

こんにちは。技術2課の加藤ゆです。
この年末年始でアレルギー性○○系に2種なりました...人生で1番薬を飲んでいるこの頃です。
2024年は無事息災を掲げて過ごそうと思います!
さて、今回ははじめてCloudSearchを触ったので、簡単に記録しようと思います。
Amazon CloudSearchとは
AWSの完全マネージド型のカスタム検索サービスです。
Webサイトやアプリケーションに検索機能を実装することが可能な、サイト内検索アプリケーション向けのサービスとなります。
検索ソリューションとは、テキストで構成された大きなデータ項目(ドキュメント)を検索し、一致する結果を見つけることが可能なサービスです。
この機能を、ウェブサイト・アプリケーション向けに、AWSフルマネージドで提供しているサービスが「Amazon CloudSearch」になります。
ちなみにCloudSearchは、基盤となるテキスト検索エンジンにApache Solr を使用しています。
Webサイト内の情報を探すための機能が備わったものだとザックリ理解しました。
※Amazon CloudSearchは、2015年以降サービスアップデートが無いサービスです(2024年1月時点)
https://aws.amazon.com/jp/cloudsearch/whats-new/
サービス選定される際には、最新情報をご確認の上検討ください。
用語
構成要素の用語をまとめます。
| 要素 | 説明 |
|---|---|
| 検索ドメイン | ・データコンテナと、データを検索可能にするサービス(ドキュメントサービス/ 検索サービス/ ドメインの動作コントロール )のセット ・データ検索のための、機能と検索データが合わさったコンテナのようなもの ・1つの検索ドメインあたり、1 つ以上の検索インスタンスを持つ |
| 検索インスタンス | ・単一の検索エンジン。実態はRAMとCPUを備えたインスタンス。 ・ドキュメントのインデックスを作成し、検索リクエストに応答する役割 |
| 検索エンドポイント | ・検索リクエスト(HTTP/HTTPS の GET リクエスト)に応答するエンドポイント。検索ドメイン毎に個別で存在する。 |
「検索エンドポイント」に送信する検索リクエストは、オプションを指定することによって、検索の制約・ファセット情報のリクエスト・ランク付けの制御・結果で返される内容の指定等を行うことができます。
検索の際には、「検索インスタンス」にて作成したインデックスに対してクエリを送信し、特定の検索条件を満たすドキュメントを見つけます。
これらの検索に必要なデータや機能をまるっと抱えているのが、一番初めに作成する「検索ドメイン」です。
利用料金
検索インスタンスの使用に応じて利用料金がかかります (データ保存先のS3の料金はかかりません)
| 課金対象 | 説明 | サンプル ※詳細はドキュメント参照 |
|---|---|---|
| 検索インスタンス | インスタンスが開始~終了するまでの、検索インスタンスごとに消費される時間当たりの料金 (1 時間未満の利用は、1時間として請求) |
[search.m1.small] を利用する場合、$0.082 /1 時間 |
| ドキュメントバッチのアップロード | 検索ドメインにアップロードされたドキュメントバッチの合計数に対して請求 | 0.10 USD/1,000 件のアップロード ( 各バッチの最大サイズは 5 MB) |
| IndexDocuments リクエスト | インデックス再構築時に利用するAPIリクエスト | 0.98 USD/GB |
| データ転送(アウト) | Amazon CloudSearch に「送信(アウト)」されるデータ転送量 | 最初の10TB/月につき、 $0.14/1GB |
設定項目でいうと、「インスタンスタイプ」と「レプリケーション数」がドメインの実行コストに影響するので注意しましょう。
無料トライアル
はじめてCloudSearch を利用する場合は、30日間の無料トライアルを利用可能です。
※ただしOrganization組織をご利用頂いている場合、無料利用枠は親アカウントと子アカウント全てで共有利用となります。
親子関係がある場合、他アカウントで指定枠が利用済みであれば無料枠対象にはなりません。
触ってみる
Amazon CloudSearchのマネジメントコンソールは懐かしい感じのUIですね.
