

はじめに
私はAWSを用いたインフラレイヤーの設計や構築を行うことが多いエンジニアなのですが、 ありがたいことに最近はプログラミングも含む小~中規模のバックエンドアプリケーションの開発案件に携わる機会が増えています。
インフラレイヤーだけを扱っていたころよりも、アプリケーションのテスト戦略について自分で考えなけばいけないことも増えました。
テストはシステム開発において品質を担保する上で非常に重要なプロセスですが、ともすれば開発効率を低下させる要因にもなり得ます。
そのため本記事では、開発効率を下げずに効率よく行えるテスト戦略を再現できることを目的に、私が学んだテスト戦略をまとめました。
想定読者
- はじめてテスト実装をする方
- 他の人がどのようなテスト戦略をとっているのか参考にしたい方
- 効率のよい小~中規模のバックエンドアプリケーション開発におけるテストをしたい方
テストの前提知識
本記事を読み進める上で事前に知っておきたい知識をまとめます。
テストの視点:ブラックボックスとホワイトボックス
テストは、システムの内部構造を考慮するかどうかによって、大きく2つの視点に分かれます。
- ホワイトボックステスト: コードレベルの処理ロジックやデータフローなど、システムの内部構造を把握した上で行うテスト。
- ブラックボックステスト: システムの内部構造を考慮せず、機能設計や入出力など、外部から見える仕様に基づいて行うテスト。
テストの分類: 正常系, 準正常系, 異常系
テストは、業務上の要件として想定されるかどうか によって、3つの分類に分かれます。
- 正常系: 業務上の要件として想定される正常な動作に対するテスト
- 準正常系: 業務上の要件として想定される異常な動作に対するテスト
- 異常系: 業務上の要件として想定されていない異常な動作に対するテスト
テストの種類
テストは、目的や期待値によってたくさんの種類があります。その中でも以下4つは基本的なテストの種類になります。
- 単体テスト: 関数、メソッド、クラスなどの最小単位のテスト(ホワイトボックステスト)
- 結合テスト: 複数のコンポーネント連携のテスト(ブラックボックステスト)
- E2Eテスト: システム全体の最初から最後までを通したテスト(ブラックボックステスト)
- 受入テスト: エンドユーザーによるシステム検証(ブラックボックステスト)
