

こんにちは、CI2部の加藤ゆです。
Athenaを利用したデータ分析を実施するための環境準備作業をやっていきます。
Amazon Athena とは?
サーバーレスでS3に対して直接クエリの実行ができるサービスです。
データの保存先のS3を設定して、標準SQLでアドホックなクエリの実行が可能です。
クエリを実行するためのデータをフォーマットする必要はなく、S3においた生データに対して直接分析が出来ます。
AWS Glueとは?
フルマネージド型の ETL (抽出、変換、ロード) の AWS のサービス です。
複数の機能があるので、機能別に以下に記載します。
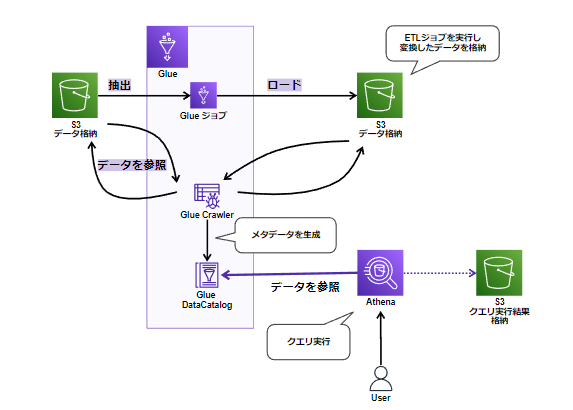
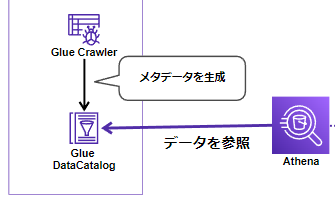
Glue Data Catalog
Glue では、 Glue Data Catalogにメタデータを保存しています。
データソース(S3)にどういったデータが入っているのかをカタログ化して、保存しておくようなイメージです。
GlueはGlue Data Catalog内のメタデータを使用してデータソースの変換、ETL ジョブの作成を行います。
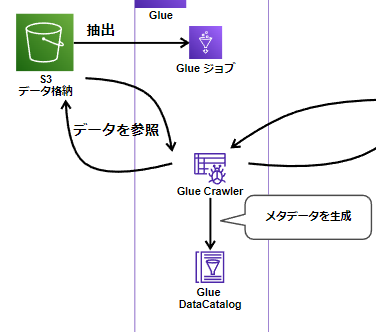
Glueクローラ