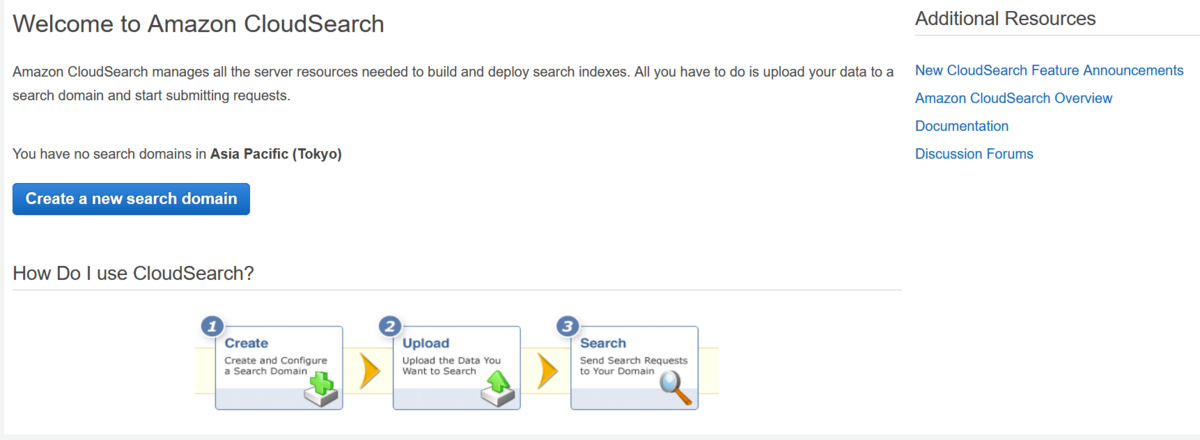
では、データ検索が出来るように設定していきます
1. 検索ドメインの作成・設定
Amazon CloudSearch でのスケーリングオプションの設定 - Amazon CloudSearch
検索可能にするデータの各コレクションについて、個別の検索ドメインを作成する必要があります。
CloudSearchは、検索データが多かったり検索リクエストが大量である場合に、検索インスタンスを柔軟にスケールアップおよびスケールダウンします。
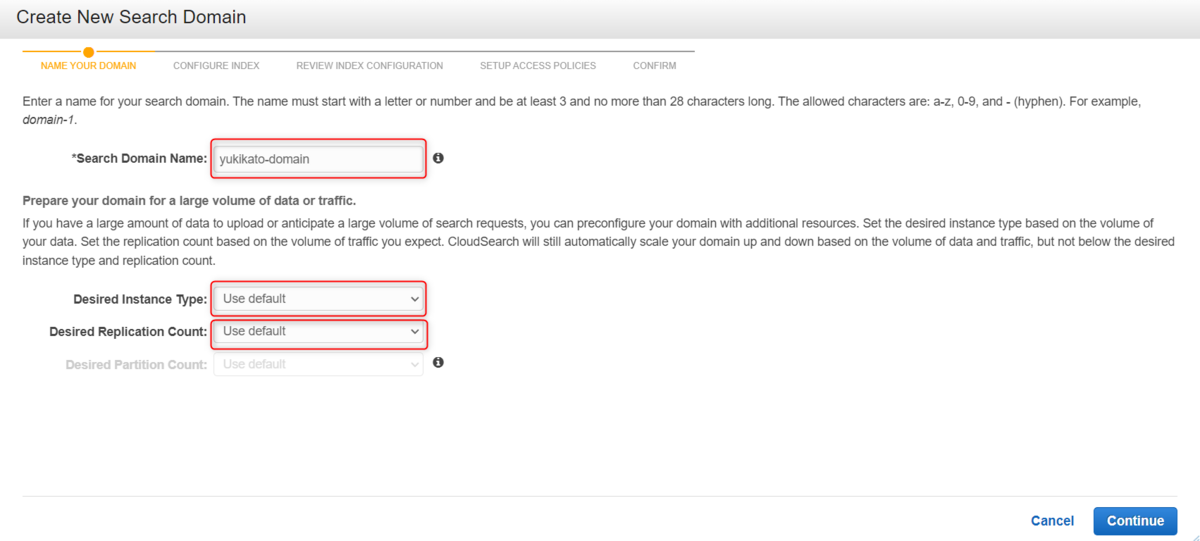
検索インスタンスは自動スケールされますが、ここで指定したインスタンス タイプとレプリケーション数を下回ることはありません。
| 項目 | 説明 | 設定値 |
|---|---|---|
| 検索ドメイン名 | データを検索する際に利用します | yukikato-domain |
| Desired Instance Type (必要なインスタンスのタイプ) |
検索インスタンスのインスタンスタイプ アップロード容量・検索リクエストのスピードに関係する項目 ※作成後、変更可能 |
User default (=search.small) |
| Desired Replication Count (必要なレプリケーション数) |
ドメインの検索容量に関係する項目 アップロード容量には影響ない ※作成後、変更可能 |
User default (=0) |
