

こんにちは!技術2課の濱岡です。 どうぶつの森でサメが釣れはじめてちょっと釣りが楽しくなっています。 背びれが見えている魚ばかり釣ってしまいますね。
さて、今回はAmazon CloudSearchにSlackのメッセージを格納してそれを検索してみようというのをやってみます。
こちらもよろしければどうぞ Amazon CloudSearchとAmazon Elasticsearch Serviceを実際に触ってみた
目的
弊社Slackでは技術的な質問したり、ノウハウを共有するチャンネルがあります。 その情報を格納して検索できれば面白いかなと思いまして、今回はそのチャンネルの情報を取得してAmazon CloudSearchで検索してみるというのをやってみます。
Pythonを使ってSlackのメッセージを取得し、jsonでファイルに格納してそれをAmazon CloudSearchに入れて検索してみます。
今回は、Pythonは3.7.3とPythonのモジュールであるRequestsとSlackのAPIのconversations.historyを使用しました。
Slackのメッセージの取得
まずはSlack Appの作成
メッセージの取得をするためにまずはSlack Appを作成します。 ここにまずアクセスします。 そしてCreate New Appを押します。
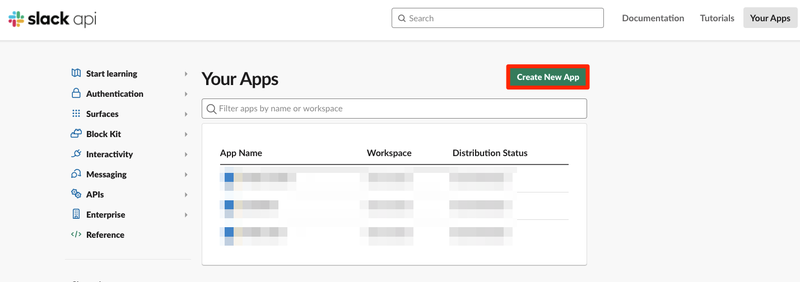
Slack Appの名前とワークスペースを選択してCreate Appを選択します。
名前やアイコンなどはお好みで設定してください。
メッセージを取得するための権限をつけます。 OAuth&Permissionを押します。 そしてAdd an OAuth Scapeをクリックして以下を追加してください。
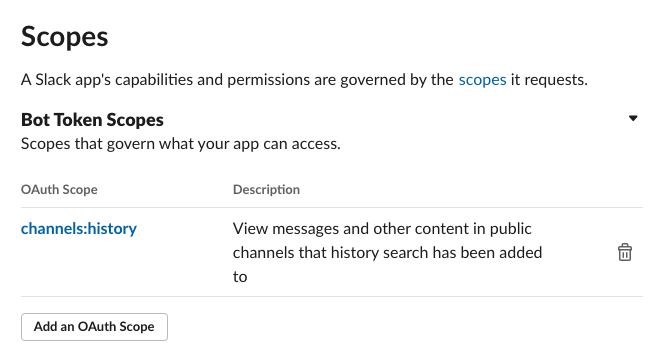
これでメッセージの取得ができるようになります。
そして上にスクロールするとInstall App to Workspacesがあるのでそれを押して自分のワークスペースにインストールします。

トークンが発行されたら準備完了です!
