

こんにちは。AWS CLIが好きな福島です。
はじめに
今回は、DynamoDBのデータをAthenaで分析する仕組みを作ってみます。
補足ですが、この仕組みを作ったキッカケは、RAGアプリのシステムにおいて、 会話履歴やフィードバック結果を保存したDynamoDBを分析したいと思ったことがキッカケとなります。
当初はDynamoDBをScanして取得したデータをRAGアプリ上で無理やり集計して画面に表示していたのですが、 頻度にもよると思いますが、分析する度にScanするのはイケテナイかなと思い、Athenaで分析する仕組みにしました。
概要図
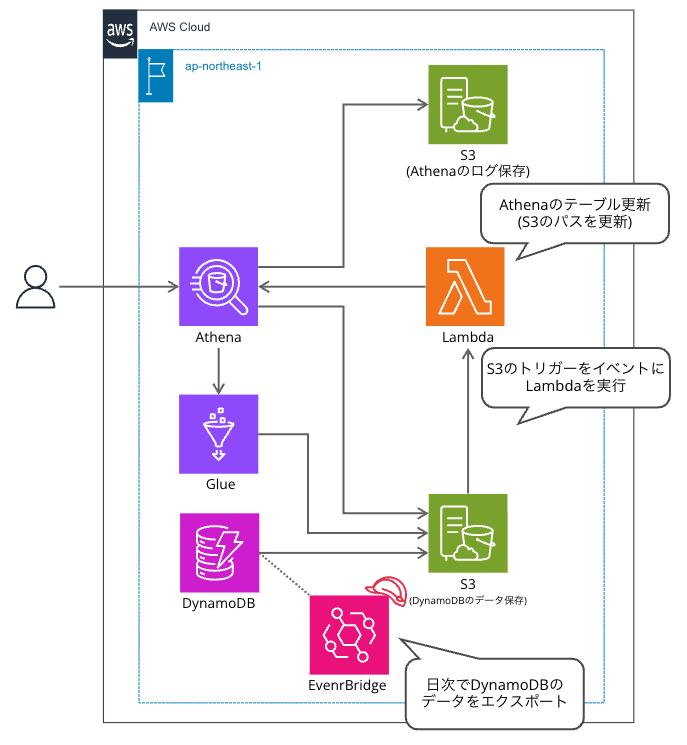
解説
- DynamoDBのエクスポートは、スケジューリングができないため、Eventbridge Schedulerを活用し定期実行するようにしています。
- DynamoDBのエクスポートは、毎回異なるオブジェクトキーになるため、エクスポートする度に、Athenaのテーブルが参照するS3のパスを更新する必要がありました。 そのため、作りたくなかったのですが、上記処理を行うLambdaを作成しています。
- DynamoDBのエクスポートには様々なファイルが作成されるのですが、data配下のjson.gzを利用します。 そのため、末尾がjson.gzのオブジェクトの作成をトリガーにLambdaを実行する仕組みにしています。
参考: DynamoDBのエクスポート時のS3のオブジェクト構造
DestinationBucket/DestinationPrefix
.
└── AWSDynamoDB
├── 01693685827463-2d8752fd // the single full export
│ ├── manifest-files.json // manifest points to files under 'data' subfolder
│ ├── manifest-files.checksum
│ ├── manifest-summary.json // stores metadata about request
│ ├── manifest-summary.md5
│ ├── data // The data exported by full export
│ │ ├── asdl123dasas.json.gz ⭐️このファイルがデータの実態
│ │ ...
│ └── _started // empty file for permission check
※https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/S3DataExport.Output.html から引用
手順
①リソースのデプロイ
- ソースコードのダウンロード
git clone https://github.com/kazuya9831/blog-sample.git
- ディレクトリの移動
cd blog-sample/athena-dynamodb/
- ソースコードのビルド
sam build
- リソースのデプロイ
sam deploy
②Athena(Glue)のセットアップ
- 変数の設定
export ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
export S3_BUCKET_FOR_ATHENA_QUERY_LOG="sample-athena-query-results-${ACCOUNT_ID}"
- データベースの作成
aws athena start-query-execution \
--query-string "$(cat sql/create-database.sql)" \
--result-configuration OutputLocation=s3://"${S3_BUCKET_FOR_ATHENA_QUERY_LOG}"
- テーブルの作成
aws athena start-query-execution \
--query-string "$(cat sql/create-table.sql | sed -e s/\${ACCOUNT_ID}/${ACCOUNT_ID}/g)" \
--result-configuration OutputLocation=s3://"${S3_BUCKET_FOR_ATHENA_QUERY_LOG}"
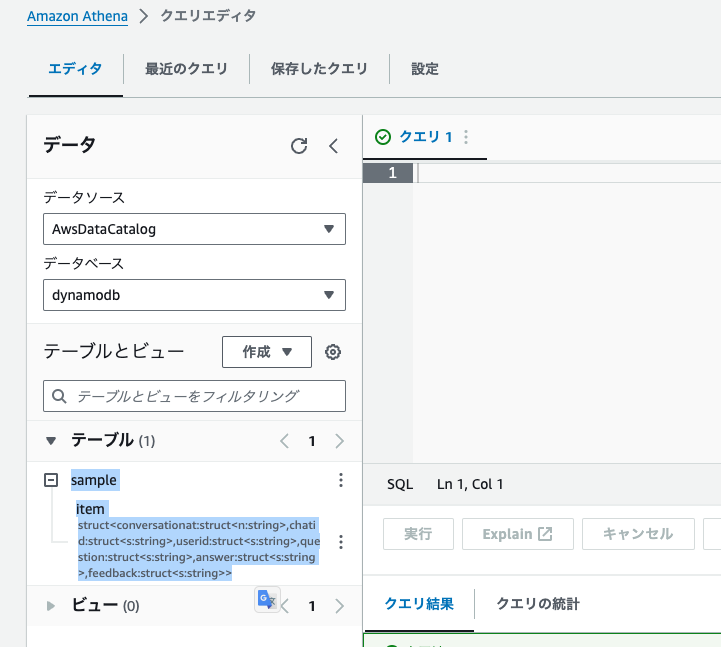
Athenaのコンソールから確認すると以下のようにsampleというテーブルが作成されていることが分かると思います。
