

こちらでははじめまして。最近サーバーワークスにJoinした三井です。
さっそくですが、先日行われたAWS Casual Talks#2なるイベントに潜入してきました。 これは個人的な話ですが、実のところ「まだAWS掘り下げ始めて日が浅いし、とりあえずコミュニティの雰囲気やどんな使われ方してるのか、ふわっと聞いて帰ろうかな」程度にゆるく考えていました。が、どうやら一緒に参加したサーバーワークスのメンバーには見透かされていたようで「報告ブログはまかせた!」と突然メッセージが届きまして、そういうわけでガチな人たちのカジュアルなお話をガチで聞いてきました!
さっそくですが、先日行われたAWS Casual Talks#2なるイベントに潜入してきました。 これは個人的な話ですが、実のところ「まだAWS掘り下げ始めて日が浅いし、とりあえずコミュニティの雰囲気やどんな使われ方してるのか、ふわっと聞いて帰ろうかな」程度にゆるく考えていました。が、どうやら一緒に参加したサーバーワークスのメンバーには見透かされていたようで「報告ブログはまかせた!」と突然メッセージが届きまして、そういうわけでガチな人たちのカジュアルなお話をガチで聞いてきました!
AWS Casual Talksとは
ひとくちに言ってしまえばAWSをガチで使い込んでいる人たちがカジュアルな話(つまるところ"ガチな話”)をするコミュニティイベントです。 AWS Casual Talks#2 on Zusaar タイトルの通りまだ2回目のイベントですが、参加申し込み受付開始から数十分で満席になるぐらいの盛況っぷりです。私は運良く補欠から繰り上がることができました!当日の様子はTogetterにもまとめられております!
2014/04/18 AWS Casual Talks #2 #awscasual - Togetterまとめこれは余談ですが、実はAmazon様のオフィスを訪問するのが今回が始めてでして、フロアに到着してまず目に飛び込んできたお洒落なエレベータのデザインにさっそく胸が高鳴ってしまいました。

メインセッション
- CloudTrailでログとれ〜る
- Data Stream Processing and Analysis on AWS: Fluentd, Elasticsearch, DynamoDB, EMR and Amazon Kinesis
- ふつうのRedshiftパフォーマンスチューニング
- AWS使用がもっと楽になるネットワーク系の新サービス at VPC,ELB,CloudFront,Route53
LT
「CroudTrailでログとれーる」@kani_bさん
CloudTrailでAWSの色んな操作ログが取れるよ!
- だいたい15分毎ぐらいにAPIの操作ログを出力してくれる
- ログはS3に出力され、さらにログ出力のお知らせをSNSに投げることも可能
- ログは他アカウントのバケットに出力することもできる
- 形式はおなじみのJSONで、どのオブジェクトに対してどのユーザエージェントからどんな操作が行われたかなど、いろいろデータ入っててお得
- 操作に失敗した記録も残る!監査的に重要なポイント
AWS側では出力されたログに関して手を加える手段を提供していない
- 勝手にパースしてよしなに扱うのが基本( MongoDBやElasticsearchに突っ込むなど)
- 解析サービス使うのもあり(SumoLogic Splunk, Stackdriver, logglyなど)
まだ太平洋は超えられていない。(us-west-1, us-west-2のみでの提供)
- Tokyoリージョンではまだ使えない。 IAM, STSのようにリージョン関係ないものは使えるよ!
GAME DAY で実践してみた
- (GAME DAY ... AWSで構築されたシステムを美しく破壊するチーム、破壊されたシステムを修復するチームに分かれて行うイベント)
- 2014年度のGAME DAYで使用されたリージョンはus-east! CloudTrail使える!
- しかし相手に渡すアカウントはPower User、やっぱり相手にCloudTrailを切られてしまったらしい……
- が、CloudTrailが切られるまでのログ(EC2インスタンスがTerminateされる様子)などは記録されていた
- 現状だと、IAMのPower UserのテンプレートにCloudTrailに関する全てのアクションが許可されている
- GAME DAYの教訓より、Power UserのテンプレートからCloudTrailの権限は外したほうがいいのではと考えている
- ログ集約用アカウントを作るなど、ログの保持方法はまとめた方が良い
- IAMの権限には注意
その他
- CloudTrailを使ってIAMのPolicyの更新を追跡できる点に着目
- ログをパースしてPolicyをGitに登録してバージョニングできるツール”iwas”を作った(IAMにかけて「I was…」という、非常にうまい名称ですね…!)