メッセージを取得してみる
今回、トークンやチャンネルIDなど必要な情報は環境変数から取得しています。 SlackのAPIのURLはこちらから確認してください。 SlackのチャンネルIDはブラウザ版のSlackから取得したいチャンネルを押してそのURLの末尾の英文字列になります。 とりあえず100個メッセージを取得してみました。
import json
import os
import requests
from dotenv import load_dotenv
#環境変数の取得
load_dotenv()
slack_channel_id = os.environ["SLACK_CHANNEL_ID"]
slack_api_url = os.environ["SLACK_API_URL"]
slack_api_token = os.environ["SLACK_API_TOKEN"]
def get_history():
params = {
"token":slack_api_token,
"channel":slack_channel_id,
"limit":100
}
data = requests.get(slack_api_url, params=params)
json_data = data.json()
return json_data
取得したメッセージからjsonのファイルを作成
このままだとAmazon CloudSearchには入れられないのでデータを綺麗にしていきます。 今回、検索用に使うのはSlackのメッセージのテキストだけにしたいのでそれだけをjsonファイルに格納していきます。
import json
def conversion_json(dict_data):
respons_data = []
index_number = 0
for value in dict_data["messages"]:
respons_data.append({"type":"add",
"id":str(index_number),
"fields":{
"message":value["text"]
}
})
index_number+=1