③DynamoDBへのサンプルデータの登録
aws dynamodb batch-write-item \ --request-items file://sample-data/request-items.json
今回は以下のようなサンプルデータを登録します。
| ChatId | ConversationAt | UserId | Question | Answer | Feedback |
|---|---|---|---|---|---|
| 1 | 1 | user1 | 質問1 | 回答1 | Good |
| 1 | 2 | user1 | 質問2 | 回答2 | Good |
| 1 | 3 | user1 | 質問3 | 回答3 | Good |
| 2 | 1 | user2 | 質問1 | 回答1 | Good |
| 2 | 2 | user2 | 質問2 | 回答2 | Bad |
| 3 | 1 | user3 | 質問1 | 回答1 | Good |
| 3 | 2 | user3 | 質問2 | 回答2 | Good |
| 3 | 3 | user3 | 質問3 | 回答3 | Bad |
| 3 | 4 | user3 | 質問4 | 回答4 | Good |
| 3 | 5 | user3 | 質問5 | 回答5 | Bad |
| 3 | 6 | user3 | 質問6 | 回答6 | Good |
④DynamoDBのエクスポート
- 変数の設定
S3_BUCKET_FOR_EXPORT_DYNAMODB="sample-export-dynamodb-${ACCOUNT_ID}"
DYNAMODB_TABLE_ARN=arn:aws:dynamodb:ap-northeast-1:${ACCOUNT_ID}:table/sample-chat-history-table
- DynamoDBのエクスポート
export_arn=$(aws dynamodb export-table-to-point-in-time \
--table-arn "${DYNAMODB_TABLE_ARN}" \
--s3-bucket "${S3_BUCKET_FOR_EXPORT_DYNAMODB}" \
--query "ExportDescription.ExportArn" \
--output text
)
- DynamoDBのエクスポートのステータス確認
aws dynamodb describe-export \
--export-arn "${export_arn}" \
--query 'ExportDescription.ExportStatus' \
--output text
エクスポート直後は、「IN_PROGRESS」と表示されると思います。 約5分程度で処理が完了すると思うので、「COMPLETED」が表示されるまで待ちます。
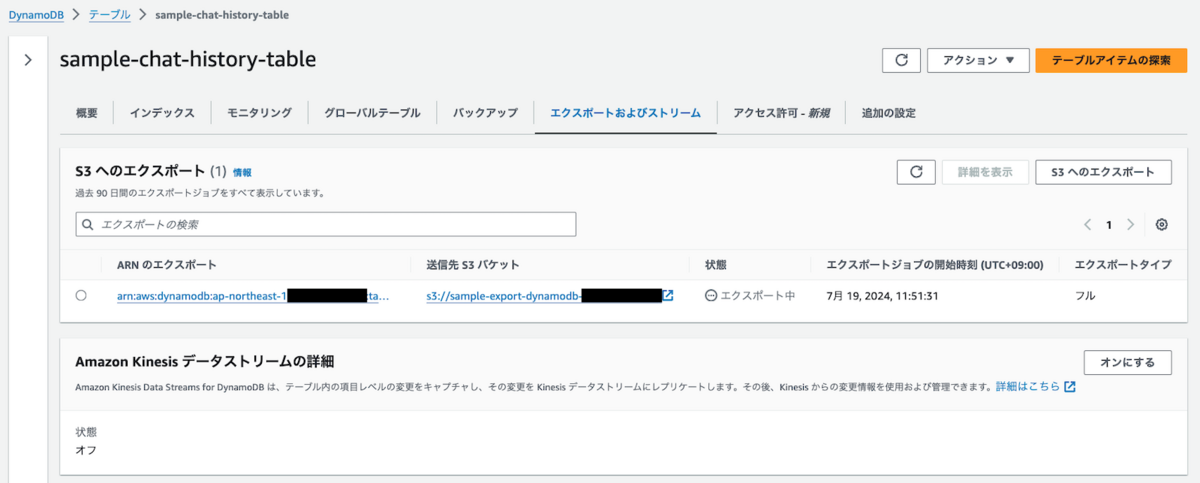
DynamoDBのコンソールから確認すると以下のようにエクスポートが実行されていることが分かると思います。
⑤動作確認
最後は動作確認として、AthenaのコンソールからSQLを実行します。
https://ap-northeast-1.console.aws.amazon.com/athena/home
- サンプルデータの確認
select
item.Chatid.s as Chatid,
item.ConversationAt.n as ConversationAt,
item.UserId.s as UserId,
item.Question.s as Question,
item.Answer.s as Answer,
item.feedback.s as feedback
from dynamodb.sample

- Good と Badの集計
select
COUNT(*) AS Total,
COUNT(CASE WHEN item.Feedback.s = 'Good' THEN 1 END) AS Good,
COUNT(CASE WHEN item.Feedback.s = 'Bad' THEN 1 END) AS Bad
from dynamodb.sample

- 利用者ランキング
SELECT item.UserId.s AS UserId, COUNT(*) AS Count FROM dynamodb.sample GROUP BY item.UserId.s ORDER BY Count DESC;

終わりに
今回は、DynamoDBのデータをAthenaで分析する仕組みを作ってみました。 どなたかのお役に立てれば幸いです。