テストの名称や目的は世の中一般的にかなり揺れるので、一例として捉えてください。
「各テストのごとのホワイトボックス・ブラックボックステストの区分け」も本来厳密に分けられるものではありませんが、今回はわかりやすさを重視して分けています。
「正常系、準正常系、異常系」はどのテストでも包含される可能性があります。
その他にも、「性能テスト、セキュリティテスト」などもありますが、+αのテストのためここでは割愛します。
テストダブル-MockとFake-
テストの効率化に寄与する重要な要素として、テストダブル があります。
- テストダブル: テスト対象が依存しているコンポーネントを置き換える代用品
よく登場するテストダブルとして以下2つを説明します。
- Mock: 常に同じ振る舞いをするオブジェクト。 【1】
- Fake: 実リソースに近い内部構造を持つ偽物のオブジェクト
例えば、DynamoDBテーブルの場合、各々は以下のようになります。
- Mock: テストコード上で自前で定義したモックオブジェクト
- Fake: DynamoDBLocalにより、ローカルのメモリ上で作成されたDynamoDBテーブル
- 本物: AWSAPIを叩いた結果、AWSアカウント上で作成されたDynamoDBテーブル
テストダブルを使えば、外部APIへの依存を減らしテストを高速化できます。
しかし過度な使用はテスト品質を低下させる可能性があるため、使いどころを見極めることが重要です。
さきほどの「テストの種類」に当てはめると、「単体テスト」で使うケースが多いです。
【1】 Mockの具体例
以下のMockは常に value や result といった同じ値を返すよう振る舞います。
import unittest.mock def test_mock_object(): mock_obj = unittest.mock.Mock() mock_obj.attribute = "value" mock_obj.method.return_value = "result" result = mock_obj.method() assert mock_obj.attribute == "value" assert result == "result" mock_obj.method.assert_called_once()