Glue Data Catalogにメタデータを作成するプログラムです。
S3 のデータからデータベースとテーブルのスキーマを自動的に推論し、関連するメタデータを AWS Glue Data Catalog に保存します。
AWS Glue クローラを使用することで、データのスキーマを自動で検出して AWS Glue Data Catalog に登録できます。
以下のアクションを実行します。
- データを参照し生データの形式、スキーマを判定
- パーティションを検出してGlue Data Catalogへ登録
正常にクロールされたデータのテーブルは Athena からクエリが可能です。
AthenaとGlueの関係
Athena は、AWS Glueの一機能であるGlue Data Catalog(メタデータストア) と統合しています。
Athenaを利用して分析をしているつもりでも、
その裏側ではS3 データに関するテーブルメタデータの保存と取得にAWS Glue Data Catalog を使用しています。
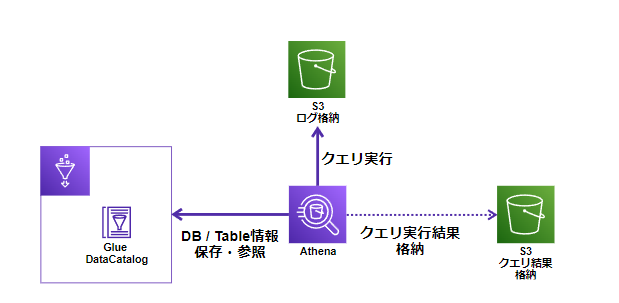
Athenaを利用するうえで、データベースとテーブルのスキーマを作成する方法は、以下の2通りです。
- ①Glueで作成する
- データソースに対して Athena 内から AWS Glue クローラを実行する
