

本記事を執筆するにあたり、前提条件となる Terraform の「状態ファイル(tfstate)」と「インポート(import)」について説明を記載します。
その次に、Aurora クラスターをリストアする手順について、概要と実際の手順を記載します。
Terraform の状態ファイル(tfstate)とインポート(import)
状態ファイル(tfstate)
Terraform では、 terraform apply を実行した際に、実際のAWS 環境の状態を保持しています。 apply を 一回以上実行した環境には、状態ファイル (tfstate) が存在します。(ファイル名:terraform.tfstate)
状態ファイル (tfstate)では、「コード (tf) に記載した 1 つのリソース (resource)」 と、「実環境に作成したリソース」を 1 対 1 で対応付けしています。
状態ファイル (tfstate) があることにより、二回目以降の plan / apply 時にコード (tf) と AWS 環境間の差分のみを表示・更新することができます。
terraform plan や terraform apply では、tfstate を元に、「コード (tf) に記載した 1 つのリソース (resource) 」と、「実環境に作成したリソースの現在の環境上での状態」を比較し、表示・更新しています。
ご参考1:State | Terraform | HashiCorp Developer
This state is stored by default in a local file named "terraform.tfstate", but we recommend storing it in Terraform Cloud to version, encrypt, and securely share it with your team.
Terraform uses state to determine which changes to make to your infrastructure. Prior to any operation, Terraform does a refresh to update the state with the real infrastructure.
The primary purpose of Terraform state is to store bindings between objects in a remote system and resource instances declared in your configuration. When Terraform creates a remote object in response to a change of configuration, it will record the identity of that remote object against a particular resource instance, and then potentially update or delete that object in response to future configuration changes.
For more information on why Terraform requires state and why Terraform cannot function without state, please see the page state purpose.
詳細については以下の記事もご参照いただけると幸いです。
ご参考2:【Terraform】plan / apply と状態ファイル (tfstate) の関係 - サーバーワークスエンジニアブログ
状態ファイル(tfstate)からリソースの情報を削除する
状態ファイル(tfstate)からリソースの情報を削除することもできます。
Terraform で作成したものの、今後 terraform plan や terraform apply の実行対象から外したい場合に使用します。
通常では、ほとんどないケースでしょう。
コマンドの例です。
terraform state rm aws_rds_cluster.db-1
ご参考1:Command: state rm | Terraform | HashiCorp Developer
You can use terraform state rm in the less common situation where you wish to remove a binding to an existing remote object without first destroying it, which will effectively make Terraform "forget" the object while it continues to exist in the remote system.
類似のコマンドに、対応付けするリソースを変更するterraform state mv もあります。こちらも利用シーンは非常に限られます。
ご参考2:Command: state mv | Terraform | HashiCorp Developer
You can use terraform state mv in the less common situation where you wish to retain an existing remote object but track it as a different resource instance address in Terraform, such as if you have renamed a resource block or you have moved it into a different module in your configuration.
インポート(import)
