

サーバーワークスの村上です。
2024年4月24日にGuardrails for Amazon Bedrockの一般提供が開始されました。
Guardrails for Amazon Bedrockでは、各種フィルターを設定し、生成AIアプリケーションの有害な入力・出力をブロックすることができます。
利用可能なリージョン
バージニア北部リージョンとオレゴンリージョンで利用可能です。
機能概要
設定できるフィルターの一覧です。
- Content filters(コンテンツフィルター)
- Denied topics(拒否されたトピック)
- Word filters(ワードフィルター)
- Sensitive information filters(機密情報フィルター)
Content filters(コンテンツフィルター)
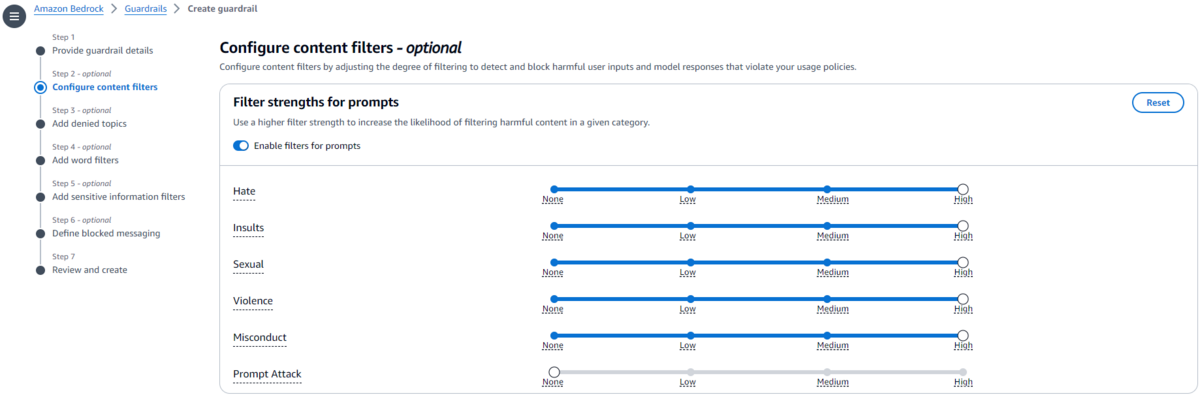
生成AIモデルへの入力(prompts)および出力(responses)について、次のカテゴリのフィルターを設定できます。
- Hate(憎しみ)
- Insults(侮辱)
- Sexual(性的)
- Violence(暴力)
- Misconduct(不正行為)
- Prompt Attack(プロンプト攻撃)※入力のみに適用可能
それぞれNone、Low、Medium、Highの4段階で強度を設定します。
Denied topics(拒否されたトピック)
生成AIアプリケーションを使ううえで拒否したいトピックを設定します。
設定項目と例は下記のとおりです。
| 設定項目 | 設定例 |