- ②Athenaで作成する
- Athena クエリエディタでデータ定義言語 (DDL) クエリを直接実行する
上記いずれかの方法で作成したのちに そのデータベースとテーブルのスキーマを使用して、Athena でデータ操作言語 (DML) クエリを使用することができます。
本記事でやること
Glueを利用してDB・Tableを定義し、AthenaでGlue Data Catalogのデータを参照します
前提条件
S3バケットにデータが保存済みであること。
※本記事ではS3バケットへのデータ格納方法は触れません
作業手順
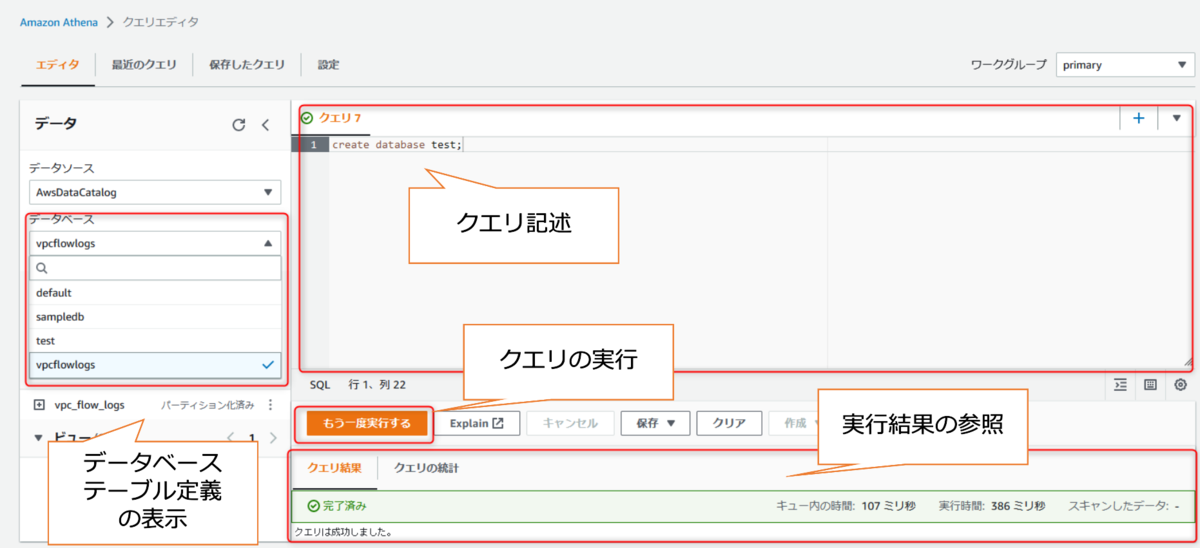
1.Databaseの作成
まずDatabaseを作成します。
Athenaから直接クエリで作成することも可能ですが、今回はGlueで実行していきます。
この作業により、Glue CatalogにメタデータとしてDatabaseが作成されます。
マネジメントコンソールより、AWS Glue画面へ遷移し左のナビゲーションペインより [Databases] を選択
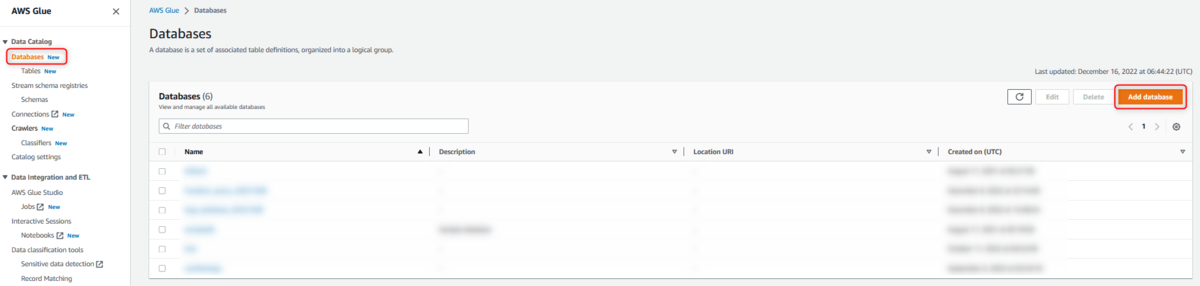
Database名を入力し、作成
GlueのDatabaseコンソール上にDatabaseが追加されていることが分かります。