| Desired Partition Count (必要なパーティション数) |
検索リクエストのスピードに関係する項目 ※Instance Type が search.2xlarge の場合のみ選択可能な設定 ※作成後、変更可能 |
User default |
検索ドメインには、数字[ 0-9 ], 英小文字[ a-z ], ハイフン[ - ]のみOKです。
DNSのドメイン的な気持ちで、ドッド[ . ]を使いたくもなりますが利用できないので、ご注意ください。
ちなみに、インスタンスタイプの選択について、公式では以下のようにコメントされています。
データが 1 GB 未満や 100 万個未満の 1 KB ドキュメントのデータセットの場合は、小さな検索インスタンスで十分です。
1 GB~8 GB のデータセットをアップロードするには、アップロードを開始する前に、目的のインスタンスタイプを search.large に設定することをお勧めします。
8 GB~16 GB のデータセットについては、search.xlarge で開始します。
16 GB~32 GB のデータセットについては、search.2xlarge で開始します。
32 GB を超えるアップロードの場合は、search.2xlarge インスタンスタイプを選択し、データセットに合わせて必要なパーティション数を増やします。 https://docs.aws.amazon.com/ja_jp/cloudsearch/latest/developerguide/configuring-scaling-options.html#choosing-scaling-options
2. 検索するデータのアップロードして、インデックスを作成する
CloudSearch側で、アップロードしたファイルから共通のインデックスフィールドを自動で設定する事が出来ます。
Amazon CloudSearch ドメインのインデックスフィールドの設定 - Amazon CloudSearch
ただし、CloudSearch によってインデックスを作成するためには、データが JSON 形式または XML 形式である必要があります。
インデックスの構成
今回はデモ用にCloudSearch側に用意されているデモデータを使おうを思います。
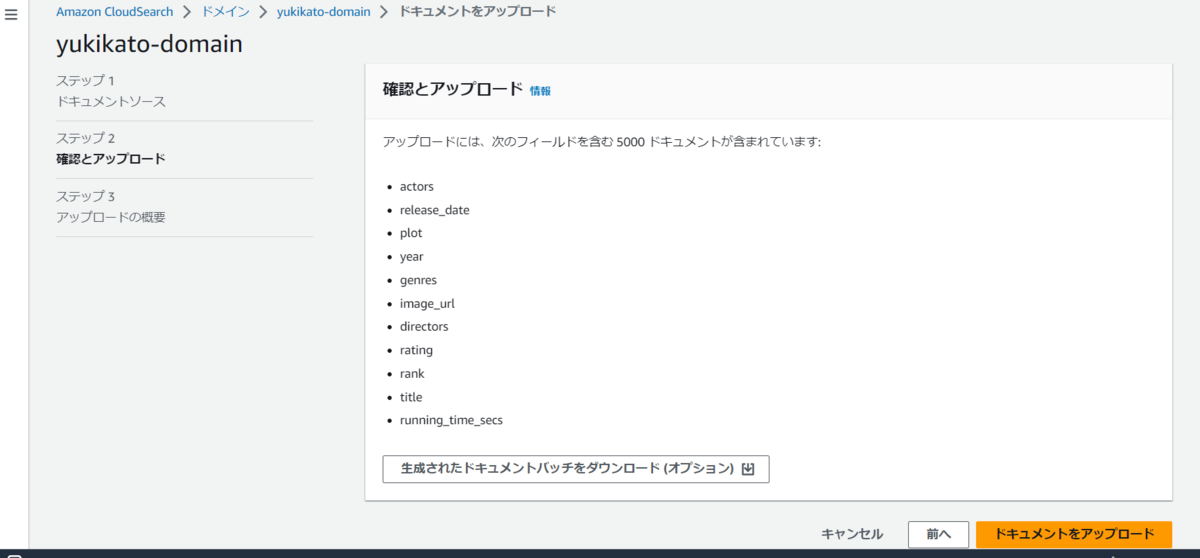
このデモデータは5,000 本の人気映画タイトルのサンプルデータセットだそうです。
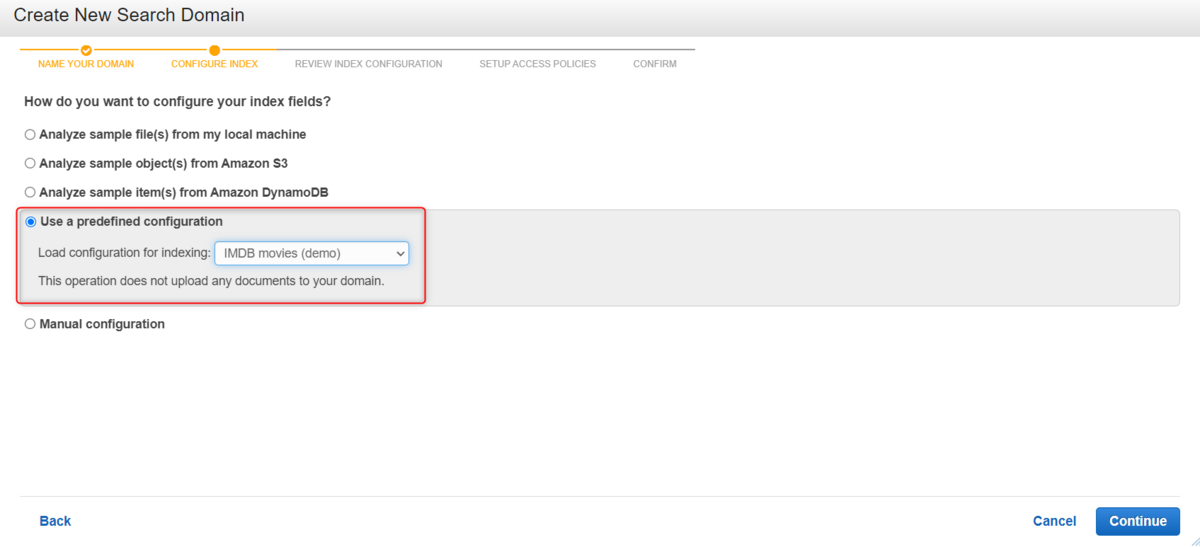
インデックス構成の確認
このように、CloudSearch側で推奨されるインデックス構成を提示されます。
今回のサンプルimdb-movie データでは、
11 個のフィールド (actors、directors、genres、image_url、plot、rank、rating、release_date、running_time_secs、title、year ) が自動的に設定されていますね。
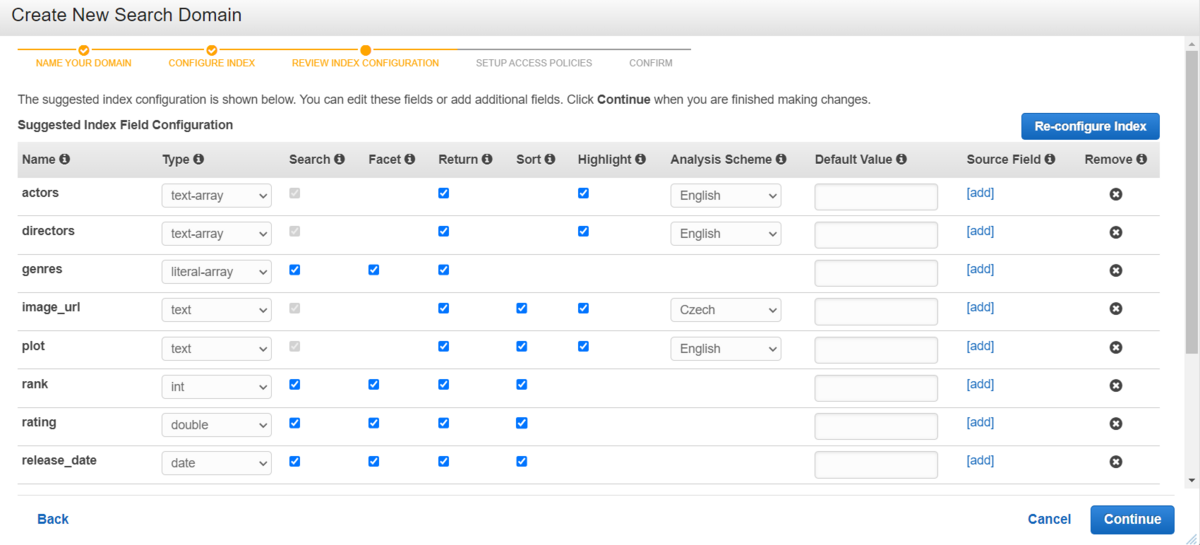
このインデックスを設定することで、タイトルで検索・名前で検索・日時で検索といった検索ができます。DBでのカラムみたいなものかと思います。
