

CI部の村上です。
前回に続きEKS・Datadogの話題です。
はじめに
Kubernetesでのリソース管理について
EKSに限らずKubernetesでは、各コンテナがCPUやメモリをどれだけ使用しても良いか、マニフェストで定義します。
具体的には、spec.containers[].resources.の中のrequestsにコンテナに割り当てる最低限のリソース、limitsにコンテナに割り当てて良い最大値を記載します。
例えば以下のマニフェストでは、コンテナにCPU500millicore(0.5vCPU)、メモリ200MiBが割り当てられ、必要に応じてCPU1000millicore(1vCPU)、メモリ400MiBが最大値として提供されます。
apiVersion: v1 kind: Pod metadata: name: example namespace: example spec: containers: - name: example image: nginx resources: limits: memory: "400Mi" cpu: "1000m" requests: memory: "200Mi" cpu: "500m"
Memory Requestsを指定しない場合、Memory Limitsと同じ値が適用されてしまうので、適切な値を設定する必要があります(CPU Requestsも同様)。
一方でMemory LimitsとCPU Limitsを指定しない場合は、ノードで割り当て可能なすべてのリソースを使えるようになります。
メモリー制限を指定しない場合、 コンテナは実行中のノードで利用可能なすべてのメモリーを使用でき、その後OOM Killerが呼び出される可能性があります。 https://kubernetes.io/ja/docs/tasks/configure-pod-container/assign-memory-resource/#%E3%83%A1%E3%83%A2%E3%83%AA%E3%83%BC%E5%88%B6%E9%99%90%E3%82%92%E6%8C%87%E5%AE%9A%E3%81%97%E3%81%AA%E3%81%84%E5%A0%B4%E5%90%88
記事の概要
各コンテナのMemory RequestsとCPU Requestsの合計値をDatadogで監視します。
この値が、ノードが割り当て可能なメモリ・CPUを超えてしまうと、そのノードにPodをデプロイできなくなります。
なので、各コンテナのRequestsの合計値が過剰な値になっていた場合、実際はノードのリソースに余裕があるのにPodをデプロイできない事態になってしまいます。
ノードがAutoScalingするならサービスが止まるような事態にはならないかもしれませんが、それでもリソースを効率よく使うためにも監視する意義はあると考えています。
今回の環境
t3.smallのノードが1つだけある構成です。