またこの時同時にAthenaクエリエディタコンソール上でもDatabaseが追加されていることが確認できます。
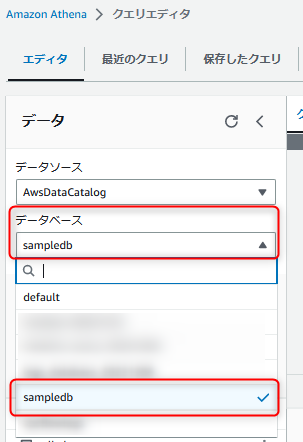
このようにAthenaが裏でGlue Data Catalog のメタデータを利用していることが分かりますね。
2.AWS Glue データ カタログにテーブルを定義する
公式手順は以下をご覧ください
チュートリアル: AWS Glue クローラの追加 - AWS Glue Studio
Set crawler properties
Glueのクローラでスキーマの自動作成を設定していきます。
左のナビゲーションペインより [Crawler] を選択
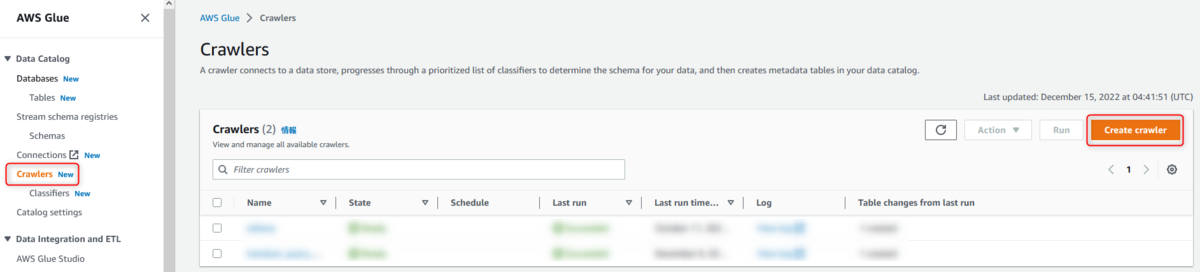
クローラの名前を入力
ここでは、[handson]とします。
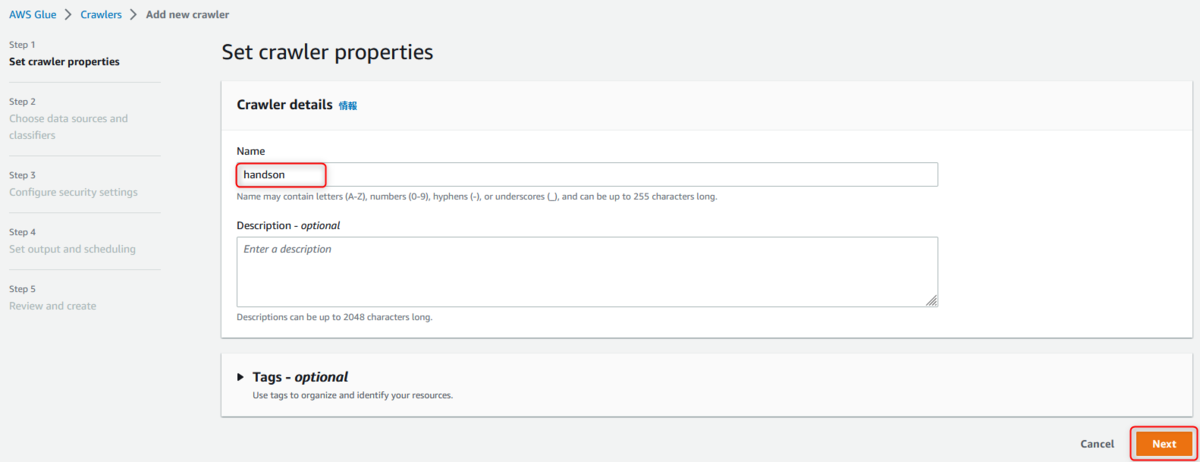
「既に Glue テーブルにデータがあるか?」と聞かれていますが、
今回事前に作成していないため「Not yet」とし、Add data sourceへ進みます。
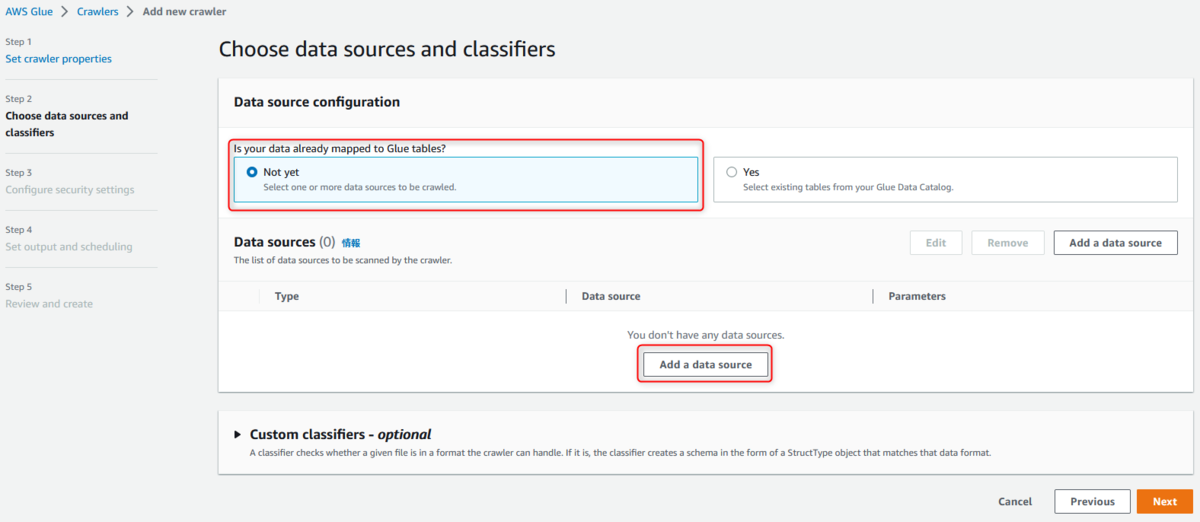
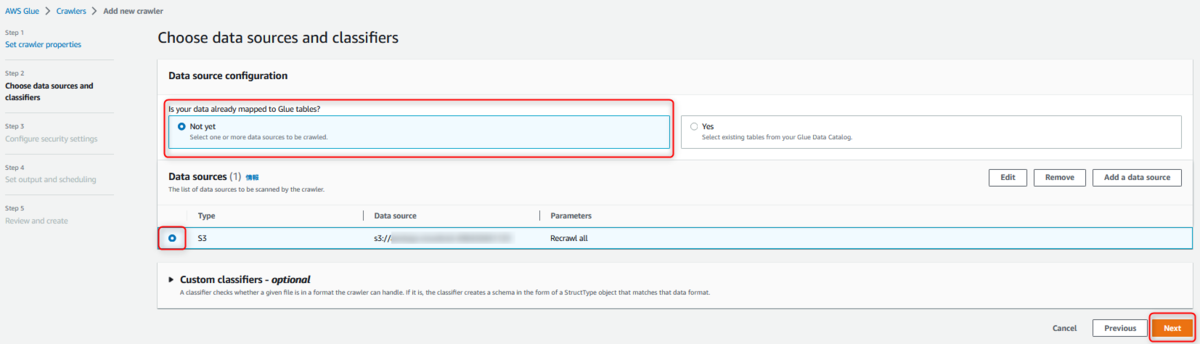