- kanny/iwas · GitHub
「Data Stream Processing and Analysis on AWS: Fluentd, Elasticsearch, DynamoDB, EMR and Amazon Kinesis」 @suzu_v さん
ログ解析基盤のアーキテクチャとしてAmazon Kinesisの検証を実施しているお話(こんなことタダで聞いちゃっていいの!?と思ってしまうほど情報量の多いスライドですので、こちらはメモを見て頂くより実際にスライドをご覧になって頂いた方が分かり良いかもしれません。) Kinesisの紹介- Kinesisはデータストリームを受け取る基盤部分、受け取ったデータをKinesisアプリケーションに渡すのが仕事
- Partition Keyを設定し、そのキーによって処理を行うworkerが選択される リアルタイムなログ集計や、相関などの分析が行える
- 広告ログの分析基盤
- アドホックな分析&定常的な分析、ターゲッティングにも使う
- 複数サービスのログをひたすら取り込む
- 過去ログもひたすら取り込み、快適に分析できるようにする
- ターゲティングはベストエフォート
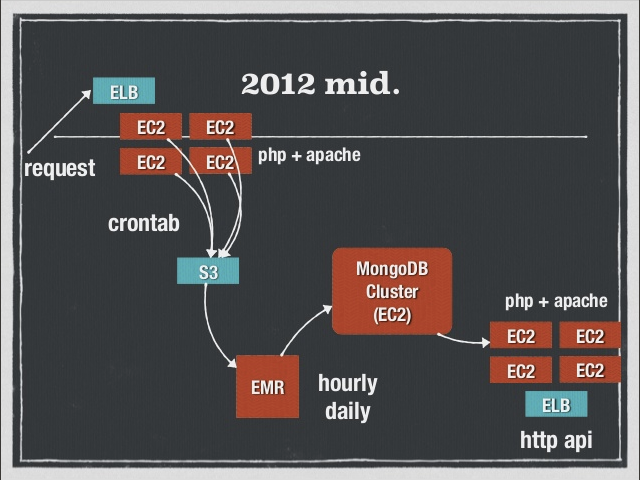
- EC2からS3にログを集積し、EMRで処理してEC2で構成したMongoDBクラスタに流していた
- リアルタイムじゃない
- DBのwrite負荷が高い
- 集計処理が重い
- MapReduceジョブを回さないと分析ができない
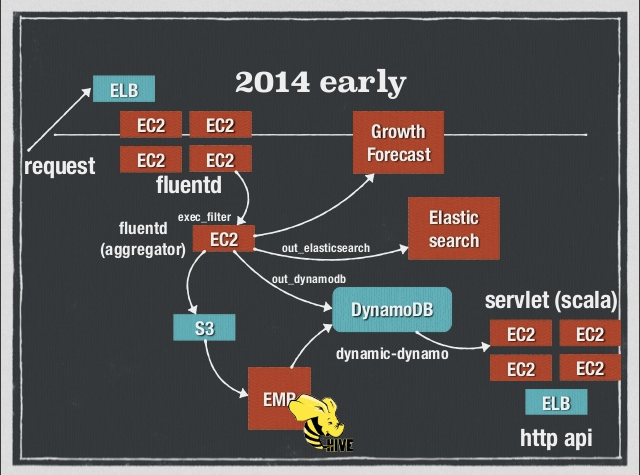
- Fluentdで各サーバのログをアグリゲータに集約し、DynamoDBやElasticsearchに流している
- EMRからも書く
- Fluentd便利すぎる
 使用感
使用感 

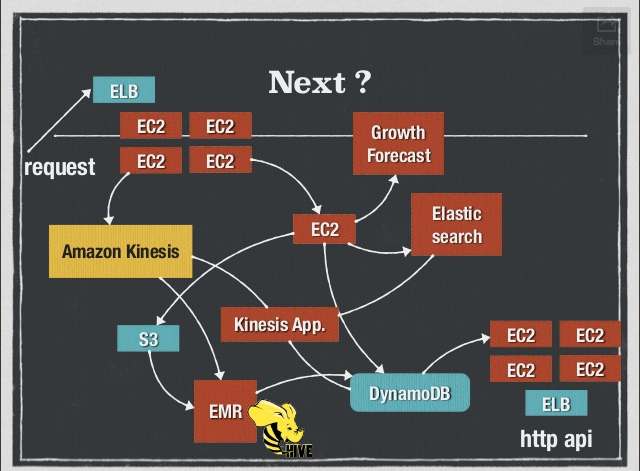
 Kinesisこうなったらいいな
Kinesisこうなったらいいな
- Kinesisのメトリクスも1minごとに見たい
- DynamoDBみたいにbatchWriteがほしい
- Tokyoリージョンにも来て欲しい
「ふつうのRedshiftパフォーマンスチューニング」@mineroaokiさん
そもそもRedshiftとは- 並列RDBMS - SQLが使えます。KVSでもHadoopでもありません
- leader-nodeの配下にcompute-nodeが存在する。各compute-nodeの中に少なくとも2 Sliceある
- Insert時の保存先は分散キーのハッシュ値で決定される
- トランザクションデータ(10億行とか100億行とか余裕で扱える)とマスタデータが格納されていく
- この2種類のデータをBIツールやバッチ処理などで分析する
- オンライン(OLTP)マイクロ秒、更新あり
- Redshiftでは無理です
- リクエストの並列度が高いと無理、Webサイトのように秒間2桁以上のリクエストがくるような用途はやめた方がいい
- 高頻度、細粒度で更新するのは無理、せいぜい5分間隔の追加ぐらいがギリギリ
- オンライン(OLAP / Tactical Query) 0.1秒〜数秒ぐらい
- sortkeyに当てろ(予め行をソートしておくことで範囲を狭めるしかない)
- テーブルサイズを実測して一番小さくしろ(テーブルごとに圧縮、エンコード)
- 事前ジョインはあんまり効かない、集計はOK(先にジョインするとデータが大きくなる可能性も)
- オンライン(OLAP / strategic)数秒〜数分ぐらい / バッチ 数分〜数時間
