS サービスの場合
ECS サービスを ALB (Application Load Balancer)と連携させると、ALB のヘルスチェックに失敗した ECS タスクは自動的に削除され、新しいタスクが再作成されるようになっています。この動作が ECS コンテナの再起動処理とどのように連動するのかを調査します。
ALB は、リクエストを nginx コンテナに転送するように設定しており、ヘルスチェックも同様に nginx コンテナに対して行います。
イメージ:
結果:ALB のヘルスチェックに失敗した際にはタスクが削除・再作成になります。ヘルスチェックに失敗する前にコンテナの再起動を実行できる場合もあります。どちらが優先されるかは、ヘルスチェックが失敗になるまでの期間によって変わります。
以下、検証内容です。
検証:ネットワーク障害
ALB と関連づけた状態で、ECS サービスのあるサブネットの通信を一時的に全て遮断します。
AWS FIS の実験テンプレートを作りました。AWS Resilience Hub のサービス画面より作成できます。
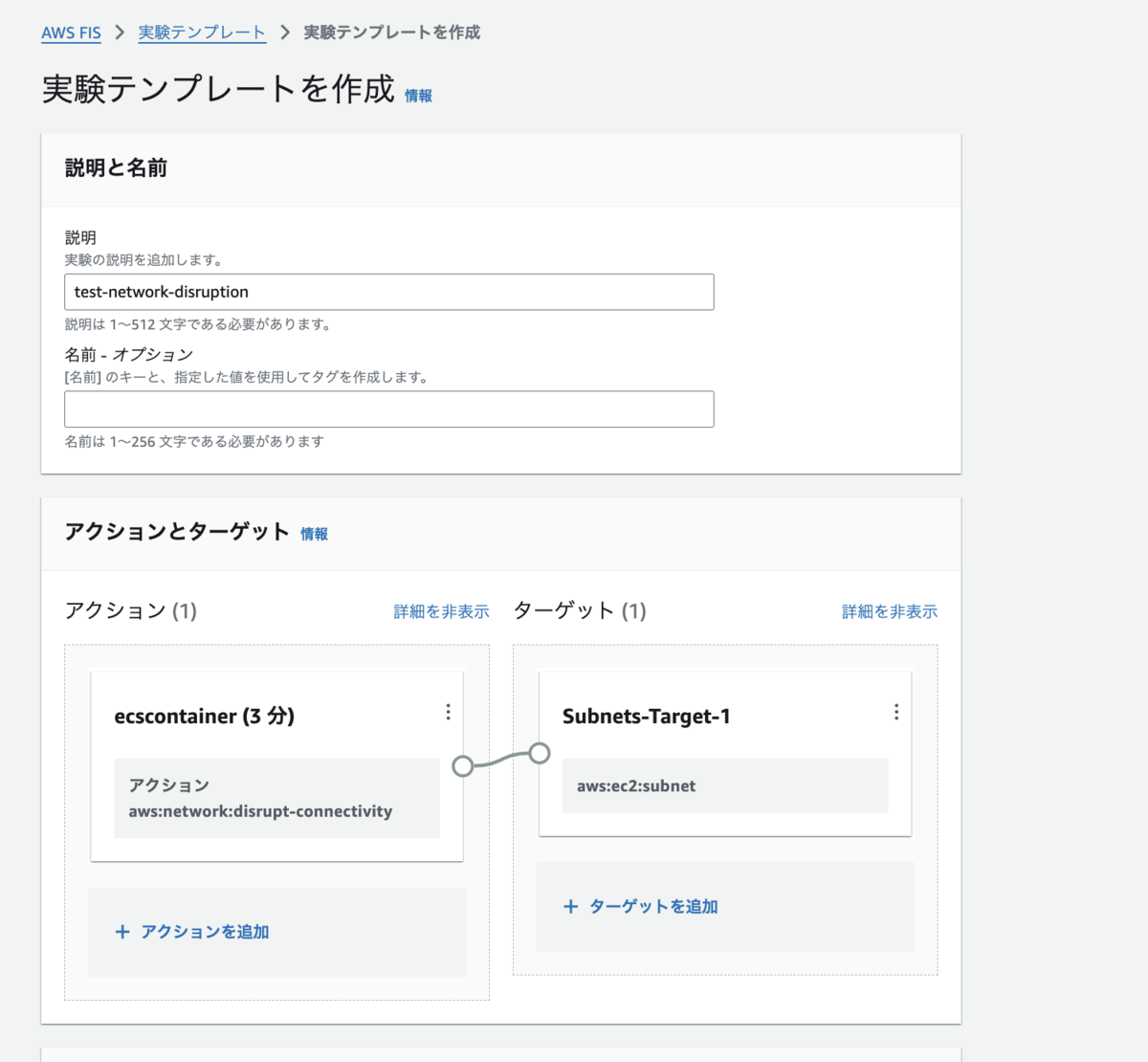
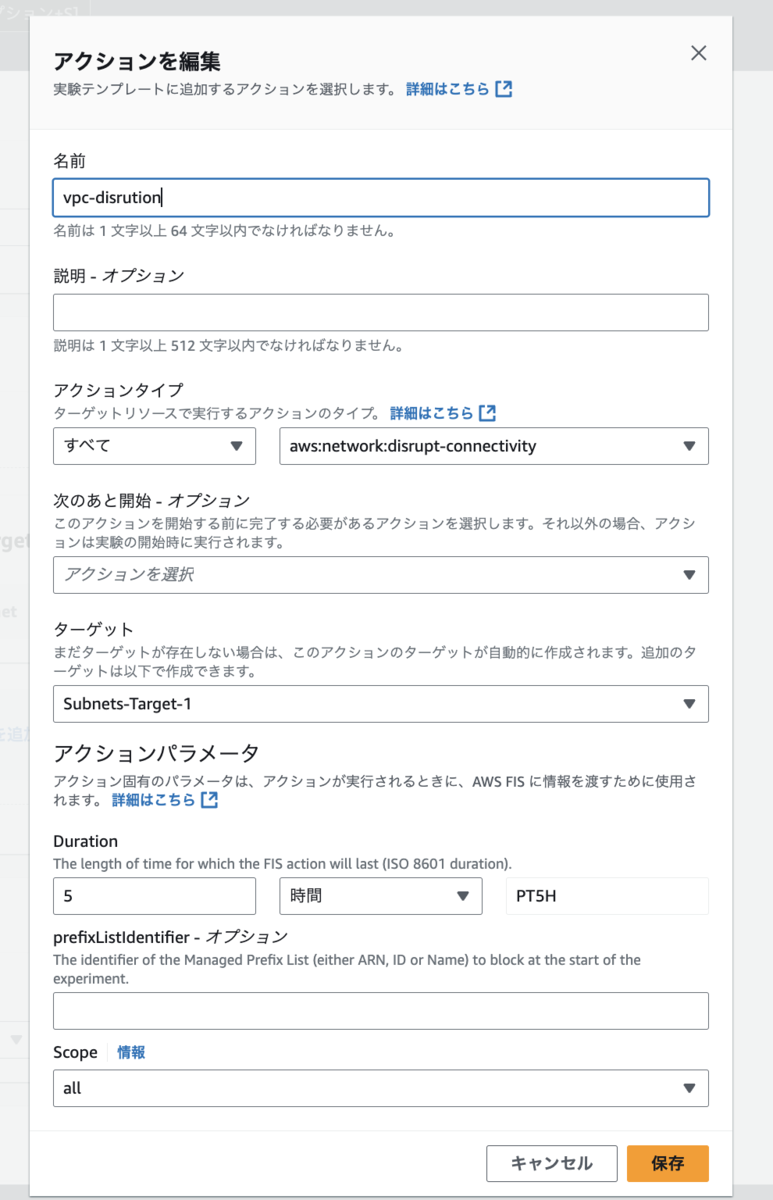
実験を開始すると、ELB のヘルスチェックが Unhealthy になりました。
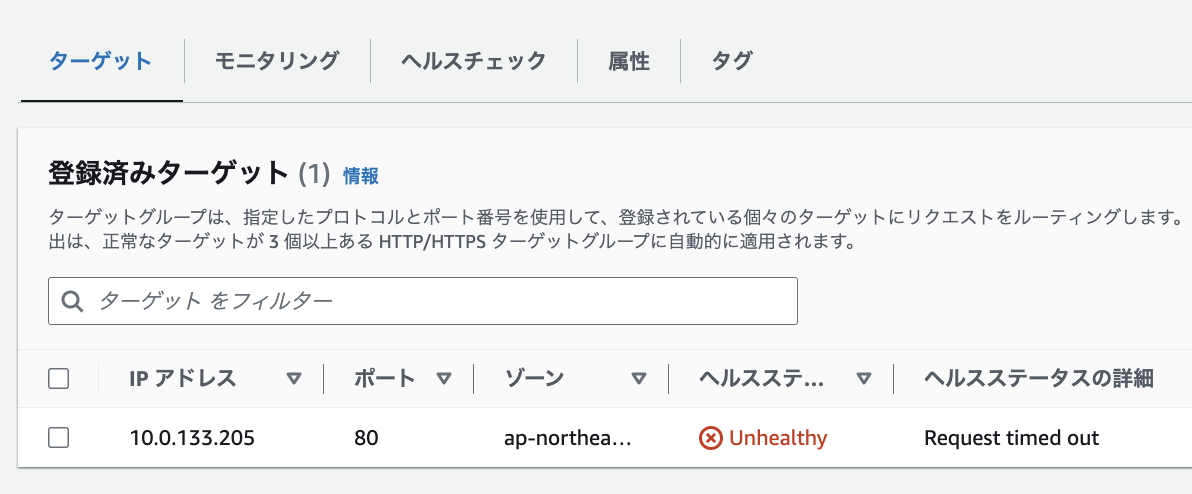
新しいタスクを起動しようとして ECR からイメージを取得できずにエラーになっていました。