return respons_data
def create_json_file(data):
with open("sample.json", "w") as file:
file.write(json.dumps(data, indent=4, ensure_ascii=False))
作成したjsonファイルの中身はこんな感じです。
[
{
"type": "add",
"id": "0",
"fields": {
"message": "Slackのテキスト"
}
},
{
"type": "add",
"id": "1",
"fields": {
"message": "Slackのテキスト"
}
},
・
・
・
{
"type": "add",
"id": "99",
"fields": {
"message": "Slackのテキスト"
}
}
]
Amazon CloudSearchに入れて検索してみる
ドメインの作成
まずは、ドメインを作成していきます。 Amazon CloudSearchのマネージメントコンソール上からCreate a new search domainを押します。
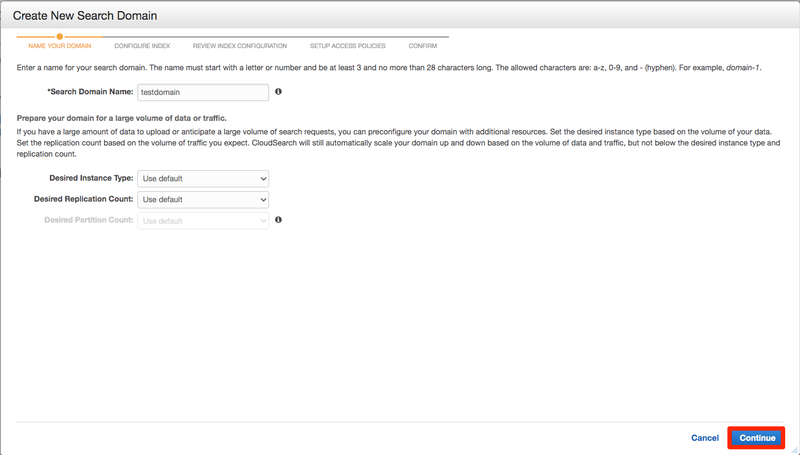
Search Domain Nameはお好きな名前で大丈夫です。 私はtestdomainにしました。 Desired Instance TypeとDesired Replication Countは今回はdefaultにしておきます。 設定できましたらContunueを押します。
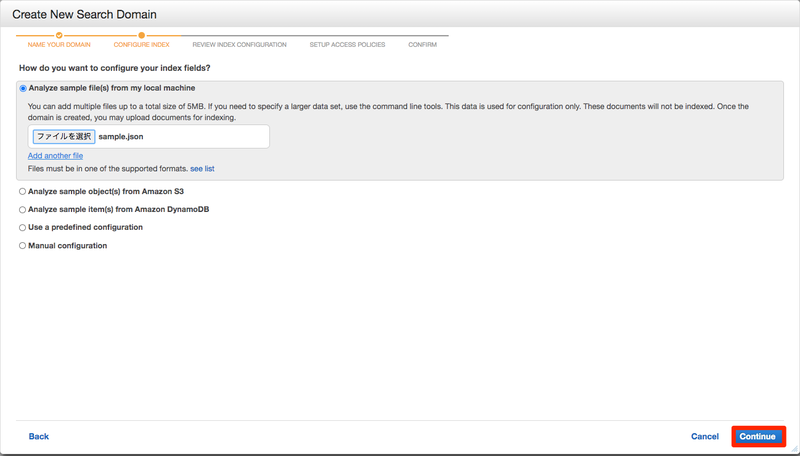
次はindexを作成します。 上で作ったjsonファイルを読み込ませれば大丈夫です。 今回はローカルからファイルをアップロードするのでAnalyze sample file(s) from my local machineを選択してファイルをアップロードしてください。 選択できましたら、Continueを押します。
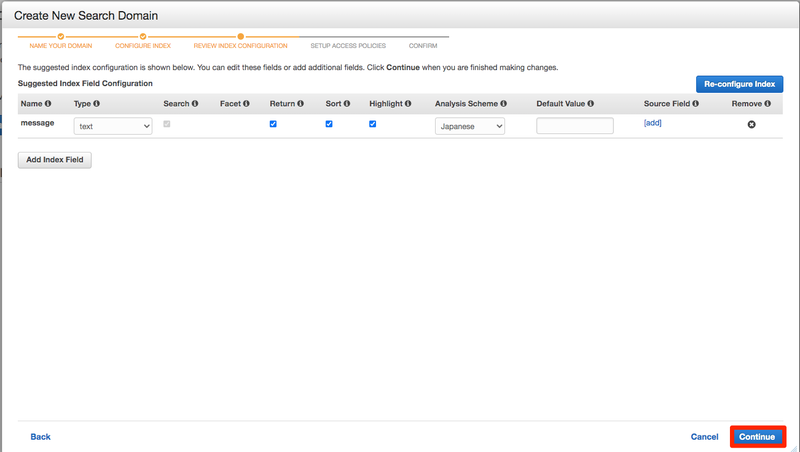
indexの確認画面がでますので問題なければContinueを押します。