テスト戦略
ここから私が実践ベースで学んだ効率的だと考えるテスト戦略について記載します。
完璧なテストを目指さない
すべての観点を網羅した完璧なテスト実装するのは人間には不可能ではあり、目指すべきところではありません。
80%の完成度を目指すことが重要です。
なぜなら、品質向上に大きく寄与する重要なテストは80%の中にほぼ含まれているケースがほとんどだからです。(※80%とは、パレートの法則から設定したおおざっぱな見積です。)
| 完成度 | 負荷 | 品質の向上 |
|---|---|---|
| 0%→80% | 小~中 | 大 |
| 80%→100% | 大 (※そもそもすべてのケースを洗い出すのは大変かつ不可能) |
小 (ごく稀なケースや他のテストとカバー範囲が被るテストが多く、向上幅が限定的) |
砂時計型のテストアーキテクチャを採用する
続いて、80%の完成度を効率よく目指すために、テストアーキテクチャを決めることが重要です。
テストアーキテクチャとは、複数テストの関係性を定めたテスト戦略の大枠を決める設計を指します。
有名なテストアーキテクチャとして、テストピラミッドがあります。
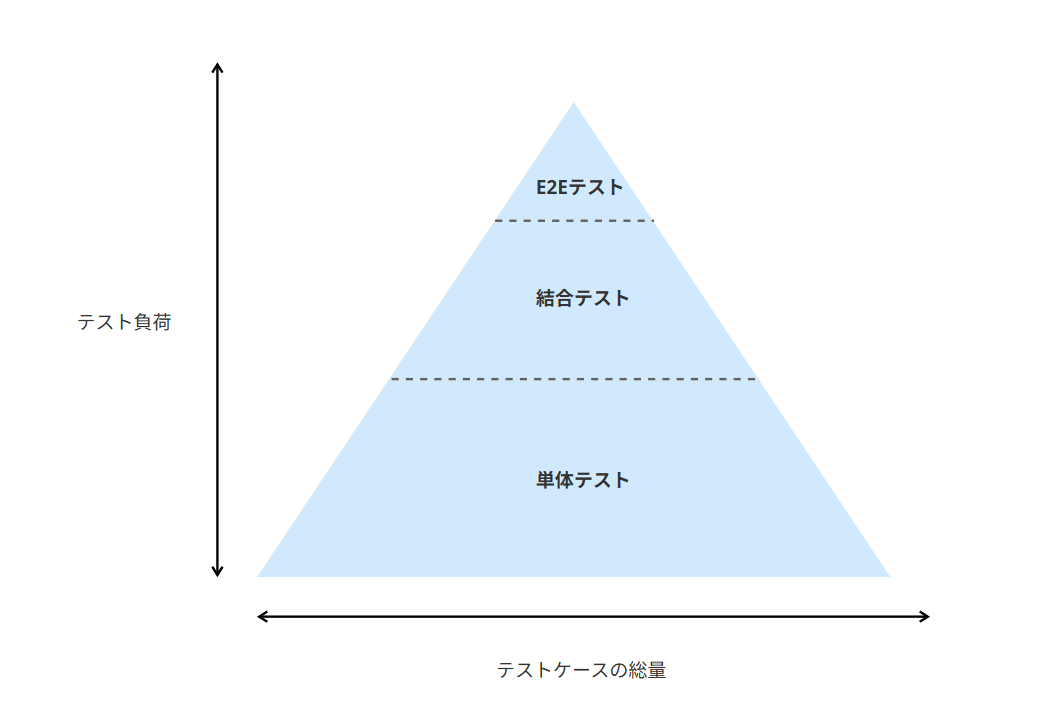
開発者が行うテストは、単体テスト→結合テスト→E2Eテストとレイヤー構造があります。(受入テストはエンドユーザが行うテストなので割愛)
上位レイヤーに行くほどテストは複雑になるのでテスト負荷が上がるという問題があります。
テストピラミッドでは、下位レイヤーのテスト量を最も多く、上位レイヤーになるにつれのテスト量を減らすので、上記の問題を解決し、スムーズなテスト戦略を実現します。
これは下位レイヤーで多くを担保しているので、上位レイヤーのテスト量を減らして問題ないという思想により成り立っています。
一方私は砂時計型のテストアーキテクチャをおすすめしたいです。(砂時計ではなく、他にちゃんとした言い方があるかも)
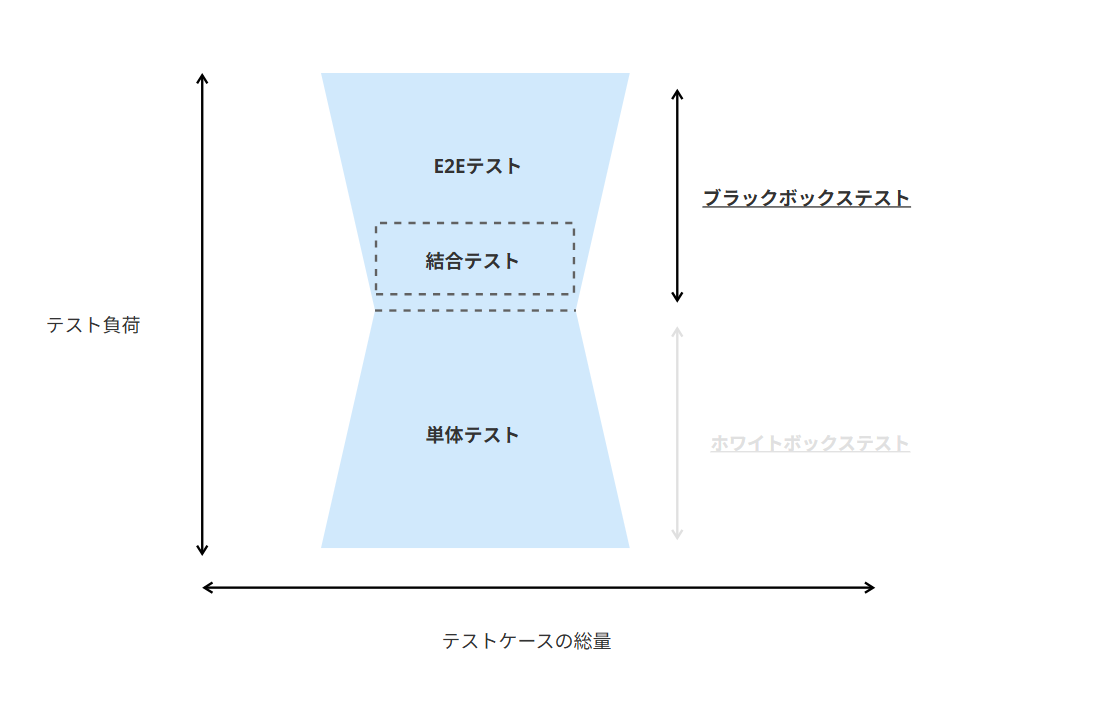
砂時計の形は、最上位レイヤーと最下位レイヤーに比重を置き、中間レイヤーのテストを最も少なくすることを目的に成り立っています。
なぜこのテストアーキテクチャがオススメなのか?
