

はじめに
こんにちは。アプリケーションサービス部 河野です。
最近 Glue の Python Shell ジョブを初めて触ったのですが、その際に検証した ETL 実装について備忘録として記載します。
検証では、以下処理を実行する単一の Python Shell ジョブを実装しました。
- S3 から CSV ファイルをダウンロード
- CSV ファイルを Pandas DataFrame に読み込む
- データ加工(列を削除)
- Parquet に変換
- S3 にアップロード
※ ジョブはコンソールから直接実行します。
前準備
S3 作成
今回は、入力用と出力用は同一バケットとし、入力用を (/in) 出力用を(/out)で Prefix を作成します。

サンプルCSVファイルのアップロード
以下 CSV ファイルを S3 にアップロードします
sample.csv
id,name,age 001,tanaka,18 002,kawano,20 003,murakami,20 004,suzuki,22
aws s3 cp sample.csv s3://{your_bucket_name}/in/
実践
1. ジョブ用のIAM ロール作成
ジョブが使用する以下ポリシーを付与したIAMロールを作成します。
| 項目 | 値 | |
|---|---|---|
| ロール名 | pythonshell-etl-sample-role | |
| ポリシー | AWS管理ポリシー | AWSGlueServiceRole |
| カスタマー管理ポリシー | pythonshell-etl-sample-policy |
- pythonshell-etl-sample-policy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::{your_bucket_name}/*" } ] }


2. Glue ジョブ(Python Shell)を作成
以下の通りジョブを作成します。


3. スクリプトを編集
ジョブを保存後、そのままスクリプトの編集画面に遷移します。
以下スクリプトを保存します。
pythonshell-sample.py
import boto3 import pandas as pd import io import os print('script start.') MY_BUCKET = '{your_bucket_name}' LOCAL_FILE_PATH = '/tmp' s3 = boto3.resource('s3') src_obj = s3.Object(MY_BUCKET, 'in/sample.csv') body = src_obj.get()['Body'].read().decode('utf-8') # 文字コードはcsv ファイルを作成したOSに合わせて変更してください buffer_str = io.StringIO(body) # Pandas DataFrame に読み込む df_in = pd.read_csv(buffer_str) print(df_in) # age 列を削除 df_in = df_in.drop(columns='age') print(df_in) # CSV → Parquet df_in.to_parquet(LOCAL_FILE_PATH + '/sample.parquet', compression='snappy') s3.meta.client.upload_file(LOCAL_FILE_PATH + '/sample.parquet', MY_BUCKET, 'out/sample.parquet') print('script complete.')
4. pyarrow ライブラリをアップロード
上記スクリプトの Parquet 変換の処理(※1)では、pyarrow を使用しています。
python shell は pyarrow をデフォルトでサポートしていない(※2)ため、手動でライブラリをアップロードする必要(※3)があります。
以下手順で、pyarrow ライブラリをアップロードします。
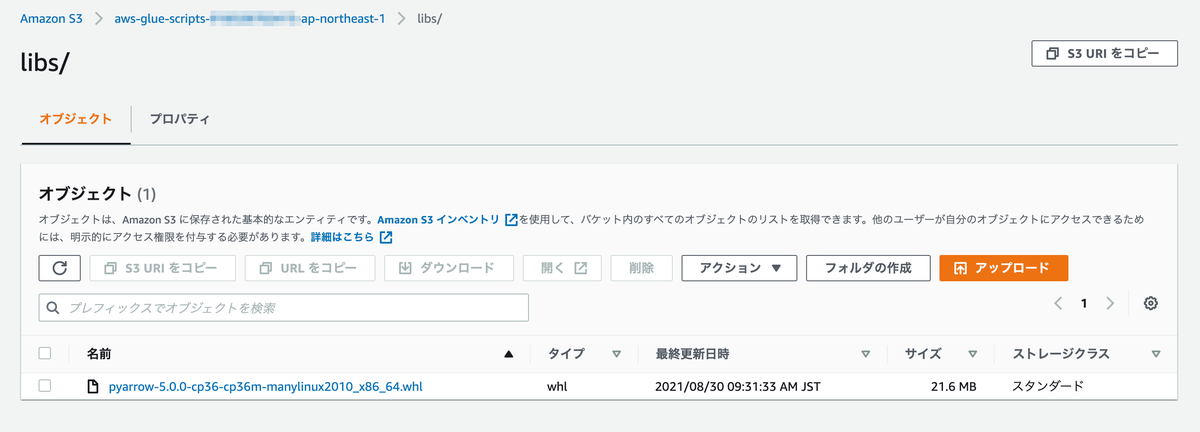
- https://files.pythonhosted.org/packages/78/5d/ff4f3d80f6332136c46d71a2b5026602e1f0462790831e687fc76408d949/pyarrow-5.0.0-cp36-cp36m-manylinux2010_x86_64.whl からpyarrow の wheel ファイルをダウンロードします。
- 下記コマンドを実行して、Glueスクリプト格納バケットにアップロードします。
aws s3 cp {ファイルパス}/pyarrow-5.0.0-cp36-cp36m-manylinux2010_x86_64.whl s3://aws-glue-scripts-{your_aws_account_id}-ap-northeast-1/libs/
※1 pandas.DataFrame.to_parquet¶
※2 Supported Libraries for Python Shell Jobs
※3 AWS Glue 1.0 または 0.9 ETL ジョブで外部 Python ライブラリを使用するにはどうすればよいですか?
5. Python ライブラリパスを追加
先ほどアップロードしたライブラリをジョブから参照できるように、ライブラリパスを追加します。
マネジメントコンソール > Glue > ジョブ > アクション > ジョブの編集 から以下プロパティを設定します。
- セキュリティ設定、スクリプトライブラリおよびジョブパラメータ
- Python ライブラリパス: s3://aws-glue-scripts-{your_aws_account_id}-ap-northeast-1/libs/pyarrow-5.0.0-cp36-cp36m-manylinux2010_x86_64.whl
6. ジョブ実行
AWS Glue コンソールからジョブを実行します。


最初にライブラリがインストールされ、その後スクリプトが実行されていることがわかります。

バケットに Parquet ファイルがアップロードされています。
7. 確認
s3 にアップロードされた Parquet ファイルをダウンロードして中身を確認します。
今回は、vscode の拡張 「parquet-viewer」を使用しました。
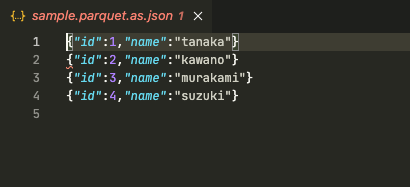
age 列が削除されていますね。
さいごに
今回は単一のジョブでしたが、ジョブワークフローを使用すれば複数ジョブを繋ぎ合わせて一つの ETL を実装することが可能です。 本記事が、Python Shell 実装の取っ掛かりの手助けになれば幸いです。
swx-go-kawano (執筆記事の一覧)