

5月末にIE課を卒業し、技術4課に配属されました前田(青)です。 ElastiCache for Redisの仕様について調査する機会があり、アプリケーション側からElastiCacheを利用するイメージを掴むために AWSが提供しているハンズオンをやってみました。その結果実感できたこと2点をお伝えしていきたいと思います。
ハンズオン概要
環境
下記画像のような環境を作成します。クライアントEC2上のPythonスクリプトを実行し、ElasitCacheに対してキャッシュデータの書き込み・読み込みが出来ることを確認します。

ハンズオン手順について
手順について本記事では説明いたしません。ハンズオン記事に詳しく載っているためそちらをご覧ください。 aws.amazon.com
実感できたこと①:実行SQLをキーに指定してキャッシュデータを格納できる。
Key-Value型データストアにあまり触れてこなかった身としては、下図のような形でKeyに主キーを指定してキャッシュデータを格納するものだと思っていました。
(勿論、左記のような格納方法も実装可能です。)

しかし下図のように、RDSに対して実行するSQLをキーとしてキャッシュデータを格納することも出来ました。
全件SELECTはキャッシュデータ量が膨大になってしまいそうですが、例えばアプリケーション側でWhere句の指定条件を動的に変えたSQLを実行する…のような応用が出来そうです。

ソースコードは下記になります。(ハンズオン中に登場するサンプルコードですが、説明しやすいように少し変えています。)
import os import json import redis import pymysql class DB: def __init__(self, **params): params.setdefault("charset", "utf8mb4") params.setdefault("cursorclass", pymysql.cursors.DictCursor) self.mysql = pymysql.connect(**params) def query(self, sql): with self.mysql.cursor() as cursor: cursor.execute(sql) return cursor.fetchall() def record(self, sql, values): with self.mysql.cursor() as cursor: cursor.execute(sql, values) return cursor.fetchone() # Time to live for cached data TTL = 10 # Read the Redis credentials from the REDIS_URL environment variable. REDIS_URL = os.environ.get('REDIS_URL') # Read the DB credentials from the DB_* environment variables. DB_HOST = os.environ.get('DB_HOST') DB_USER = os.environ.get('DB_USER') DB_PASS = os.environ.get('DB_PASS') DB_NAME = os.environ.get('DB_NAME') # Initialize the database Database = DB(host=DB_HOST, user=DB_USER, password=DB_PASS, db=DB_NAME) # Initialize the cache Cache = redis.Redis.from_url(REDIS_URL) def fetch(sql): """Retrieve records from the cache, or else from the database.""" res = Cache.get(sql) if res: print("キャッシュあり") return json.loads(res) print("キャッシュなし") res = Database.query(sql) Cache.setex(sql, TTL, json.dumps(res)) return res # Display the result of some queries print(fetch("SELECT * FROM planet"))
注目いただきたいのは関数「fetch」です。実行するSQL「SELECT * FROM planet」をキーとしてキャッシュデータをElastiCacheに書き込んでいます。
def fetch(sql): #print(fetch("SELECT * FROM planet"))から呼び出される """Retrieve records from the cache, or else from the database.""" res = Cache.get(sql) #ElastiCacheからキー「SELECT * FROM planet」を指定してキャッシュデータを取得する if res: print("キャッシュあり") return json.loads(res) #ElastiCacheからキャッシュデータを取得できた場合、jsonを返す。 print("キャッシュなし") res = Database.query(sql) #ElastiCacheからキャッシュデータを取得できない場合、RDSからデータ取得する Cache.setex(sql, TTL, json.dumps(res)) #ElastiCacheに「SELECT * FROM planet」をキーとしてキャッシュデータを格納する return res
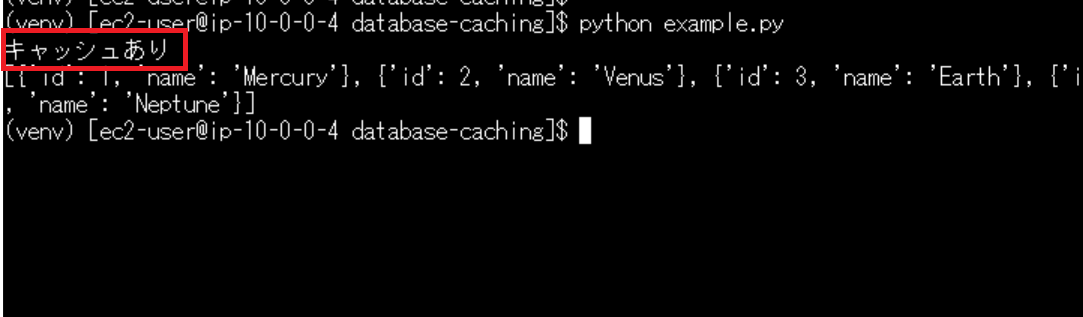
実際の挙動は下記のような感じです。
初回アクセス時はRDSからデータを取得し、ElastiCacheにデータを格納します。