それは私が実際にテスト戦略を考えていて最も負荷が大きいと感じたのが、中間レイヤーのテスト(≒結合テスト)だったためです。
当初はテストピラミッドを採用したのですが、中間レイヤーのテストは定義の負荷が難しいうえに、人によってかなりブレるので、こちらのテストアーキテクチャにたどり着きました。(後述の【結合テストを明確にするのは難しい】も参考ください。)
このテストアーキテクチャは、以下考え方をベースとしています。
- テストをブラックボックステストとホワイトボックステストの2つに捉える。
- ブラックボックステストは、最上位レイヤー(≒E2Eテスト)で担保できる。
- これにより、例えば同じブラックボックステストの結合テストはE2Eテストに包含されてるとみなし、ある程度省略が可能
- ホワイトボックステストは、最下位レイヤー(≒単体テスト)で担保する
砂時計型は、テストピラミッドよりも以下点で優れているためオススメです。
- 他のテストとの境界が曖昧ゆえに、最も定義・設計しづらい中間レイヤー(=結合テスト)を最小にし、開発スピードを上げられる
- 中間レイヤーを全て省略することも可能なので、テスト負荷大きく下げられる
レイヤードアーキテクチャを採用する
テスト戦略ではアプリケーション設計も重要です。アプリケーション設計が整理されていないと、テストケースの洗い出しやテストコード実装がしづらくなり、テスト負荷が一気に高まります。
上記の問題を回避するために、例えば、レイヤードアーキテクチャ を採用したコード実装をオススメします
レイヤードアーキテクチャは app → domain → infra のように階層構造で成り立つコードアーキテクチャです。
| 階層 | 詳細 |
|---|---|
| app | domainで定義された関数を呼び出すメイン関数を実装する。 |
| domain | infraで定義された関数を呼び出すビジネスドメイン(=そのアプリケーション特有)関数を実装する |
| infra | ビジネスドメインによらない普遍的な関数を実装する。(外部APIの呼び出しを最低限ラップしたものなど)。 |
モノリシックなコードと比較するとレイヤードアーキテクチャの採用メリットが分かります。
※ モノリシックなコードとは、「1関数に処理が詰め込まれ、役割の明確化や可読性が低いコードアーキテクチャ」を指します。
| レイヤードアーキテクチャ | モノリシックなコード | |
|---|---|---|
| 共通認識 | 〇 階層ごとの役割が明確で統一しやすい |
× 人によって粒度がブレる |
| 関数の役割 | 〇 ミニマムな役割を持つ関数 |
× 条件分岐やループなどが含まれる長くて複雑な関数 |
| 使い回やすさ | 〇 アプリケーションを超えて使い回せる |
× 使い回しづらい |
レイヤードアーキテクチャにより、テスト戦略上で以下のようなメリットがあります。
- 共通認識がとりやすいので、統一的な規格に沿ったテストコードが書きやすい。
- 関数の役割がミニマムなので、テストケースの洗い出ししやすい。
- 使い回しがきくので、次回のアプリケーション開発で品質が担保されたコードをテストコードとセットで横展開でき、開発を加速できる
レイヤードアーキテクチャのサンプル -カレーを作る-
抽象的な話が続いたので、サンプルコードでも考えてみます。
以下はカレーを作るアプリケーション想定したサンプルコードのモノリシックなコード例です。