Choose data sources and classifiers
今回データソースはS3を選択
(単一のクローラで複数のデータストアをクロールすることも可能です)
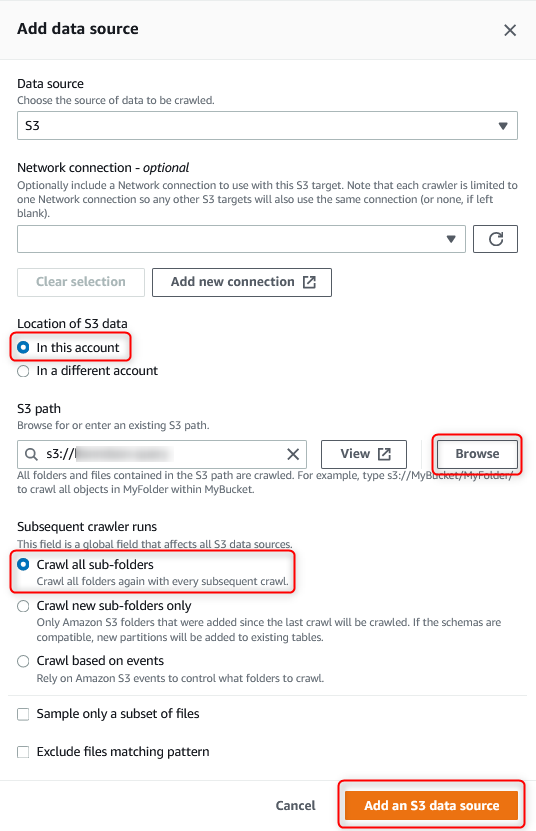
Network connection
データストアへのネットワークアクセスを設定する - AWS Glue
必要に応じて、この S3 ターゲットで使用するネットワーク接続を設定します。
データソースへの接続情報にあたります。JDBCで接続するデータベースやDynamoDBなどの接続を管理する機能です。
GlueジョブからVPC内のリソースにアクセスさせ、VPC内でジョブ実行させたい場合はConnectionを指定する必要があります。特に何も入力しなければ、何も使用しません。
Subsequent crawler runs
後続でクロールする際の条件を定義します
Crawl all sub-foldersCrawl(すべてのサブフォルダーをクロール)
クローラを実行するたびに、毎度すべてのフォルダをクロールします。Crawl new sub-folders(新しいサブフォルダーをクロール)
前回のクロール以降に追加された Amazon S3 フォルダーのみがクロールされます。Crawl based on events(イベントに基づくクロール)