この時点で推奨されているインデックスに間違いがあれば変更しましょう。
アクセスポリシーのセットアップ
Amazon CloudSearch のアクセスの設定 - Amazon CloudSearch
CloudSearchサービスエンドポイントにアタッチする、ポリシー設定をします。
CloudSearch 設定サービスや各検索ドメインのドキュメント、検索、提案サービスへのアクセスを制御が可能です。(ここでの設定はIAMが使われます)
検索機能の利用者を制限する設定になります。
たとえば、以下のようにドメイン毎にアクセス制御が可能です
- 本番ドメインの設定変更許可はユーザーAのみに与える
- テスト用独自ドメインを作成・変更管理許可をユーザーA/ユーザーB/ユーザーCに与える
- エンドポイントにアクセス可能なIPアドレス範囲を限定する
Amazon CloudSearch のアクセスの設定 - Amazon CloudSearch
一旦、私のIAMユーザからのすべてのcloudsearchアクションを許可する設定をいれました。
検索サービスを利用する対象(APIGW, EC2, アクセス元IPアドレス 等)があればそちらで絞ると良いと思います。
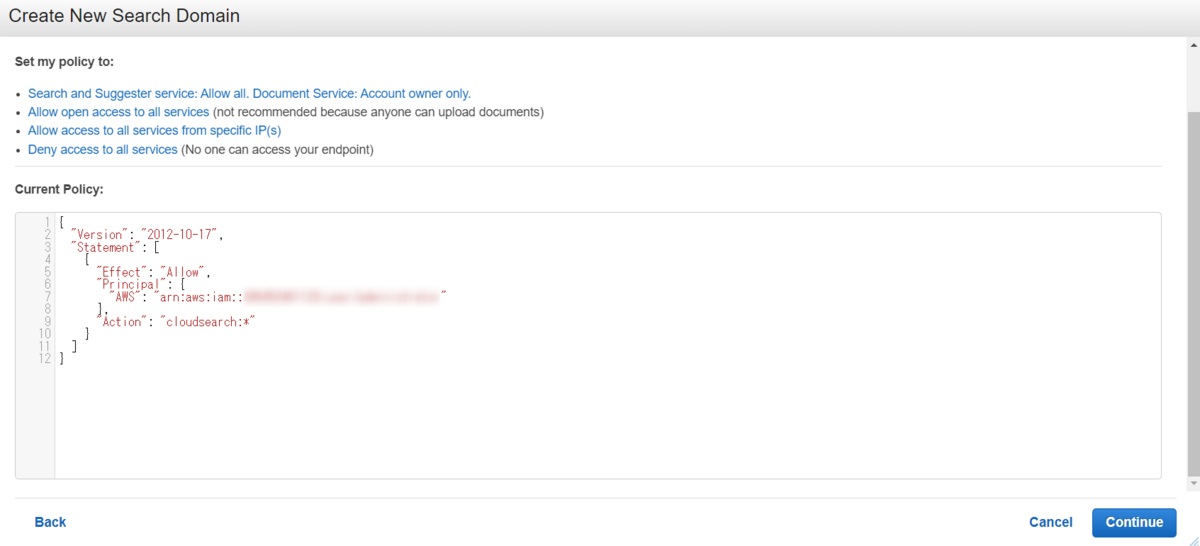
初期設定完了
設定内容確認後、作成します。
(作成までに10分ほどかかります)
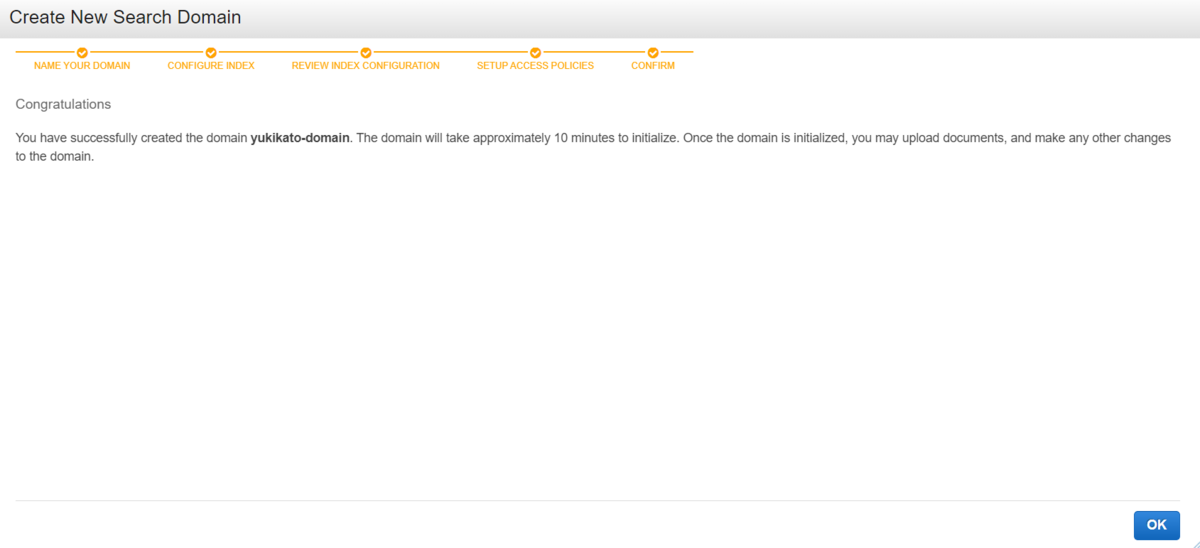
作成完了画面