administrator:~/environment $ kubectl get node NAME STATUS ROLES AGE VERSION ip-192-168-71-210.ap-northeast-1.compute.internal Ready <none> 11h v1.19.13-eks-8df270 administrator:~/environment $ kubectl get node ip-192-168-71-210.ap-northeast-1.compute.internal -o json | jq '.metadata.labels."beta.kubernetes.io/instance-type"' "t3.small"
Datadogで監視する
今回は以下のDeploymentで試します。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80 resources: requests: memory: "50Mi" cpu: "50m"
デプロイした後、kubectlで実際の値を確認してみます。Memory requstsが19%、CPU Requestsが23%と表示されています。
administrator:~/environment $ kubectl describe node ※中略 Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 460m (23%) 0 (0%) memory 290Mi (19%) 340Mi (23%) ephemeral-storage 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0
メモリ要求の監視
Memory Requestはkubernetes_state.container.memory_requestedのメトリクスで取得可能です。
これをノードごとで合計することで、1ノードあたりの各コンテナのMemory Requestの合計値が出ます。
また、ノードがコンテナに割り当て可能なメモリはkubernetes_state.node.memory_allocatableで取得可能です。
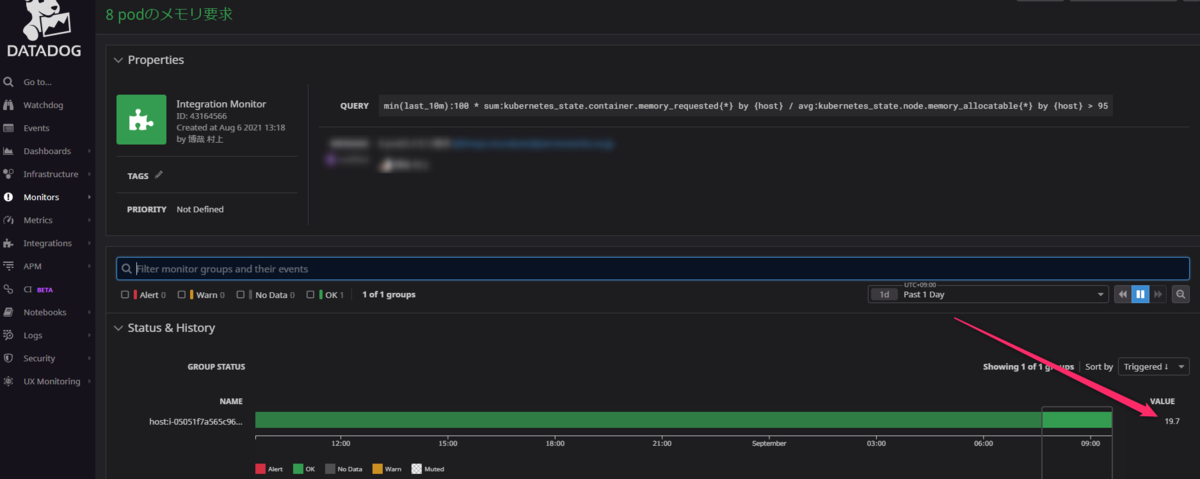
実際にこれらのメトリクスを使用してモニターを作成してみました。19.7%と表示されており、さきほどkubectl describe nodeで得た値と一致します。
CPU要求の監視
CPU Requestsはkubernetes_state.container.cpu_requestedのメトリクスで取得可能です。
また、ノードがコンテナに割り当て可能なCPUはkubernetes_state.node.cpu_allocatableで取得可能です。
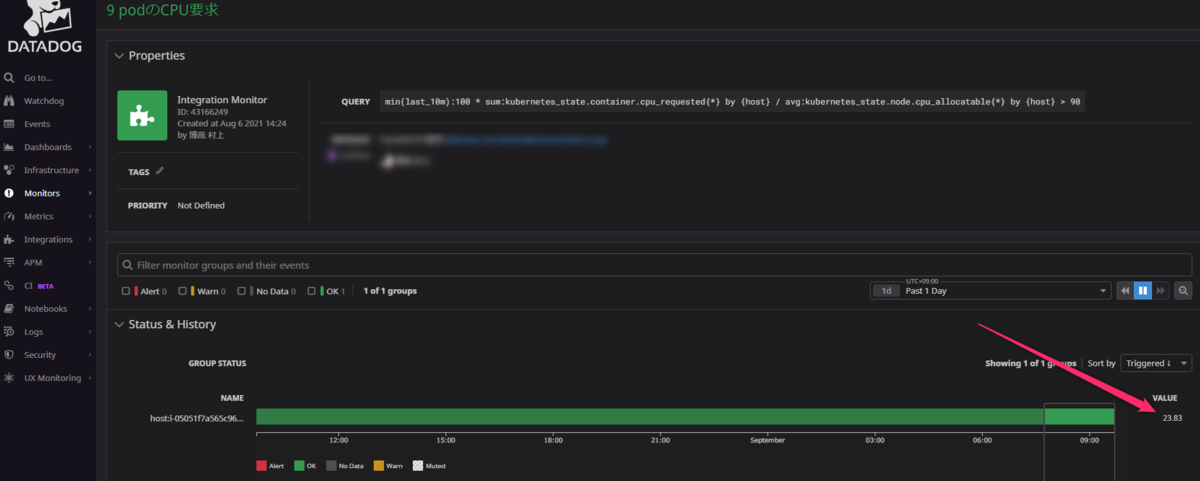
同様にしてモニターを作成してみました。23.83%と表示されており、さきほどkubectl describe nodeで得た値と一致します。
今回は以上になります。読んでいただき有難うございました。