

SRE部 佐竹です。
今回のブログでは Amazon Lookout for Vision の推論モデルを精度よく維持管理するための運用を考えた結果を共有します。
はじめに
Amazon Lookout for Vision とは、コンピュータービジョン を使用し異常を検知することが可能となるマネージドの機械学習サービスの1つです。
Amazon Lookout for Vision を利用すれば、予め「正解画像(Normal)」と「異常画像(Anomaly)」を機械学習させることで、画像を渡した時に「異常」を判定する推論モデルをクラウド上に簡単に構築できます。
これはつまり、工場のライン等において「明らかに見た目が異常な組み立て品を途中で弾く」ような用途に活用できるということです。

加えて、推論モデルが「優れているかどうか」を判定する値である Precision: 適合率, Recall: 再現率, F1 score: F1値 をそれぞれ視覚的に表示してくれます。これらの値について良く知らないとしても、この値が高ければ高いほど優れているのだろう、というのは直感的にわかるようになっています。
Amazon Lookout for Vision の機能については既に別社員によるブログもありますので、合わせてご参考ください。
2021年1月現在はプレビュー状態にあり、GAしたタイミングで機能の仕様が変更される可能性も高く、現時点ではプレビュー中の機能での想定で記載している点についてご了承ください。
Amazon Lookout for Vision の運用
Amazon Lookout for Vision の全体構成をご紹介しながら、どのような運用が発生するのか説明します。
Amazon Lookout for Vision を開始する

Amazon Lookout for Vision を開始するには、上図の通りの流れになります。
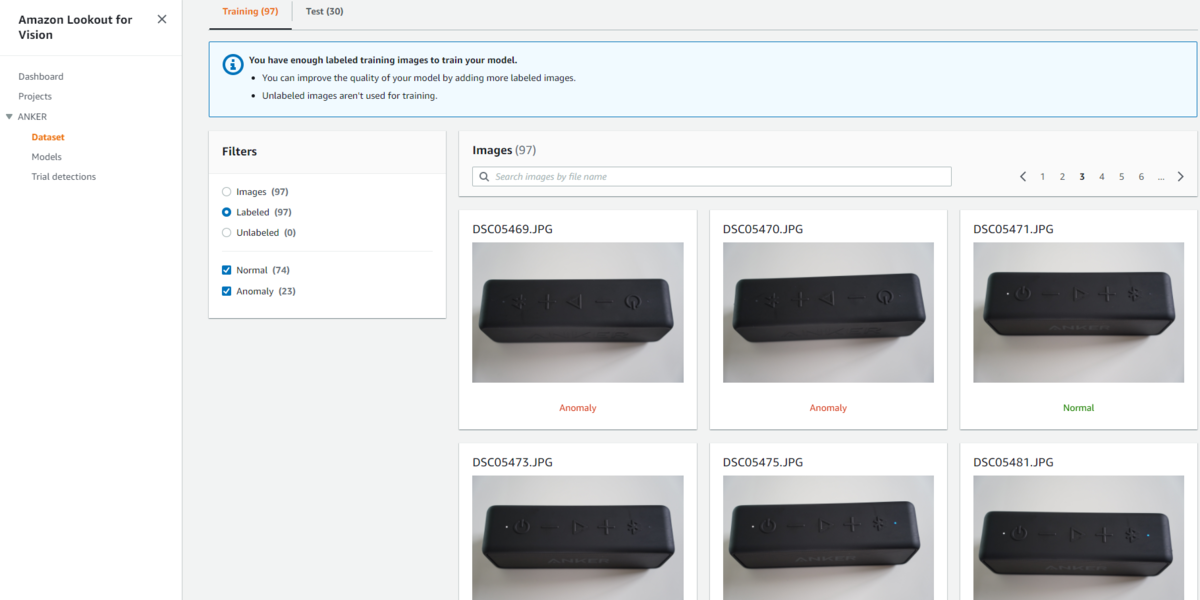
まずは「1. Training/Test に必要な画像セットを配置する」ですが、S3 Bucket にトレーニング及びテストのための画像セット(Dataset)をアップロードします。マネジメントコンソールからの直接の取り込みも可能ですが、S3 にアップロードされるほうが運用上良いと考えます。
それは、「2. Directory(Prefix)の設定で取り込み時の自動タグ付けが可能」と記載している箇所で、フォルダ階層を正しく設定することで自動のタグ付けに対応しているためです。