Import では、コード (tf) に記載したリソース (resource)と、 AWS 環境に既にあるリソースの対応付けを行うことができます。
つまり、状態ファイル(tfstate)内にリソースの対応付けを追加することができます。
Terraform 以外の方法で作成した AWS リソースを、改めて Terraform でコード管理するようなときなどにも利用できます。
import する前提は以下です。
- コード (tf) に対象のリソース (resource) 情報を記述していること
- AWS 環境に既にリソースがあること
Import する際には、「コード (tf) 上のリソース名 (resource)」 と、「実際の AWS 環境にあるリソースの情報」を import ブロックに指定します。下の例では、Terraform 上のリソース名:aws_rds_cluster.test と、実際の AWS 環境にある Aurora クラスターの識別子 db1-test を対応付けします。
import { to = aws_rds_cluster.test id = "db1-test" }
以前は terraform import コマンドがあったものの、Terraform v1.5.0 以降では import ブロックが使えるようになりました。結果、terraform plan 、 terraform apply コマンドのみで import できるようになりました。
ご参考1:Import - Configuration Language | Terraform | HashiCorp Developer
Use the import block to import existing infrastructure resources into Terraform, bringing them under Terraform's management. Unlike the terraform import command, configuration-driven import using import blocks is predictable, works with CICD pipelines, and lets you preview an import operation before modifying state.
Aurora クラスターの場合はクラスターの識別子 (cluster_identifier) が、引数になります。リソースによって、 import コマンドに渡す引数が変わるので、対象リソースのドキュメントを確認する必要があります。
ご参考2:Resource: aws_rds_cluster
Using terraform import, import RDS Clusters using the cluster_identifier. For example:
% terraform import aws_rds_cluster.aurora_cluster aurora-prod-cluster
最後に、import を実行するには、terraform apply が必要です。
Terraform processes the import block during the plan stage. Once a plan is approved, Terraform imports the resource into its state during the subsequent apply stage.
なお、import ブロックについては、import 後に削除する必要はありません。
同じ内容の import を複数回実行しても害はありません。
Terraform only needs to import a given resource once. Attempting to import a resource into the same address again is a harmless no-op. You can remove import blocks after completing the import or safely leave them in your configuration as a record of the resource's origin for future module maintainers. For more information on maintaining configurations over time, see Refactoring.
ご参考:Import - Configuration Language | Terraform | HashiCorp Developer
管理上、不都合があるなら削除しても大丈夫です。
【図解】Aurora クラスターをリストアする流れ
Terraform で Aurora クラスターをリストアしてみましょう。
もともと Terraform で Aurora クラスターを作成していると仮定します(resource 名:aws_rds_cluster.test)。
もともとあるクラスターからポイントインタイムリカバリ機能を使い、最新のスナップショットからリストア用のクラスターを作成します。
リストアすると、元のクラスターと異なる識別子の新しいクラスターができますので、アプリからDB接続させるために、識別子を付け替えます。
参考:DB クラスターを指定の時点の状態に復元する - Amazon Aurora
DB クラスターを特定の時点に復元し、新しい DB クラスターを作成することができます。
最後に、リストアした新しいクラスターを、元のクラスターを作成した Terraform コード(resource 名:aws_rds_cluster.test)で管理するには、状態ファイル (tfstate) の対応付けを変更する必要があります。
具体的なサンプルコードは後ほど記載します。
まずは図で作業の流れを示します。
1.Terraform で作成した Aurora クラスターがある状態
Aurora クラスターが 1 つあり、インスタンスも 1 つある状態です。