2回目のアクセスではElastiCacheからデータを取得します。
実感できたこと②:クラスターモード有効ElastiCacheのノードへのアクセス方法
今回実施したハンズオンではクラスターモード無効のElastiCacheを使用することが前提だったのですが、クラスターモード有効のElastiCacheを使用するとどうなるのかが気になり、色々いじったり調査したりしました。その結果実感できたことを記載していきます。
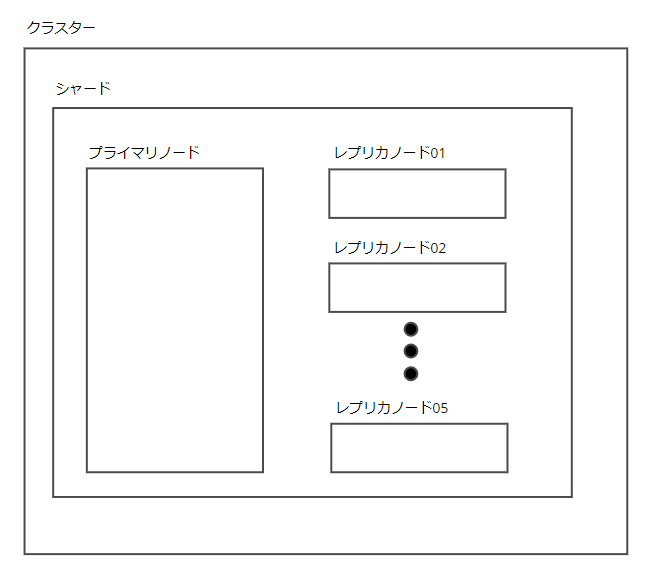
前提1:ElastiCache for Redisの構成要素
前提として、ElastiCacheは下記の要素から構成されています。
- ノード…ElastiCacheの構成要素の最小単位です。キャッシュ書き込み・読み込み用のプライマリノードとキャッシュ読み込み専用のレプリカノードがあります。プライマリノードは1シャードにつき1個、レプリカノードは1シャードにつき0~5個存在します。
- シャード…プライマリノードとレプリカノードのまとまりです。
- クラスター…シャードのまとまりです。
図示すると下記のようになります。
前提2:クラスターモードとは
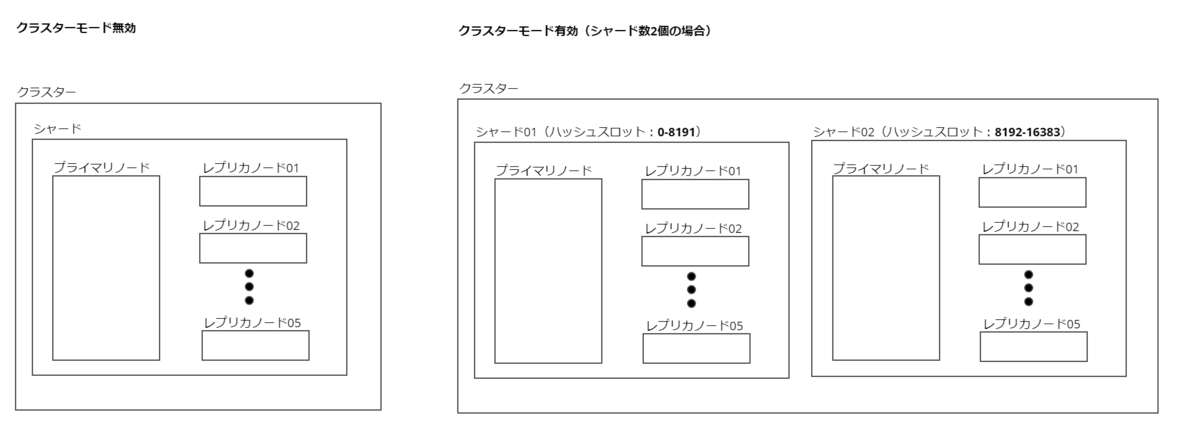
ElastiCache for Redisにはクラスターモードという設定があり、無効化するか有効化するかを選択できます。
- クラスターモード無効…クラスター(※1)が持てるシャードは1個のみです。
- クラスターモード有効…クラスターが持てるシャードは1~500個です。
また、キャッシュデータを複数のシャードに分割して持つ(※2)ようになります。データを分散するための基準として、シャードには「ハッシュスロット」というハッシュ値の範囲が下記画像のように割り当てられています。