コンソールでは、上画像の通りフォルダ名に沿ってラベルを画像に自動付与するオプションがあります。これが非常に楽です。教師ありの機械学習ではラベルを付けるのに手間がかかりますが、その工数が大きく削減されます。

実際に上画像のように配置することで問題なくラベルの自動付与が行われました。
次に「3. S3 から Dataset を取り込み、学習により推論Modelを構築する」ですが、これは「Train model」を押下するだけで自動的に行われます。なお、Train model はある程度時間を要する処理です。実際に試してみたところ、Training (97枚)、Test (30枚)の画像で55分程度かかりました。
推論モデルが完成すれば、後は CLI 等を利用してその推論モデルに画像を渡すだけです。画像を受け渡す流れは画像の下半分になります。
まず「4. AWS CLI/SDKを予め機器にインストールしておく必要あり」と記載しているのは、この画像の受け渡しに CLI 等で処理を実行しなければならないためです。
そして「5. 検知したい対象を撮影して画像を取得」し、その画像を「6. detect-anomalies CLI の実行で画像を渡す」ようにすれば、「7. false(正常), true(異常)の判定結果を返却」されます。
注意したいのは、コマンドは「detect-anomalies」であり「異常が検知されているか?」という確認のコマンド名です。つまり「True」ということはイコール「Anomaly」であるとなります。よって、 false が正常を示し、 true が異常を示します。

実際のコマンド実行結果は、上画像のようになります。
運用上の注意事項ですが、本コマンドの実行は図の通り「インターネット経由」で行う必要があります。現状 VPC Endpoint が作成できないためです。よって、PoC などにおいてはインターネットに接続が可能な状況を確立して頂く必要があります。工場等のラインにおいて、これが実現可能かは懸念される事項となるでしょう。
運用 Tips 1. S3 のストレージクラス
S3 にアップロードする画像のコストを削減されたい方が多いと思います。そのような場合はS3のストレージクラスを変更することを推奨します。

今回、実際に検証では「One Zone-IA」を利用しました。「低頻度アクセス (S3 One Zone-IA)」は アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適しています。 と記載がある通り、今回のようなケースにマッチしています。
| Class | 月間利用料 | その他 |
|---|---|---|
| S3 標準(最初の 50 TB/月) | $0.025/GB | 初期値 |
| S3 標準 - 低頻度アクセス(IA) | $0.019/GB | IA: Infrequent Access |
| S3 1 ゾーン - 低頻度アクセス(IA) | $0.0152/GB | 今回利用したクラス |
| S3 Glacier | $0.005/GB | アーカイブされているためデータがすぐに利用ができない |
| S3 Glacier Deep Archive | $0.002/GB | アーカイブされているためデータがすぐに利用ができない |
表の通り、「One Zone-IA」はすぐに利用が可能なクラスの中で最も低コストであるため、コストを削減されたい方はこちらのストレージクラスがおすすめです。
※表に記載がある AWS 利用料は東京リージョンのものとなります
Amazon Lookout for Vision にフィードバックを行う
ここまでで「一旦推論モデルを作成して、それをもって異常検出を試した」ところまでは到達しました。
次は「実際にその推論モデルが使えるのかどうか」という判定を行うため、日々のフィードバック及び判定した結果を収集する必要があると考えています。そして、その収集されたデータを活用し推論モデルを改善することを考えます。

具体的には上図のような流れになると想定されます。
「8. 判定を行った画像とその結果をS3に収集し、精度を確かめる」と記載している箇所ですが、これはどういうことかと言いますと推論モデルは「決して間違わないわけではない」ため、以下の情報を収集し、継続的に推論を適切に維持していく必要があります。
- TP(真陽性):正しい=Anomalyと予想して、実際にAnomalyであったもの。及びその判定を行った画像
- TN(真陰性):誤り=Normalと予想して、実際にNormalであったもの。及びその判定を行った画像
- FP(偽陽性):正しい=Anomalyと予想して、実際にはNormalであったもの。及びその判定を行った画像
- FN(偽陰性):誤り=Normalと予想して、実際にはAnomalyであったもの。及びその判定を行った画像
これらを例えば S3 に収集し、分析を行う必要が出るでしょう。ただしこの部分は Amazon Lookout for Vision の範囲外ですので、Computer Vision の機器からいかにして S3 にこのデータと画像を転送するのかというのが運用上の課題になるのではと想像されます。
ラインの流れが非常に早い場合、都度 S3 への転送は負荷などを考えても現実的ではないでしょう。特に CLI/SDK の API コールの Error 発生時にリトライなど考えるとなると、画像は後ほどバッチ処理などでまとめて転送するほうがより良いように考えられます。
S3 に新しい画像が設置されたら、それと既存の画像を利用して「9. 再度学習を実行し推論モデルの新バージョンを作成する」ことになります。これにより推論モデルは新しいバージョン「2」となり更新されます。

