

はじめに
こんにちは、技術3課の紅林です。今回は、Cloud Automatorを使って、Slackの全チャンネルの1日分のメッセージの取得を自動化する試みを紹介したいと思います。
やりたいことと課題
1日に1回、Slackの全チャンネルの過去1日分のメッセージの取得し、その情報を使うことで、例えば、毎日の社内の活動の分析や可視化に利用できます。
もちろん、EC2インスタンスを立てておき、Cronでメッセージを取得するスクリプトを実行すれば可能ではあるのですが、そのインスタンスが実質使用されるのは、1日1回のスクリプトの実行時のみであるため、スクリプト実行時以外のインスタンスの稼働時間が無駄になってしまいます。
そこで、Cloud Automatorを使うことで、コストを最小限に抑えつつ、メッセージの取得を試みます。
さばわのSlackについて
弊社のSlackの現在のチャンネル数(アーカイブ済を除く)は、1049です。
その他、Slackの活用術等は以下の資料等でも言及しておりますので、参照頂けたらと思います。
クラウドインテグレータのChatOpsな取り組み
構成/処理の流れ
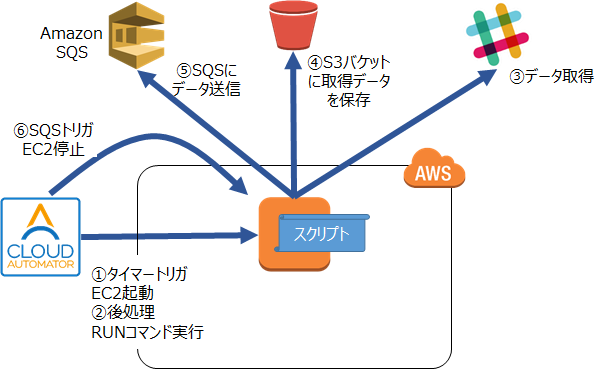
構成/処理の流れとしては、以下のような形となります。
①Cloud Automatorのタイマートリガで決められた時間にEC2インスタンスを起動します。
②「①」の後処理でRUN COMMANDを実行し、Slackのデータを取得するスクリプトを実行します。
③データを取得します。
④取得したデータをS3にアップロードします。
⑤SQSにメッセージを送信します。
⑥Cloud AutomatorのSQSトリガでEC2インスタンスを停止します。
Run Commandアクションや、それとEC2の起動アクションとの組み合わせについては以下の記事でも言及されておりますので、適宜参照ください。
Cloud Automator | EC2インスタンスでコマンドを実行するアクションを正式リリースしました!
実装
全チャンネルの1日分のメッセージの取得について
Slackの全チャンネルの1日分のメッセージの取得を行うため、Slack APIを利用します。
具体的な流れとしては、
1. channels.list APIを利用し、Slackの全チャンネル(アーカイブ済を除く)情報を取得します
2. channels.history APIを利用し、チャンネルごとの1日分のメッセージを取得します
実装例
例えば、1.については以下のようなコードとなります(一部抜粋、Python、python-slackclientを利用)。
from slackclient import SlackClient
slack_token = "xxxxxx"
sc = SlackClient(slack_token)
# 結果は辞書型で格納される
channels_list_dist = sc.api_call(
"channels.list",
exclude_archived=1
)
2.については以下のようなコードとなります(一部抜粋)。
全力でリクエストを送ると、レートリミットによく引っかかってしまうため、1秒に1リクエストを送信する形としています。厳密に実装するなら、エラー時のリトライ処理等を入れるとよいと思います。
試しにローカルで実行したところ、1.の処理と合わせて1049全チャンネル分のデータ取得が完了するまでに1500秒前後要しました。
from datetime import datetime, timedelta
channels_list = channels_list_dist["channels"]
now = datetime.now()
before1day = now - timedelta(days=+1)
before1day_unixime = n.timestamp()
for channel in channel_list:
sleep(1)
channels_history = sc.api_call(
"channels.history",
channel=channel_id,
count=1000,
oldest=before1day_unixime
)
S3バケットへの取得データ保存
取得したデータはファイルにしてS3にアップロードします。
今回はチャンネルごとの欲しい情報を格納するPythonのオブジェクトを用意し、そのオブジェクトのリスト(以下コード中のchannel_obj_list)をシリアライズしてファイル化してみました。
シリアライズするライブラリにpickle、S3へのアップロードにboto3を用いますので、インストールしておきます。
実装例(一部抜粋)
import pickle
import boto3
# シリアライズ
with open("channel_obj_list.pickle", 'wb') as f:
pickle.dump(channel_obj_list, f)
# S3にアップロード
s3_client = boto3.client('s3')
s3_client.upload_file('channel_obj_List.pickle', '[bucket-name]', 'channel_obj_List.pickle')
SQSにデータ送信
S3にアップロード後、Cloud AutomatorのSQSトリガーによりインスタンスを停止するため、SQSにデータを送信します。
実装例
sqs = boto3.resource('sqs')
queue = sqs.get_queue_by_name(QueueName='[QueueName]')
queue.send_message(MessageBody='test')
設定手順概要
以下に設定の流れを記載します。特に変わった手順は無いため、個別の詳細手順は割愛します。
1. スクリプト実行環境の構築
- EC2インスタンスの作成(必要なIAMロール権限を付与)
- スクリプトの配置
- SSMエージェントのインストール
等、Run Command経由でスクリプトが実行できる環境を構築します。
2. AWSリソースの作成
- 取得データ保存用S3バケット
- Cloud Automator連携用Amazon SQS
を作成します。
3. Cloud Automatorの設定
3.1 タイマートリガ(EC2起動)設定
Cloud Automatorのタイマートリガを設定し、スクリプトを実行したい時刻やスクリプトを仕込んだインスタンスを指定します。設定手順は以下のリンク等を参照ください。
Cloud Automator | Cloud Automatorのジョブ作成方法
3.2 後処理(Run Command実行)設定
Cloud Automatorの後処理機能で、インスタンス起動した後に、スクリプトを実行するRun Commandを設定します。設定手順は以下のリンク等を参照ください。
Cloud Automator | SQS後処理の使い方チュートリアル
3.3 SQSトリガ(EC2停止)設定
Cloud AutomatorのSQSトリガを設定し、インスタンスを停止するジョブを作成します。設定手順は以下のリンク等を参照ください。
Cloud Automator | SQSトリガーを使う最初の一歩
実行
さて、設定が完了したら、実際にテストしてみましょう。といっても、3.1で設定していれば、Cloud Automatorで指定の時間が来た時に実行されるのを待つだけです。 正常に実行完了していましたら、 - S3バケットに取得データが格納されている - EC2インスタンスは停止されている - Run Commandが実行され、正常終了されている - Cloud Automatorの各ジョブが正常終了している 等を確認しましょう。 また、取得したデータはS3からダウンロードし、Pythonでデシリアライズすることで、プログラムの中で再度データを利用可能となります。
終わりに
今回、Cloud Automatorを使って、Slackの全チャンネルの1日分のメッセージの取得を自動化する試みを紹介しました。次回は、AWSの別のサービスを利用して、同様の機能を実現する方法をご紹介したいと思います。