

こんにちは、ディベロップメントサービス1課の山本です。
もう12月で、1年過ぎるのがとても早いですね。
今回は、少し早いクリスマスプレゼントとして、
AWS Lambda(以下、Lambda)を1円でも安くする方法を説明します。
AWS Lambda Power Tuningというツールを使って、Lambdaの割り当てメモリ量の最適化を行います。
この記事の対象者は?
この記事は以下の方々に向けて書かれています:
- Lambdaのコストを1円でも下げたい方々
- Lambdaの割り当てメモリを何となく決めている方々
- Lambdaの基本的なコストの計算方法を知りたい方々
Lambdaのコスト
まず、おさらいです。
Lambdaのコストは下記の表に従って決まります。 ※東京リージョン x86のみ抜粋
| アーキテクチャ | 期間 | リクエスト |
|---|---|---|
| x86 | ||
| 最初の60億GB秒/月 | GB-秒あたり 0.0000166667USD | リクエスト 100 万件あたり 0.20USD |
| 次の 90億GB秒/月 | GB-秒あたり 0.000015USD | リクエスト 100 万件あたり 0.20USD |
| 150億GB秒/月 以上 | GB-秒あたり 0.0000133334USD | リクエスト 100 万件あたり 0.20USD |
リクエストは、0.20USD/100万件ということもあり、コストに大きな影響は与えません。
大事なのは、期間の方です。
GB-秒あたりとは、Lambdaが、メモリ1GBで1秒間動作する単位のことを言います。
そのため、期間の価格は下記の計算式で出ます。
期間の価格 = 割り当てメモリ量(GB) × 月稼働時間(秒) × GB-秒あたりの単価
結果、Lambdaのコストが増加する要因としては、下記の二つになります。
- 割り当てメモリ量(GB)が大きくなる
- 稼働時間(秒)が長くなる
なら、コストを下げるには、割り当てメモリ量を限界まで下げればいいんだ!
それは、違います。
LambdaのメモリとCPUの関係
Lambdaでは、割り当てメモリ量が増えると、それに比例して、利用できるCPUリソースも増加する特徴があります。
先ほどの価格ページから引用します。
AWS Lambda のリソースモデルでは、お客様が関数に必要なメモリ量を指定すると、それに比例した CPU パワーとその他のリソースが割り当てられます。メモリサイズが増えると、関数で利用可能な CPU にも同等の増加が発生します。
簡単にいうと、メモリ量を半分に減らすと、処理性能も半分に減ります。
なので、メモリ量を限界まで下げると、今度は稼働時間が増加して、コストが増加する可能性があります。
逆に、メモリ量を上げ過ぎても、処理速度には限界があるので、コストは増加します。
割り当てメモリ量(GB) × 月稼働時間(秒)が最小
となる割り当てメモリ量を見つけることがコスト最適化の鍵です。
AWS Lambda Power Tuning
概要
割り当てメモリ量(GB) × 月稼働時間(秒)が最小となるメモリ量を探してくれるツールがAWS Lambda Power Tuningとなります。
仕組みは簡単です。
作成したLambda関数に対して、複数パターンでメモリ量を割り当てて、その稼働時間を計測するツールです。
その後、計測した時間を可視化して、一番低いコストとなるパラメータを見つけてくれます。
以下、可視化される際のサンプルです。

構成図
AWS Lambda Power Tuningの構成図は下記の通りです。
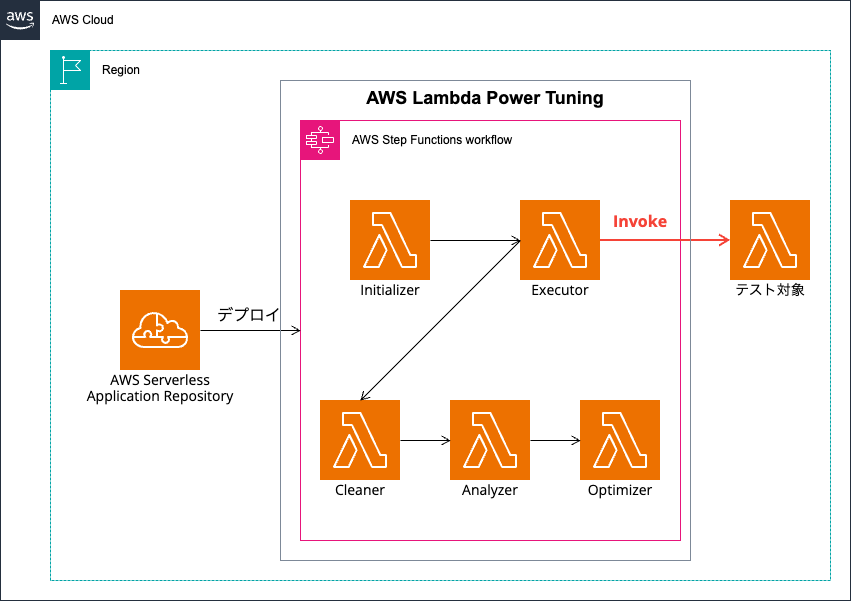
デプロイ方法
まず、AWS Lambda Power Tuningを自身のAWSアカウントにデプロイします。
デプロイ方法は、下記Githubに格納されてます。
aws-lambda-power-tuning/README-DEPLOY.md at master · alexcasalboni/aws-lambda-power-tuning · GitHub
いくつか手段はあるのですが、今回は一番簡単なAWS Serverless Application Repository (SAR)を利用する方法でデプロイします。
Option 1: AWS Serverless Application Repositoryの Serverless Application Repositoryをクリックして、SARへと遷移します。