実際に推論モデルを再作成すると、上画像の通りバージョンが増えて別のモデルになります。

上画像は実際のコンソールの UI ですが、残念ながら現在の仕様では S3 Bucket に入れたデータを既存の Dataset には追加できないようです。画像の受け渡しはブラウザから行うか、CLI などコマンドで受け渡しします。しかし、この時に S3 を転送元に選べない状況でした。
ここは今後改善されるのではと想定しますが、構成図のように S3 に転送したファイルをもって推論モデルを更新するということが直接的にできないのが現状です。
運用 Tips 2. 実際に発生した Error
aws lookoutvision detect-anomalies の CLI 実行時に An error occurred (ServiceUnavailableException) when calling the DetectAnomalies operation (reached max retries: 2): None というエラーが返ってきたことがあります。
参考までに記載します。直後に手動でリトライすると成功しました。
運用 Tips 3. FNに注意する
先の「偽陰性」と記載しました FN = False Negative ですが、これが最も注意すべき結果です。
生産ラインで考えますと「故障ではない Normal なものだ」と推論モデルが予想したということは、チェック時に正常なものとして通過しています。ですが実際は「Anomaly なものだった」となります。この FN の出現をできる限り下げるようにチューニングしていくのが1つの目標になります。
推論モデルの新しいバージョンを使用する
先ほど新しいバージョンを作成した推論モデルですが、そのままだと古いバージョンを使い続けてしまうため更新が必要です。

以下が実際に実行する時に利用した CLI のコマンドですが --model-version 1 と引数でバージョンを指定しています。
aws lookoutvision detect-anomalies --project-name ANKER --model-version 1 --content-type image/jpeg --body /home/cloudshell-user/Anomaly3.JPG
ここを新しいバージョンナンバーに更新しなければ、バージョン2の推論モデルが利用できません。その作業が図の「10. 推論モデルの新しいバージョンを指定するよう更新」にあたります。
11.~からは先ほどと同じ流れになります。
実際の運用を想定してみますと、各 Computer Vision に対して「バージョンの引数を更新する作業を施す」のはかなり手間です。遠隔操作でまとめて更新できるような仕組みも必要になってくると考えられます。
まとめ
今回のブログではGA後に本番環境で使うことを想定し Amazon Lookout for Vision の運用を深く考えてみました。注意したい点はいくつかありますが、まとめると特に以下の点が気になります。
- 判定した画像とその結果をどう収集して推論モデルの質を向上させるのか
- Computer Vision の更新やメンテナンスをどのように行うのか
この2点を特に十分検証した上で運用設計を行わない場合、維持運用が厳しいのではと考えられます。
また「画像の判定」なのですが、工場ラインの画像が実際に「正常」なのか「異常」なのかは、情報システム部の人材には判定ができないと考えられます。よって情報を正しく吸い上げていくには現場の方々の協力も必要になります。しかし現場の方々に、AWS や機械学習の何かをわかって頂くことは高いハードルとなります。よって、この間をうまく取りまとめる役割(人材)を用意するなどコミュニケーション部分でも注意が必要な箇所があると感じました。
2月24日に一般提供が開始されました
今回はここまでとなります。それでは、またお会いしましょう。
佐竹 陽一 (Yoichi Satake) エンジニアブログの記事一覧はコチラ
セキュリティサービス部所属。AWS資格全冠。2010年1月からAWSを業務利用してきています。主な表彰歴 2021-2022 AWS Ambassadors/2020-2025 Japan AWS Top Engineers/2020-2025 All Certifications Engineers。AWSのコスト削減やマルチアカウント管理と運用を得意としています。