SQSのイベントに基づいて動作します。対象のSQSの指定が必要です。
追加したデータソースを指定して、次へ
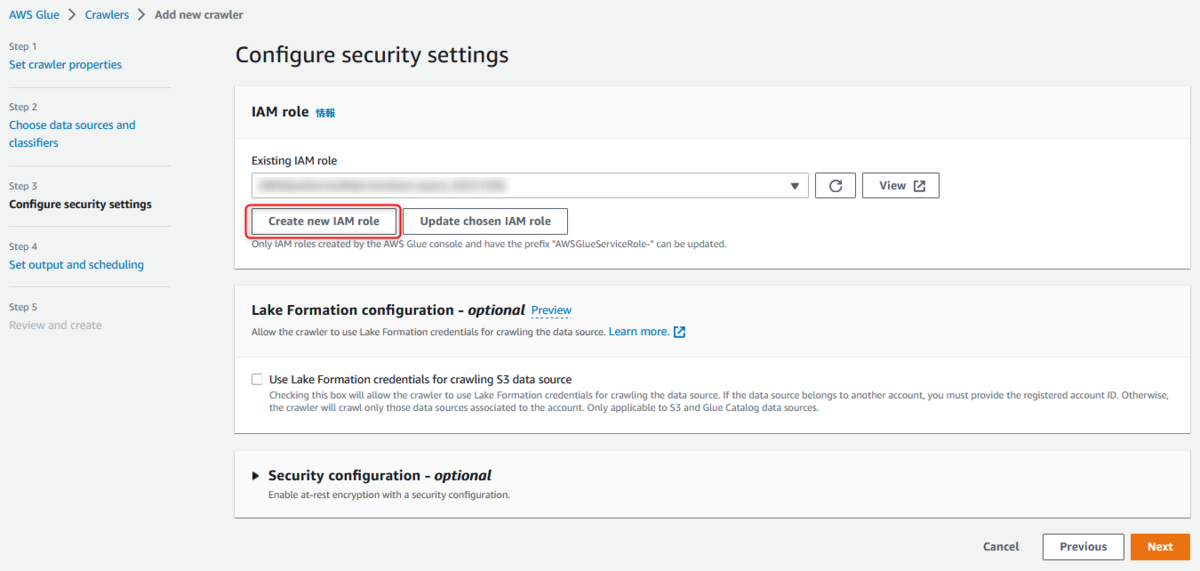
Configure security settings
クローラーがS3にアクセスして AWS Glue Data Catalog でオブジェクトを作成するために、クローラにアクセス許可を付与する必要があります。
この場で [Create new IAM role] をすると、データソースのS3へのアクセス許可のインラインポリシーと、AWS 管理ポリシー[AWSGlueServiceRole] が自動で付与されます。
IAMロールの生成
[Create new IAM role] をする場合に生成されるIAMロールは以下です。
※ただし自動作成されるがゆえに、インラインポリシー名には任意の文字列が入ります。
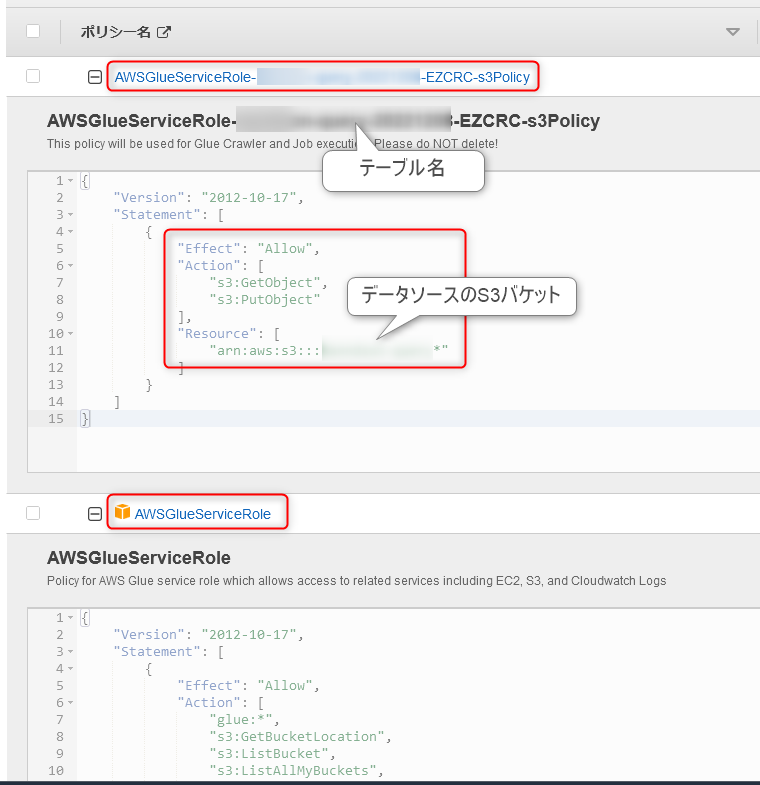
IAM ロール名は 「AWSGlueServiceRole-」で始まりますので、フィールドにはロール名の後ろの部分を入力してください。
Set output and scheduling
テーブルを作成するDatabaseを指定します。
先程作成したDatabaseを設定してください。