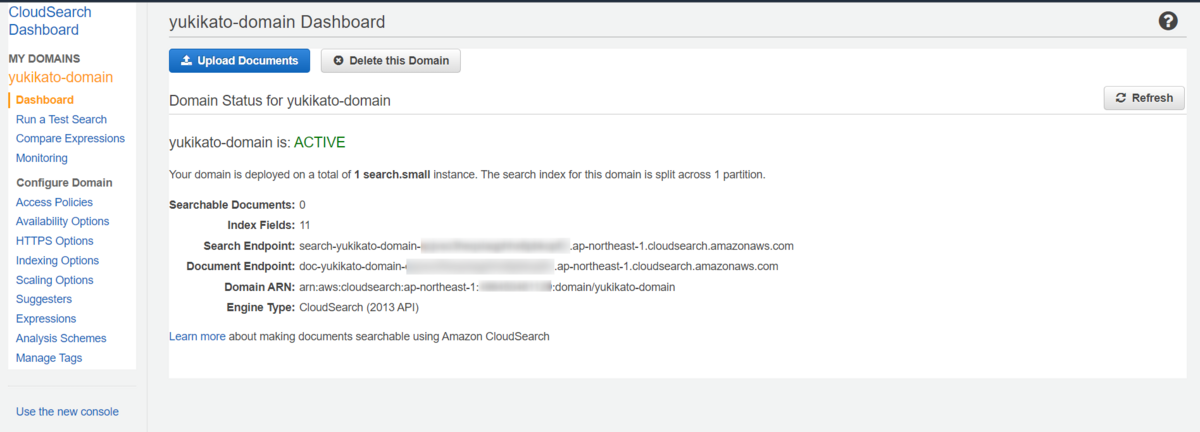
検索ドメインの設定は、以下の通りです。
[cloudshell-user@ip-10-132-78-113 ~]$ aws cloudsearch describe-scaling-parameters --domain-name yukikato-domain
{
"ScalingParameters": {
"Options": {
"DesiredReplicationCount": 0,
"DesiredPartitionCount": 0
},
"Status": {
"CreationDate": "2024-01-16T06:18:15.639000+00:00",
"UpdateDate": "2024-01-16T06:18:15.639000+00:00",
"UpdateVersion": 15,
"State": "Active",
"PendingDeletion": false
}
}
}
[cloudshell-user@ip-10-132-78-113 ~]$
新しいコンソール画面
ドメイン作成後に、新しいコンソール画面を確認出来たのでこちらも載せておきます。
初回はドメインを作成しないと新しいコンソールに切り替えが出来ないようです。
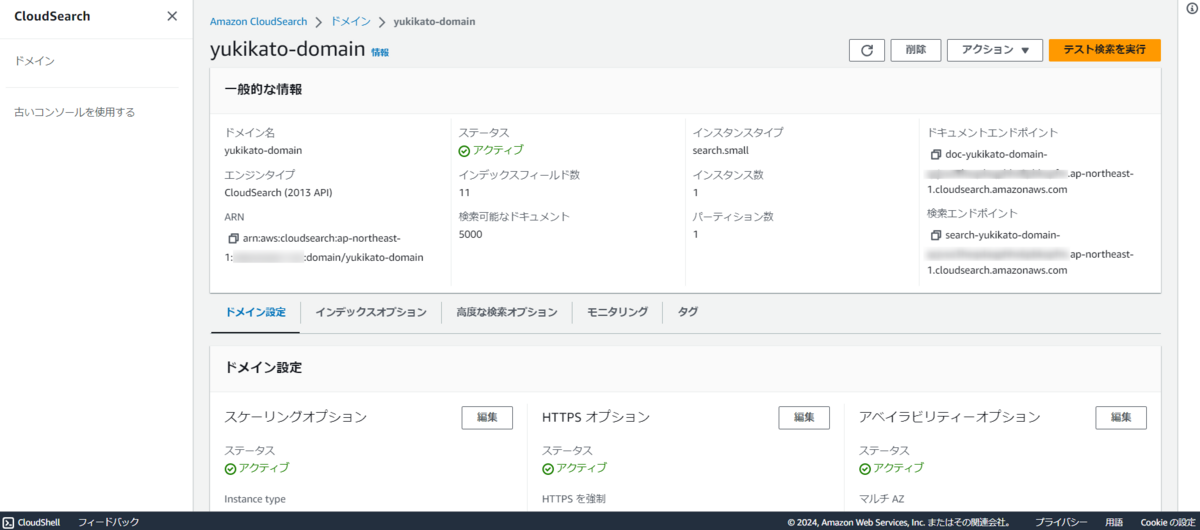
3. ドメインに検索リクエストを送信する
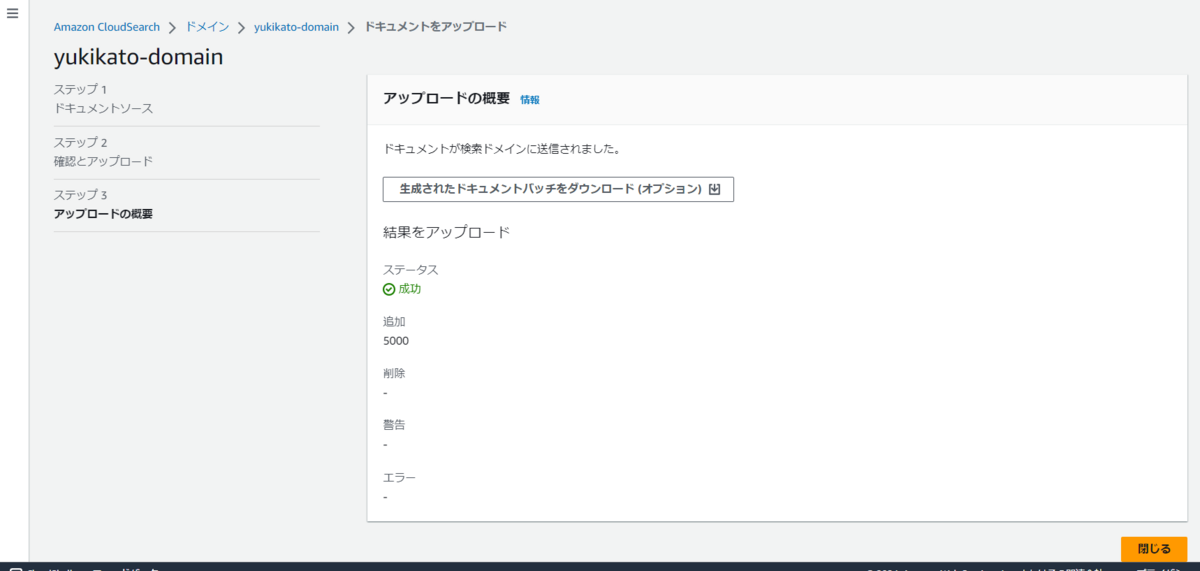