参考1:クラスターの管理 - Amazon ElastiCache for Redis
参考2:レプリケーション: Redis (クラスターモードが無効) 対 Redis (クラスターモードが有効) - Amazon ElastiCache for Redis
クラスターモード無効・有効は図示すると下図のようなイメージになります。
※1…クラスターモードはシャードを1個のみ持つか複数個持つかの違いであって、無効化してもクラスターという概念自体は存在するのです…。ややこしいですね。
※2…このようなデータの持ち方をシャーディングと言います。
クラスターモード有効化状態のノードへのアクセス方法
今回の記事で一番お伝えしたいことを書いています。 シャーディングなどの関係で、クラスターモード無効・有効ではそれぞれノードへのアクセス方法が異なります。(参考: Redis クライアントの読み取りリクエストがシャードのプライマリノードから読み取られるか、シャードのプライマリノードにリダイレクトされる理由を確認する | AWS re:Post)
クラスターモード無効の場合はプライマリエンドポイントとリーダーエンドポイントが用意されており、前者はプライマリノードへ、後者はレプリカノードへアクセスすることが出来ます。

クラスターモード有効の場合は設定エンドポイントのみが用意されています。アクセスするとランダムなノードへ飛ばされ、そのノードからキーのハッシュ値に基づいて目的のノードへリダイレクトされます。
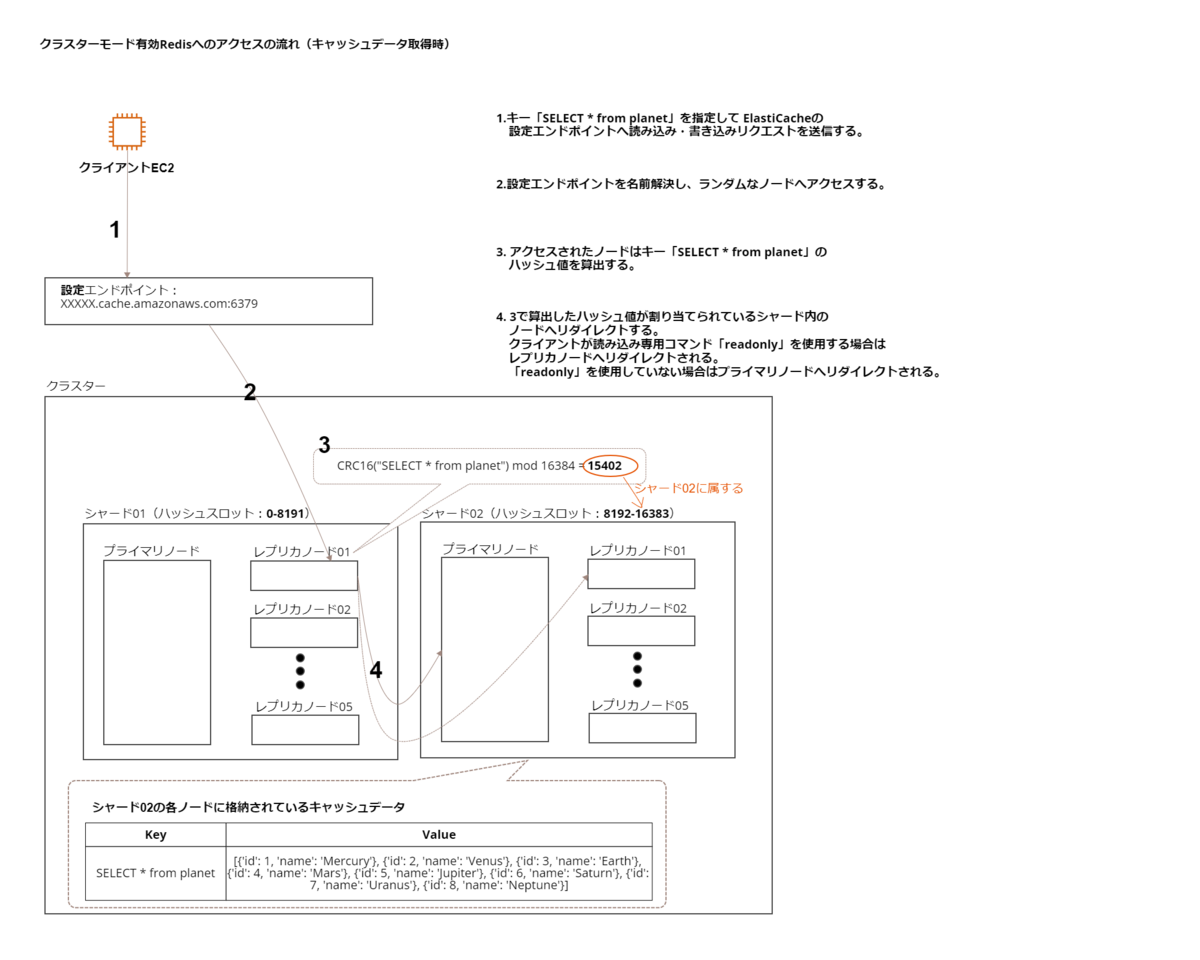
もしクラスターモード有効化状態のElastiCacheにアクセスする場合、今回のハンズオンではソースコードが対応していないため、redis.exceptions.ResponseError: MOVED 15402 10.0.0.109:6379のようなエラーが発生します。