FIS が VPC 内の通信を全て妨害しているためです。
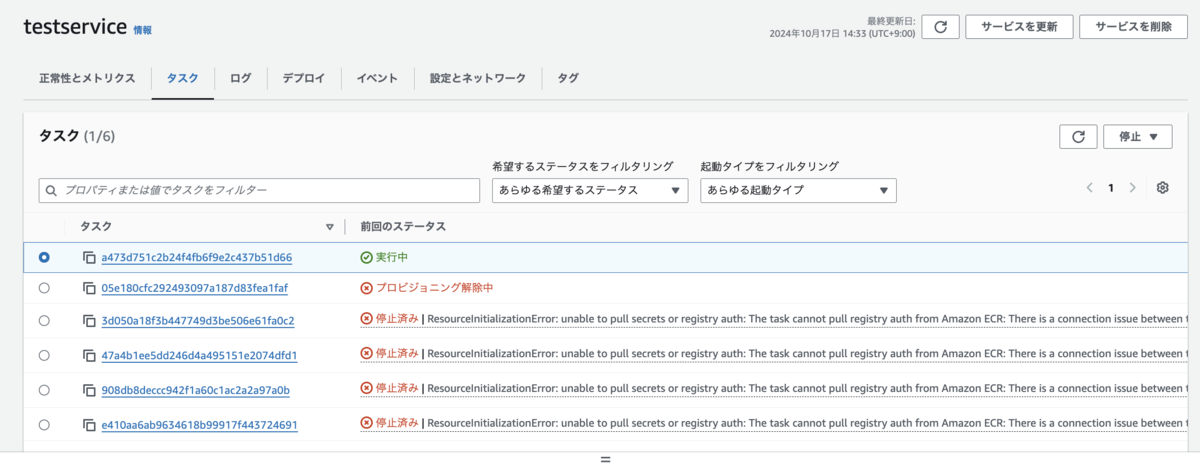
コンテナ再起動は、起きていませんでした。このネットワーク障害時に、コンテナは exit せず、Running 状態を続けていました。
CloudWatch メトリクスから RestartCount のメトリクスを参照しても、0 になっていました。
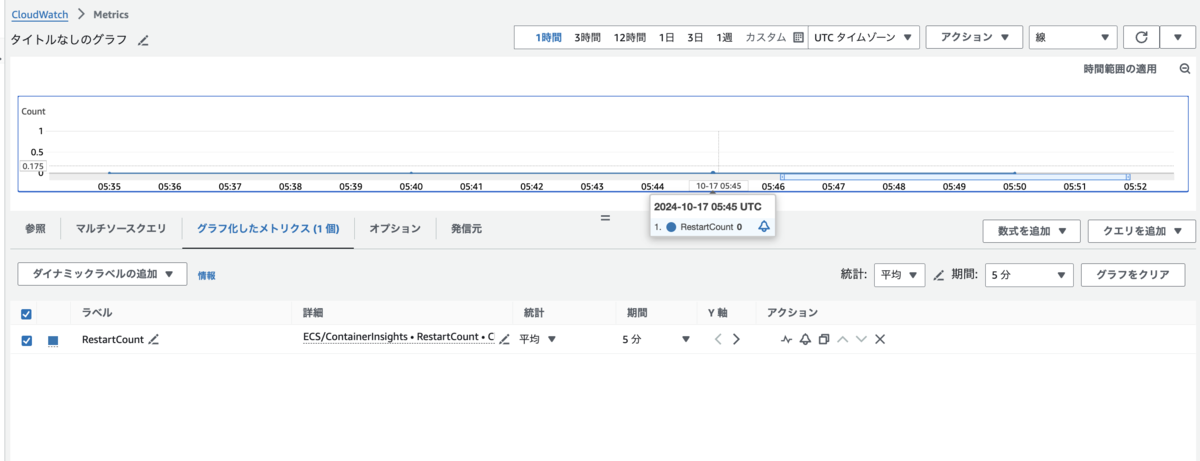
ALB と ECS サービスを紐づけている時に、ALB のヘルスチェックに失敗する場合には、タスクが再作成される、というのは以前のままのようです。
検証:nginx コンテナの停止
ネットワーク障害を停止し、今度はコンテナを終了させる実験をしてみます。
nginx コンテナを停止させる際には、ALB からのヘルスチェックに失敗して、先にタスクが削除になってしまう可能性があります。
そのため、以下2パターンを試験します。
- ALB のヘルスチェックが失敗するまでの間隔を長くして nginx を停止したとき
- コンテナの再起動を実行できる想定
- ALB のヘルスチェックが失敗するまでの間隔を短くして nginx を停止したとき
- 先に ALB のヘルスチェックにより、タスクが削除・再作成になる想定
- コンテナの再起動を実行できない想定
- 先に ALB のヘルスチェックにより、タスクが削除・再作成になる想定