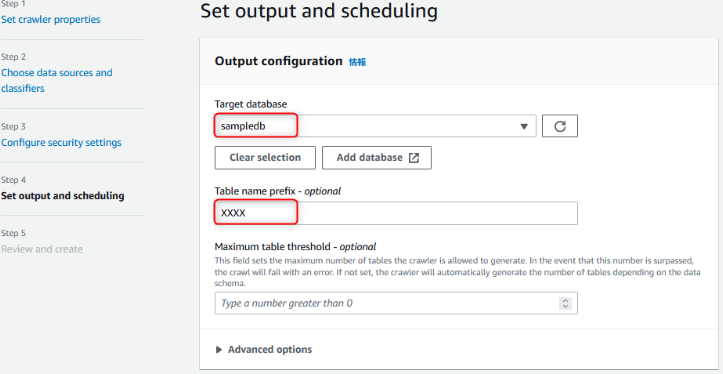
Table name prefix
クローラで作成したテーブルの名前を識別するために、プレフィックスの指定が可能です。
Maximum table threshold
クローラーが生成できるテーブルの最大数を設定できます。
設定しない場合は、データのスキーマに応じてテーブルを自動作成しますが、
最大値を設定した場合、指定した数値を超えるとエラーの挙動となります。
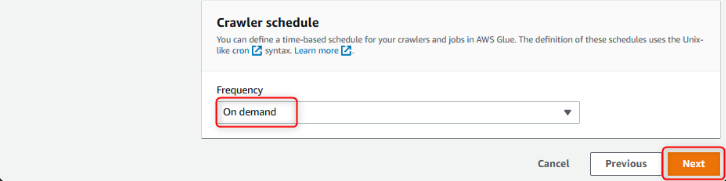
テーブルを作成するDatabaseとクローラを実行する頻度(スケジュール)を設定することが可能です。
定期実行 or スケジュール設定が出来ます(最小精度は 5 分)が、今回はオンデマンドで実行します。
最後に確認画面が表示されたら、クローラを作成しましょう。
※ここでは「クローラが作成される」までであり、クロール実行はされていないのでご注意下さい。
3.クローラを実行する
左のナビゲーションペインより、 [Crawlers] を選択し作成したクローラを選択します
[Run Crawler] を押下するとすぐに実行されます
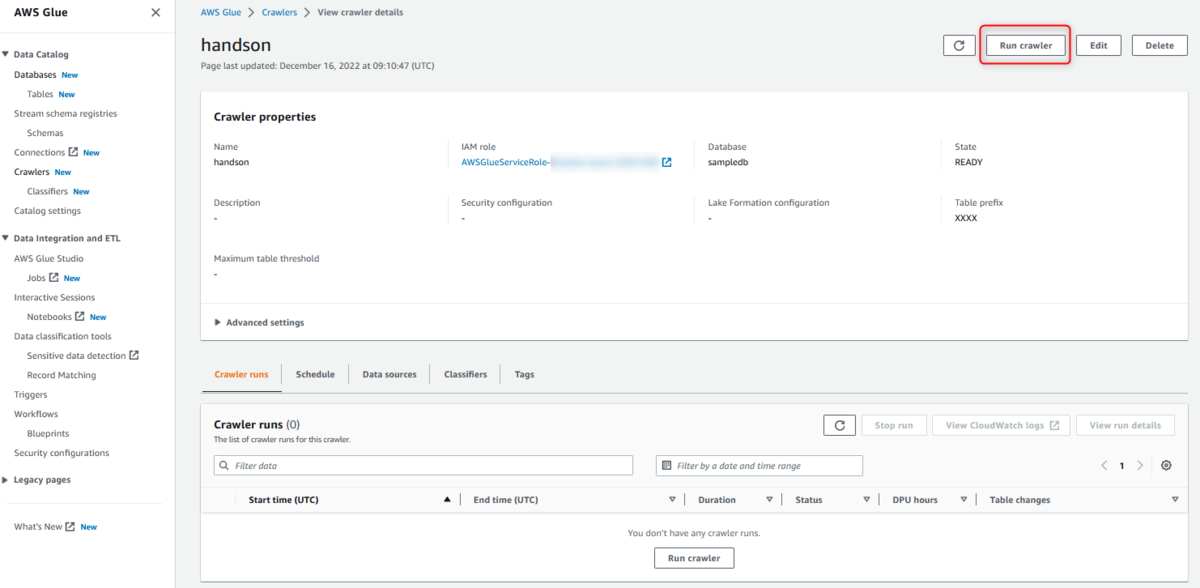
Statusが「Running」>「Completed」となれば完了です