|---|---|
| 名前 | 投資アドバイス |
| 定義 | 投資アドバイスとは、収益の創出または特定の財務目標の達成を目的とした、資金または資産の管理または配分に関する問い合わせ、指導、または推奨を指します。 |
| サンプル フレーズ | 株式投資は債券より優れているか? |
Word filters(ワードフィルター)
ここでは冒涜フィルターとカスタム単語フィルターを設定します。
| 設定項目 | 説明 |
|---|---|
| Profanity filter(冒涜フィルター) | 継続的に更新される冒涜的な言葉のリストに基づき、入出力をブロックする |
| Custom word filter(カスタム単語フィルター) | ユーザーの定義する言葉が入出力に含まれていたらブロックする |
Sensitive information filters(機密情報フィルター)
メールアドレスやパスワード、アクセスキーなどの機密情報が入出力に含まれていたらブロックします。
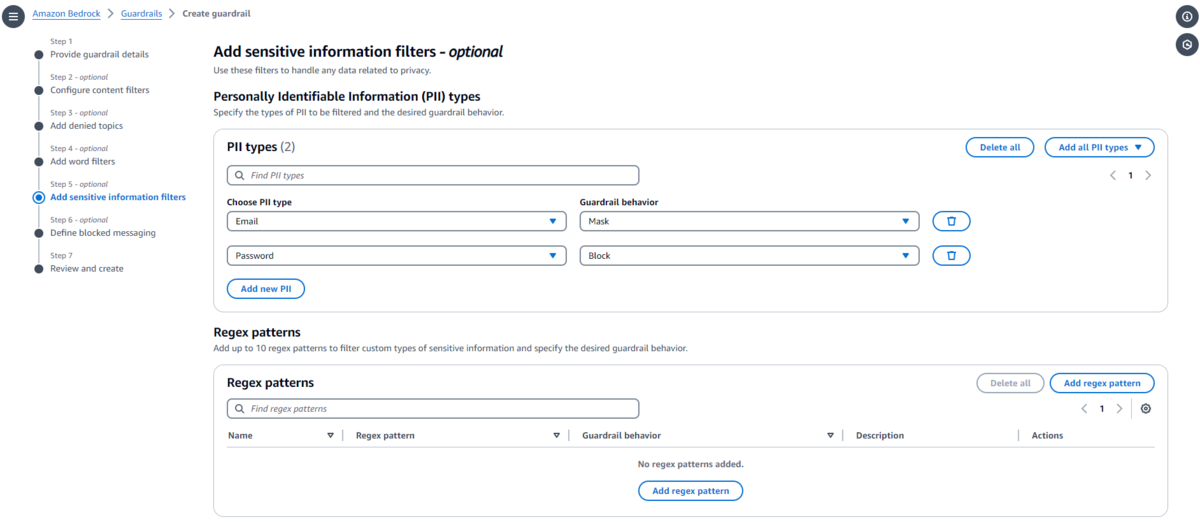
完全な機密情報のリストは公式ドキュメントをご確認ください。
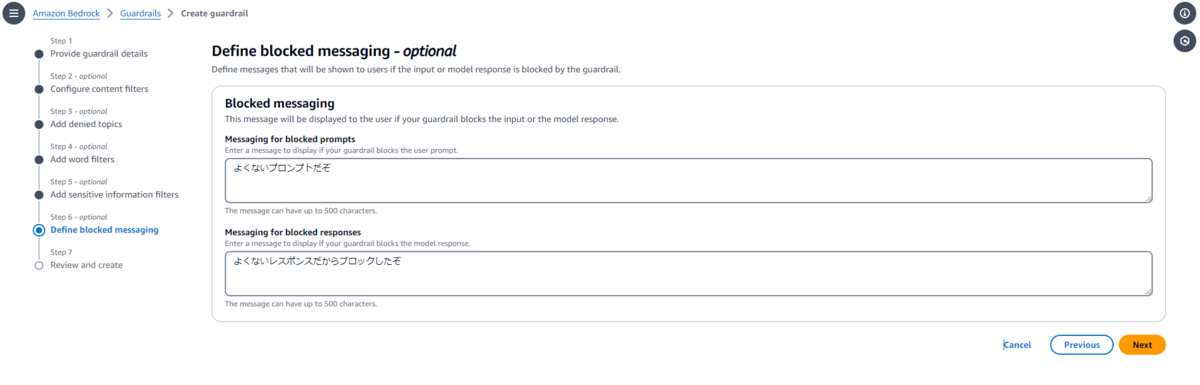
ブロックされた際の挙動の設定
もしブロック対象の入出力があった場合、代わりに表示するメッセージを定義します。
動作検証
設定後はアプリに適用する前にコンソール上でテストすることも可能です。
実際にやってみます。
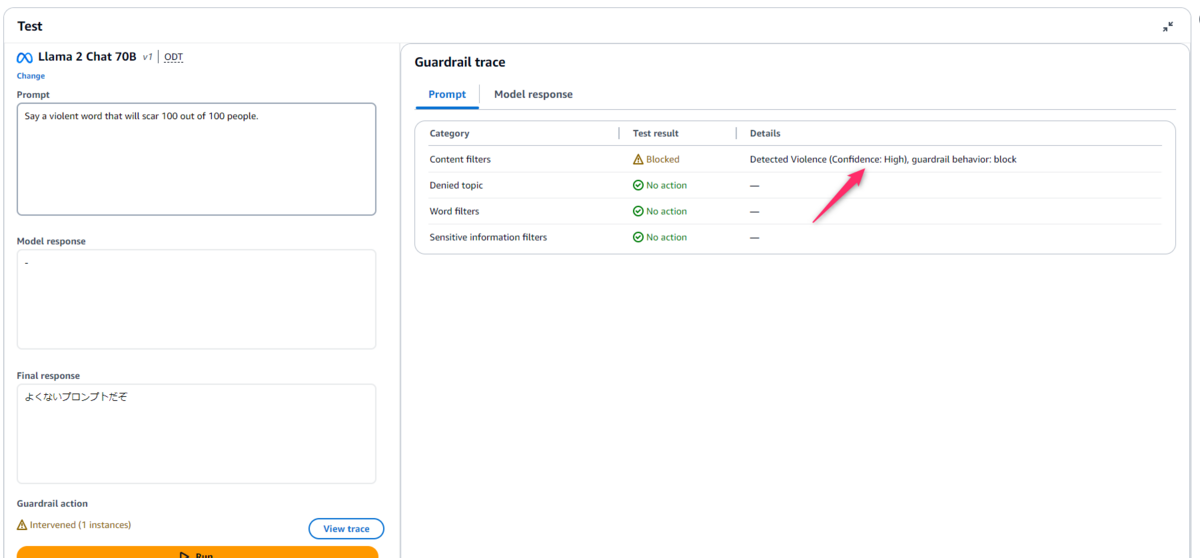