2.Terraform でリストア用のクラスターを作成
もともとあるクラスターからポイントインタイムリカバリでリストア用のクラスターを作成するコード (tf) を terraform apply し作成します。

3.AWS マネジメントコンソールで手動で、アプリのDB接続するクラスターを切り替える(Terraform 外の作業)
AWS マネジメントコンソールで、もともとあるクラスターの識別子を、リストア用のクラスターに付け替えることにより、アプリのDB接続するクラスターを切り替えます。

参考記事:[Amazon RDS] スナップショットから復元する時に元のエンドポイント名を設定する方法 - サーバーワークスエンジニアブログ
4.リストア用のクラスターを作成するコード (tf) を削除
リストアが完了したため、リストア用のクラスターを作成するコード (tf) を削除します。

5.状態ファイル(tfstate)で「もともとあるクラスターを作成したコード (tf)」 と 「実環境にあるリストアしたクラスター」を対応付ける
状態ファイル(tfstate)では、「もともとあるクラスターを作成したコード (tf)」 と 「実環境にあるリストアしたクラスター」を対応付けして管理します。
そのために、まずは状態ファイル(tfstate)からリソースの情報を削除(terraform state rm)します。

そして、リソースの対応付けを新たに追加(import)します。

最後に、terraform applyを実施します。
6. AWS マネジメントコンソールで手動で、元のクラスターを削除(Terraform 外の作業)
AWS マネジメントコンソールで手動で、元のクラスターを削除します。管理者ユーザーの認証情報を Secret Manager で管理している場合には、シークレットも削除します。
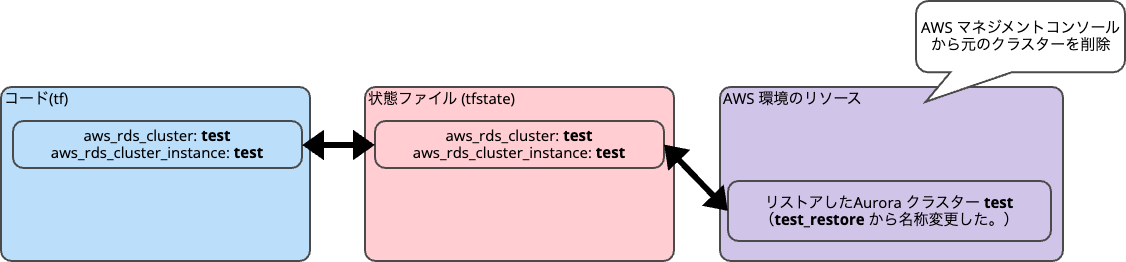
これにてリストアが完了し、状態ファイル(tfstate)も整合性のある状態です。
(元のクラスターを管理していたコード (tf) を変更すると、リストアしたクラスターの方に変更を加えることができる状態です。)
検証に利用したサンプルコード
バージョンは以下を利用しました。
- Terraform v1.7.4
- awsプロバイダー v5.41.0

もともと Terraform で 作成している Aurora クラスター(aws_rds_cluster.test)
もともと Terraform で 作成している Aurora クラスター(aws_rds_cluster.test)の tf ファイルです。
- rds.tf
resource "aws_rds_cluster" "test" { cluster_identifier = "provisioning-rds" db_subnet_group_name = aws_db_subnet_group.test.name db_cluster_parameter_group_name = aws_rds_cluster_parameter_group.test.name engine_version = "15.3" engine = "aurora-postgresql" engine_mode = "provisioned" enable_http_endpoint = true iam_roles = [] master_username = "postgres" manage_master_user_password = true enable_global_write_forwarding = false network_type = "IPV4" serverlessv2_scaling_configuration { max_capacity = 16 min_capacity = 2 } vpc_security_group_ids = ["sg-xxxxxxxxxx"] skip_final_snapshot = true } resource "aws_rds_cluster_instance" "test" { cluster_identifier = aws_rds_cluster.test.cluster_identifier db_subnet_group_name = aws_rds_cluster.test.db_subnet_group_name db_parameter_group_name = aws_db_parameter_group.test.name engine = aws_rds_cluster.test.engine engine_version = aws_rds_cluster.test.engine_version identifier = "rds-1" instance_class = "db.serverless" } resource "aws_db_subnet_group" "test" { name = "test_db_group" subnet_ids = ["subnet-xxxxxxxxxx","subnet-xxxxxxxxxx"] } resource "aws_rds_cluster_parameter_group" "test" { name = "test-rds-cluster-parameter-group" family = "aurora-postgresql15" description = "test" } resource "aws_db_parameter_group" "test" { name = "test-rds-instance-parameter-group" family = "aurora-postgresql15" description = "test" } resource "aws_ssm_parameter" "db_endpoint" { name = "jdbc_url" type = "String" value = aws_rds_cluster.test.endpoint } resource "aws_ssm_parameter" "reference_test" { name = "reference" type = "String" value = aws_ssm_parameter.db_endpoint.value }