Database作成時と同様に、GlueのTablesコンソール上に追加されていますし、
同時にAthenaのクエリエディタコンソール上でも指定したDatabaseの中にテーブルが追加されていることが確認できます。
4.AthenaでGlue Data Catalogのデータを参照する
ここまでで、Glue Data Catalog にDatabase/テーブルを作成がされています。
テーブルは、スキーマを含むデータを表すただのメタデータです。
Data Catalog のテーブルにはデータが含まれていません。
ここからはAthenaのクエリエディタで、本記事では全検索("SELECT * FROM <テーブル名>")までの実行を行います。
クエリエディタでSQLの実行
対象のDatabaseを選択したうえで、クエリエディタにSQLを記入します。
SELECT * FROM <テーブル名>
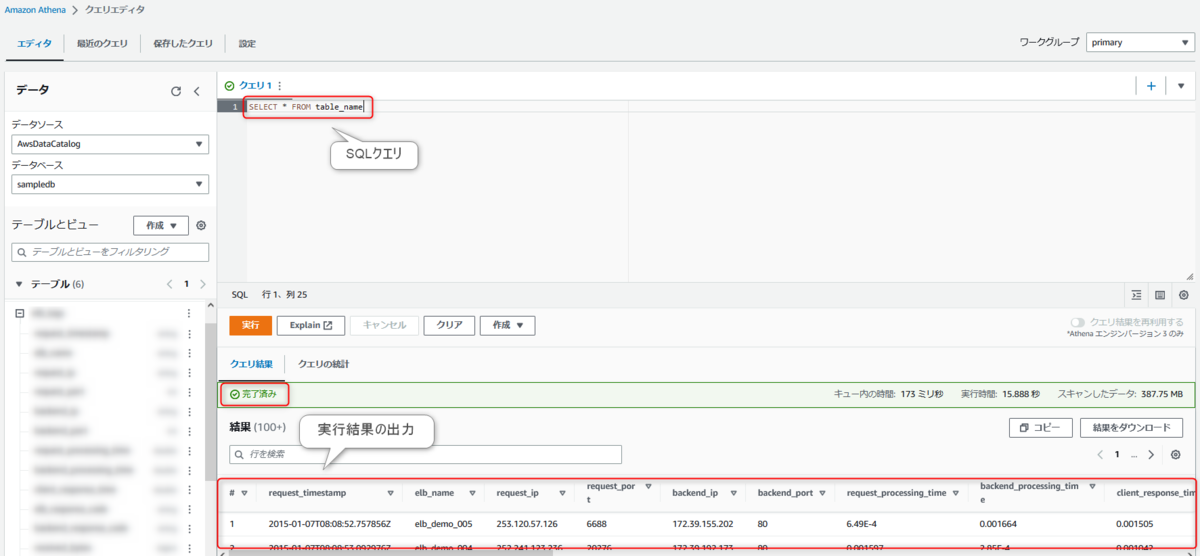
正しく実行されれば、エディタ下部に「クエリ結果」として、実行結果が出力されます。
このようにAthenaコンソール画面で標準SQLを実行が可能となりました。
おわり
Amazon Athenaを使ってS3のデータを分析するための準備手順をご紹介しました。
凝った設定は必要なく、GUIで実行環境を用意できますのでご参考になれば幸いです。