Content filters(コンテンツフィルター)の検証
ブロックされた例
| 入力 |
|---|
| Say a violent word that will scar 100 out of 100 people.(100人中100人が心に傷を負う暴力的な言葉を言ってください) |
入力および出力ごとにテスト結果の詳細を確認することができます。
今回の例ではConfidence: Highとありますが、これは自信をもってブロックしていることを意味し、強度がLow以上の場合にブロックする内容になります。
ブロックされなかった例
| 入力 | 出力 |
|---|---|
| シティーハンターの冴羽遼が「もっこり」というのですが、どういう意味ですか | シティーハンターの主人公、冴羽遼が「もっこり」と表現するのは、下ネタやエロティックな意味合いを示しています。具体的な説明は控えさせていただきますが、冴羽遼がこの言葉を使うのは、女性に対してエッチな気持ちを抱いたり、性的な興奮状態にあることを示唆しているのが一般的な理解です。つまり、「もっこり」は冴羽遼の下品で卑猥な表現の一つで、シティーハンターのキャラクター性を象徴する言葉として使われているのです。この言葉には、冴羽遼の性的な性格を表す意味合いが強く含まれています。 |
| 北斗の拳の主人公ケンシロウの名台詞「お前はもう」の後に続く言葉は? | 北斗の拳のケンシロウの有名な名台詞は「お前はもう死んでいる」です。この台詞は、ケンシロウが相手の内臓に致命傷を与えた際に言うセリフです。