

クラウドインテグレーション部の村上です。NBAが大好きです。
渡邊選手も八村選手もケガから復帰したので毎日楽しみですね。
Everybody eats 🍴 pic.twitter.com/y479KqAOvn
— Brooklyn Nets (@BrooklynNets) 2022年12月22日
さて、今回はAmazon SageMaker Clarifyのブログ第2弾です。前回のブログは以下からご参照ください。
- 機械学習モデルの説明可能性とは
- Amazon SageMaker Clarifyと説明可能性
- Amazon SageMaker Clarifyを使ってみる
- Explainability Reportで分かること
- まとめ
機械学習モデルの説明可能性とは
様々な定義があるかと思いますが、「なぜそのように推論されたのか人間が説明できること」と私は理解しています。
例えば、ローンの審査で機械学習を使って融資の可否を決定しているとします。
この場合「なぜローン審査に落ちたのか」を説明できないと、審査に落ちた人にとっては不満ですよね。
このように機械学習モデルの説明可能性は、人間が機械の判断を受け入れるのに必要な要素といえます。
Amazon SageMaker Clarifyと説明可能性
Amazon SageMaker Clarifyでは機械学習モデルを説明するために、SHAP (SHapley Additive exPlanations)を採用しています。
SHAP (SHapley Additive exPlanations)とは
SHAPは「ある特徴量がその予測にどれだけ影響したか」を把握するためのアプローチです。
下の絵ではブラックボックスとなっていたモデルが、SHAPを導入することで、各特徴量がどのように影響したのか可視化されています。

もともとはゲーム理論でプレイヤーの貢献度を測るShapley Valueを機械学習に応用したものらしいです。
AWS Online Tech Talksでは、タクシーの乗り合いで誰がいくら支払うべきかを例に説明されています。英語セッションなので雰囲気だけ感じましょう。

SHAPの補足説明
ここではSHAPで登場する用語を備忘録として私なりにまとめます。
SHAP値
「ある特徴量がその予測にどれだけ影響したか」を数値化したものです。
これを計算するためには、各特徴量の順列のパターンを考慮して平均をとる必要があります。タクシーの例を再掲しますが、A・B・Cすべての順列3! = 6通りの考慮をしています。
特徴量がないときの予測値
これは用語というより考え方の話です。
タクシーの例では、乗り合いをしない場合に支払う金額が定義されています。