- 全行SelectしてRedshiftの外で非並列処理とか絶対にやっちゃいけない(問題外の頻出パターン)
- 並列RDBMSではデータを移動したら負け(1回データを入れたら出さない)
- どういうときに再分散が起こるか
- JOINとGROUP BY
- ジョインキーがdistkeyなら再分散は起こらない(distkeyのハッシュ値でsliceの場所が決まるため、ジョイン相手も同じnode sliceにある)
- Redshiftで一番ボトルネックになりやすいのがネットワーク
- ネットワークに負荷をかけないために、再分散を避ける
- EXPLAINコマンドで DS_DIST_NONEが出てくればOK
- 並列RDBではネットワークが最も貴重なリソース
- 再分散を回避するためには分散キーを熟慮しよう
「AWS使用がもっと楽になるネットワーク系の新サービス at VPC,ELB,CloudFront,Route53」@ar1 さん
AWS、今年に入ってからすでに100件以上のアップデートが!そのうち、ネットワーク系の新サービスの紹介。 ELB- Logging機能が追加
- 実はELB、ほとんどのTCPのポートに対してプロキシとして動く
- Connection Draining機能が追加
- ECDHEサポート:一定時間ごとに鍵交換
- Server Order Preferenceサポート
- PFSサポート:ポリシー「ELBSecurityPolicy2014-01」を使おう
- EDHでの鍵交換 DHパラメータを署名するためにサーバ秘密鍵を使う
- SNI (Server Name Identification) 対応
- RFC6606のTLS拡張仕様
- HTTPSをユーザが独自証明書なしで使用可能に
- クライアント側の対応も必要 (故・Windows XPでは非対応だったり……)
- HTTP Redirect:HTTPからHTTPSにリダイレクトするよう設定可能に
- EDNS-Client-Subnetをサポート
- Google Public DNSやOpenDNSなど、サポートされるDNSリゾルバを使っている場合、より正確に最も近いエッジロケーションが選択されるように
- この機能をOFFにすることはできません
- ヘルスチェックの間隔を10秒に設定できるように
- フェイルオーバ実行のしきい値の制御が1〜10の間で設定可能に(デフォルト3)
- フェイルオーバにかかる時間 = TTL + (間隔 * しきい値)
- ヘルスチェック機能の拡充
- HTTPSへの対応
- レスポンス文字列の設定ができる(先頭5120バイトまでのうち255文字まで)
- UPSERT対応
- レコードに対して更新と新規作成を区別なく可能に
- インスタンス起動時に自分を登録するような場合に使える
LT
「EC2 + Spot Instance + Spark + MLlib で実現する簡単低コスト高速機械学習」@yamakatuさん
「5分でできる ebfly」@hakoberaさん
「Logging and Data Analysis on .NET Framework with Redshift and DataPipeline」@tanaka_733さん
発表資料が現時点で公開されていないようでしたので非掲載です。(写真撮っておけば良かったです…)ETW (Event Tracing for Windows:Windows OSが提供するロギング機構) からS3にデータを書き込み、Redshiftに格納して処理しようという取り組みの紹介。