図にすると下図のようになります。

ソースコードをクラスターモード有効に対応させるには
対応させる方法はとても簡単で、redisライブラリのclusterモジュールを使用するだけです。 下記ソースコードの3行目と39行目のように記述します。(参考:Python guide | Redis)
import os import json from redis.cluster import RedisCluster # クラスター無効の時は「import redis」と記述されていた箇所 import pymysql class DB: def __init__(self, **params): params.setdefault("charset", "utf8mb4") params.setdefault("cursorclass", pymysql.cursors.DictCursor) self.mysql = pymysql.connect(**params) def query(self, sql): with self.mysql.cursor() as cursor: cursor.execute(sql) return cursor.fetchall() def record(self, sql, values): with self.mysql.cursor() as cursor: cursor.execute(sql, values) return cursor.fetchone() # Time to live for cached data TTL = 10 # Read the Redis credentials from the REDIS_URL environment variable. REDIS_URL = os.environ.get('REDIS_URL') # Read the DB credentials from the DB_* environment variables. DB_HOST = os.environ.get('DB_HOST') DB_USER = os.environ.get('DB_USER') DB_PASS = os.environ.get('DB_PASS') DB_NAME = os.environ.get('DB_NAME') # Initialize the database Database = DB(host=DB_HOST, user=DB_USER, password=DB_PASS, db=DB_NAME) # Initialize the cache Cache = RedisCluster.from_url(REDIS_URL) # クラスター無効の時は「Cache = redis.from_url(REDIS_URL) 」と記述されていた箇所 def fetch(sql): """Retrieve records from the cache, or else from the database.""" res = Cache.get(sql) if res: print("キャッシュあり") return json.loads(res) print("キャッシュなし") res = Database.query(sql) Cache.setex(sql, TTL, json.dumps(res)) return res # Display the result of some queries print(fetch("SELECT * FROM planet"))
結果、エラーを発生させずにキャッシュデータを取得することが出来ました!

補足
補足1:コードがクラスターモード有効に対応していなくてもキャッシュデータ取得が成功する時がある。
実はソースコードがクラスターモード有効に対応していなくても、数回に1回は下記画像のようにキャッシュデータ取得が成功します。

成功した理由は、下図のようにキャッシュデータがあるプライマリノードへ初回アクセスできてリダイレクトが発生しなかったからです。

補足2:ハンズオンの手順からソースコードを改修してクラスターモード有効に対応させたい場合
ハンズオン中でインストールするredisのライブラリはバージョンが古く、cluster関連のモジュールが存在していません。 そのため、下記コマンドを実行してredisライブラリをアップデートしてください。
pip install -U redis
感想
ElastiCacheはキャッシングのためのサービスだということは理解していたのですが、今回の体験を得てより具体的なイメージを持って理解することが出来ました。 特に、ノードへのアクセス方法をしっかり理解できたことは非常に良かったと思います。この記事がどなたかの一助になれば幸いです。