Deployをクリックすると、ログインしているAWSコンソールのLambdaのアプリケーション画面へと遷移します。

アプリケーションの設定項目から、いくつかのツールの設定が可能です。
特にこだわりがなければ、全てデフォルト値で利用可能です。
| 項目 | デフォルト値 | 説明 |
|---|---|---|
| アプリケーション名 | aws-lambda-power-tuning | スタック名 |
| PowerValues | 128,256,512,1024,1536,3008 | テストする割り当てメモリ量 |
| lambdaResource | * | 呼び出しを許可するLambdaリソース。ARN指定やプレフィックス指定が可能。 |
| layerSdkName | ツールで利用するSDKレイヤー。 | |
| logGroupRetentionInDays | 7 | ログ保持日数 |
| payloadS3Bucket | 大きいペイロードを利用する際の、取得先バケット。 | |
| payloadS3Key | * | 上記バケットのオブジェクトキー。 |
| permissionsBoundary | ||
| securityGroupIds | ツールに割り当てるセキュリティグループID(VPC内のLambdaテスト時のみ必要) | |
| subnetIds | ツールに割り当てるセキュリティグループID(VPC内のLambdaテスト時のみ必要) | |
| totalExecutionTimeout | 300 | テスト実行時のタイムアウト時間 |
| visualizationURL | https://lambda-power-tuning.show/ | 可視化する際のURL |
設定項目の変更を終えたら、デプロイをクリックします。
CloudFormationのスタックが生成され、各種LambdaとStep Functionsのリソースが構築されます。

テスト実行方法
Step Functionsのステートマシンから、powerTuningStateMachineを選択します。

実行を開始をクリックします。

設定値入力画面に遷移するので、設定値を入力後に、実行を開始を選択します。

| パラメータ | 説明 |
|---|---|
| lambdaARN | テスト対象のLambdaARN |
| powerValues | テストするメモリ量 |
| num | 並列テスト数 |
| payload | eventデータの内容 |
他にも入力できる項目はありますので、詳細知りたい方は、READMEを参照ください。
https://github.com/alexcasalboni/aws-lambda-power-tuning/blob/master/README-INPUT-OUTPUT.md
結果確認
実行ステータスが成功に変わると、テスト完了です。
実行の入力と出力タブに切り替えると、出力に以下の内容が記載されます。
{ "power": 1024, "cost": 5.376e-7, "duration": 31.166666666666668, "stateMachine": { "executionCost": 0.0003, "lambdaCost": 0.000039679500000000005, "visualization": "https://lambda-power-tuning.show/*******" } }
| パラメータ | 説明 |
|---|---|
| power | 最適なメモリ量 |
| cost | Lambda1コールの費用 |
| duration | 稼働時間 |
| stateMachine.executionCost | テストにかかった費用 |
| stateMachine.lambdaCost | テストにかかったLambdaの費用 |
| stateMachine.visualization | 可視化用のURL |
可視化用のURLに遷移すると、メモリ量 vs 稼働時間、 メモリ量 vs コストがグラフ化されてます。
この内容を見ることで、最適なコストとなるメモリ量が1024MBとなることが分かります。
検証
せっかくなので、特性の異なる2つのLambdaを作成して、それぞれ最適となるメモリ量を検証してみます。
- サンプル1(計算負荷が高い)
- サンプル2(通信負荷が高い)
サンプル1(計算負荷が高い)
まず、サンプルとして計算負荷が高いLambdaを作成します。
とりあえず、X番目のフィボナッチ行列を導出させます。
def fibonacci(n: int): if n <= 0: return 0 elif n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) def lambda_handler(event, context): input_number = event.get('input_number', 30) fib_result = fibonacci(input_number) return fib_result
直感だと、CPUの価値が高まるので、ある程度高いメモリでコストが最適化されるイメージです。
結果は以下の通りです。
想像通り、パラメータ(計算数)が増えるにつれて、最適メモリ量も増加しました。
| パラメータ | 最適メモリ量(MB) |
|---|---|
| 10 | 128 |
| 20 | 256 |
| 30 | 1024 |



サンプル2(通信負荷が高い)
次に、サンプルとして通信負荷が高いLambdaを作成します。
DynamoDBにX回Get Itemを行い、通信回数を多くして、負荷を上げます。
import boto3 def get_item_dynamodb(table_name, key): dynamodb = boto3.resource('dynamodb') table = dynamodb.Table(table_name) response = table.get_item(Key=key) return response['Item'] def lambda_handler(event, context): count = event.get('count', 1) item_list = [] for i in range(count): item = get_item_dynamodb('sample_table', {'Key': 'sample'}) item_list.append(item) return { 'statusCode': 200, 'body': item_list }
直感だと、待ち時間が大半なので、低いメモリでコストが最適化されるイメージです。
結果は以下の通りです。想像通りですね。
| パラメータ | 最適メモリ量(MB) |
|---|---|
| 10 | 256 |
| 50 | 256 |
| 100 | 256 |



さいごに
少し早い、クリスマスプレゼントいかがでしたでしょうか。
Lambdaのメモリ量を適切にチューニングすることで、コスト削減/応答速度の向上が見込めます。 特に、無駄に大きいメモリを割り当てて、性能限界に達している場合は効果絶大です。
本ブログがどなかたのお役に立てれば幸いです。