# mono.py def create_my_curry(integratedients): required_ingredients = ['玉ねぎ', '牛肉'] if not all(item in integratedients for item in required_ingredients): raise('必要な具材がありません') for i in integratedients: print(f'{i}を切ります') print('具材と水を鍋に入れます') print('カレー粉を鍋に入れます') print('煮ます') print('完成!') if __name__ == '__main__': ingredients = ['人参', '玉ねぎ', 'じゃがいも', '牛肉'] create_my_curry(ingredients)
この場合、以下の問題を孕んでいるため、非常にテスト負荷が高いです。
- 1関数の責任範囲が広いので、人によってテストコードの書き方がブレる可能性が高く、一定の品質が維持できない。
- 1関数にすべての条件分岐やループが含まれているため毎回のテストケースでそれらの考慮が必要。そのため1テストあたりの実装コストが大きく、漏れもでやすい。
- 関数内でアプリケーション特有の箇所がわかりづらく、他アプリケーションに横展開しづらい
では、レイヤードアーキテクチャではどうでしょうか。以下設計思想で作成してみます。
- app.pyはdomain層の関数を使い回し、カレーを作る関数を一つだけ定義
- domain.pyはinfra層の関数を使い回し、カレー特有の処理を関数ごとに定義
- infra.pyはカレーに依存しないミニマムな関数を定義
#app.py #from domain import cut_curry_integratedients, boil_curry def create_my_curry(integratedients): cut_curry_integratedients(integratedients) boil_curry(integratedients) print('完成!') #domain.py #from infra import cut, put_into_pot, check_ingredients def cut_curry_integratedients(integratedients): required_ingredients = ['玉ねぎ', '牛肉'] check_ingredients(integratedients, required_ingredients) for i in integratedients: cut(i) def boil_curry(integratedients): for i in [integratedients, '水', 'カレー粉']: put_into_pot(i) print('煮ます') #infra.py def check_ingredients(integratedients, required_ingredients): if not all(item in integratedients for item in required_ingredients): raise('必要な具材がありません') return def cut(integratedient): print(f'{integratedient}を切ります') def put_into_pot(something): print(f'{something}を鍋に入れます')
上記の構成だと以下のメリットにより、テスト負荷を大きく減らせます。
- 設計思想が明確なため、共通認識が取りやすい。よってテストコードが人によってブレづらく、一定の品質が維持しやすい
- 各関数の責任範囲がミニマムなため、関数ごとのテストケースを考えやすく、テスト負荷が下がる
- infra層のほとんどの関数は正常系のみに注力してテストできる
- domain層は呼び出す関数がすでにテスト済みなので、ループ処理に注力したテストができる。