上記の前提のもと、タクシー乗り合いをすることで支払う金額がどれだけ少なくなるか、各人の貢献度を測るのがShapley Valueの考え方です。
これを機械学習に応用すると、ある特徴量がないとき(ゲーム理論的に言うと、あるプレイヤーが不在のとき)の予測値を出す必要があります。
どう出すのかというと、平均的な特徴量の値を決めてしまいます。これを「ベースライン」といいます。
適切なベースラインはどのように選択すればよいでしょうか。多くの場合、情報コンテンツが非常に少ないベースラインを選択することが望ましいです。例えば、数値特徴では、中央値または平均値、カテゴリ特徴では、モードをとることで、トレーニングデータセットから平均的なインスタンスを構築できます。
説明可能性のための SHAP ベースライン - Amazon SageMaker
このベースラインに特徴量をひとつずつ加えていくことで、予測がどう変化していくのかを見ます。
SHAPの図を再掲します。この図ではBase rateと表記されており、その値は0.1です。
まず特徴量BMIが加わり、予測が+0.1変化しています。次に特徴量BPが加わり、予測が+0.1変化しています。
Amazon SageMaker Clarifyでは、baseline引数として登場します。
サンプル数
これまでの考え方のもと、すべてを計算しようとすると計算量が膨大になります。
特徴量数をd個とすると、どの特徴量を不在とするかは2dパターンになるからです。
d 個の特徴がある場合、このような特徴の組み合わせは 2d とおりあり、それぞれが潜在的なモデルに対応します。
(中略)
ただし、妥当な値の d、例えば 50 個の特徴であっても、2d の可能なモデルをトレーニングすることは計算上禁止されており、現実的ではありません。
Shapley 値を使用する特徴属性 - Amazon SageMaker
そこでSHAPでは全てのパターンを考慮するのではなく、いくつかサンプリングして計算を行います。
サンプリングの結果、不在となった特徴量の値はベースラインの値が使用されます。
Amazon SageMaker Clarifyでは、サンプル数はnum_samples引数として登場します。
Amazon SageMaker Clarifyを使ってみる
前回のブログでは、データやモデルのバイアスを検出するためにAmazon SageMaker Clarifyを使用しました。
具体的にはバイアスレポートを作成していましたが、同じような方法で説明可能性レポート(Explainability Report)というものも作成することができます。
それでは、Amazon SageMaker Clarifyを使って、モデルを理解していく過程を見ていきましょう。
使用するサンプルノートブックについて
今回もサンプルノートブックを使っていきます。年齢や学歴などの情報から年収が5万ドル以上かどうか予測するタスクです。
sagemaker-examples.readthedocs.io
データの前処理からモデルの作成までは前回のブログと同様ですので、詳細はそちらをご確認ください。
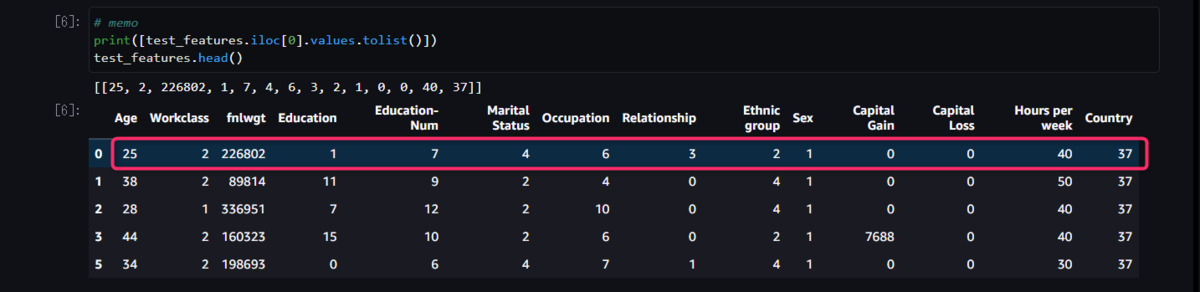
前提として、テストデータから目的変数のカラムを削除したDataFrameをtest_featuresとしています。
test_features = testing_data.drop(["Target"], axis=1)
SHAPConfig でベースラインを作成
shap_config = clarify.SHAPConfig(
baseline=[test_features.iloc[0].values.tolist()],
num_samples=15,
agg_method="mean_abs",
save_local_shap_values=True,
)
baselineとnum_samplesは前述の補足説明で記載したとおりです。ちなみに、どちらも必須のパラメータではありません。
ここではbaselineにテストデータの1つめのサンプルの値を指定しています。
agg_methodは各サンプルで得られたSHAP値(Local SHAP Value)から、モデル全体を解釈するためのSHAP値(Global SHAP Value)をどのように算出するか定義します。ここでは平均をとっています。
DataConfigでデータの入出力場所を定義する
次にデータの入出力場所を定義します。この辺はバイアスレポートのときと似ていますね。
explainability_output_path = "s3://{}/{}/clarify-explainability".format(bucket, prefix) explainability_data_config = clarify.DataConfig( s3_data_input_path=train_uri, s3_output_path=explainability_output_path, label="Target", headers=training_data.columns.to_list(), dataset_type="text/csv", )
ちなみにtrain_uriは前処理後の学習データをアップロードしたS3 URIのことです。
Explainability Reportを出力する
以下のコードで計算を実行します。
clarify_processor.run_explainability(
data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config,
)
model_configは前回のブログで定義した、Amazon SageMaker Clarify専用の推論エンドポイントです。
以上で、指定したS3に説明可能性レポート(Explainability Report)が保存されます。


Explainability Reportで分かること
Global SHAP Valuesから、重要な特徴量は出身国(Country)、教育年数(Education-num)、年齢(Age)であることが分かります。
また、Local SHAP Valuesでは、その特徴量が高い値だと赤い点が、低い値だと青い点がプロットされます。
The color represents the feature value (red high, blue low).
https://github.com/slundberg/shap
例えば教育年数(Education-num)が大きい(=赤い点)と、SHAP値が正の値になっていることがわかります。つまり、教育を長く受けていればいるほど、年収が高いと予測する傾向にあるということです。
しかし、年齢(Age)の場合、年齢が高い(=赤い点)とSHAP値が正の値である傾向はあるものの、若くても(=青い点)SHAP値が正の値をとっているものもあり、教育年数ほどの重要性はないような気がします。

以上のようなことがわかります。
まとめ
このブログではAmazon SageMaker Clarifyを使って、SHAP値を求めることにより、特徴量の重要度を見ました。
料金は使用したコンピューティングリソースの分だけですので、バイアスレポートと説明可能性レポートはぜひ活用していきたいですね。