ALB のヘルスチェックが失敗するまでの間隔を長くして nginx を停止したとき
ALB のヘルスチェックが失敗になる前に、コンテナの再起動を実行できる想定です。
ALB のヘルスチェックに失敗するまで5分に設定しました。

nginx のメインプロセスを停止します。

nginx コンテナが再起動しました。
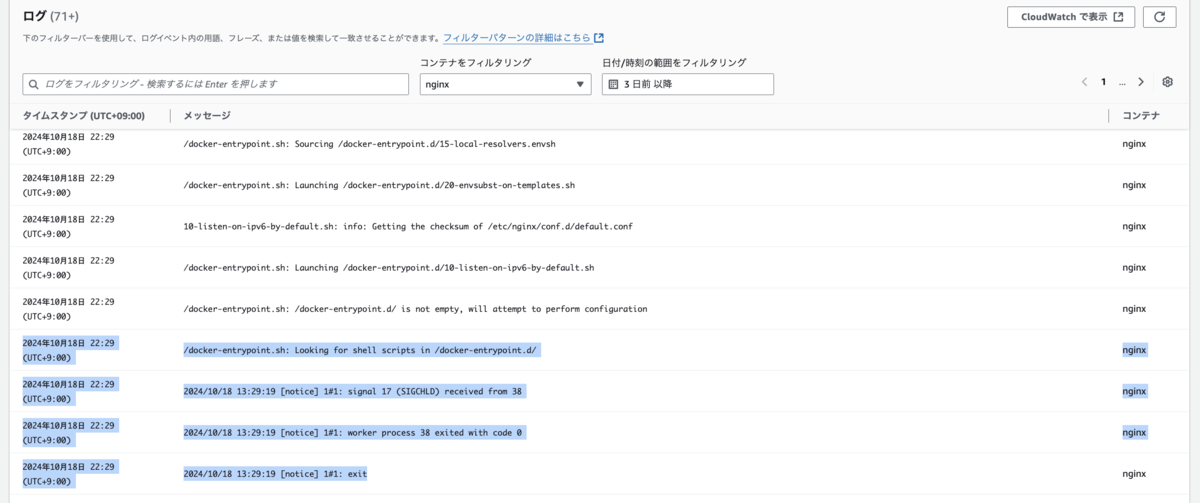
想定通りです。
ALB のヘルスチェックが失敗するまでの間隔を短くして nginx を停止したとき
コンテナの再起動が起きる前に、ALB のヘルスチェックにより、タスクが削除・再作成になる想定です。
ALB のヘルスチェックに失敗するまで 20 秒に設定しました。これが最小です。

nginx のメインプロセスを停止します。

ヘルスチェックに失敗しました。

ログを眺めてもコンテナの再起動はしません。
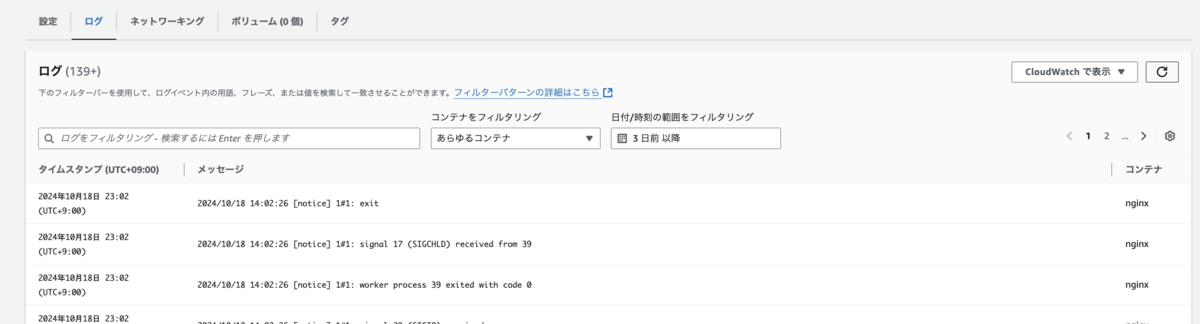
タスクが停止し、新しいタスクが起動しました。
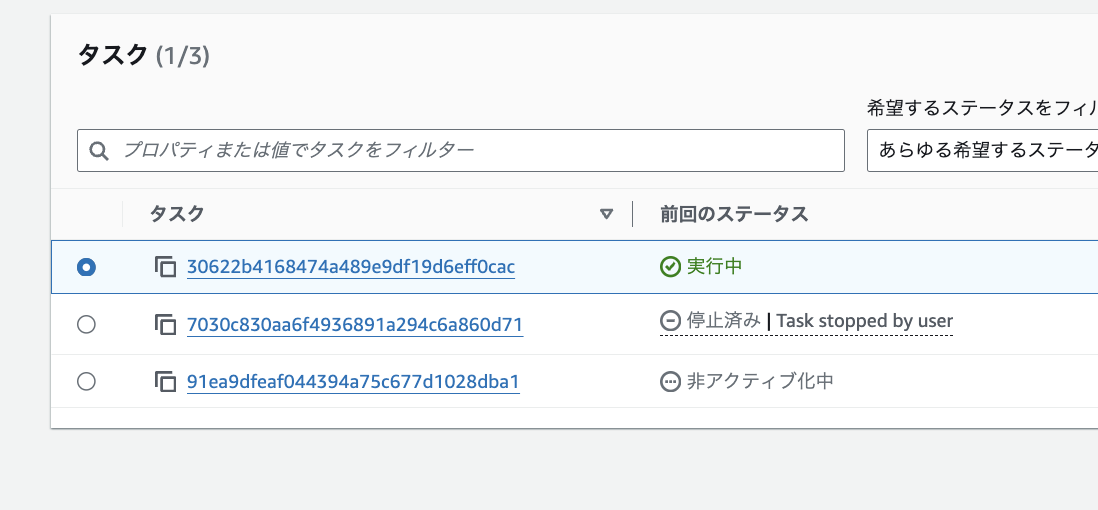
想定通りです。
検証:flask コンテナの停止
flask コンテナは、ECS サービスを ALB と関連付けしていなかったときと同じイメージを使用しました。
結果、ECS サービスを ALB と関連付けしていなかったときと同様に、再起動ポリシーが実行されました。