- app層は呼び出す関数がすでにテスト済みなので、入出力に着目したブラックボックステストができる。
- infra層(と一部domain層)の関数は別アプリケーション(例えば「シチューを作るシステム」)にも横展開できる
レイヤードアーキテクチャとテストアーキテクチャ
サンプルコードを踏まえ、レイヤードアーキテクチャとテストアーキテクチャの関係をまとめます。
例えば、【砂時計型のテストアーキテクチャを採用する】の砂時計型のテストアーキテクチャに当てはめると以下のようなイメージです。
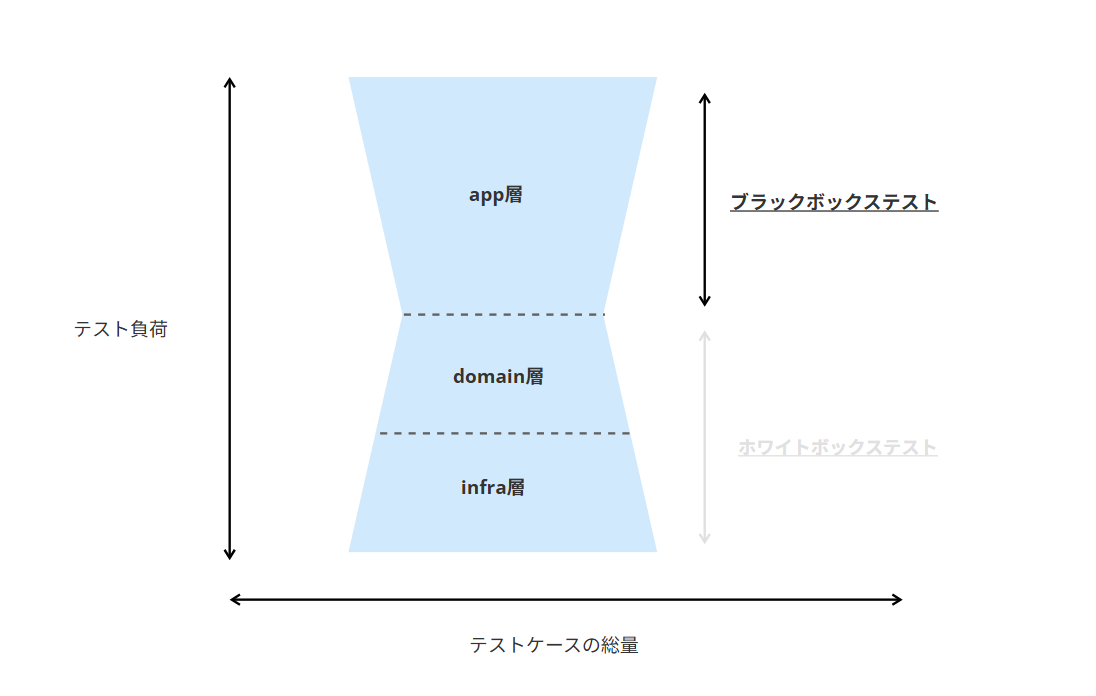
ブラックボックステストをapp層、ホワイトボックステストをinfra層, domain層で行うため、漏れなくカバーできてますね。
テストの種類ごとの洗い出し方と実装のポイント
テストの種類ごとの洗い出し方と、実装のポイントをまとめます。
| テストの種類 | 洗い出し方 | 実装のポイント |
|---|---|---|
| 単体テスト | ホワイトボックステストのため、「条件分岐、ループ、例外処理、境界値、異常値」など内部の実装に着目 | コード実装時に直接コードで設計し、設計書の作成は非推奨。 設計書の作成は負荷が高く、開発のスピードを損ねる傾向があるため |
| 結合テスト | ブラックボックステストのため、「入出力仕様書」に着目 | ある程度大きな部品単位で実施することが推奨。細かい部品での結合テストはテストケースが膨大になるため。 |
| E2Eテスト | ブラックボックステストのため、「要件定義書やユーザ体験」に着目 | ー |
結合テストを明確にするのは難しい
【砂時計型のテストアーキテクチャを採用する】 でも触れたのですが、中間に位置するゆえに定義が広く曖昧な結合テストは設計が最も大変です。
人によって捉え方もかなりブレるので、チーム内で定義を明確にさせておくことが大切です。
今までの経験から私は結合テストの詳細に以下のように認識・定義しています。(が、今後もブラッシュアップしていかないとなと感じています)
- APIやNWを経由して接続する外部リソースとの結合を担保するテスト
- ゆえにFakeやMockはなるべく使わず、本物のリソースを用いる
- ブラックボックステストを前提に、インプットアプトプットに着目してテストケースを洗い出す
- ある程度大きい部品同士の結合を優先的に対象とする。細かい部品同士の結合はその中に包含され、担保されるとみなす
イメージしやすくなるように私が実際に結合テスト絡みで悩んだ具体例もあげてみました。
■ Case1. 1スクリプトをまるっと実行するテストの種類は?
1スクリプトをまるっと実行するテストは単体テストなのか結合テストなのか?という点で悩みました。
スクリプト全体を1つの部品と捉えると単体テストといえるし、関数同士の結合と考えると結合テストといえなくもないからです。
最終的には以下でFIXしました。
- テストダブル(MockやFake)により外部へのリクエストを発生させない(=ローカル環境だけで完結する) → 単体テスト
- 本物のリソースを使い、外部へのリクエストを発生させる → 結合テスト
ここでは、結合の単位というよりも、外部リソースと結合するかどうかが決め手で結合テストの境界を確定しました。
■ Case2. Lambda関数のテストの種類は?
AWSのLambda関数に対するテストは、単体テストなのか結合テストなのか迷いました。 Lambda関数が、コードのレイヤーと Lambda関数のメタデータレイヤーを結合したものだからです。
Case1 を前提とすると、Lambda関数の時点でテストダブルを使っていることは基本的にないはずなので、結合テスト でFIXしました。
■ Case3. バックエンド全体をまるっと実行するテストの種類は?