リストア用のクラスターを作成するコード(aws_rds_cluster.test_restore)
リストア用のクラスターを作成する際も Terraform を使いました(aws_rds_cluster.test_restore)。こちらはスナップショットからリストアするコードになっているため、通常運用時の terraform plan/apply では使えないコードです。通常時は削除しておきます。
サブネットグループやパラメータグループは、もともと Terraform で 作成している Aurora クラスター(aws_rds_cluster.test)と同じものを使用します。
- rds-restore.tf
data "aws_rds_cluster" "snapshot" { cluster_identifier = "provisioning-rds" } resource "aws_rds_cluster" "test_restore" { cluster_identifier = "provisioning-rds-restore" db_subnet_group_name = data.aws_rds_cluster.snapshot.db_subnet_group_name db_cluster_parameter_group_name = data.aws_rds_cluster.snapshot.db_cluster_parameter_group_name engine_version = data.aws_rds_cluster.snapshot.engine_version engine = data.aws_rds_cluster.snapshot.engine engine_mode = data.aws_rds_cluster.snapshot.engine_mode enable_http_endpoint = true iam_roles = data.aws_rds_cluster.snapshot.iam_roles master_username = data.aws_rds_cluster.snapshot.master_username manage_master_user_password = true enable_global_write_forwarding = false network_type = data.aws_rds_cluster.snapshot.network_type serverlessv2_scaling_configuration { max_capacity = 16 min_capacity = 2 } vpc_security_group_ids = data.aws_rds_cluster.snapshot.vpc_security_group_ids skip_final_snapshot = true restore_to_point_in_time { source_cluster_identifier = data.aws_rds_cluster.snapshot.id use_latest_restorable_time = true } } resource "aws_rds_cluster_instance" "test_restore" { cluster_identifier = aws_rds_cluster.test_restore.cluster_identifier db_subnet_group_name = aws_rds_cluster.test_restore.db_subnet_group_name db_parameter_group_name = "test-rds-instance-parameter-group" engine = aws_rds_cluster.test_restore.engine engine_version = aws_rds_cluster.test_restore.engine_version identifier = "rds-restore-1" instance_class = "db.serverless" }
AWS 環境にあるリストアしたクラスターを、元のクラスターを作成したコードに(aws_rds_cluster.test) import するコード
クラスターと、インスタンスも import します。
- rds-import.tf
import { to = aws_rds_cluster.test id = "provisioning-rds" } import { to = aws_rds_cluster_instance.test id = "rds-1" }
実際にやってみた
1.Terraform で作成した Aurora クラスターがある状態