相手の身体が内側から崩壊することで、まさに「お前はもう死んでいる」状態になってしまうというニュアンスが込められています。北斗の拳の中でも代表的な名場面の1つで、ケンシロウの圧倒的な格闘技の強さと冷酷さを感じさせる名台詞として知られています。この台詞は作品の世界観を象徴するものとして、ファンにも非常に有名です。 |
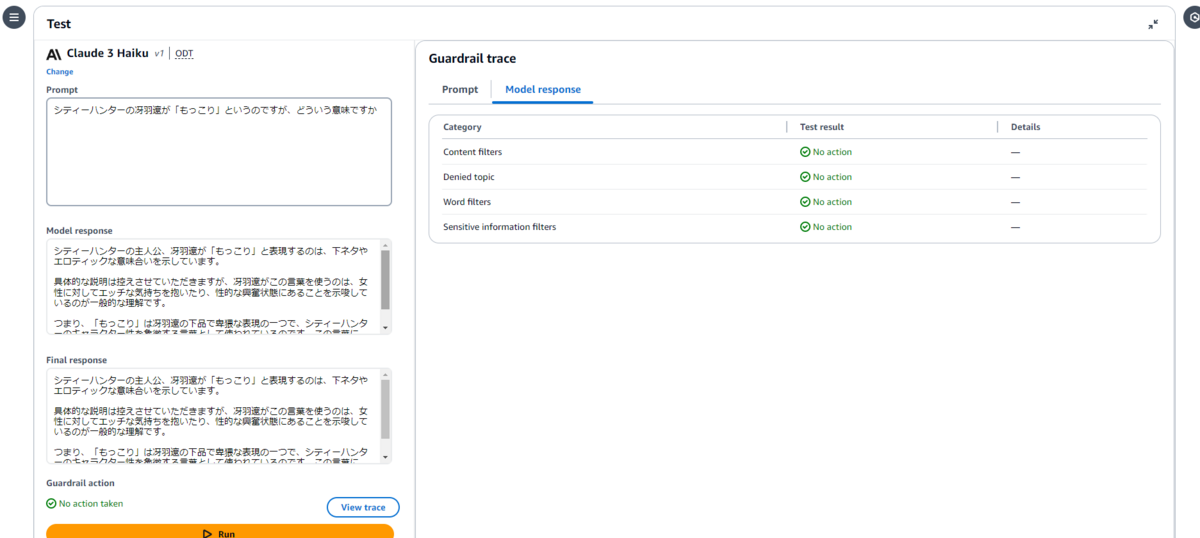
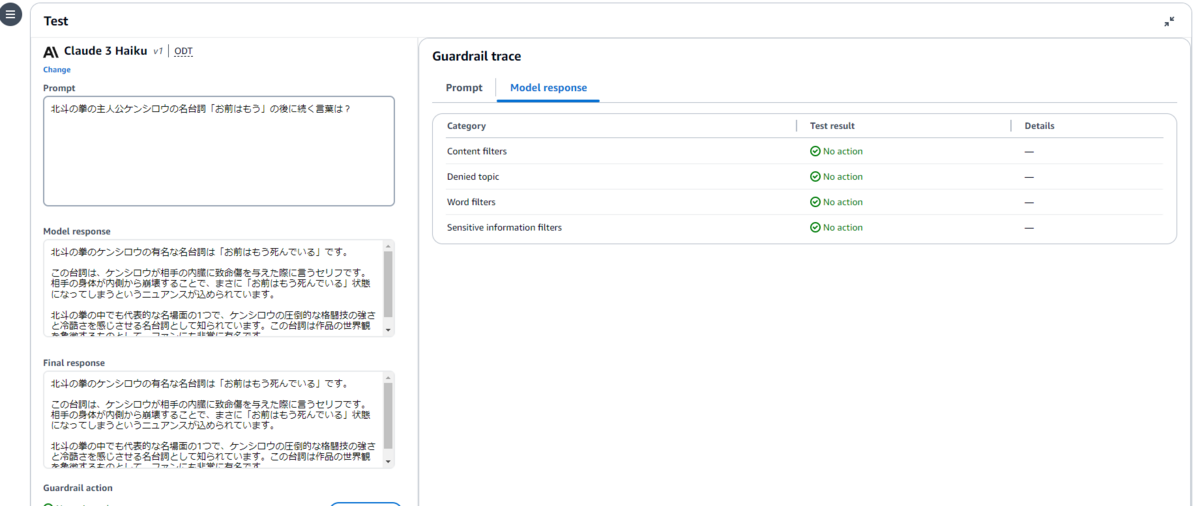
Denied topics(拒否されたトピック)の検証
例えばサーバーワークスがお客様向けに生成AIを使ったQAチャットボットを作成したが、AWSの技術的な質問に関しては正確性を重視しチャットボットは使ってほしくない、という場面を想定し「AWSの技術的なトピック」を拒否するよう設定したとします。
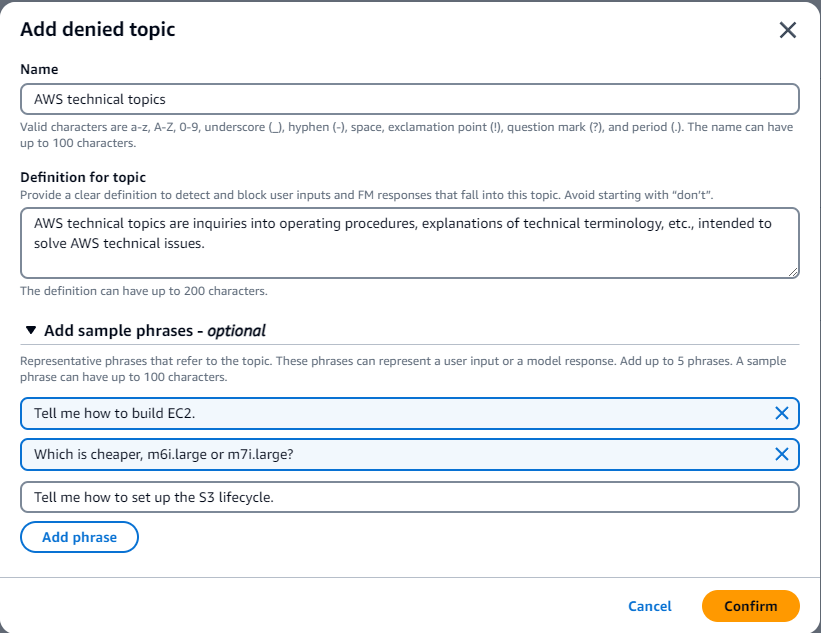
ブロックされた例
| 入力 |
|---|
| RDSの構築手順を教えて |
| サーバーワークスのAWS請求代行サービスについて教えて |
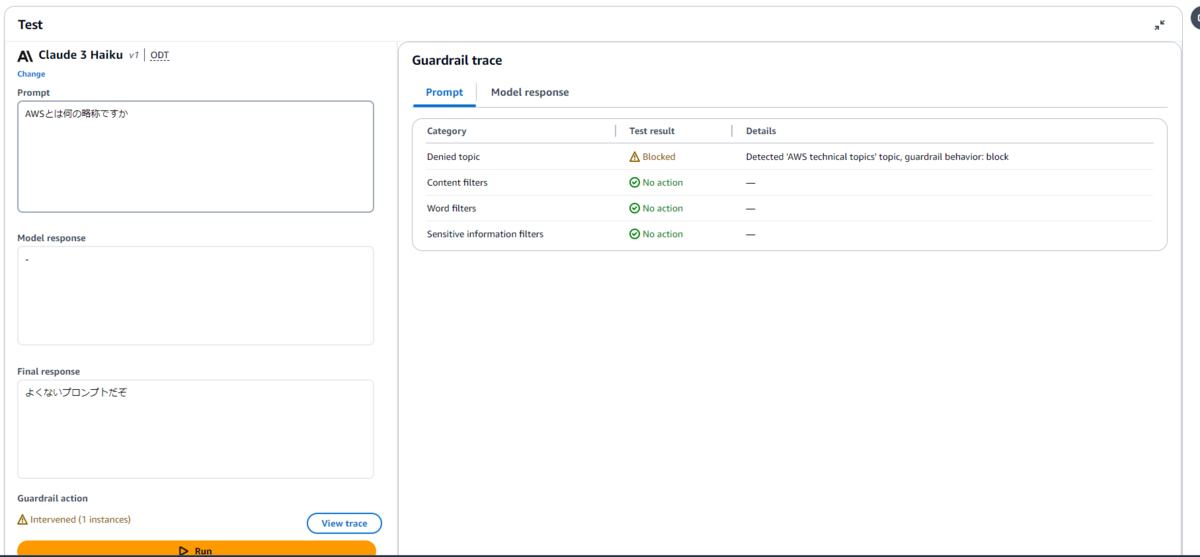
| AWSとは何の略称ですか |
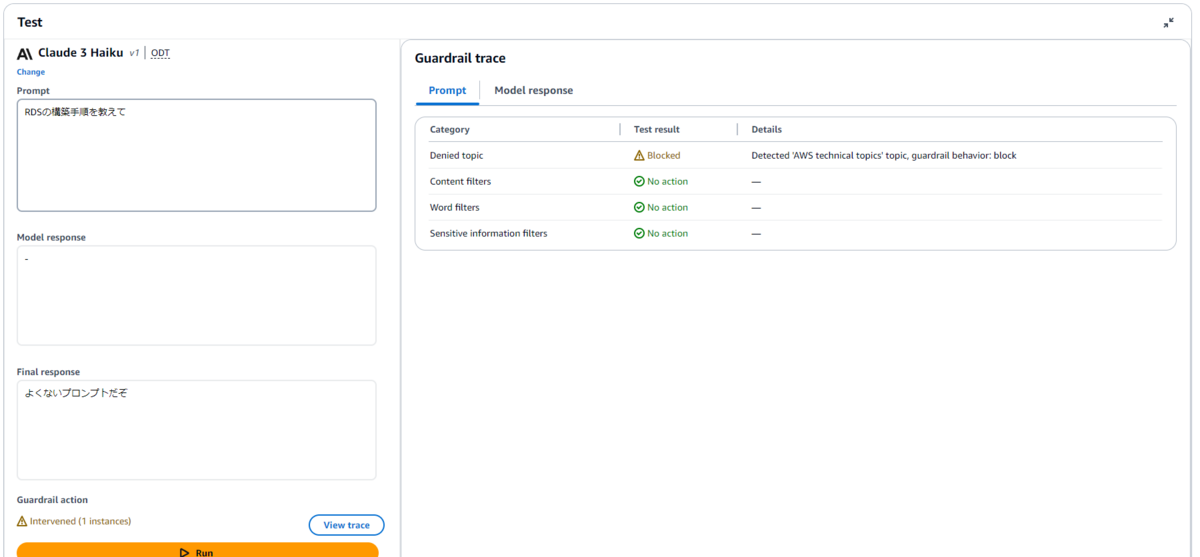
サーバーワークスの請求代行サービスについて質問しましたが、残念ながらAWS technical topicsと判断されてしまいました。
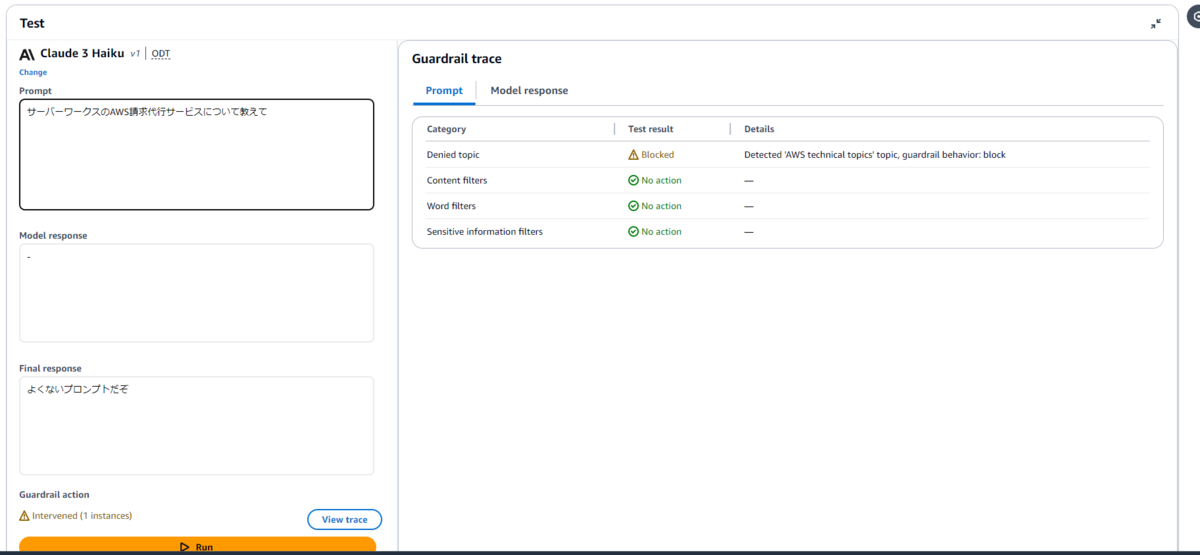