私が参加する開発案件はよくフロントエンド開発が別会社様担当で、バックエンド開発のみ担当することが多いです。
そのため、結合テストを含めた各テストの定義は以下認識で考えていました。
- ある程度大きな部品同士の結合→結合テスト
- バックエンド全体→E2Eテスト
- フロントエンド~バックエンド→受入テスト
ただプロジェクトを進めてみると最終的には以下でFIXしました。
- バックエンド全体→ここまでが結合テスト
- フロントエンド~バックエンド(by開発者目線)→E2Eテスト
- フロントエンド~バックエンド(byエンドユーザ目線)→受入テスト
1チームとしてではなく、1システムとしてテストの全体像をとらえた結果 、結合テストの境界が確定しました。
エラーハンドリングのテストは異常系とは限らない
突然ですが問題です。
- エラーハンドリングに関するテストは正常系、準正常系、異常系のどれに該当するでしょうか?
ここでのエラーハンドリングとは、 例えば try~catchで行う例外処理のようなものを想像ください。
異常系!と思った方も多いんじゃないかと思います。実は準正常系です。(テストあるあるだと思ってます)
エラーハンドリングは「正常じゃない=異常」な動作なため、エラーハンドリングのテストは異常系に分類されると思いますよね。
しかしエラーハンドリングとは、「予期せぬ事態(エラー)にどのように対処するかを設計した機能の一部(=回復機能)」です。
従って、機能が正常に動くかどうかの確認といえるので、異常系には当たらないのです。
ただし、正常動作なケースとは異なるため、準正常系と分類されます。
■ 異常系テストとは?
では異常系のテストとはどうゆうものを指すのでしょうか?
業務の要件で考慮されていない異常な状況下でのアプリケーション振る舞いを確認するテストを指します。 例えば以下が該当するはずです。
- 外部から攻撃をうけ、おかしな入力があった場合にアプリケーションがどのように振舞うか(=セキュリティテスト)
- 想定以上のリクエストが来たときにアプリケーションがどのように振舞うか(=負荷テスト)
テスト設計書を作成するときのポイント
- テスト設計書は表形式で一覧化すると見やすい
- 期待値は主観要素を排除し数値や出力されるメッセージなどを具体的に書くことで、エンドユーザや開発者同士での認識ズレを防げる
- テストケースは、漏れなくダブりなく洗い出せるよう MECE を意識する(MECEは大学の授業で習った)
- テスト証跡を貼る場合は、改ざんができないスクリーンショットがオススメ。
- そのため表には埋め込めないので、テスト手順と一緒に別のドキュメントにまとめるとよい
テスト設計書サンプル
例えば機能要件に対して、私は以下のような表をExcelで作ることが多いです。
- 機能要件: 認証されたユーザだけがチケットを起票できる
| テスト項目 | 期待値 | 実施日 | 作業者 | 結果 | 備考 |
|---|---|---|---|---|---|
| 認証されたユーザがチケットを起票できるか? | 該当のユーザがチケットを1枚を起票できる | 4/1 | 山田 | OK | |
| 認証されたユーザがチケットを起票できるか? | 起票されたチケットのタイトルが「xxxx」となる | 4/1 | 山田 | OK | |
| 認証されたユーザがチケットを起票できるか? | CloudWatch LogsにError, Warnログが記録されない | 4/1 | 山田 | OK | |
| 認証されていないユーザがチケットを起票できるか? | 該当のユーザがチケットを起票できない | 4/1 | 山田 | NG | |
| 認証されていないユーザがチケットを起票できるか? | CloudWatch LogsにErrorログとして「Error: xxx」が記録される | 4/1 | 山田 | OK |
※同じテスト項目でも複数期待値ある場合は、期待値ごとに行を分けて書くとわかりやすいのでオススメです
まとめ
テスト戦略を踏まえた簡単なガイドラインとそのサンプルも書きたかったのですが、テスト戦略だけでブログ記事が長くなりすぎたのでまたどこかでまとめようと思います。
まだまだ自分のテスト開発の経験は浅いので、もし皆さんでもこんなテスト戦略オススメだよとかテストあるあるがあればコメントいただけたらうれしいです!
菅谷 歩 (記事一覧)