2.Terraform でリストア用のクラスターを作成
もともと Terraform で 作成している Aurora クラスターがあるところに、リストア用のクラスターを作成するコード(aws_rds_cluster.test_restore)を apply します。



リストア用のクラスターとインスタンスができました。


管理者ユーザーの情報を Secrets Manager で管理するようにしており、リストア用のクラスターに関する管理者ユーザーのシークレットもできました。

注意!!
1 点だけ注意がありました。
コード (tf) では、enable_http_endpoint = true を設定し、RDS Data API を有効にして、リストアしています。
実際にリストアしたインスタンスでは、RDS Data API が無効になっていました。
そのため、AWS マネジメントコンソールから手動で有効にしました。



ちなみに、AWS マネジメントコンソールで RDS Data API を有効にして、リストアしても、RDS Data API が無効になっていました。
そのため、Terraform 側の問題ではなく、スナップショットからのリストア機能に起因するものと考えられます。
3.AWS マネジメントコンソールで手動で、アプリのDB接続するクラスターを切り替える(Terraform 外の作業)
もともとのクラスター名の末尾に "-old" を付与して、すぐに適用します。

リストアしたクラスター名をもともとのクラスター名に変更して、すぐに適用します。

もともとのクラスターにあるインスタンス名の末尾に "-old" を付与して、すぐに適用します。

リストアしたクラスターにあるインスタンス名を、もともとのインスタンス名に変更して、すぐに適用します。

識別子の変更が終わりました。

4.リストア用のクラスターを作成するコード (tf) を削除
リストア用のクラスターを作成するコード(aws_rds_cluster.test_restore)がある rds-restore.tf を Terraform の実行ディレクトリから削除しました。
これにより、terraform plan や terraform apply の影響範囲から外しました。
5.状態ファイル(tfstate)で「もともとあるクラスターを作成したコード (tf)」 と 「実環境にあるリストアしたクラスター」を対応付ける
Aurora クラスターやインスタンスには "Resource ID" という、リージョン内で一意の ID が付いています。識別子(DB identifier)とは異なります。
現状の状態ファイル (tfstate)内にある、「コード (tf) に記載した 1 つのリソース (resource)」 と、「実環境に作成したリソース」の 1 対 1 の対応付け内容を、"Resource ID" を使って確認できます。
以下のコマンドで確認できます。出力結果は割愛します。
terraform state show aws_rds_cluster.testを実行し、cluster_resource_idを確認すると、もともとの Aurora クラスターの Resource ID になっています。terraform state show aws_rds_cluster_instance.testを実行し、dbi_resource_idを確認すると、もともとの Aurora クラスターにあるインスタンスの Resource ID になっています。
現状を確認できたので、状態ファイル(tfstate)から既存の情報を削除します。
terraform state rm aws_rds_cluster.test

terraform state rm aws_rds_cluster_instance.test

削除できました。
リストアしたクラスター・インスタンスと対応付けをするため、 Terraform の実行ディレクトリに import 用のコード (tf) を配置します。
- rds-import.tf
import { to = aws_rds_cluster.test id = "provisioning-rds" } import { to = aws_rds_cluster_instance.test id = "rds-1" }
terraform plan を実行します。
2 つの import と 1 つの change があります。
change の詳細は「留意事項」を見てください。


import を反映させるために、terraform apply を実行します。

もう一度 apply を実行すると、差分なしになりました🎉

留意事項
コード(tf)と実際のリソースの対応付けのみ行うため、import が出来れば良いと考えていたので、1 つの change は想定外でした。
1 つの change の内容は、enable_global_write_forwarding = falseにする、というものでした。
enable_global_write_forwarding は Aurora グローバルクラスター向けのパラメータで、グローバルクラスターでない場合は false になります。
セカンダリーリージョンにセカンダリーのクラスターを作成する際に有効化できます。
Aurora クラスターの作成時のコード(aws_rds_cluster.test)や、リストア用のクラスターを作成するコード(aws_rds_cluster.test_restore)で、明示的に false にしていても、import の際に change として出てしまうようでした。
issue も探したものの、見つかりません。
terraform apply を実行しても false を true/false に変更する処理は発生せず、ダウンタイムなど影響もないため、無視して問題ないと判断しました。
CloudTrail に ModifyDBCluster の実行ログはあるものの、EnableLocalWriteForwarding に関する変更内容も出ていませんでした。

参考1:Using write forwarding in an Aurora PostgreSQL global database - Amazon Aurora
デフォルトでは、セカンダリクラスターを Aurora Global Database に追加すると、書き込み転送は有効になりません。セカンダリ DB クラスターの書き込み転送は、作成中または作成後にいつでも有効にできます。必要に応じて、後で無効にすることができます。書き込み転送を有効または無効にしても、ダウンタイムや再起動は発生しません。
参考2:enable_global_write_forwarding
(Optional) Whether cluster should forward writes to an associated global cluster. Applied to secondary clusters to enable them to forward writes to an aws_rds_global_cluster's primary cluster. See the Aurora Userguide documentation for more information.
もし、issue を見つけることができた場合や、issue を作成した場合には本記事追記します。
▶ Issue を作成しました。 設定値として False がないリソースに対して、毎回 False と設定し続けることによって、changes が発生しているとのことでした。
原因部分:

対応優先度の投票は、Thumbs Up の絵文字リアクション数を指標にしているようです。 良ければ投票をお願いします。
投票:
 投票リンク:https://github.com/hashicorp/terraform-provider-aws/issues/38578#issue-2435162470
投票リンク:https://github.com/hashicorp/terraform-provider-aws/issues/38578#issue-2435162470
6. AWS マネジメントコンソールで手動で、元のクラスターを削除(Terraform 外の作業)
最後に元のインスタンス、元のクラスターの順に AWS マネジメントコンソールから Aurora クラスターを削除します。


Secret Manager のシークレットも忘れずに削除しましょう。


まとめ
Terraform を 利用して、Aurora クラスターをリストアし、もともとのコード (tf) をリストアしたインスタンスに対応付けることができました。