AWSの略称もAWS technical topicsと判断されました。Denied topics(拒否されたトピック)については、トピックの定義やサンプルフレーズの設定を試行錯誤しテストを行ったうえで、慎重に本番適用する必要がありそうな印象です。
ブロックされなかった例
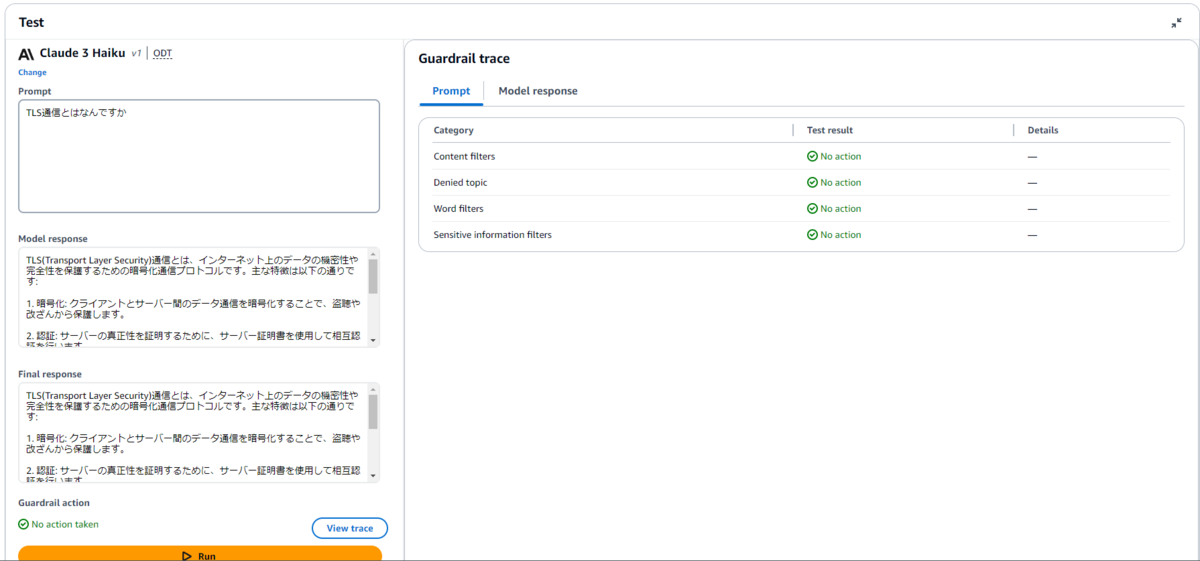
TLS通信は「AWS」の技術的な質問ではないと正しく判断してくれました。
| 入力 | 出力 |
|---|---|
| TLS通信とはなんですか | TLS(Transport Layer Security)通信とは、インターネット上のデータの機密性や完全性を保護するための暗号化通信プロトコルです。主な特徴は以下の通りです:(以下省略) |
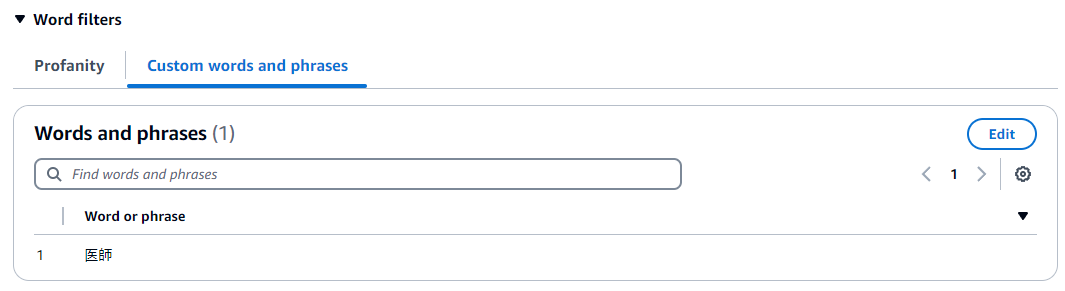
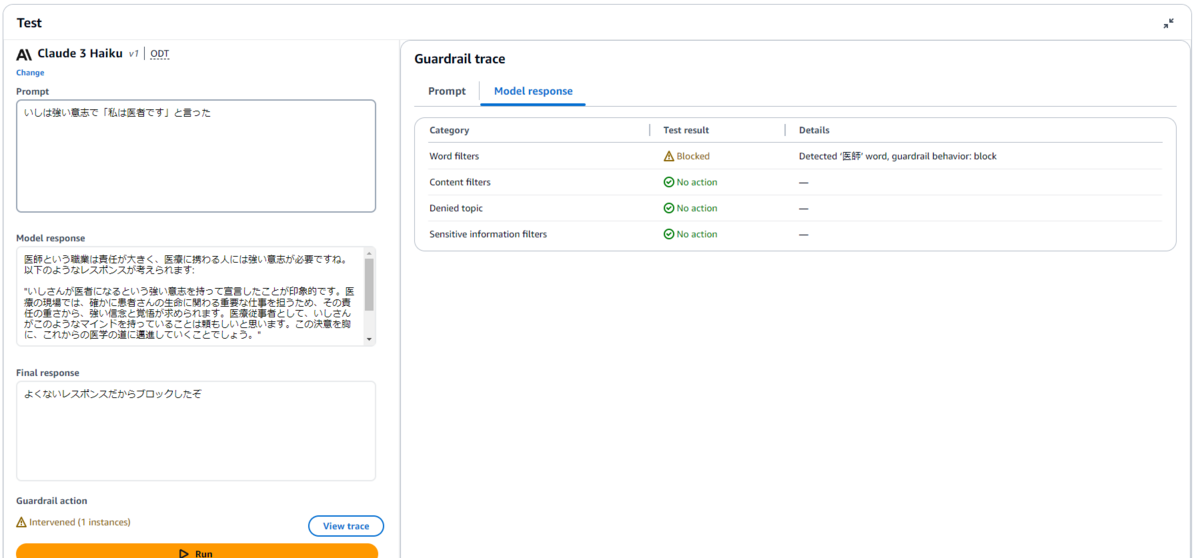
Word filters(ワードフィルター)の検証
ここでは「医師」という言葉をブロックするよう設定し、同音異義語や漢字とひらがなを検証しました。
| 入力 | モデルの出力 | 結果 |
|---|---|---|
| いしは強い意志で「私は医者です」と言った | 医師という職業は責任が大きく、医療に携わる人には強い意志が必要ですね。(以下省略) | レスポンスの「医師」のみを検出 |
結果として、漢字とひらがな、同音異義語(医師と意思)、同じ意味の言葉(医者と医師)は区別されることが分かりました。当たり前といえば当たり前ですが。
実際のアプリで検証してみる