ALB からのヘルスチェックを受けているのは nginx コンテナなので、ALB から nginx へのヘルスチェックが healthy であれば、影響は受けないです。
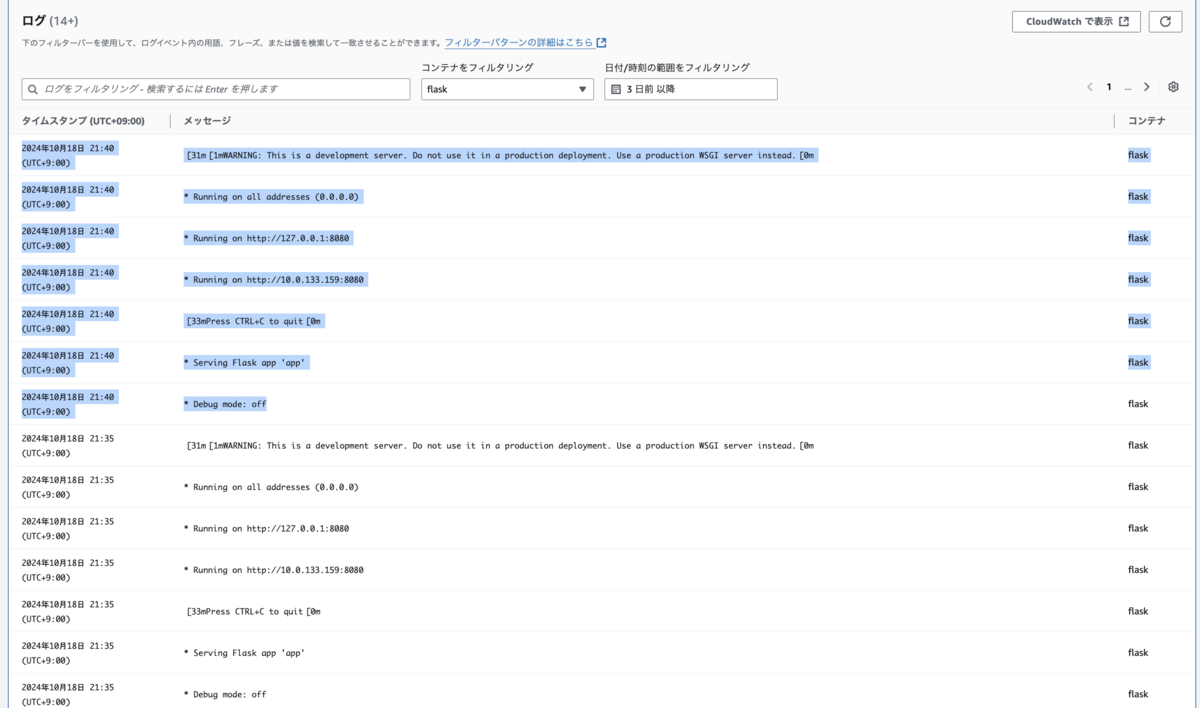
想像通りです。
再起動ポリシーのパラメータを試してみる

無視された終了コード
「無視された終了コード」は、「コンテナ再起動をさせない終了コード」です。 試しに 0 を指定した場合、その終了コード 0 の場合には再起動されませんでした。 ドキュメントの記載通りでした。
試行リセット期間
「試行リセット期間」は、「再起動を試みる前にコンテナを実行する必要がある時間」です。
flask コンテナの部分でも確認したとおり、デフォルトでは、コンテナを 300 秒実行していない場合には再起動してくれない、とあります。
このとき、180 秒で停止するコンテナをデプロイしてみたところ、再起動されませんでした。
ドキュメントの記載通りでした。
まとめ
長くなったものの、この機能を試せて、充実感があります。
ALB と併用する際には、ヘルスチェック間隔を短くしてしまうと、コンテナの再起動はできなくなります。
また、再起動したコンテナには ECS Exec でログインできない点も留意点です。
付録:Dockerfile / アプリケーションファイル
以下の Dockerfile / アプリケーションファイル を私の PC 、Macbook Pro M2 で docker buildして、ECR にイメージを格納し、検証しました。
nginx
- Dockerfile