今の状態では、検索対象のドキュメント(Searchable Documents)が 0 なので、ドキュメントをアップロードします。
今回の検索ソースは、サンプルデータ(IMDb movies(demo))です。
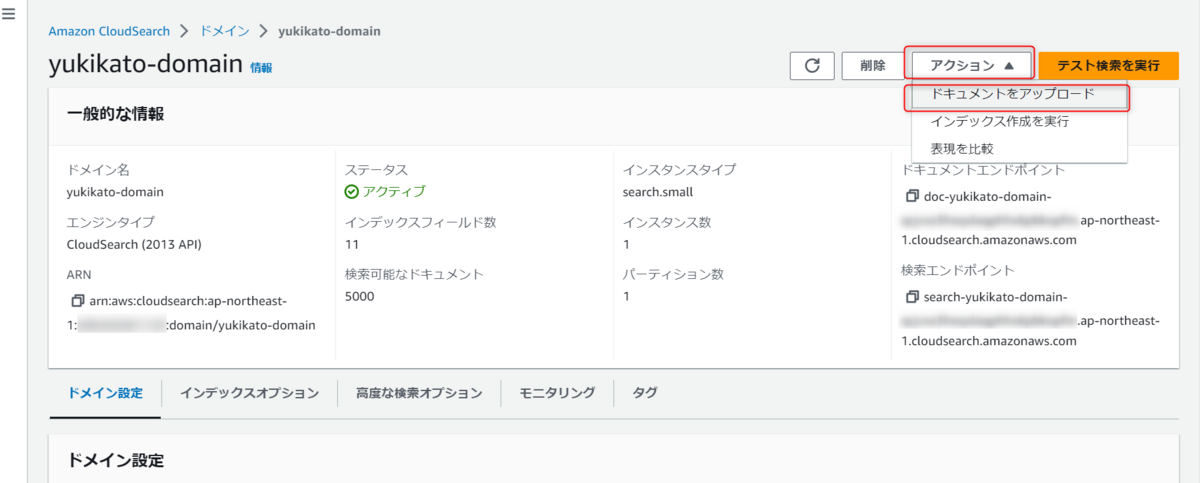
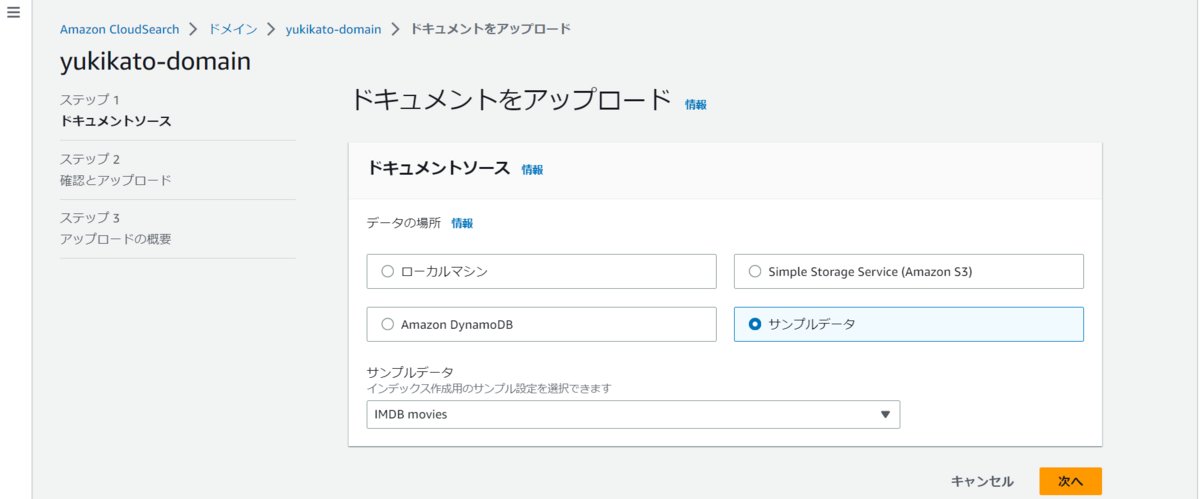
↑ 今回はサンプルデータをアップロードしましたが、表示の通り3種からアップロード可能です。
- ローカルマシン
- S3
- DynamoDB
ドメインを検索する
適当に「Nelson」をクエリに入れてみます。
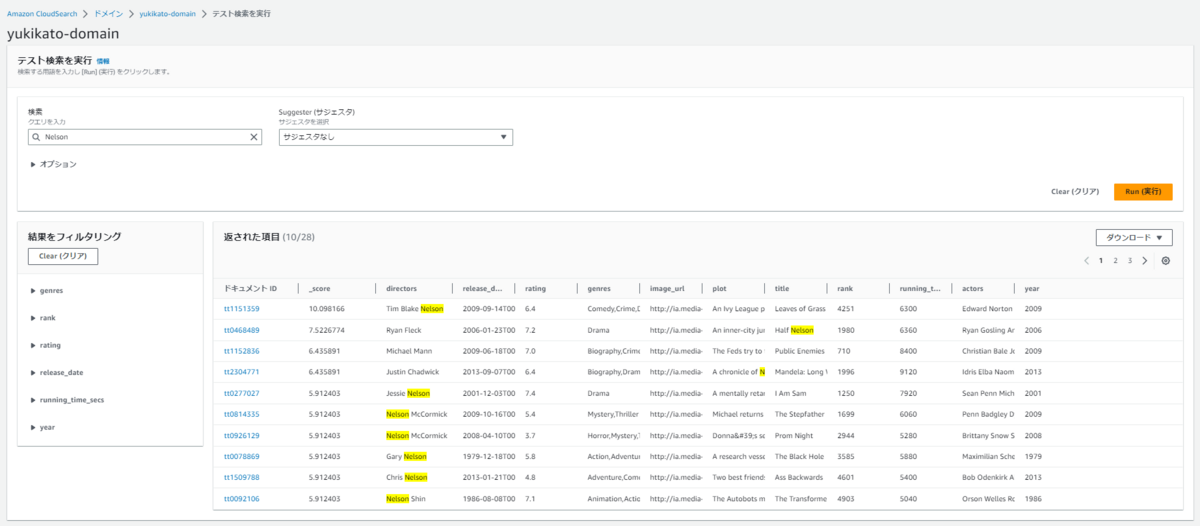
なんだかAthenaっぽい画面ですね。
先程設定したインデックスに合わせて、検索のフィルタリングが可能です。
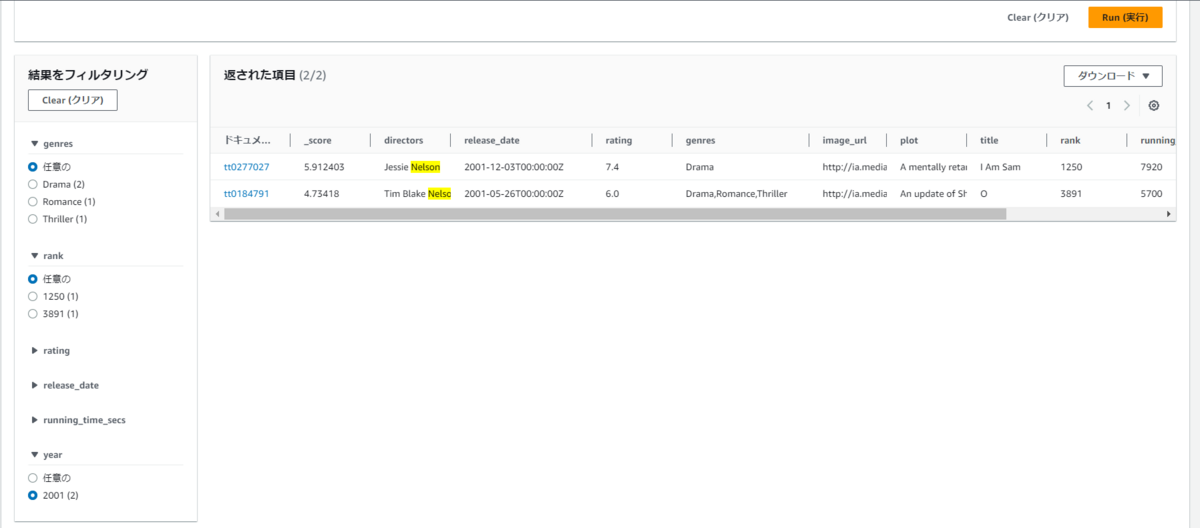
作成した検索エンドポイントを叩いて、クエリを元に検索機能を使う事が可能です。
クエリの詳細はドキュメントを参照下さい。
その他
HTTPSオプションの利用
ドメインへのすべてのトラフィックが HTTPS 経由でアクセスするよう指定可能です。
Amazon CloudSearch でのドメインエンドポイントオプションの設定 - Amazon CloudSearch
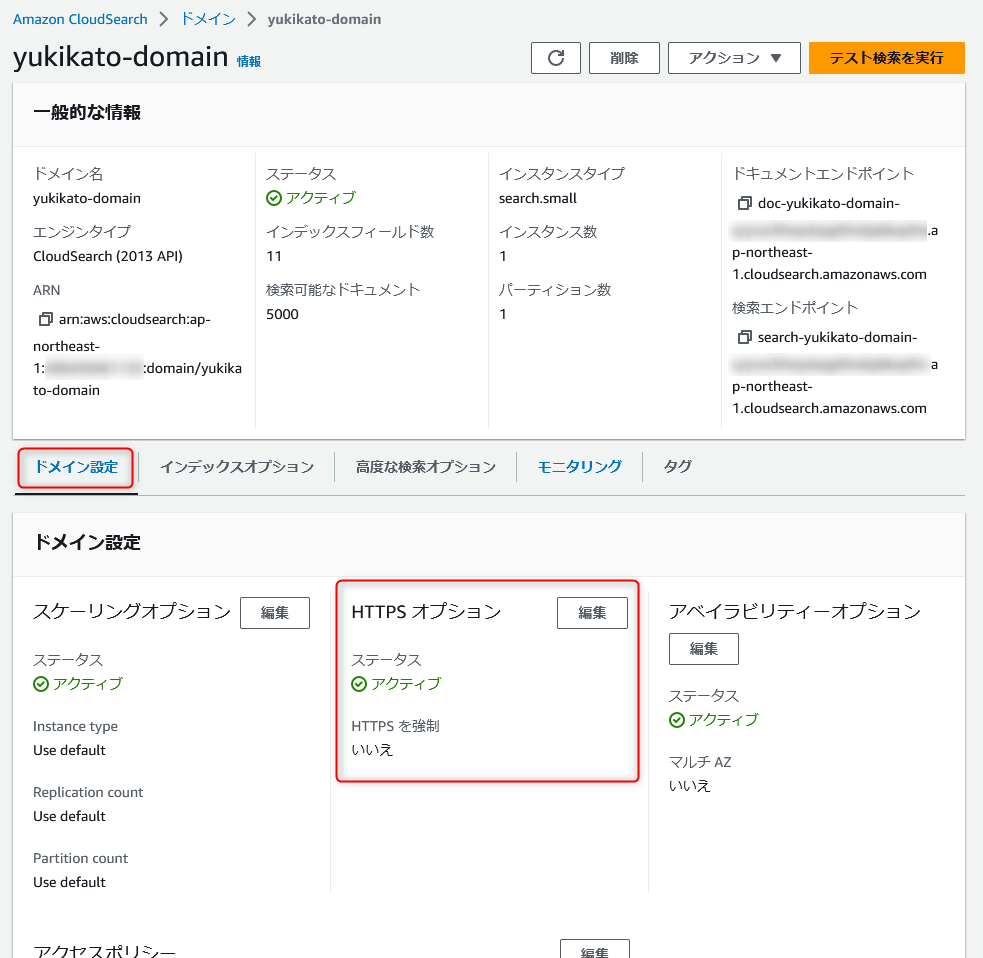
HTTPS オプションを利用することで、暗号化されていないリクエストでドメインに送信された場合はブロックされます。