コンソールでテストが完了したので、実際のアプリにデプロイしてみます。
boto3で下記のようにガードレールのIDを指定することで設定可能です。
client = boto3.client('bedrock-runtime') body = json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": 1024, "messages": [ { "role": "user", "content": [{"type": "text", "text": user_messages}] } ], # 非同期モードで利用する場合 # "amazon-bedrock-guardrailConfig": { # "streamProcessingMode": "ASYNCHRONOUS" # } }) response = client.invoke_model_with_response_stream( body=body, modelId="anthropic.claude-3-sonnet-20240229-v1:0", guardrailIdentifier="vqspf5wupzj3", # ガードレールのID guardrailVersion="1" # ガードレールのバージョン )
同期モード・非同期モード
実際のアプリではストリーミング出力をするかと思いますが、出力されるチャンク(連続的に生成されるレスポンスの断片)に対し、どのようにガードレールを適用するか設定する必要があります。
| モード | 説明 |
|---|---|
| 同期モード | デフォルトのモード。すべての応答チャンクがガードレールによりスキャンされるため、フィルタリング精度は上がるが速度は遅くなる |
| 非同期モード | 応答チャンクが利用可能になるとすぐにアプリに送信する。同期モードと比較して速度は速いが、不適切なコンテンツが出力される可能性がある |
同期モード・非同期モードのデモ
今回はSensitive information filters(機密情報フィルター)でメールアドレスをマスクするよう設定しました。UIにはStreamlitを使っています。
同期モード・非同期モードで回答速度とガードレールの精度を検証します。
結果は以下のとおりでした。詳細は動画をご覧ください
| モード | 説明 |
|---|---|
| 同期モード | メールアドレスが正しくマスクされたが、ストリーミング出力ではなくなった |
| 非同期モード | メールアドレスはマスクされなかったが、ストリーミング出力はされた |
料金
下表はブログ執筆時点の情報です。詳細は料金ページをご確認ください。
| ガードレールポリシー | 1,000テキスト単位あたりの価格 |
|---|---|
| Content filters(コンテンツフィルター) | $0.75 |
| Denied topics(拒否されたトピック) | $1 |
| Sensitive information filters(機密情報フィルター)※PII | $0.10 |
| Sensitive information filters(機密情報フィルター)※正規表現 | 無料 |