# ベースイメージとして最新の nginx イメージを使用 FROM nginx:latest # ローカルの index.html ファイルをコンテナ内にコピー COPY index.html /usr/share/nginx/html/index.html # デフォルトの設定ファイルを置き換える COPY default.conf /etc/nginx/conf.d/default.conf
- default.conf
server {
listen 80;
server_name hogehoge.net;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
}
index.html は割愛します。お好きなコンテンツにしてください。
flask
- Dockerfile
# Use the official Python image from the Docker Hub FROM python:3.9-slim # Set the working directory in the container WORKDIR /app # Copy the current directory contents into the container at /app COPY . /app # If you don't have a requirements.txt, you can install Flask directly RUN pip install flask # Make port 8080 available to the world outside this container EXPOSE 8080 # Run app.py when the container launches CMD ["python", "app.py"]
- app.py
from flask import Flask
import threading
import os
import time
app = Flask(__name__)
@app.route('/')
def hello():
return "Hello, World!"
def terminate_after_delay(delay):
# 指定された秒数待機
time.sleep(delay)
# プロセスを強制終了
os._exit(1)
if __name__ == '__main__':
# 300 秒後に終了するスレッドを開始
timer_thread = threading.Thread(target=terminate_after_delay, args=(300,))
timer_thread.start()
# Flaskアプリケーションを開始
app.run(host='0.0.0.0', port=8080)
余談
100 マイルのトレイルランニングレース、OSJ koumi 100 に挑戦したものの、見事に砕け散りました。
来年頑張ろうと思います。
66 km 地点で色々ありリタイア。