次にポリシーを選択します。 Search and Suggester service: Allow all. Document Service: Account owner only.を押してポリシーが表示されましたらContinueを押します。
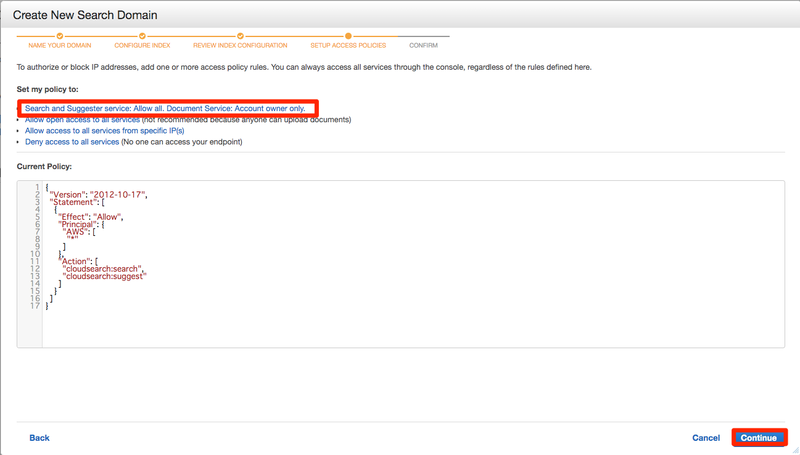
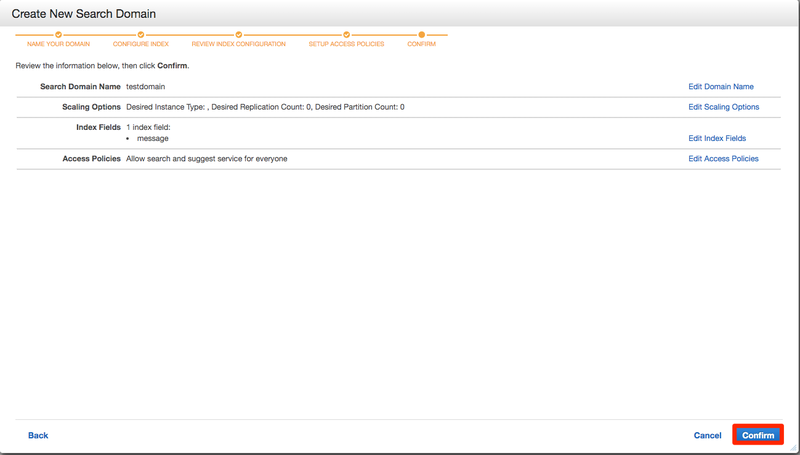
確認画面がでますので問題なければConfirmを押してください。
この画面がでましたらOKを押してください。
ドメインの作成まで10分ほどかかるので待ちます。
データのアップロード
いよいよデータのアップロードです。
Update Documentsを押します。
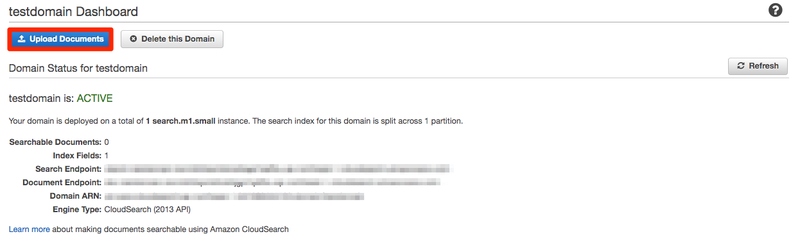
File(s) on my local diskを選択して作成したjsonファイルを選択してContinueを押します。
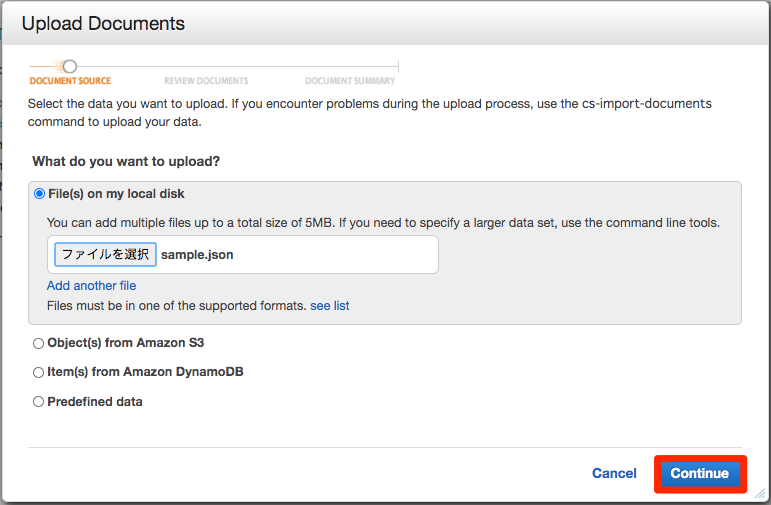
確認画面がでますので問題なければUpload Documentsを押します。
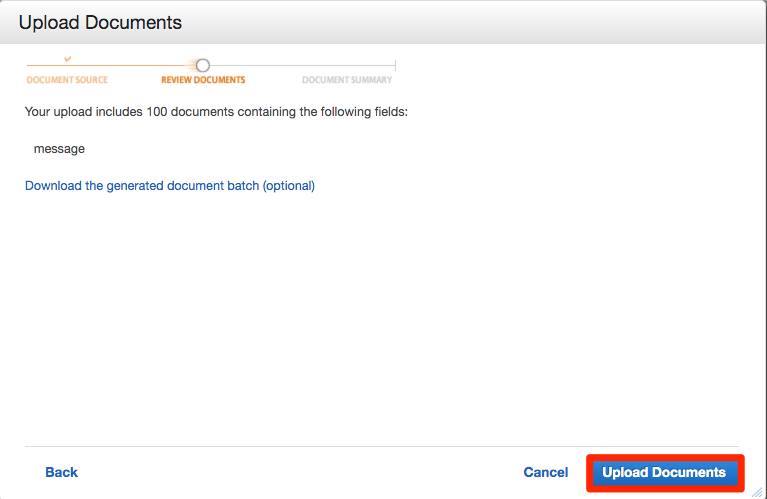
最後にFinishを押します。
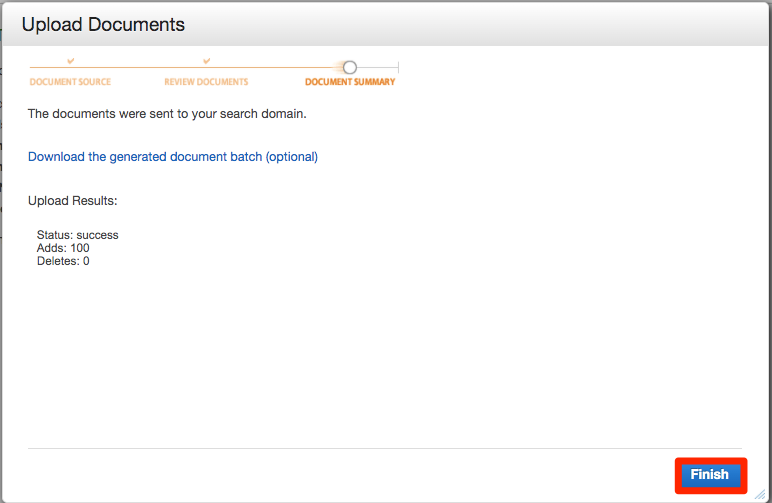
これでデータのアップロードは完了です!
検索してみる
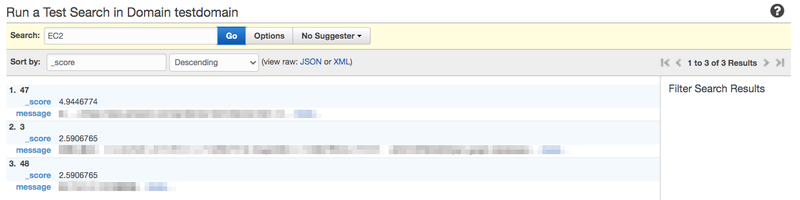
データをアップロードしたらRun a test searchというのが表示されていると思います。 そこにキーワードを入力してGoを押すと検索ができます。
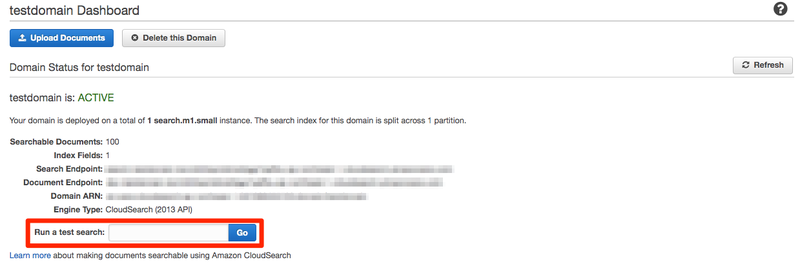
こんな感じで検索ができます!
まとめ
今回はAmazon CloudSearchにSlackのメッセージを格納してそれを検索してみました。 ここから色々できそうなので試してみようかと思います。 また、何かできましたらブログに書くかもしれません。
以上、濱岡でした!