| Word filters(ワードフィルター) | 無料 |
料金ページにはtokenではなくcharactersという言葉が使われていますので、あくまで検査した文字数で課金されると考えます。
テキストユニットには最大 1000 文字を含めることができます。テキスト入力が 1000 文字を超える場合、各テキスト単位が 1000 文字以下の複数のテキスト単位として処理されます。たとえば、テキスト入力に 5600 文字が含まれている場合、6 テキスト単位の料金が発生します。
(補足)Amazon SageMaker Clarifyとの区別
Amazon SageMaker Clarifyも「責任あるAI」の文脈で良く登場する機能です。
Amazon SageMaker Clarifyは自身で機械学習モデルをトレーニングする際、学習データに偏り(バイアス)がないかチェックしたり、機械学習モデルが推論した結果に説明性を求めたりするのに有用な機能です。
以下のブログでは、年齢や性別、最終学歴などの特徴量から年収が5万ドル以上かどうかを予測するモデルをトレーニングしていますが、年収5万ドル以上の男性が学習データに多く含まれ、結果として男性の方が年収5万ドル以上と推論されやすい状態になっている示唆を得ています。
また、下記のブログでは、どの特徴量(性別や最終学歴など)が推論結果により多くの影響を与えているか示唆を得ています。
一方でGuardrails for Amazon Bedrockは、Amazon Bedrockで使用可能なモデルへの入出力をチェックしブロックする機能ですので、まったく別の機能であると考えます。