設定オプションを変更する場合
検索ドメインの設定オプションを変更する場合、インデックスの再作成が必要になるものもあれば、既存のインデックスの再デプロイのみで済むものもあります。
よくある質問 - Amazon CloudSearch | AWS
FAQにまとまった図があったので、参考までに載せておきます。
ドキュメント記載の通り、更新には一定の時間が必要となるので計画的に更新いただくのが良いでしょう。
ドメインに少数のドキュメントしか含まれていない場合でも、インデックスの構築とその配置に必要な処理やプロビジョニングのために、インデックスの再作成にはこれだけの時間がかかります。
そのため、設定変更を事前に計画し、すべての変更を一度に行ってから、ドメインのインデックスの再作成を行ってください。
| 設定オプション | インデックスの再作成が必要 (30-60min) |
再デプロイが必要 (10-15min) |
|---|---|---|
| マルチ AZ | 無 | 有 |
| インデックスフィールド | 有 | 有 |
| インデックスフィールドオプション | 有 | 有 |
| インスタンスタイプ | 有 | 有 |
| パーティション数 | 有 | 有 |
| レプリケーション数 | 無 | 有 |
| サジェスタ | 有 | 有 |
| 式 | 無 | 有 |
| 分析スキーム | 有 | 有 |
おわり
あまり触れる機会が無いサービスなので、この機会に書いてみました。
どなたかのお役に立てれば幸いです!
最後までご覧いただきありがとうございました ;)